基于深度学习的图像匹配技术一览

整理自:https://mp.weixin.qq.com/s/8ilO_X_uEfMMQDNwzLSaUQ
编辑:极市平台
- 应用:
目标识别、目标跟踪、超分辨率影像重建、视觉导航、图像拼接、三维重建、视觉定位、场景深度计算
- 方法:
基于深度学习的特征点匹配算法、实时匹配算法、3维点云匹配算法、共面线点不变量匹配算法,以及基于深度学习的图像区域匹配等。
- 分类:
局部不变特征点匹配、直线匹配、区域匹配
Part1:局部不变特征点匹配-2D1. 什么是图像特征点?- 关键点+描述子
- 关键点:指特征点在图像中的位置,具有方向、 尺度等信息;
- 描述子:描述子通常是一个向量,描述关键点邻域的像素信息。
2. 如何进行特征点匹配 ?- 人工设计检测器
在向量空间对两个描述子进行比较,距离相近则判定为同一个特征点
角点、边缘点等都可以作为潜在特征点
- SIFT总结【5】:许允喜等,对局部图像描述符进行分析描述,对这类方法的计算复杂度、评价方法和应用领域 予以总结。
- SIFT总结【4】:刘立等,对 SIFT 算法的演变以及在 不同领域的典型应用进行了较为全面的论述,并比 较了各类算法的优缺点。
- SIFT算法改进【9】【10】【11】:针对算法时间复杂度高,PCA-SIFT, SURF, SSIF
- SIFT算法改进【12】:对彩色图 像进行处理的 CSIFT( colored SIFT)
- SIFT算法改进【13】:使用对数极坐标分级结构的 GLOH( gradient location and orientation histogram)
- SIFT算法改进【14】:具有仿射不变性的ASFIT( affine SIFT)
- Fast【2】:通过邻域像素对比进行特征点检测并引入机器学习加速这一过程,可应用在对实时性要求较高的场合,如视频监控中的目标识别。由于FAST 仅处理单一尺度图像,且检测的不仅仅是“角点”这一特征,还可以检测到其他 符合要求的特征点,如孤立的噪点等。当图像中噪 点较多时会产生较多外点,导致鲁棒性下降。
- Harris【1】:通过两个正交方向上 强度的变化率对角点进行定义,其本身存在尺度固 定、像素定位精度低、伪角点较多和计算量大等问题。
- Harris改进算法【6】:将多分辨率思想引入 Harris 角点,解决了 Harris 算法不具有尺度变化的问题。
- Harris改进算法【7】:在 Harris 算法中两次筛选候选点集,利用最小二乘加 权距离法实现角点亚像素定位,大幅度提高角点检测效率和精度。
- Harris改进算法【8】:将灰度差分及模板与 Harris 算法相结合,解决了 Harris 算法中存在较多伪角 点和计算量大等问题。
角点检测算法 - 最常用:基于图像灰度的方法
邻域像素检测
SIFT【3】:不再局限于对角点检测
3. 如何进行特征点匹配 ?
3.1 深度学习特征检测器 - 局部特征点的重复检测
- FAST-ER算法【15】:把特征点检测器定义为一种检测高重复点的三元决策树,并采用模拟退火算法对决策树进行优化,从而提高检测重复率。由于在每次 迭代过程中,都需要对重新应用的新决策树进行检 测,且其性能受到初始关键点检测器的限制,降低了 该算法的鲁棒性。
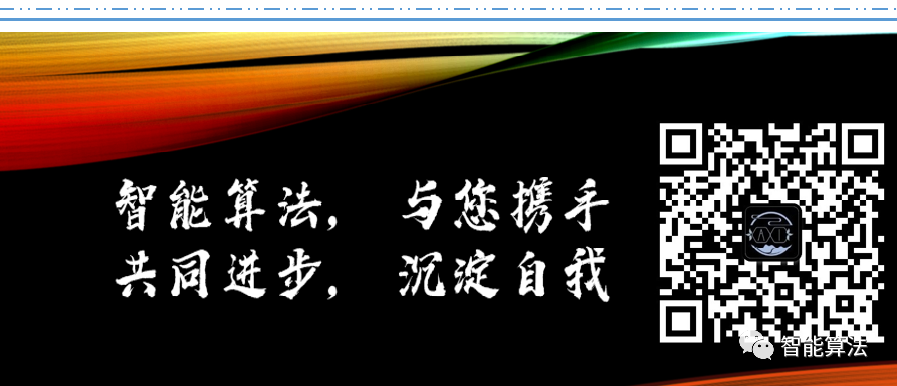
- 时间不变特征检测器( TILDE) 【16】:Verdie 等人提出,能够较好地对由天气、季节、时 间等因素引起的剧烈光照变化情况下的可重复关键 点进行检测。参与训练的候选特征点是由多幅训练 图像中采用 SIFT 算法提取的可重复关键点组成,如 图a ; 正样本是以这些点为中心的区域,负样本 是远离这些点的区域。在进行回归训练时,正样本 在特征点位置返回最大值,远离特征点位置返回较 小值,如图 b ; 回归测试时,将测试图像分成固定 大小的图像块,其回归响应如图c ,然后根据非 极大值抑制提取特征点,如图d 。该方法适用于处理训练数据和测试数据为同一场景的图像。(TILDE 采用手动标记的数据作为区分性特征训练,使用DOG-difference of Gaussian收集训练集,对于跨模态任务如RGB/深度模态对不再适用)
- 基于学习的协变特征检测器【17】:综合考虑两个局部特征检测器特性(检测可区分的特征;协变约束-在不同的变换下重复检测一致特征),Zhang 等人提出。该方法将 TILDE 的输出作为候选标准图像块,通过变换预测 器的训练建立学习框架,将局部特征检测器的协变 约束转化为变换预测器的协变约束,以便利用回归 ( 如深度神经网络) 进行变换预测。预测的变换有 两个重要性质: 1) 变换的逆矩阵能将观察到的图像 块映射到“标准块”,“标准块”定义了具有可区分性 的图像块以及块内“典型特征”( 如单位圆) 的位置 和形状; 2) 将变换应用到“典型特征”可以预测图像 块内变换特征的位置和形状。
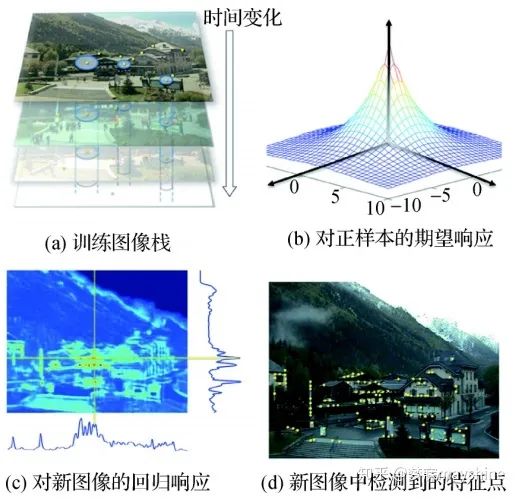
- Quadnetworks【18】:采用无监督学习方式进行特征点检测。Savinov 等人 提出,该方法将关键点检测问题转化为图像变换上的关键点 一致性排序问题,优化后的排序在不同的变换下具 有重复性,其中关键点来自响应函数的顶/底部分位 数。Quad-networks 的训练过程如图所示,在两幅 图像中提取随机旋转像块对( 1,3) 和( 2,4) ; 每个块 经过神经网络输出一个实值响应 H( p w) ,其中 p 表示点,w 表示参数向量; 通过四元组的排序一致 函数计算铰链损失,并通过梯度下降法优化。Quadnetworks 在 RGB/RGB模式和RGB/深度模式的重复检测性能均优于 DOG,可以和基于学习的描述符 相结合进行图像匹配,还可用于视频中的兴趣帧检测。
3.2 深度学习特征描述符学习
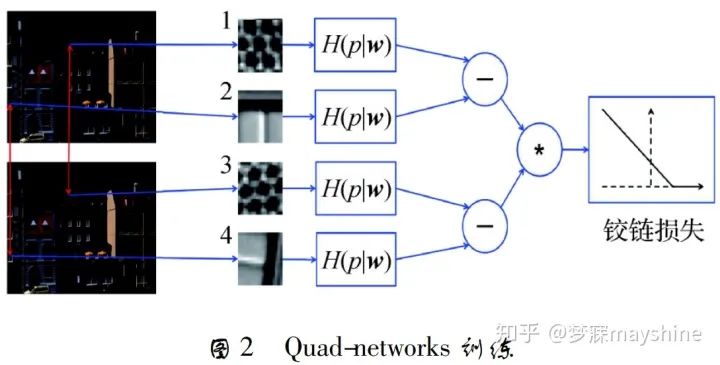
- 用于特征点描述符判别学习的 DeepDesc【19】:Simo-Serra 等人提出,该方法采用 Siamese 网络侧重训练难以区分 类别的样本,输入图像块对,将 CNN 输出的非线性 映射作为描述符,采用欧氏距离计算相似性并最小 化其铰链损失。该方法适用于不同的数据集和应 用,包括宽基线图像匹配、非刚性变形和极端光照变 化的情况,但该方法需要大量的训练数据来保证其鲁棒性。
3.3 深度学习各阶段统一
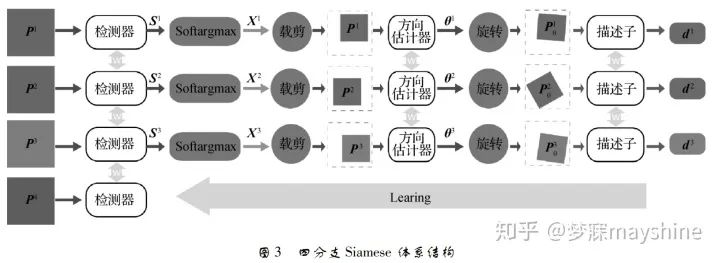
- Yi 等人提出【20】:基于学习的不变特征变换( LIFT) 结合空间变换网络【21】和 Softargmax 函数,将基于深度学习的特征点检测【16】、基于深度学习的方向估计【22】和基于深度 学习的描述符【19】连接成一个统一网络,从而实现完 整特征点匹配处理流水线。其中图像块的裁剪和旋 转通过空间变换网络实现,训练阶段采用四分支 Siamese 网络,输入特征点所在图像块, 其位置和方向均来自 SFM 算法的输出,其中 P1 和 P2 为同一3D 点在不同视角下的图像,P3 为不同3D 点的投影的图像块,P4 为不包含任何特征点的图像 快,S 为得分图,x 代表特征点位置。采用从后至前 的训练策略,即先训练描述子,再训练方向估计,最 后训练特征点检测。测试阶段,将特征点检测与方 向估计及描述子分开,使优化问题易于处理。LIFT 方法的输入为多尺度图像,以滑窗形式进行特征点 检测,提取局部块逐个分配方向,再计算描述子。与 SIFT 相比,LIFT 能够提取出更为稠密的特征点,且 对光照和季节变化具有很高的鲁棒性。
3.4 不同对象或场景的匹配方法研究( 图像语义匹配):
与考虑在时间( 光流) 或空间( 立体) 相邻的图像特 征对应不同,语义对应的特征是图像具有相似的高 层结构,而其精确的外观和几何形状可能不同。
3.4.1 相同对象类的像对匹配
- 经 典 SIFT 流方法【23】: 提出不同场景的稠密对应概念, 通过平滑约束和小位移先验计算不同场景间的稠密 对应关系。
- Bristow 等人【24】: 将语义对应问题转化为 约束检测问题,并提出 Examplar-LDA( Examplar linear discriminant analysis) 分类器。首先对匹配图像 中的每个像素学习一个 Examplar-LDA 分类器,然后 以滑动窗口形式将其应用到目标图像,并将所有分 类器上的匹配响应与附加的平滑先验结合,从而获 得稠密的对应估计。该方法改善了语义流的性能,在背景杂乱的场景下具有较强鲁棒性。
3.4.2 不同对象类的像对匹配
- Novotny 等人【25】: 提出基于几何敏感特征的弱监督学习方法 AnchorNet。在只有图像级标签的监督下,AnchorNet 依赖一组从残差超列 HC( hypercolumns) 中提取具 有正交响应的多样过滤器,该过滤器在同一类别的 不同实例或两个相似类别之间具有几何一致性。AnchorNet 通 过 在 ILSVRC12 ( imagenet large scale visual recognition competition 2012) 上预先训练的深 度残差网络( ResNet50) 模型初始化网络参数,并采 用两阶段优化与加速训练完成匹配。
3.4.3 多图像语义匹配
可以找到多个图像间的一致对应关系,从而在应用中发挥更为重要的作用
- 对象类模型重建【26】
- 自动地标注释【27】
