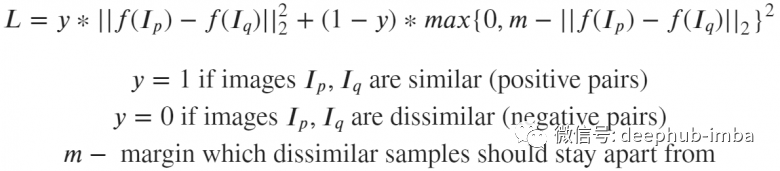本文约3400字,建议阅读7分钟
本文为你介绍如何查找相似图像的理论基础并且使用一个用于查找商标的系统为例介绍相关的技术实现。
在本文中将介绍如何查找相似图像的理论基础并且使用一个用于查找商标的系统为例介绍相关的技术实现,本文提供有关在图像检索任务中使用的推荐方法的背景信息。阅读本文后你将有能够从头开始创建类似图像的搜索引擎的能力。
图像检索(又名基于内容的图像检索Content-Based Image Retrieval 或 CBIR)是任何涉及图像的搜索的基础。上图来自文章Recent Advance in Content-based Image Retrieval: A Literature Survey (2017) arxiv:1706.06064
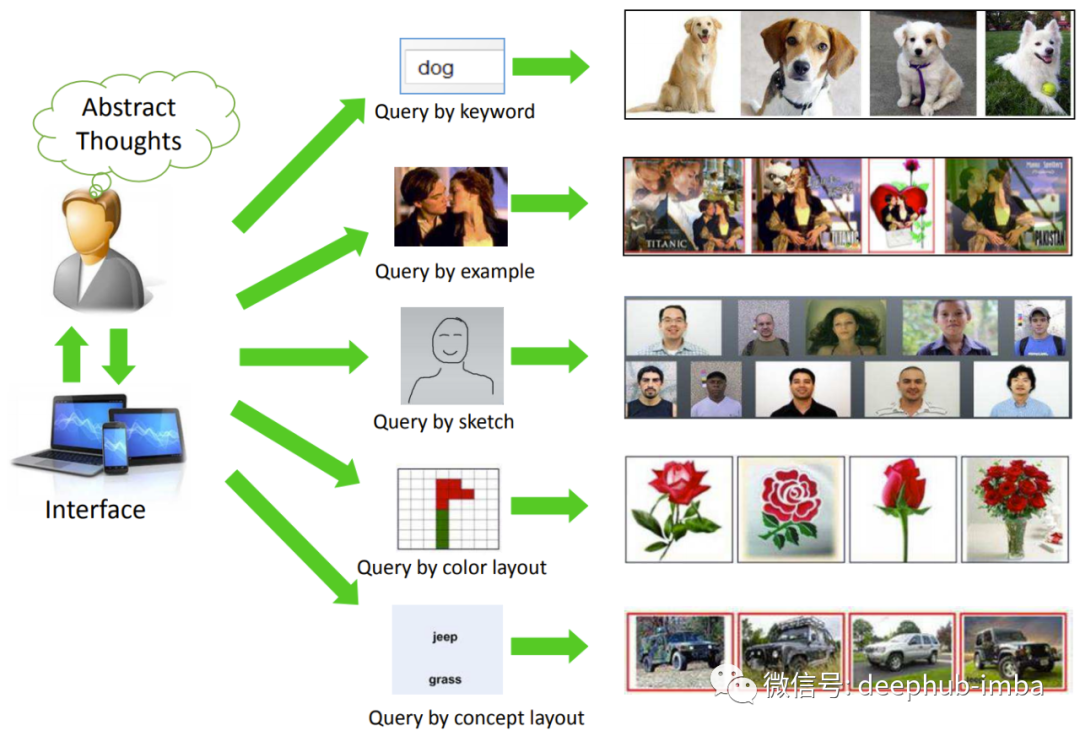
“按照片进行搜索”方式已经出现在各个领域,特别是在电子商务网站中(例如淘宝),并且 “通过关键词搜索图片”(对图片内容的理解)早已被谷歌、百度,bing等搜索引擎使用(图片搜索)。我认为自从计算机视觉界轰动一时的 CLIP: Connecting Text and Images 出现后,这种方法的全球化将会加速。在本文中,将只讨论研究计算机视觉中的神经网络的图片搜索方法。基础服务组件
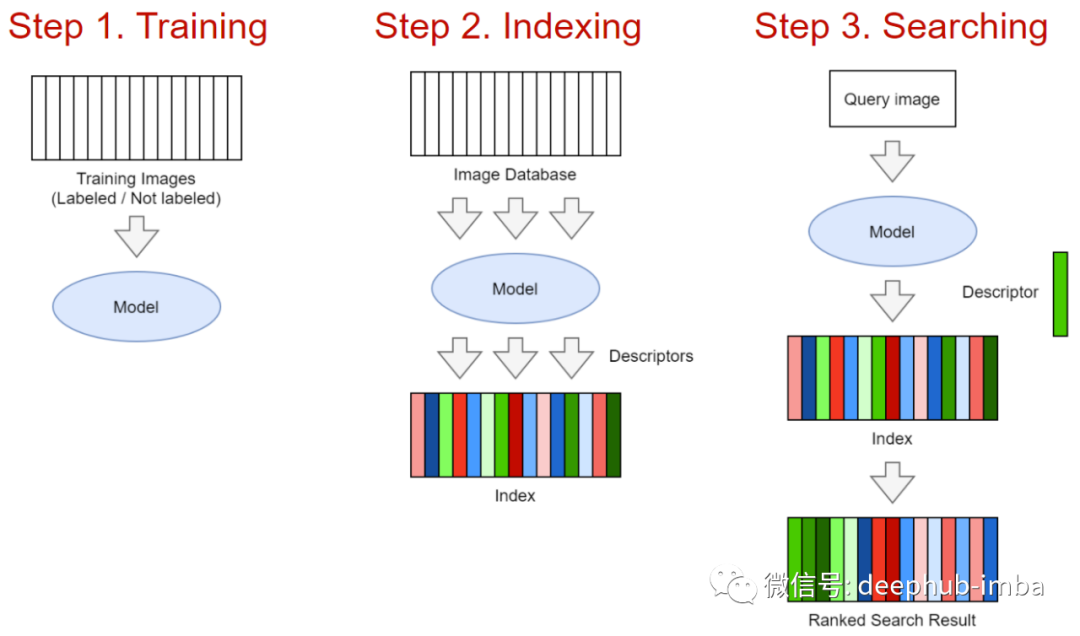
步骤 1. 训练模型。该模型可以在经典的 CV 或基于神经网络的基础上制作。模型输入——图像,输出——D维的特征嵌入。在传统的情况下,它可以是 SIFT-descriptor + Bag of Visual Words 的组合。在神经网络的情况下,可以是像 ResNet、EfficientNet 等这样的标准主干 + 复杂的池化层 。如果有足够的数据,神经网络几乎总是表现得很好,所以我们将专注于它们。
步骤 2. 索引图像。索引是在所有图像上运行经过训练的模型,并将获得的嵌入写入特殊索引以进行快速搜索的过程。步骤 3. 搜索。使用用户上传的图像,通过模型获得嵌入,并将该嵌入与数据库(索引)中的其他图像的嵌入进行比较,并且搜索结果可以按照相关性排序。神经网络和度量学习
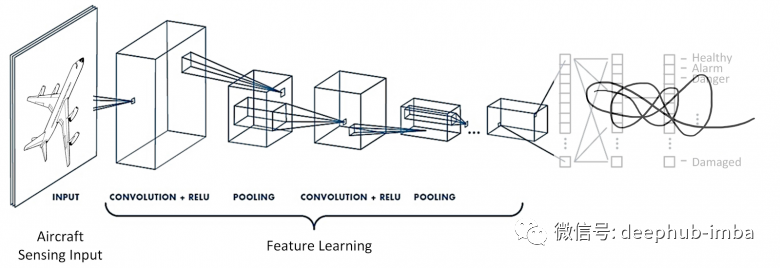
在寻找相似性任务中,神经网络的作用是特征提取器(主干网络)。主干网的选择取决于数据的数量和复杂性——可以考虑从 ResNet18 到 Visual Transformer 的所有模型。
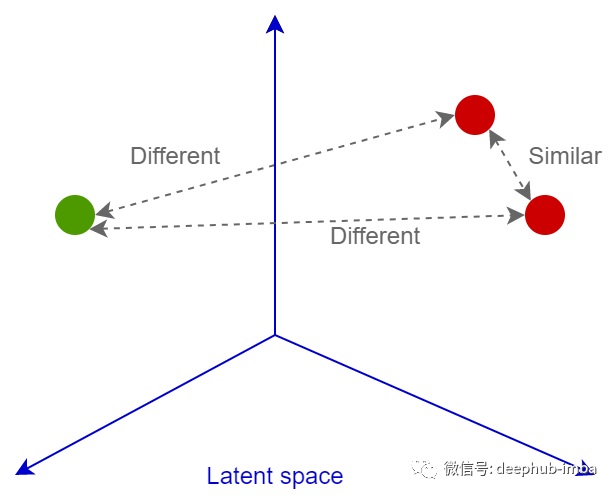
图像检索中模型的第一个特点是是神经网络头的设计。在Image Retrieval 排行榜(https://kobiso.github.io/Computer-Vision-Leaderboard/cars.html)上,它们通过parallel pools 、Batch Drop Block等技术,可以获得使输出特征图的激活分布更均匀的最佳图像特征描述。第二个主要的特征是损失函数的选择。仅在 Deep Image Retrieval: A Survey (arxiv 2101.11282)中,就有十几个推荐的可用于配对训练的损失函数。 所有这些损失的主要目的都是训练神经网络将图像转换为线性可分空间的向量,以便进一步通过余弦或欧几里德距离比较这些向量:相似的图像将具有紧密的嵌入,不相似的图像将距离则比较遥远。下面我们看看几个主要的损失函数。损失函数