- Wang 等人【28】: 将多图像间的语义匹 配问题转化为特征选择与标注问题,即从每幅图像 的初始候选集中选择一组稀疏特征点,通过分配标 签建立它们在图像间的对应关系。该方法可以为满 足循环一致性和几何一致性的图像集合建立可靠的 特征对应关系,其中循环一致性可以对图像集合中 的可重复特征进行选择和匹配。低秩约束用于确保 特征对应的几何一致性,并可同时对循环一致性和 几何一致性进行优化。该方法具有高度可扩展性, 可以对数千幅图像进行匹配,适用于在不使用任何 注释的情况下重构对象类模型。
3.5 图像匹配应用于临床的精确诊疗
通过精确比对器官的几何形状,来判断脏器是否存在病变; 通过分析肿瘤的几何特征,来判断肿瘤是否为恶性。
- Yu 等人[29]提 出 A-NSIFT( accelerated multi-dimensional scale invariant feature transform) 与 PO-GMMREG( parallel optimization based on gaussian mixture model registration) 相结合的方法,改进了特征提取和匹配过程。ANSIFT 为加速版 NSIFT,采用 CUDA 编程加速 NSIFT 的前两个步骤,用于提取匹配图像和待匹配图像中 的特征点( 仅保留位置信息) 。PO-GMMREG 是基 于并行优化的高斯混合模型( GMM) 匹配算法,并行 优化使得匹配图像和待匹配图像可以任意旋转角度 对齐。该方法可以减少时间消耗,提高大姿态差异 下的匹配精度。
- TV-L1 ( total variation-L1 ) 光流模型[30] 能有效地保 持图像边缘等特征信息,但对于保持具有弱导数性 质的纹理细节信息仍不够理想。
- 张桂梅等人[31]将 G-L ( Grünwald-Letnikov ) 分 数 阶 微 分 理 论 引 入 TV-L1 光流模型,代替其中的一阶微分,提出分数阶 TV-L1 光流场模型 FTV-L1 ( fractional TV-L1 ) 。同 时给出匹配精度和 G-L 分数阶模板参数之间关系, 为最佳模板选取提供依据。FTV-L1 模型通过全变分 能量方程的对偶形式进行极小化以获得位移场,可 以解决图像灰度均匀,弱纹理区域匹配结果中的信 息模糊问题。该方法能有效提高图像匹配精度,适合于包含较多弱纹理和弱边缘信息的医学图像匹配。
- 为了解决待匹配图像对中目标的大形变和灰度 分布呈各向异性问题,陆雪松等人[32]将两幅图像的 联合 Renyi α -entropy 引入多维特征度量并结合全 局和局部特征,从而实现非刚性匹配。首先,采用最 小距离树构造联合 Renyi α -entropy 度量准则; 其 次,根据该度量相对形变模型 FFD( free-form deformation) 的梯度解析表达式,采用随机梯度下降法进 行优化; 最后,将图像的 Canny 特征和梯度方向特征 融入度量中,实现全局和局部特征的结合。该方法 的匹配精度与传统互信息法和互相关系数法相比有 明显提高,且新度量方法能克服因图像局部灰度分 布不一致造成的影响,能够在一定程度上减少误 匹配。
- Yang 等人[33] 提出的 FMLND( feature matching with learned nonlinear descriptors) 采用基于学习的局 部非线性描述符 LND 进行特征匹配,对来自 T1w 和 T2w 两种不同成像参数的磁共振成像( MRI) 数据的 CT( computed tomography) 图像进行预测。该过程分 为两个阶段: 学习非线性描述符和预测 pCT( pseudo CT) 图像。第 1 阶段,首先采用稠密 SIFT 提取 MR 图像的特征; 其次通过显式特征映射将其投影到高 维空间并与原始块强度结合,作为初始非线性描述 符; 最后在基于改进的描述符学习( SDL) 框架中学 习包含监督的 CT 信息的局部描述符。第 2 阶段, 在训练 MR 图像的约束空间内搜索输入 MR 图像 的局部描述符的 K 最近邻域,和对应原始 CT 块进 行映射,对重叠的 CT 块进行加权平均处理得到最 终的 pCT 块。与仅使用成像参数 T1w 或 T2w 的 MR 图像方法相比,FMLND 方法提高了预测的准 确率。
- 对骨盆CT和MRI匹配可以促进前列腺癌放射治疗两种方式的有效融合。由于骨盆器官的模态外 观间隙较大,形状/外观变化程度高,导致匹配困难。基于此,Cao 等人【34】提出基于双向图像合成的区域 自适应变形匹配方法,用于多模态骨盆图像的匹配, 双向图 像 合 成,即 从MRI合 成CT并 从CT合 成MRI。多目标回归森林 MT-RF 采用CT模式和MRI模式对方向图像合成进行联合监督学习,消除模态 之间的外观差异,同时保留丰富的解剖细节,其匹配 流程为: 首先,通过 MT-RF 合成双向图像,获得实际CT和合成CT( S-CT) 的CT像对以及实际MRI和合成 MRI( S-MRI) 的 MRI 像对; 其次,对CT像对的骨骼区域和 MRI像对的软组织区域进行检测,以结合 两种模式中的解剖细节; 最后,利用从两种模式中选 择的特征点进行对称匹配。在匹配过程中,特征点 数量逐渐增加,对形变场的对称估计起到较好的分 级指导作用。该方法能够较好地解决骨盆图像匹配 问题,具有较高的准确性和鲁棒性。
3.6 图像匹配应用于遥感图像处理-高分辨率
- 何梦梦等人【35】 对细节纹理信息丰富的高分辨率光学及 SAR( synthetic aperture radar) 遥感图像进行分析,提出一种特征 级高分辨率遥感图像快速自动匹配方法。该方法首 先对匹配图像和待匹配图像进行 Harr 小波变换,将 其变换到低频近似图像再进行后续处理,以提高图 像匹配速度; 接着对光学图像和 SAR 图像分别采用 Canny 算子和 ROA( ratio of averages) 算子进行边缘 特征提取,并将边缘线特征转换成点特征; 而后通过 匹配图像和待匹配图像中每对特征点之间的最小和 次小角度之比确定初始匹配点对,并通过对随机抽 样一致性算法( RANSAC) 添加约束条件来滤除错误 匹配点对; 最后采用分块均匀提取匹配点对的方法, 进一步提高匹配精度。该方法能快速实现并具有较 高的配准精度和较好的鲁棒性。
3.7 剔除误差匹配
3.7.1 几何约束为参数的情况,如要求相应点位于极线上
- Fischler 等 人[36]提出 RANSAC 方法,采用迭代方式从包含离群 数据的数据集中估算出数学模型。进行匹配点对的 提纯步骤为: 1) 从已匹配的特征点对数据集中随机 抽取四对不共线的点,计算单应性矩阵 H,记作模型 M; 2) 设定一个阈值 t,若数据集中特征点与 M 之间 的投影误差小于 t,就把该点加入内点集,重复以上 步骤,迭代结束后对应内点数量最多的情况即为最 优匹配。RANSAC 对误匹配点的剔除依赖单应性矩 阵的计算,存在计算量大、效率低等问题。
- 文献[37] 通过引入针对内点和外点的混合概 率模 型 实 现 了 参 数 模 型 的最大似然估计。
- 文献[38] 使用支持向量回归学习的对应函数,该函 数将一幅图像中的点映射到另一幅图像中的对应点, 再通过检验它们是否与对应函数一致来剔除异常值。
- 将点对应关系通过图匹配进行描述[39-40]
- 为了在不依赖 RANSAC 情况下恢复大量内点,Lin 等人【41】提出 BF( bilateral functions) 方法,从含 有噪声的匹配中计算全局匹配的一致函数,进而分 离内点与外点。BF 从一组初始匹配结果开始,利用 每个匹配定义的局部仿射变换矩阵计算两幅图像之 间的仿射运动场。在给定运动场的情况下,BF 为每 个特征在描述符空间寻找最近邻匹配以恢复更多对 应关系。与 RANSAC 相比,双边运动模型具备更高 的查全率和查准率。
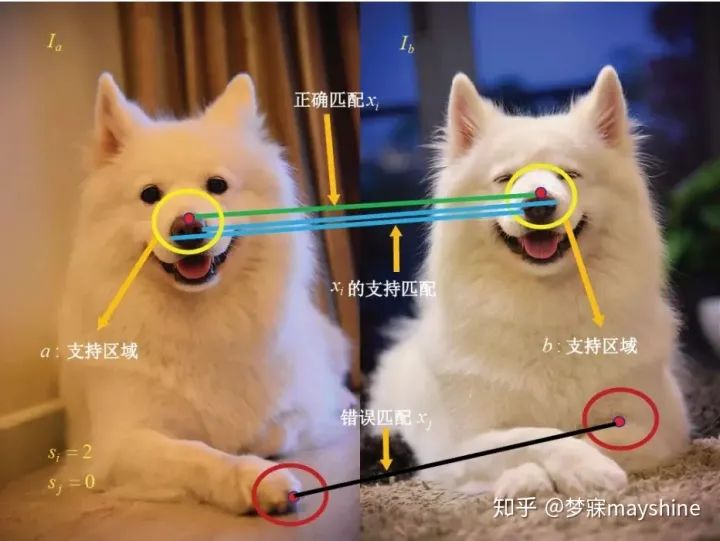
- 受 BF 启发,Bian 等人【42】将运动平滑度作为统计量,提出基于网格的运动统计( GMS) 方法,根据 最近邻匹配数量区分正确匹配和错误匹配点对。GMS 算法的核心为运动统计模型,如图 4 所示。其 中,si 和 sj 分别表示正确匹配 xi 和错误匹配 xj 的运 动统计,为了加速这一过程,可将整幅图像划分成 G = 20 × 20 的网格,并在网格中进行操作。由于 GMS 算法在进行网格划分时,并未考虑图像大小, 对于长宽比例不一致的图像,会生成矩形状的网格, 导致网格中特征分布不均。基于此,文献[43]通过 计算五宫格特征分数剔除外点,并将图像大小作为 约束对图像进行方形网格划分,能够在提高运算速 度的同时获得与 GMS 算法相同的匹配精度。
3.7.2 几何约束为非参数
- Ma 等人[44]提出 VFC( vector field consensus) 方法,利用向量场的光滑先验,从带有外点的样本中寻找向量场的鲁棒估计。向量场的光滑 性由再生核希尔伯特空间( RKHS) 【45】范数表征,VFC 算法基于这一先验理论,使用贝叶斯模型的最 大后验( MAP) 计算匹配是否正确,最后使用 EM 算法将后验概率最大化。VFC 算法的适用范围: 1) 误匹配比例高的时候( 遥感图像、红外图像和异质图像) ; 2) 无法提供变换模型的时候( 如非刚性变形、 相机参数未知) ; 3) 需要一个快速匹配算法且不需要求解变换参数的时候。