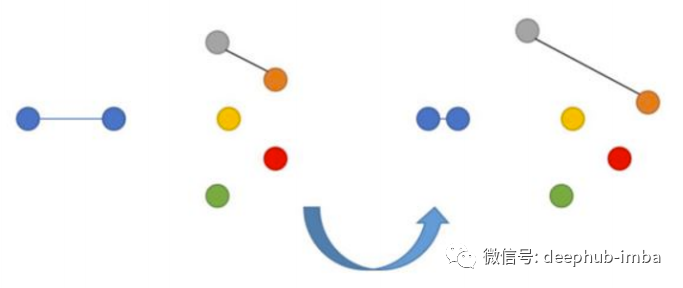
如果这些图像实际上相似,则神经网络会因图像 p 和 q 的嵌入彼此之间的距离过远而受到惩罚。如果图像实际上是彼此不同,但嵌入距离较近也会受到惩罚,但是在这种情况下设置了边界 m(例如,0.5),这个设置是认为神经网络已经应对了“分离”不同图像的任务,不需要进行过多的惩罚。
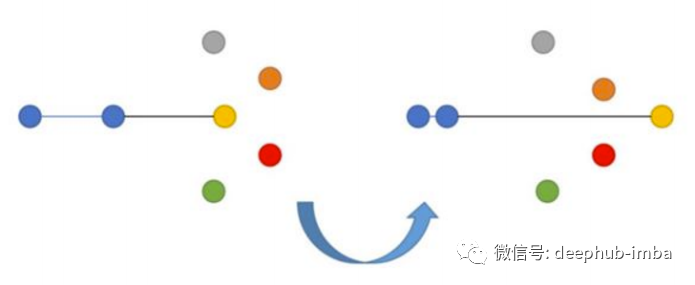
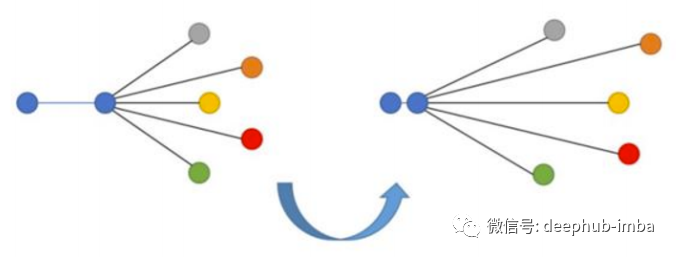
这个损失的目标是最小化anchor到positive的距离,最大化anchor到negative的距离。Triplet Loss 最早是在 Google 的 FaceNet 关于人脸识别的论文中引入的,长期以来一直是最先进的解决方案。N-tupled Loss是Triplet Loss 的一种发展,它也采用 anchor 和 positive,但使用多个negative样本而不是一个negative样本。
4、Angular Additive Margin (ArcFace)
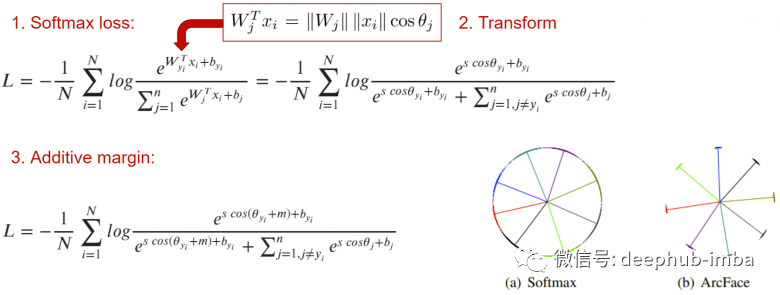
双重损失的问题在于选择anchor、positive和negative的组合——如果它们只是从数据集中均匀随机抽取,那么就会出现“light pairs”的问题,某些图像对的损失将为 0这样会网络非常快的收敛到一个状态,因为我们的输入中的大多数样本对它来说很“容易”,当损失为0时网络就停止学习了。为了避免这个问题,ArcFace为样本的配对提出复杂的挖掘技术—— hard negative和hard positive挖掘。对这方面感兴趣的可以看看一个叫PML 库,它实现了许多挖掘方法,该库包含很多关于 PyTorch 上的 Metric Learning 任务的有用信息,有兴趣的可以多关注下。light pairs问题的另一个解决方案是分类损失。ArcFace主要思想是在通常的交叉熵中添加一个缩进 m,它可以使同类图像的嵌入分布在该类的质心区域中心周围,以便它们都与其他类的嵌入集群分开最小的角度 m。
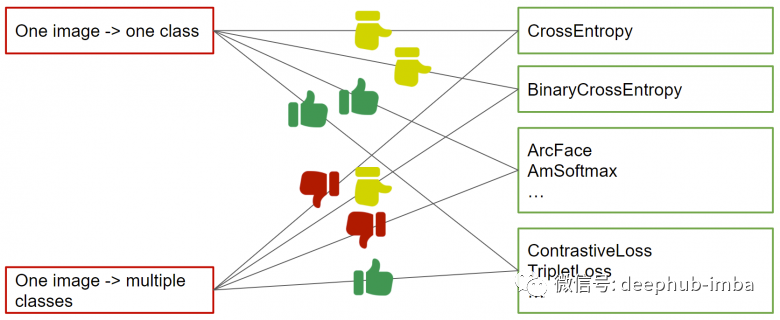
这是一个完美的损失功能,尤其是在使用MegaFace 进行基准测试时。但是ArcFace需要在有分类标记的情况下才会起作用。毕竟如果没有分类的标记是无法计算交叉熵的,对吧。上图展示了具有单类和多类标记时选择损失函数的推荐(如果没有标记也可以通过计算样本的多标签向量之间的交集百分比从后者派生成匹配对的标记)。
池化
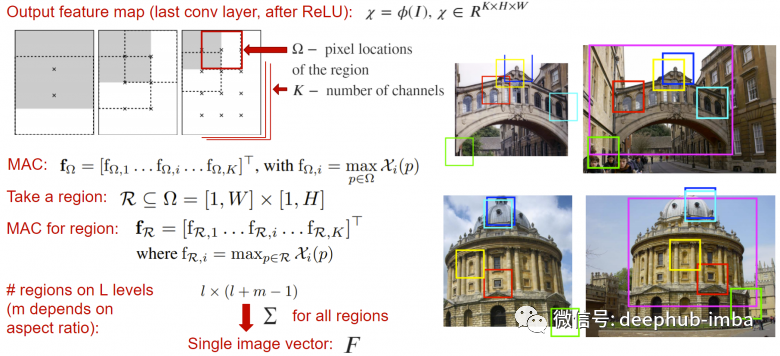
在神经网络架构中池化也会经常被用到,下面介绍图像检索任务中使用的几个池化层。Regional Maximum Activation of Convolutions (R-MAC)可以看作一个池化层,它接收神经网络的输出特征图(在全局池化或分类层之前)并返回根据不同窗口计算输出激活总和的向量描述,其中每个窗口的激活是每个通道独立的取这个窗口的最大值。这种操作是通过图像在不同尺度上的局部特征创建了更丰富的特征描述。这个描述符本身就是是一个嵌入的向量,所以它可以直接输送到loss函数。