3维图像常用的表现形式包括: 深度图( 以灰 度表达物体与相机的距离) 、几何模型( 由 CAD 软 件建立) 、点云模型( 所有逆向工程设备都将物体采 样成点云) ,3 维点匹配算法中常见的是基于点云模 型的和基于深度模型的。点云模型中的每个点对应 一个测量点,包含了最大的信息量。
1.特征检测
- PointNet【46】 可以直接将 3D 点云作为输入,其改进版 PointNet++【47】能更好地提取局部信息。3 维局部描述符在 3 维视 觉中发挥重要作用,是解决对应估计、匹配、目标检 测和形状检索等的前提,广泛应用在机器人技术、导 航( SVM) 和场景重建中。点云匹配中的 3 维几何 描述符一直是该领域的研究热点,这种描述符主要 依赖 3 维局部几何信息。
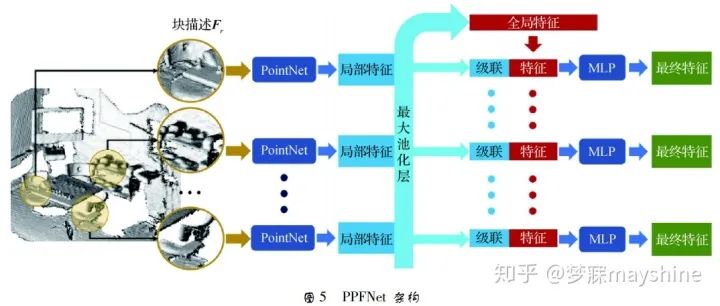
- Deng 等人[48]提出具有全局感知的局部特征提取网络 PPFNet ( point pair feature network) 。PPFNet 结构如图 5 所示。块描述 Fr 由点对特征( PPF) 集合、局部邻域内的点及法线 构成,首先采用 PointNet 处理每个区域块,得到局部 特征; 其次通过最大池化层将各个块的局部特征聚 合为全局特征,将截然不同的局部信息汇总到整个 片段的全局背景中; 最后将该全局特征连接到每个 局部特征,使用一组多层感知机( MLP) 进一步将全 局和局部特征融合到最终全局背景感知的局部描述 符中。PPFNet 在几何空间上学习局部描述符,具有 排列不变性,且能充分利用原始点云的稀疏性,提高 了召回率,对点云的密度变化有更好的鲁棒性。但 其内存使用空间与块数的 2 次方成正比,限制了块 的数量,目前只能设置为 2 K。
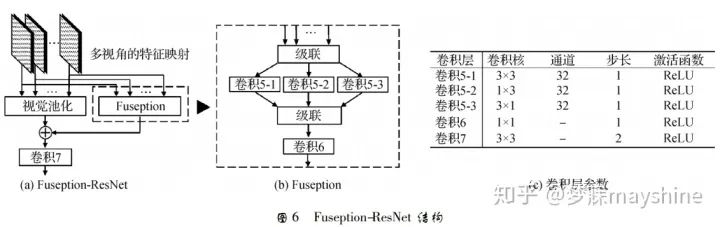
- 在基于深度模型的匹配算法中,Zhou 等人【49】基于多视图融合技术 Fuseption-ResNet(FRN) ,提出 多视图描述符 MVDesc。FRN 能将多视图特征映射 集成到单视图上表示,如图 6 所示。其中,视图池化 ( view pooling) 用于快捷连接,Fuseption 分支负责学 习残差映射,两个分支在精度和收敛率方面互相加强。采用 3 × 3、1 × 3 和 3 × 1 3 种不同内核尺寸的 轻量级空间滤波器提取不同类型的特征,并采用上 述级联特征映射的 1 × 1 卷积负责跨通道统计量的合并与降维。将 FRN 置于多个并行特征网络之上, 并建立 MVDesc 的学习网络,其中卷积 6 的通道数 与特征网络输出的特征映射通道数相同。
- 与依 赖多视图图像或需要提取固有形状特征的卷积神经网络不同,Wang 等人[50]提出一种可以根据 3 维曲面形状生成局部描述符的网络框架。该方法将关键点的邻域进行多尺度量化并参数化为 2 维网格,并 将其称之为几何图像,描述符的训练过程如下: 首先 提取曲面上关键点邻域的多尺度局部块,根据这些块构造一组几何图像; 其次将这些块输入 Triplet 网 络,每个网络分支采用 ConvNet ( convolutional networks) 训练; 最后输出 128 维描述符,并采用 MinCV Triplet 损失函数最小化锚样本和正样本距离的变异系数( CV) 之比。相对于其他局部描述符学习方法,该方法具有更好的可区分性、鲁棒性及泛化 能力。
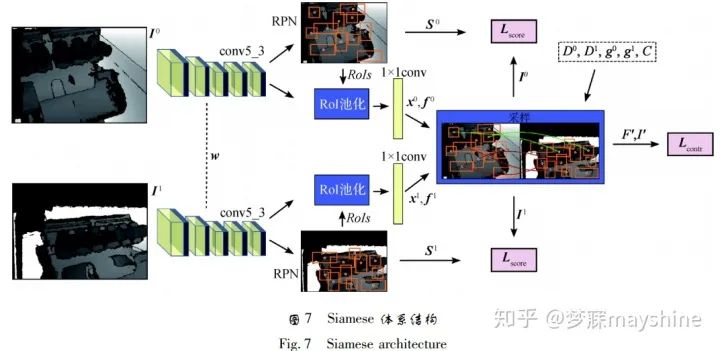
- Georgakis 等人[51]提出用于特征点检测和描述符学习的端到端框架。 该框架基于 Siamese 体系结 构,每个分支都是一个改进的 Faster R-CNN[52]。如 图 7 所示,采用 VGG-16 的卷积层 cov5_3 提取深度图I的深度卷积特征,一方面经过RPN( region propose network) 处理,产生特征点的候选区域( 橙色区域) 及分数 S ; 另一方面输入到 RoI( region of interest) 池化层,经过全连接层将特征点候选区域映射 到对应卷积特征 f 上; 采样层以候选区域的质心 x、 卷积特征 f 、深度图像值 D、相机姿态信息 g 和相机 内在参数作为输入,动态生成局部块对应标签( 正 或负) ,并采用对比损失函数 Lcontr 最小化正样本对间的特征距离,最大化负样本对间的距离,该方法对视角变化具有一定的鲁棒性。
2. 误差剔除
- 采用基于图模型的3维误匹配点剔除方法RMBP( robust matching using belief propagation) 。该模型可以描述匹配对之间的相 邻关系,并通过置信传播对每个匹配对进行推断验 证,从而提高 3 维点匹配的准确性和鲁棒性。
研究直线匹配首先要克服线特征本身存在的一 些问题,如端点位置不准确、图像边缘特征不明显、 线段碎片问题等,与点特征相比,线特征包含更多场 景和对象的结构信息。线特征匹配方法可以大致分 为 3 种: 基于单线段匹配方法、基于线段组方法和基于共面线—点不变量( LP) 方法。
1.基于单线段匹配
- Wang 等人[53]提出 的 MSLD( mean standard deviation line descriptor) 方 法通过统计像素支持区域内每个子区域 4 个方向的 梯度向量构建描述子矩阵,进而提高描述符的鲁棒 性。MSLD 对具有适当变化的纹理图像有较好的匹 配效果,可以应用在 3 维重建和目标识别等领域。为了解决 MSLD 对尺度变化敏感问题,文献[54]将 区域仿射变换和 MSLD 相结合,利用核线约束确定 匹配图像对应的同名支持域,并对该支持域进行仿 射变换以统一该区域大小,实现不同尺度图像上直 线的可靠匹配。
- 与 MSLD 相似,Zhang 等人[55]提出 线带描述符( LBD) ,在线支持区域( LSR) 中计算描 述符,同时利用直线的局部外观和几何特性,通过成 对几何一致评估提高对低纹理图像直线匹配的精确 度。该方法可在不同尺度空间中检测线段,能够克 服线段碎片问题,提高抗大尺度变化的鲁棒性。
2.基于线段组方法
- 当像对间旋转角度过大时,单线段匹配方法的匹配准确率不高,可以采用线段组匹配方法通过更多的几何信息解决这一问题。Wang 等人[56]基于线段局部聚类的方式提出半局部特征 LS( line signature) ,用于宽基线像对匹配,并采用多尺度方案提 高尺度变化下的鲁棒性。
- 为了提高在光照不受控制 情况下对低纹理图像的匹配准确度,López 等人[57] 将直线的几何特性、局部外观及线邻域结构上下文 相结合,提出双视图( two-view) 直线匹配算法 CA。首先对线特征进行检测: 1) 在高斯尺度空间利用基 于相位的边缘检测器提取特征; 2) 根据连续性准则 将边缘特征局部区域近似为线段; 3) 在尺度空间进 行线段融合。其次,该方法中的相位一致性对于图 像亮度和对比度具有较高不变性,线段融合可以减 少重叠线段以及线段碎片出现。最后,线特征匹配 采用迭代方式进行,通过不同直线邻域的局部结构 信息来增强每次迭代的匹配线集,该方法适用于低 纹理图像中线特征的检测与匹配。
基于线段组匹配方法对线段端点有高度依赖性,图像变换及部分遮挡可能导致端点位置不准确, 进而影响匹配效果。
3.基于共面线—点不变量( LP) 方法
- Fan 等人[58-59]利用线及其邻域点的局部几何信息构造共面线—点不变量( LP) 用 于线匹配。 LP 包括: “一线 + 两点”构成的仿射不 变量和“一线 + 四点”构成的投影不变量。该投影 不变量和“两线 + 两点”构成的投影不变量[60] 相 比,可以直接用于线匹配而无需复杂的组合优化。根据直线的梯度方向,将线邻域分为左邻域和右邻 域( 线梯度方向) ,以获得左右邻域内与线共面的匹 配点,进行线相似性度量时,取左右邻域相似性的最大值。
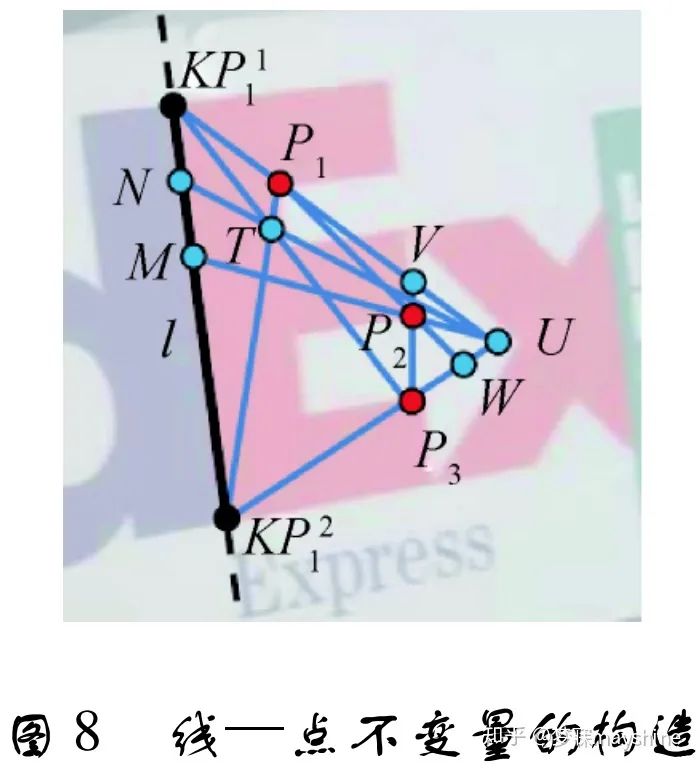
- 该方法对误匹配点和图像变换具有鲁棒性, 但高度依赖匹配关键点的准确性。为此,Jia 等 人[61]基于特征数 CN[62]提出一种新的共面线—点 投影不变量。CN 对交叉比进行扩展,采用线上点 和线外点描述基础几何结构。通过“五 点”构 造 线—点不变量,其中两点位于直线上,另外三点位于 直线同一侧但不共线,如图 8 所示。点 KP1 l ,KP2 l , P1 ,P2 ,P3 用于构造该不变量,通过两点连线可以 获得其他特征点。计算直线邻域相似性时,把线邻 域按照线梯度方向分为左邻域和右邻域( 梯度方 向) ,根据线点不变量分别计算左、右邻域的相似 性。这种相似性度量方法受匹配特征点的影响较 小。该方法对于低纹理和宽基线图像的线匹配效果 要优于其他线匹配算法,对于很多图像失真也有较 好鲁棒性。由于该线—点不变量是共面的,对于非平面场景图像的处理具有局限性。
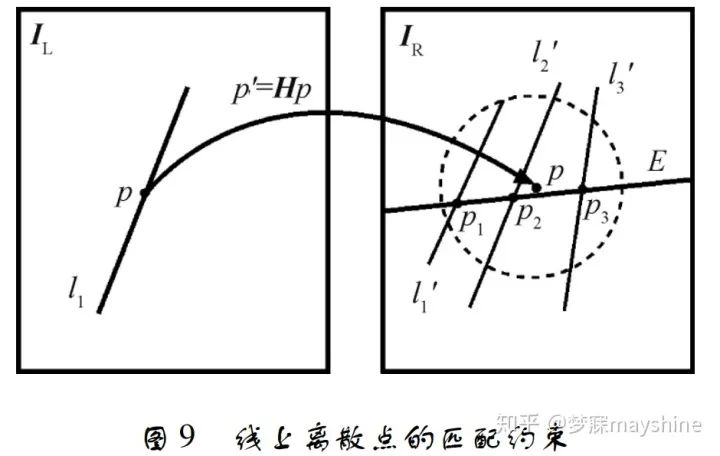
- 对航空影像进行线匹配时,线特征通常会出现遮挡、变形及断裂等情况,使得基于形态的全局描述 符不再适用。基于此,欧阳欢等人[63]联合点特征匹 配优势,通过对线特征进行离散化描述并结合同名 点约束实现航空影像线特征匹配。 线特征离散化, 即将线看做离散点,通过统计线上同名点的分布情 况来确定线特征的初匹配结果,最后利用点线之间 距离关系对匹配结果进行核验。同名点约束包括单 应性约束和核线约束,单应性约束实现线特征之间 的位置约束,核线约束将匹配搜索空间从 2 维降至 1 维。线上离散点的匹配约束如图 9 所示,IL 为目 标影像,l1 为目标线特征,p 为其上一点; IR 为待匹 配影像,线 E 代表 p 所对应核线,p' 为 p 由单应性矩 阵映射得到的对应点,虚线圆为单应性矩阵的约束 范围,l'1 、l'2 、l'3 是由约束确定的候选线特征,点 p1、p2 、p3 为 p 的候选同名点。该算法匹配正确率 高,匹配速度相对较快,可实现断裂线特征的多对多匹配,但匹配可靠性仍受到点特征匹配的影响,对于 难以获得初始同名点的区域,其适用性不高。
Part4:区域匹配
1.区域特征提取与匹配方法
区域特征具有较高的不变性与稳定性,在多数图像中可以重复检测,与其他检测器具有一定互补性,被广泛应用于图像识别、图像检索、图像拼接、3 维重建、机器人导航等领域。
- Matas 等人[64]于 2002 年提 出最大稳定极值区域( MSER) 采用分水岭方法,通 过对灰度图像取不同阈值分割得到一组二值图,再 分析相邻二值图像的连通区域获得稳定区域特征。经典 MSER 算法具有较高的时间复杂度。
- Nistér 等 人[65]基于改进的分水岭技术提出一种线性计算 MSER 的算法,该算法基于像素的不同计算顺序,获 得与图像中存在灰度级数量相同的像素分量信息, 并通过组件树表示对应灰度级。MSER 这类方法可 用于图像斑点区域检测及文本定位,也可与其他检 测器结合使用,如文献[66]将 SURF 和 MSER 及颜 色特征相结合用于图像检索,文献[67]将 MSER 与 SIFT 结合用于特征检测。
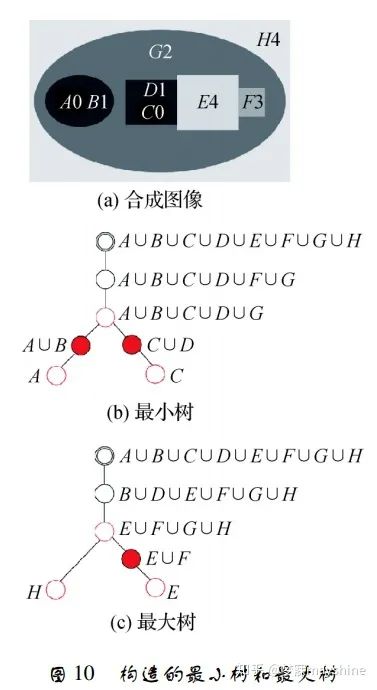
- 区域特征检测还可利用计算机技术中的树理论 进行稳定特征提取,Xu 等人[68]提出一种基于该理 论的拓扑方法 TBMR( tree-based Morse regions) 。该 方法以 Morse 理论为基础定义临界点: 最大值点、最小值点和鞍点,分别对应最大树叶子节点、最小树叶 子节点和分叉节点。TBMR 区域对应树中具有唯一 子节点和至少具有一个兄弟节点的节点。如图 10 所示,节点 A 和 C 代表最小值区域; 节点 H 和 E 代 表最大值区域; 节点 A ∪ B ∪ C ∪ D ∪ G 和 E ∪ F ∪ G ∪ H 表示鞍点区域; 节点 A ∪ B 、C ∪ D 、E ∪ F 为所求 TBMR 区域。该方法仅依赖拓扑信息,完全继承形状空间不变性,对视角变化具有鲁棒性,计算 速度快,与 MSER 具有相同复杂度,常用于图像配准 和 3 维重建。
2. 模板匹配:
模板匹配是指给定一个模板( 通常是一块小图像区域) ,在目标图像中寻找与模板对应区域的方法,被广泛应用于目标跟踪、目标检测及图像拼接等领域。
模板和目标图像子窗口间的相似性度量是模板 匹配的主要部分,常采用逐像素比较的计算方式,如 上述方法采用的 SAD、CSAD 和 SV-NCC,此外还有 差值平方和 SSD 等,这些方法在图像背景杂乱或发 生复杂形变的情况下不再适用。
- Korman 等人[69]提出可以处理任意仿射变换的模板匹配算法 FAST-Match ( fast affine template matching) ,该方法首先将彩色图像灰度化,再构建 仿射变换集合,并遍历所有可能的仿射变换,最后计 算模板与变换后区域之间绝对差值的和 SAD,求取 最小值作为最佳匹配位置。该方法能够找到全局最 优匹配位置,但对彩色图像匹配时,需预先转换成灰 度图像,而这一过程损失了彩色空间信息,降低了图像匹配的准确率。
- Jia 等人[70]将灰度空间的 SAD 拓 展到 RGB 空间形成 CSAD( colour SAD) ,提出适合 彩色 图 像 的 模 板 匹 配 算 法 CFAST-Match ( colour FAST match) 。该方法通过矢量密度聚类算法计算 每个像素点所属类别,并统计同类像素个数及 RGB 各通道的累计值,以此求解每个分类的矢量中心,将 矢量中心作为 CSAD 的判定条件,同类像素个数的 倒数作为分值系数,以此建立新的相似性度量机制。
- 上方法对存在明显色差的区域具有较高匹配精度, 但部分参数依据经验设置,且不适合处理大尺寸图 像。为了解决这一问题,文献[71]提出一种基于分值图的模板匹配算法。该方法依据彩色图像的多通道特征,采用抽样矢量归一化互相关方法 ( SVNCC) 度量两幅图像间的区域一致性,以降低光照和噪声影响。
- Dekel 等人[72-73]基 于模板与目标图像间的最近邻( NN) 匹配属性提出 一种新的 BBS( best-buddies similarity) 度量方法,采 用不同图像特征( 如颜色、深度) 通过滑动窗口方式 统计模板点与目标点互为 NN 的匹配数量,并将匹 配数量最多的窗口视为最终匹配位置。但该算法在 发生剧烈非刚性形变或处于大面积遮挡及非均匀光 照等环境下匹配鲁棒性差。文献[74]利用曼哈顿 距离代替 BBS 算法中的欧氏距离,并对生成的置信 图进行阈值筛选和滤波,能够较好地解决光照不均 匀、模板中外点较多与旋转变形等多种复杂条件下 的匹配问题。
- 采用双向 NN 匹配导致 BBS 的计算时间较长, Talmi 等人[75]提出基于单向 NN 匹配的 DDIS ( deformable diversity similarity) 方法。首先计算目标图 像窗口点在模板中的 NN 匹配点,并统计对应同一 匹配点的数量,计算像素点的置信度。其次采用欧 氏距离计算目标点和对应 NN 匹配点间距离,最后 结合度量模板和目标图像窗口间的相似性获得匹配 结果。尽管 DDIS 降低了算法复杂度并提高了检测 精度,但当形变程度较大时依然会影响匹配效果。
- 由于 DDIS 对每个滑动窗口单独计算 NN 匹配且滑 动窗口的计算效率较低,导致模板在与较大尺寸的 目标图像进行匹配时,处理时间较长。为此,Talker 等人[76]基于单向 NN 匹配提出 DIWU( deformable image weighted unpopularity) 方法。与 DDIS 基于目 标图像窗口点不同,DIWU 计算整幅目标图像点在 模板中的最近邻匹配点,若多个像素的 NN 匹配点 相同,则像素的置信分数就低,匹配的正确性就低。DIWU 以第 1 个图像窗口的分数为基础,逐步计算 之后的每个窗口分数,该方法在保证匹配准确性的同时,提高了运算速度,使得基于 NN 的模板匹配适合实际应用。
- BBS 和 DDIS 均采用计算矩形块间的相似性度量解决几何形变和部分遮挡问题,但滑动窗口的使 用限制了遮挡程度。Korman 等人[77]基于一致集最 大化( CSM) 提出适用于存在高度遮挡情况下的模 板匹配算法 OATM ( occlusion aware template matching) 。OATM 通过约简方法,将单个向量和 N 个目 标向量间的匹配问题转化为两组 槡N 向量间的匹配 问题,并基于随机网格哈希算法进行匹配搜索。匹 配搜索的过程为寻找 CSM 的过程,即使用阈值内的 残差映射进行变换搜索。OATM 提高了算法的处理 速度,较好地解决了遮挡问题。
- 与基于欧氏距离的像素间的相似性不同,共现 统计( cooccurrence statistics) 是从数据中学习像素间 的相似性。Kat 等人[78]通过统计模板点和目标点在 目标图像窗口共同出现的概率提出 CoTM( cooccurrence based template matching) 。CoTM 在处理彩色 图时,采用 k-means 聚类算法将图像量化为 k 个类 簇,根据共现矩阵统计模板和目标图像中的类簇对 在目标图像中共同出现的次数,再基于每个类簇的 先验概率进行归一化,构造点互信息( PMI) 矩阵,值 越大表明共现概率越高,误匹配率越低。最后根据 PMI 计算模板类簇中的像素和目标图像窗口中包含 的类簇中的像素之间的相关性,选出最佳匹配位置。CoTM 也适用于颜色特征之外的其他特征,如深度 特征,可将共现统计( 捕获全局统计) 与深度特征 ( 捕获局部统计数据) 相结合,在基于标准数据集的 模板匹配中提升匹配效果。
3. 深度学习方法-块匹配:
近年来,基于深度学习的图像区域匹配成为研 究热点,卷积神经网络( CNN) 在局部图像区域匹配的应用中,根据是否存在度量层可以分为两类:
第一 类为具有度量层的方法,这类网络通常把图像块对 匹配问题视为二分类问题。
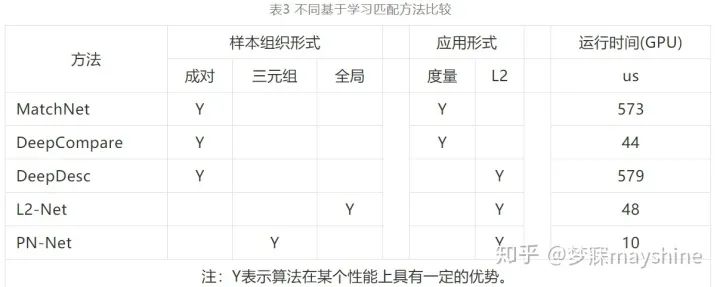
- Han 等 人[79] 提出 的 MatchNet 通过 CNN 进行图像区域特征提取和相似 性度量,过程如图 11 所示。对于每个输入图像块, 特征网络输出一个固定维度特征,预处理层的输入 为灰度图像块,起到归一化作用。卷积层激活函数 为 ReLU,瓶颈( bottlebeck) 层为全连接层,能够降低 特征维度并防止网络过拟合。采用 3 个全连接层组 成的度量网络计算特征对的匹配分数,双塔结构在 监督环境下联合训练特征网络和度量网络。
- Zagoruyko 等人[80] 提出 DeepCompare 方法,通 过 CNN 比较灰度图像块对的相似性。该方法对基 础网络框架 Siamese、pseudo-Siamese 和 2 通道( 2ch) 进行描述,并在此基础上采用深度网络、中心环绕双 流网络( central-surround two-stream,2stream) 和空间 金字塔池化( SPP) 网络提升基础框架性能。