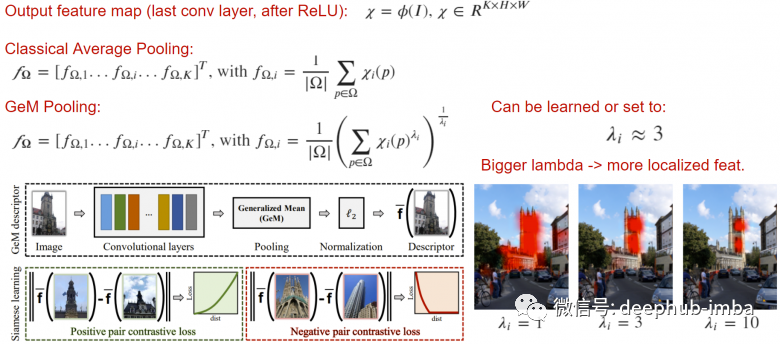
Generalized Mean(GeM)是一个可以提高输出描述符的质量简单的池化操作,它将lambda范式应用到平均池化操作中。通过增加lambda,使网络聚焦于图像的重要部分,这在某些任务中是很有效的。
距离的测量
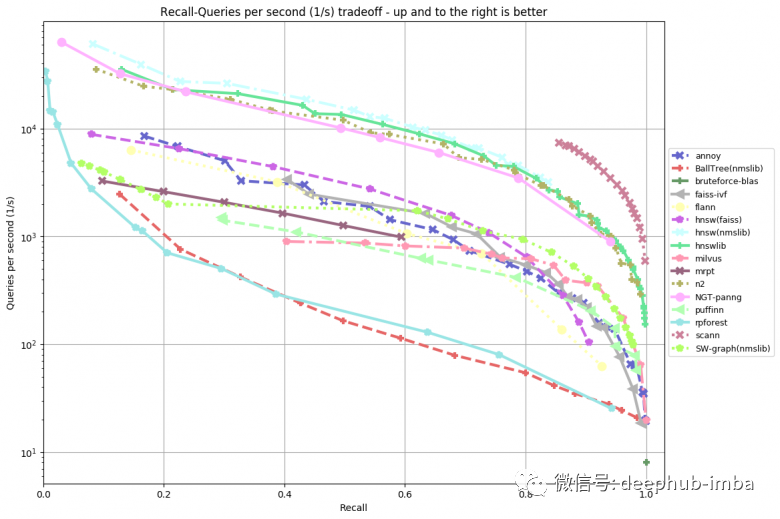
高质量搜索相似图像的另一个关键点是排名,即显示给定查询的最相关结果。它的主要度量是建立索引的速度、搜索的速度和消耗的内存。最简单的方法是直接使用嵌入向量进行暴力的搜索,例如使用余弦距离。但是当有数据量很大时就会出现问题——数百万、数千万甚至更多。搜索速度明显降低。这些问题可以以牺牲质量为代价来解决——通过压缩(量化)而不是以原始形式存储嵌入。同时也改变了搜索策略——不是使用暴力搜索,而是尝试用最小的比较次数来找到最接近给定查询的嵌入向量。有大量的高效的框架来近似搜索最接近的对象。例如NMSLIB, Spotify Annoy, Facebook Faiss, Google Scann。除了机器学习的库以外,传统 Elasticsearch在7.3 以后也支持向量的查询。
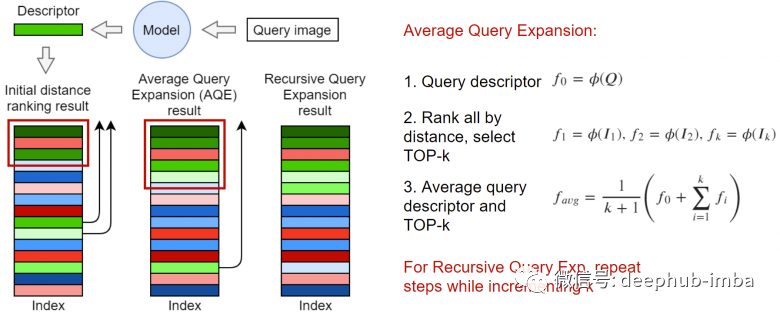
信息检索领域的研究人员很早早就发现了:在收到原始搜索结果后,可以通过某种方式对集合进行重新排序来改进搜索结果的质量。使用最接近搜索输入的 top-k 来生成新的嵌入, 在最简单的情况下可以取平均向量。如上图所示,还可以对嵌入进行加权,例如通过问题中的距离或与请求的余弦距离进行加权排序。