- 为了提高卫星影像的配准率,范大昭等人[81]提 出基于空间尺度双通道深度卷积神经网络方法 ( BBS-2chDCNN) 。BBS-2chDCNN 是在双通道深度 卷积神经网络( 2chDCNN) 前端加入空间尺度卷积 层,以加强整体网络的抗尺度特性。2chDCNN 将待 匹配点对局部合成的两通道影像作为输入数据,依 次进行 4 次卷积、ReLU 操作、最大池化操作,3 次卷 积和 ReLU 操作,最后进行扁平化和两次全连接操 作输出一维标量结果。该方法适用于处理异源、多 时相、多分辨率的卫星影像,较传统匹配方法能提取 到更为丰富的同名点。
第二类方法不存在度量层,这类网络的输出即为特征描述符,在某些应用中可以直接代替传统描述符。
- Balntas 等人[82]提出的 PN-Net 采用 Triplet 网 络训练,训练过程如图 14 所示。图像块三元组 T = { p1,p2,n} ,包 括 正 样 本 对 ( p1,p2 ) 和 负 样 本 对 ( p1,n) 、( p2,n) ,采用 SoftPN 损失函数计算网络输 出描述子间相似性,以确保最小负样本对距离大于 正样本对距离。表 2 给出所采用的 CNN 体系结构 的参数,采用 32 × 32 像素的图像块作为输入,括号 内的数字表示卷积核大小,箭头后面的数字表示输 出通道数,Tanh 为激活函数。与其他特征描述符相 比,PN-Net 具有更高效的描述符提取及匹配性能, 能显著减少训练和执行时间。
- Yang 等人[83]提出用于图像块表示的一对互补 描述符学习框架 DeepCD。该方法采用 Triplet 网络 进行训练,输出主描述符( 实值描述符) 和辅描述符 ( 二值描述符) ,如图 15 所示,输入图像区域包括正 样本对 ( a,p) ,负样本对 ( a,n) 和 ( p,n) ,L 代表 主描述符,C 代表辅描述符,Δ 代表主描述符距离, Δ 珚代表辅描述符距离。数据相关调制层( DDM) 通过学习率的动态调整实现辅助描述符对主导描述符 的辅助作用。该方法能够有效地提高图像块描述符 在各种应用和变换中的性能。
- 以上这些方法都是对图像块对或三元组进行的 处理,Tian 等人[84]提出的 L2-Net 通过 CNN 在欧氏 空间将一批图像块转换成一批描述符,将批处理中 的最近邻作为正确匹配描述符。如图 16 所示,每个 卷积层左边数字代表卷积核大小,右边数字表示输 出通道数,2 表示下采样层的步长; 3 × 3 Conv 由卷 积、批归一化( BN) 和 ReLU( rectified linear unit) 组 成; 8 × 8 Conv 由卷积和批归一化( BN) 组成; 局部响应归一化层( LRN) 作为单元描述符的输出层,获 得 128 维描述符。CS L2-Net 由两个独立 L2-Net 级 联成双塔结构,左侧塔输入和 L2-Net 相同,右侧塔 输入是中心裁剪后的图像块。采用渐进式采样策 略,在参与训练的批样本中,从每对匹配样本中随机 抽取一个组成若干不匹配样本,增加负样本数量。与成对样本和三元组样本相比,能够利用更多负样 本信息。

 2维点匹配
2维点匹配TILDE
- https://cvlab.epfl.ch/research/tilde
协变特征检测[17]
- http://dvmmweb.cs.columbia.edu/files/3129.pdf
- https://github.com/ColumbiaDVMM/Transform_Covariant_Detector
DeepDesc
- http://icwww.epfl.ch/~trulls/pdf/iccv-2015-deepdesc.pdf
- https://github.com/etrulls/deepdesc-release
LIFT
- https://arxiv.org/pdf/1603.09114.pdf
- https://github.com/cvlab-epfl/LIFT
Quad-networks
- https://arxiv.org/pdf/1611.07571.pdfGMShttp://jwbian.net/gmsVFC
- http://www.escience.cn/people/jiayima/cxdm.html
PPFNet
- http://tbirdal.me/downloads/tolga-birdal-cvpr-2018-ppfnet.pdf
文献[51]
- http://cn.arxiv.org/pdf/1802.07869
文献[49]
- http://cn.arxiv.org/pdf/1807.05653
文献[50]
- http://openaccess.thecvf.com/content_ECCV_2018/papers/Hanyu_Wang_Learning_3D_Keypoint_ECCV_2018_paper.pdf
样本LDA分类器
- http://ci2cv.net/media/papers/2015_ICCV_Hilton.pdf
- https://github.com/hbristow/epic
AnchorNet
- http://openaccess.thecvf.com/content_cvpr_2017/papers/Novotny_AnchorNet_A_Weakly_CVPR_2017_paper.pdf
文献[28]
- http://cn.arxiv.org/pdf/1711.07641
LBD
- http://www.docin.com/p-1395717977.html
- https://github.com/mtamburrano/LBD_Descriptor
新线点投影不变量[61]
- https://github.com/dlut-dimt/LineMatching
FAST-Match
- http://www.eng.tau.ac.il/~simonk/FastMatch/
CFAST-Match
- https://wenku.baidu.com/view/3d96bf9127fff705cc1755270722192e453658a5.html
DDIS
- https://arxiv.org/abs/1612.02190
- https://github.com/roimehrez/DDIS
DIWU
- http://liortalker.wixsite.com/liortalker/code
CoTM
- http://openaccess.thecvf.com/content_cvpr_2018/CameraReady/2450.pdf
OATM
- http://cn.arxiv.org/pdf/1804.02638
MatchNet
- http://www.cs.unc.edu/~xufeng/cs/papers/cvpr15-matchnet.pdf
- https://github.com/hanxf/matchnet
DeepCompare
- http://imagine.enpc.fr/~zagoruys/publication/deepcompare/
PN-Net
- https://arxiv.org/abs/1601.05030
- https://github.com/vbalnt/pnnet
L2-Net
- http://www.nlpr.ia.ac.cn/fanbin/pub/L2-Net_CVPR17.pdf
- https://github.com/yuruntian/L2-Net
DeepCD
- https://www.csie.ntu.edu.tw/~cyy/publications/papers/Yang2017DLD.pdf
- https://github.com/shamangary/DeepCD
参考文献:
[1] Harris C,Stephens M. A combined corner and edge detector [C]/ /Proceedings of the 4th Alvey Vision Conference. Manchester: AVC,1988: 147-151. [DOI: 10. 5244 /C. 2. 23]
[2] Rosten E,Drummond T. Machine learning for high-speed corner detection[C]/ /Proceedings of the 9th European Conference on Computer Vision. Graz,Austria: Springer,2006: 430-443. [DOI: 10. 1007 /11744023_34]
[3] Lowe D G. Distinctive image features from scale-invariantkeypoints[J]. International Journal of Computer Vision,2004, 60( 2) : 91-110. [DOI: 10. 1023 /B: VISI. 0000029664. 99615. 94]
[4] Liu L,Zhan Y Y,Luo Y,et al. Summarization of the scale invariant feature transform[J]. Journal of Image and Graphics, 2013,18( 8) : 885-892. [刘立,詹茵茵,罗扬,等. 尺度不 变特征 变 换 算 子 综 述[J]. 中 国 图 象 图 形 学 报,2013, 18( 8) : 885-892.][DOI: 10. 11834 /jig. 20130801]
[5] Xu Y X,Chen F. Recent advances in local image descriptor[J]. Journal of Image and Graphics,2015,20( 9) : 1133-1150. [许 允喜,陈方. 局部图像描述符最新研究进展[J]. 中国图象 图形学报,2015,20( 9) : 1133-1150.][DOI: 10. 11834 /jig. 20150901]
[6] Zhang X H,Li B,Yang D. A novel Harris multi-scale corner detection algorithm[J]. Journal of Electronics and Information Technology,2007,29 ( 7) : 1735-1738. [张小 洪,李 博,杨 丹. 一种新的 Harris 多尺度角点检测[J]. 电子与信息学报, 2007,29 ( 7 ) : 1735-1738.] [DOI: 10. 3724 / SP. J. 1146. 2005. 01332]
[7] He H Q,Huang S X. Improved algorithm for Harris rapid subpixel corners detection[J]. Journal of Image and Graphics, 2012,17( 7) : 853-857. [何海清,黄声享. 改进的 Harris 亚 像素角点快速定位[J]. 中国图象图形学报,2012,17( 7) : 853-857.][DOI: 10. 11834 /jig. 20120715]
[8] Zhang L T,Huang X L,Lu L L,et al. Fast Harris corner detection based on gray difference and template[J]. Chinese Journal of Scientific Instrument,2018,39( 2) : 218-224. [张立亭,黄 晓浪,鹿琳琳,等. 基于灰度差分与模板的 Harris 角点检测 快速算法[J]. 仪器仪表学报,2018,39( 2) : 218-224.]
[9] Ke Y,Sukthankar R. PCA-SIFT: a more distinctive representation for local image descriptors[C]/ /Proceedings of 2004 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington,DC: IEEE,2004: 506-513. [DOI: 10. 1109 /CVPR. 2004. 1315206]
[10] Bay H,Tuytelaars T,Gool L. SURF: speeded up robust features [C]/ /Proceedings of the 9th European Conference on Computer Vision. Graz,Austria: Springer,2006: 404-417. [DOI: 10. 1007 /11744023_32]
[11] Liu L,Peng F Y,Zhao K,et al. Simplified SIFT algorithm for fast image matching[J]. Infrared and Laser Engineering,2008, 37( 1) : 181-184. [刘立,彭复员,赵坤,等. 采用简化 SIFT 算法实 现 快 速 图 像 匹 配[J]. 红外与激光工程,2008, 37( 1) : 181-184.][DOI: 10. 3969 /j. issn. 1007-2276. 2008. 01. 042]
[12] Abdel-Hakim A E,Farag A A. CSIFT: a SIFT descriptor with color invariant characteristics[C]/ /Proceedings of 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. New York,NY: IEEE,2006: 1978-1983. [DOI: 10. 1109 /CVPR. 2006. 95]
[13] Mikolajczyk K,Schmid C. A performance evaluation of local descriptors[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2005,27 ( 10 ) : 1615-1630. [DOI: 10. 1109 /TPAMI. 2005. 188]
[14] Morel J M,Yu G S. ASIFT: a new framework for fully affine invariant image comparison[J]. SIAM Journal on Imaging Sciences,2009,2( 2) : 438-469. [DOI: 10. 1137 /080732730]
[15] Rosten E,Porter R,Drummond T. Faster and better: a machine learning approach to corner detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence,2010,32( 1) : 105- 119. [DOI: 10. 1109 /TPAMI. 2008. 275]
[16] Verdie Y,Yi K M,Fua P,et al. TILDE: a temporally invariant learned DEtector[C]/ /Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston,MA: IEEE, 2015: 5279-5288. [DOI: 10. 1109 /CVPR. 2015. 7299165]
[17] Zhang X,Yu F X,Karaman S,et al. Learning discriminative and transformation covariant local feature detectors[C]/ /Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI: IEEE,2017: 4923-4931. [DOI: 10. 1109 /CVPR. 2017. 523]
[18] Savinov N,Seki A,Ladicky L,et al. Quad-networks: unsupervised learning to rank for interest point detection[C]/ /Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI: IEEE,2017: 3929-3937. [DOI: 10. 1109 /CVPR. 2017. 418]
[19] Simo-Serra E,Trulls E,Ferraz L,et al. Discriminative learning of deep convolutional feature point descriptors[C]/ /Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago,Chile: IEEE,2015: 118-126. [DOI: 10. 1109 / ICCV. 2015. 22]
[20] Yi K M,Trulls E,Lepetit V,et al. LIFT: learned invariant feature transform[C]/ /Proceedings of the 14th European Conference on Computer Vision. Amsterdam,The Netherlands: Springer,2016: 467-483. [DOI: 10. 1007 /978-3-319-46466-4_28]
[21] Jaderberg M,Simonyan K,Zisserman A,et al. Spatial transformer networks[C]/ /Proceedings of the 28th International Conference on Neural Information Processing Systems. Montreal, Canada: ACM,2015: 2017-2025.