k-reciprocal 是一组来自 top-k 的元素包括最接近请求本身的 k 个元素, 在这个集合的基础上构建了对结果进行重新排序的过程,其中之一是在Re-ranking Person Re-identification with k-reciprocal Encoding一文中进行的描述。k-reciprocal 比 k最近邻更接近查询。因此可以粗略地将 k-reciprocal 集中的元素视为已知正样本,并更改加权规则。原始论文中包含大量计算,这超出了本文的范围,建议有兴趣的读者阅读。
验证指标
最后就是检查类似搜索质量的部分。初学者在第一次开始从事图像检索项目时可能不会注意到此任务中的许多细微之处。让我们看一下图像检索任务中这些流行的指标:precision@k、recall@k、R-precision、mAP 和 nDCG。- 对给定查询的相关样本的数量非常敏感,可能产生对搜索质量的非客观评估,因为不同的查询有不同数量的相关结果
- 仅当所有查询的相关数 >= k 时,才有可能达到1
与precision@k 相同,其中k 设置为等于相关查询的数量。
优点:对precision@k中数字k的敏感性消失,度量变得稳定缺点:必须知道与查询请求相关的样本总数(如果不是所有相关的都被标记,会产生问题)4、mAP(mean Average Precision)用相关结果填充搜索结果顶部的密集程度。可以将其视为搜索引擎用户收到相同的信息量时需要阅读的页面数(越少越好)。