[22] Yi K M,Verdie Y,Fua P,et al. Learning to assign orientations to feature points[C]/ /Proceedings of 2016 IEEE Conference on Computer Vision and Pattern Recognition. Las Vegas,NV: IEEE,2016: 107-116. [DOI: 10. 1109 /CVPR. 2016. 19]
[23] Liu C,Yuen J,Torralba A. SIFT flow: dense correspondence across scenes and its applications[J]. IEEE Transactions on Pattern Analysisand Machine Intelligence,2011,33( 5) : 978-994. [DOI: 10. 1109 /TPAMI. 2010. 147]
[24] Bristow H,Valmadre J,Lucey S. Dense semantic correspondence where every pixel is a classifier[C]/ /Proceedings of 2015 IEEE International Conference on Computer Vision. Santiago, Chile: IEEE,2015: 4024-4031. [DOI: 10. 1109 / ICCV. 2015. 458]
[25] Novotny D,Larlus D,Vedaldi A. AnchorNet: A weakly supervised network to learn geometry-sensitive features for semantic matching[C]/ /Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI: IEEE, 2017: 2867-2876. [DOI: 10. 1109 /CVPR. 2017. 306]
[26] Kar A,Tulsiani S,Carreira J,et al. Category-specific object reconstruction from a single image[C]/ /Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA: IEEE,2015: 1966-1974. [DOI: 10. 1109 /CVPR. 2015. 7298807]
[27] Thewlis J,Bilen H,Vedaldi A. Unsupervised learning of object landmarks by factorized spatial embeddings[C]/ /Proceedings of 2017 IEEE International Conference on Computer Vision. Venice,Italy: IEEE,2017: 3229-3238. [DOI: 10. 1109 / ICCV. 2017. 348]
[28] Wang Q Q,Zhou X W,Daniilidis K. Multi-image semantic matching by mining consistent features[C]/ /Proceedings of 2018 IEEE /CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT: IEEE,2018: 685-694. [DOI: 10. 1109 /CVPR. 2018. 00078]
[29] Yu D D,Yang F,Yang C Y,et al. Fast rotation-free featurebased image registration using improved N-SIFT and GMM-based parallel optimization[J]. IEEE Transactions on Biomedical Engineering,2016,63 ( 8) : 1653-1664. [DOI: 10. 1109 /TBME. 2015. 2465855]
[30] Pock T,Urschler M,Zach C,et al. A duality based algorithm for TV - L1 - optical-flow image registration[C]/ /Proceedings of the 10th International Conference on Medical Image Computing and Computer-Assisted Intervention. Brisbane,Australia: Springer, 2007: 511-518. [DOI: 10. 1007 /978-3-540-75759-7_62]
[31] Zhang G M,Sun X X,Liu J X,et al. Research on TV-L1 optical flow model for image registration based on fractional-order differentiation[J]. Acta Automatica Sinica,2017,43 ( 12) : 2213- 2224. [张桂梅,孙晓旭,刘建新,等. 基于分数阶微分的 TV-L1光流 模 型 的 图 像 配 准 方 法 研 究[J]. 自 动 化 学 报, 2017,43 ( 12 ) : 2213-2224.][DOI: 0. 16383 /j. aas. 2017. c160367]
[32] Lu X S,Tu S X,Zhang S. A metric method using multidimensional features for nonrigid registration of medical images[J]. Acta Automatica Sinica,2016,42( 9) : 1413-1420. [陆雪松, 涂圣贤,张素. 一种面向医学图像非刚性配准的多维特征度 量方法[J]. 自动化学报,2016,42( 9) : 1413-1420.][DOI: 10. 16383 /j. aas. 2016. c150608]
[33] Yang W,Zhong L M,Chen Y,et al. Predicting CT image from MRI data through feature matching with learned nonlinear local descriptors[J]. IEEE Transactions on Medical Imaging,2018, 37( 4) : 977-987. [DOI: 10. 1109 /TMI. 2018. 2790962]
[34] Cao X H,Yang J H,Gao Y Z,et al. Region-adaptive deformable registration of CT /MRI pelvic images via learning-based image synthesis[J]. IEEE Transactions on Image Processing, 2018,27 ( 7 ) : 3500-3512. [DOI: 10. 1109 /TIP. 2018. 2820424]
[35] He M M,Guo Q,Li A,et al. Automatic fast feature-level image registration for high-resolution remote sensing images[J]. Journal of Remote Sensing,2018,22( 2) : 277-292. [何梦梦,郭擎, 李安,等. 特征级高分辨率遥感图像快速自动配准[J]. 遥 感 学 报,2018,22 ( 2 ) : 277-292.] [DOI: 10. 11834 /jrs. 20186420]
[36] Fischler M A,Bolles R C. Random sample consensus: a paradigm for model fitting with applications to image analysis and automated cartography[J]. Communications of the ACM,1981, 24( 6) : 381-395. [DOI: 10. 1145 /358669. 358692]
[37] Torr P H S,Zisserman A. MLESAC: a new robust estimator with application to estimating image geometry[J]. Computer Vision and Image Understanding,2000,78( 1) : 138-156. [DOI: 10. 1006 /cviu. 1999. 0832]
[38] Li X R,Hu Z Y. Rejecting mismatches by correspondence function[J]. International Journal of Computer Vision,2010, 89( 1) : 1-17. [DOI: 10. 1007 / s11263-010-0318-x]
[39] Liu H R,Yan S C. Common visual pattern discovery via spatially coherent correspondences[C]/ /Proceedings of 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco,CA: IEEE,2010: 1609-1616. [DOI: 10. 1109 /CVPR. 2010. 5539780]
[40] Liu H R,Yan S C. Robust graph mode seeking by graph shift [C]/ /Proceedings of the 27th International Conference on International Conference on Machine Learning. Haifa,Israel: ACM, 2010: 671-678.
[41] Lin W Y D,Cheng M M,Lu J B,et al. Bilateral functions for global motion modeling[C]/ /Proceedings of the 13th European Conference on Computer Vision. Zurich,Switzerland: Springer, 2014: 341-356. [DOI: 10. 1007 /978-3-319-10593-2_23]
[42] Bian J W,Lin W Y,Matsushita Y,et al. GMS: grid-based motion statistics for fast,ultra-robust feature correspondence[C]/ / Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI: IEEE,2017: 2828-2837. [DOI: 10. 1109 /CVPR. 2017. 302]
[43] Chen F J,Han J,Wang Z W,et al. Image registration algorithm based on improved GMS and weighted projection transformation [J]. Laser & Optoelectronics Progress,2018,55 ( 11 ) : 111006. [陈方杰,韩军,王祖武,等. 基于改进 GMS 和加权 投影变换的图像配准算法[J]. 激光与光电子学进展,2018, 55( 11) : 111006.]
[44] Ma J Y,Zhao J,Tian J W,et al. Robust point matching via vector field consensus[J]. IEEE Transactions on Image Processing, 2014,23 ( 4 ) : 1706-1721. [DOI: 10. 1109 /TIP. 2014. 2307478]
[45] Aronszajn N. Theory of reproducing kernels[J]. Transactions of the American Mathematical Society,1950,68 ( 3 ) : 337-404. [DOI: 10. 2307 /1990404]
[46] Charles R Q,Su H,Mo K,et al. PointNet: deep learning on point sets for 3D classification and segmentation[C]/ /Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI: IEEE,2017: 77-85. [DOI: 10. 1109 /CVPR. 2017. 16]
[47] Qi C R,Yi L,Su H,et al. PointNet + + : deep hierarchical feature learning on point sets in a metric space[C]/ /Proceedings of the 31st Conference on Neural Information Processing Systems. Long Beach,CA: ACM,2017.
[48] Deng H W,Birdal T,Ilic S. PPFNet: global context aware local features for robust 3D point matching[C]/ /Proceedings of 2018 IEEE /CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT: IEEE,2018. [DOI: 10. 1109 / CVPR. 2018. 00028]
[49] Zhou L,Zhu S Y,Luo Z X,et al. Learning and matching multiview descriptors for registration of point clouds[C]/ /Proceedings of the 15th European Conference on Computer Vision. Munich, Germany: Springer,2018. [DOI: 10. 1007 /978-3-030-01267-0 _31]
[50] Wang H Y,Guo J W,Yan D M,et al. Learning 3D keypoint descriptors for non-rigid shape matching[C]/ /Proceedings of the 15th European Conference on Computer Vision. Munich,Germany: Springer,2018. [doi: 10. 1007 /978-3-030-01237-3_1]
[51] Georgakis G,Karanam S,Wu Z Y,et al. End-to-end learning of keypoint detector and descriptor for pose invariant 3D matching [C]/ /Proceedings of 2018 IEEE /CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT: IEEE, 2018. [DOI: 10. 1109 /CVPR. 2018. 00210]
[52] Ren S Q,He K M,Girshick R,et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017,39 ( 6 ) : 1137-1149. [DOI: 10. 1109 /TPAMI. 2016. 2577031]
[53] Wang Z H,Wu F C,Hu Z Y. MSLD: a robust descriptor for line matching[J]. Pattern Recognition,2009,42 ( 5 ) : 941- 953. [DOI: 10. 1016 /j. patcog. 2008. 08. 035]
[54] Wang J X,Zhang X,Zhu H,et al. MSLD descriptor combined regional affine transformation and straight line matching[J]. Journal of Signal Processing,2018,34 ( 2 ) : 183-191. [王竞 雪,张雪,朱红,等. 结合区域仿射变换的 MSLD 描述子与 直线段匹配[J]. 信号处理,2018,34( 2) : 183-191.][DOI: 10. 16798 /j. issn. 1003-0530. 2018. 02. 008]
[55] Zhang L L,Koch R. An efficient and robust line segment matching approach based on LBD descriptor and pairwise geometric consistency[J]. Journal of Visual Communication and Image Representation,2013,24 ( 7 ) : 794-805. [DOI: 10. 1016 /j. jvcir. 2013. 05. 006]
[56] Wang L,Neumann U,You S Y. Wide-baseline image matching using line signatures[C]/ /Proceedings of the 12th International Conference on Computer Vision. Kyoto,Japan: IEEE,2009: 1311-1318. [DOI: 10. 1109 / ICCV. 2009. 5459316]
[57] López J,Santos R,Fdez-Vidal X R,et al. Two-view line matching algorithm based on context and appearance in low-textured images[J]. Pattern Recognition,2015,48 ( 7 ) : 2164-2184. [DOI: 10. 1016 /j. patcog. 2014. 11. 018]
[58] Fan B,Wu F C,Hu Z Y. Line matching leveraged by point correspondences[C]/ /Proceedings of 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. San Francisco,CA: IEEE,2010: 390-397. [DOI: 10. 1109 / CVPR. 2010. 5540186]
[59] Fan B,Wu F C,Hu Z Y. Robust line matching through line-point invariants[J]. Pattern Recognition,2012,45 ( 2) : 794- 805. [DOI: 10. 1016 /j. patcog. 2011. 08. 004]
[60] Lourakis M I A,Halkidis S T,Orphanoudakis S C. Matching disparate views of planar surfaces using projective invariants[J]. Image and Vision Computing,2000,18 ( 9) : 673-683. [DOI: 10. 1016 / S0262-8856( 99) 00071-2]
[61] Jia Q,Gao X K,Fan X,et al. Novel coplanar line-points invariants for robust line matching across views[C]/ /Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer,2016: 599-611. [DOI: 10. 1007 / 978-3-319-46484-8_36]
[62] Luo Z X,Zhou X C,Gu D X. From a projective invariant to some new properties of algebraic hypersurfaces[J]. Science China Mathematics,2014,57( 11) : 2273-2284. [DOI: 10. 1007 / s11425-014-4877-0]
[63] Ouyang H,Fan D Z,Ji S,et al. Line matching based on discrete description and conjugate point constraint[J]. Acta Geodaetica et Cartographica Sinica,2018,47 ( 10 ) : 1363-1371. [欧阳欢,范大昭,纪松,等. 结合离散化描述与同名点约束 的线特征匹配[J]. 测绘学报,2018,47( 10) : 1363-1371.] [DOI: 10. 11947 /j. AGCS. 2018. 20170231]
[64] Matas J,Chum O,Urban M,et al. Robust wide baseline stereo from maximally stable extremal regions[C]/ /Proceedings of the 13th British Machine Vision Conference. Cardiff: BMVC,2002: 1041-1044.
[65] Nistér D,Stewénius H. Linear time maximally stable extremal regions[C]/ /Proceedings of the 10th European Conference on Computer Vision. Marseille,France: Springer,2008: 183-196. [DOI: 10. 1007 /978-3-540-88688-4_14]
[66] Elnemr H A. Combining SURF and MSER along with color features for image retrieval system based on bag of visual words[J]. Journal of Computer Science,2016,12 ( 4) : 213-222. [DOI: 10. 3844 /jcssp. 2016. 213. 222]
[67] Mo H Y,Wang Z P. A feature detection method combined MSER and SIFT[J]. Journal of Donghua University: Natural Science, 2011,37( 5) : 624-628. [莫会宇,王祝萍. 一种结合 MSER 与 SIFT 算子的特征检测方法[J]. 东华大学学报: 自然科学 版,2011,37 ( 5) : 624-628.][DOI: 10. 3969 /j. issn. 1671- 0444. 2011. 05. 017]
[68] Xu Y C,Monasse P,Géraud T,et al. Tree-based Morse regions: a topological approach to local feature detection[J]. IEEE Transactions on Image Processing,2014,23( 12) : 5612-5625. [DOI: 10. 1109 /TIP. 2014. 2364127]
[69] Korman S,Reichman D,Tsur G,et al. FasT-Match: fast affine template matching[C]/ /Proceedings of 2013 IEEE Conference on Computer Vision and Pattern Recognition. Portland,OR: IEEE,2013: 2331-2338. [DOI: 10. 1109 /CVPR. 2013. 302]
[70] Jia D,Cao J,Song W D,et al. Colour FAST ( CFAST) match: fast affine template matching for colour images[J]. Electronics Letters,2016,52( 14) : 1220-1221. [DOI: 10. 1049 /el. 2016. 1331]
[71] Jia D,Yang N H,Sun J G. Template selection and matching algorithm for image matching[J]. Journal of Image and Graphics, 2017,22( 11) : 1512-1520. [贾迪,杨宁华,孙劲光. 像对匹 配的模 板 选 择 与 匹 配[J]. 中国图象图形学报,2017, 22( 11) : 1512-1520.][DOI: 10. 11834 /jig. 170156]
[72] Dekel T,Oron S,Rubinstein M,et al. Best-buddies similarity for robust template matching[C]/ /Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA: IEEE,2015: 2021-2029. [DOI: 10. 1109 /CVPR. 2015. 7298813]
[73] Oron S,Dekel T,Xue T F,et al. Best-buddies similarity—robust template matching using mutual nearest neighbors[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2018,40 ( 8 ) : 1799-1813. [DOI: 10. 1109 /TPAMI. 2017. 2737424]
[74] Wang G,Sun X L,Shang Y,et al. A robust template matching algorithm based on best-buddies similarity[J]. Acta Optica Sinica,2017,37( 3) : 274-280. [王刚,孙晓亮,尚洋,等. 一种 基于最佳相似点对的稳健模板匹配算法[J]. 光 学 学 报, 2017, 37 ( 3 ) : 274-280.] [DOI: 10. 3788 /aos201737. 0315003]
[75] Talmi I,Mechrez R,Zelnik-Manor L. Template matching with deformable diversity similarity[C]/ /Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI: IEEE,2017: 1311-1319. [DOI: 10. 1109 /CVPR. 2017. 144]
[76] Talker L,Moses Y,Shimshoni I. Efficient sliding window computation for NN-based template matching[C]/ /Proceedings of the 15th European Conference on Computer Vision. Munich,Germany: Springer,2018: 409-424. [DOI: 10. 1007 /978-3-030- 01249-6_25]
[77] Korman S,Soatto S,Milam M. OATM: occlusion aware template matching by consensus set maximization[C]/ /Proceedings of 2018 IEEE /CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City,UT: IEEE,2018. [DOI: 10. 1109 /CVPR. 2018. 00283]
[78] Kat R,Jevnisek R J,Avidan S. Matching pixels using co-occurrence statistics[C]/ /Proceedings of 2018 IEEE /CVF Conference on Computer Vision and Pattern Recognition. Salt Lake City, UT: IEEE,2018. [DOI: 10. 1109 /CVPR. 2018. 00188]
[79] Han X F,Leung T,Jia Y Q,et al. MatchNet: unifying feature and metric learning for patch-based matching[C]/ /Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston,MA: IEEE,2015: 3279-3286. [DOI: 10. 1109 /CVPR. 2015. 7298948]
[80] Zagoruyko S,Komodakis N. Learning to compare image patches via convolutional neural networks[C]/ /Proceedings of 2015 IEEE Conference on Computer Vision and Pattern Recognition. Boston,MA: IEEE,2015: 4353-4361. [DOI: 10. 1109 / CVPR. 2015. 7299064]
[81] Fan D Z,Dong Y,Zhang Y S. Satellite image matching method based on deep convolution neural network[J]. Acta Geodaetica et Cartographica Sinica,2018,47( 6) : 844-853. [范大昭,董 杨,张永生. 卫星影像匹配的深度卷积神经网络方法[J]. 测绘 学 报,2018,47 ( 6 ) : 844-853.] [DOI: 10. 11947 /j. AGCS. 2018. 20170627]
[82] Balntas V,Johns E,Tang L L,et al. PN-Net: conjoined triple deep network for learning local image descriptors[EB /OL]. [2018-08-09]https: / /arxiv. org / pdf /1601. 05030. pdf.
[83] Yang T Y,Hsu J H,Lin Y Y,et al. DeepCD: learning deep complementary descriptors for patch representations[C]/ /Proceedings of 2017 IEEE International Conference on Computer Vision. Venice,Italy: IEEE,2017: 3334-3342. [DOI: 10. 1109 / ICCV. 2017. 359]
[84] Tian Y R,Fan B,Wu F C. L2-Net: deep learning of discriminative patch descriptor in Euclidean space[C]/ /Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu,HI: IEEE,2017: 6128-6136. [DOI: 10. 1109 /CVPR. 2017. 649].