5、nDCG (Normalized Discounted Gain)该度量显示了 top-k 中的元素在它们之间的排序是否正确。这里不会介绍这个指标的优缺点,因为这是度量指标列表中唯一考虑元素顺序的一个指标。并且有研究表明当需要考虑顺序时,这个指标相当稳定并且适用于大多数情况。
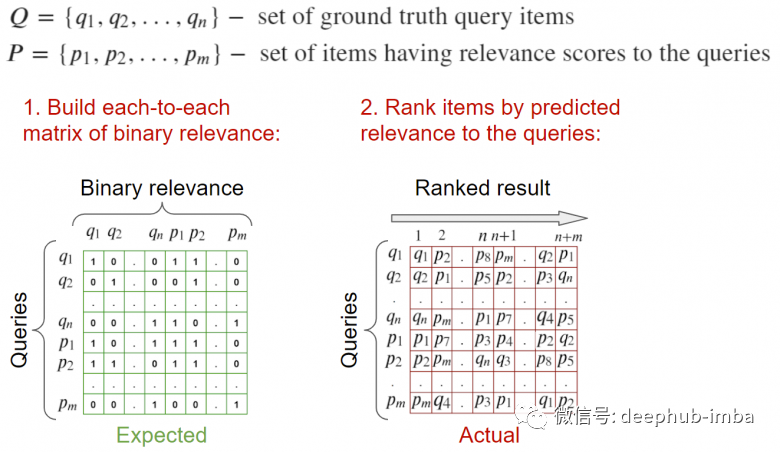
输入:请求图像和与其相关的图像。需要有与此查询相关的列表形式的标记。
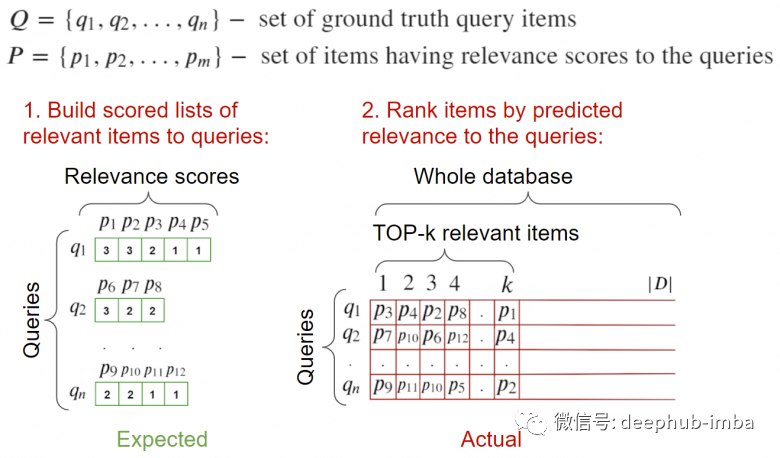
要计算指标:计算每个的相关矩阵,并根据有关元素相关性信息,计算指标。输入:请求的图像,以及与它们相关的图像。理想情况下应该有一个验证图像的数据库,所有相关查询都在其中被标记。需要注意的是相关图像中不应包含查询的图像以免它会排在 top-1,我们的任务是相关图像而不是找到他自己本身。
要计算指标:遍历所有请求,计算到所有元素(包括相关元素)的距离,并将它们发送到指标计算函数。完整的样例介绍
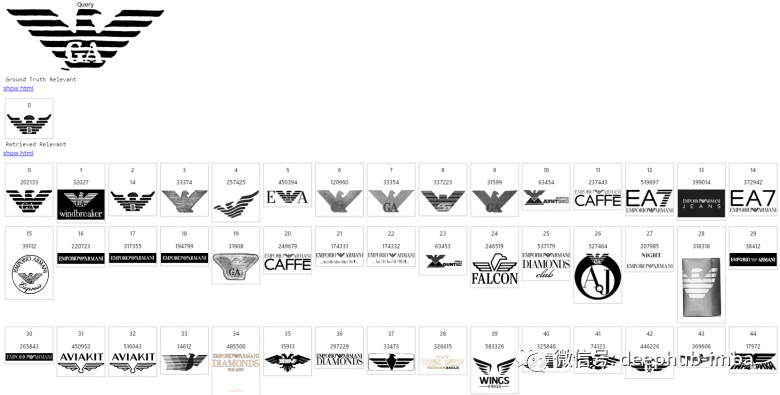
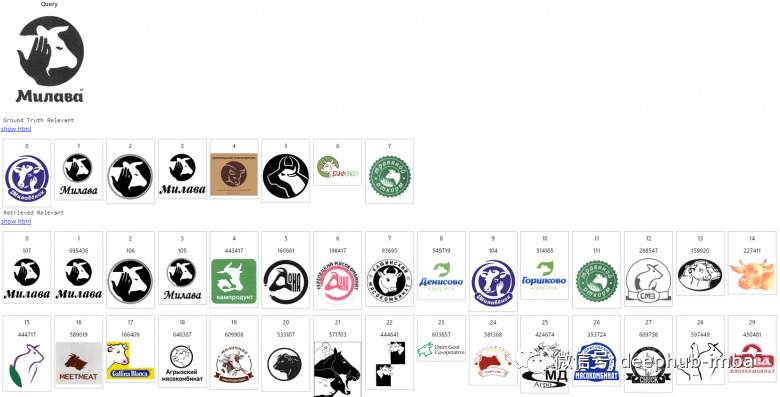
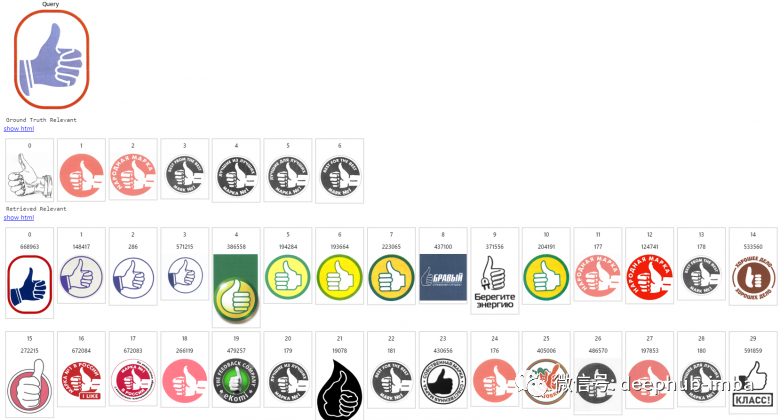
这里以搜索相似商标logo为例介绍图像搜索引擎是如何工作的。图像索引数据库的大小:数百万个商标。这里第一张图片是一个查询,下一行是返回的相关列表,其余行是搜索引擎按照相关性递减的顺序给出的内容。
总结
就是这样,希望本篇文章可以那些正在构建或即将构建类似图像搜索引擎的人提供一个完整的思路,如果你有什么好的建议也欢迎留言。