
【深度学习】通俗讲解深度学习中的图像分割技术
来源:Python数据之道
作者:来自读者投稿
整理:阳哥
今天来跟大家分享 深度学习中图像分割技术 相关的知识点,文章内容由公众号读者创作。
近几年来,深度学习技术发展迅速,自动驾驶、目标检测、人脸识别等热门科技逐渐走进人们的生活当中,今天小编带大家一起来认识图像分割技术。
图像分割
图像分割,顾名思义就是根据某些规则将图片分成若干特定的、具有独特性质的区域,并抽取出感兴趣的目标。
下图展示了图像分割领域的几种子领域:
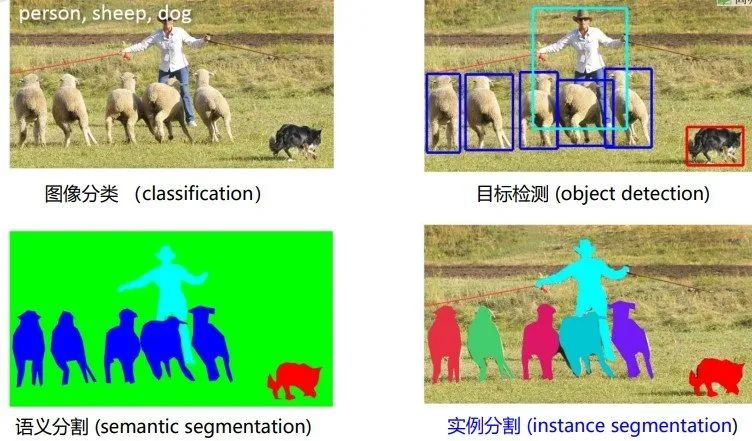
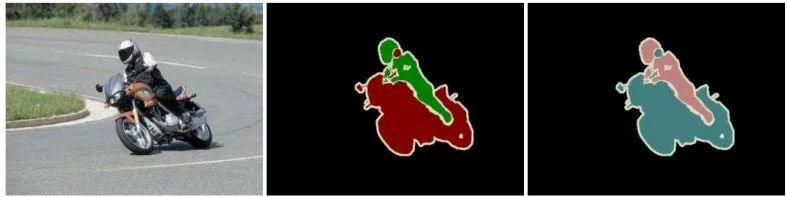
语义分割:对于一张图像,分割出所有的目标(包括背景),但对于同一类别的目标,无法区别不同个体。 实例分割:将图像中除背景之外的所有目标分割出来,并且可以区分同一类别下的不同个体(例如第三幅图中每个人都用不同的颜色表示) 全景分割:在实例分割的基础上,可以分割出背景目标。

几种分割方式的关系
下图说明了什么是语义分割,从像素层次上来识别图像,为图像中的每个像素指定类别标记,如图,使用相应的颜色表示不同的类别,来标记图像中的每个像素。
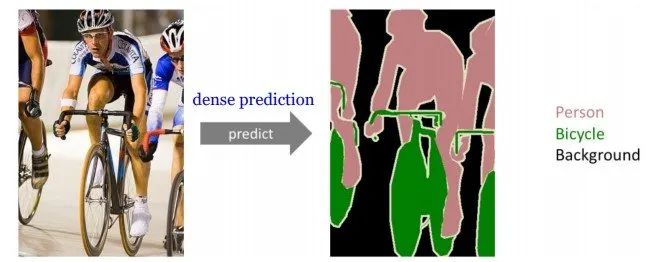
语义分割与实例分割最主要的区别就是,实例分割在正确检测目标的同时,还要精确的分割出每个实例,但不包括背景信息。
分割在图像中的表达
我们知道,图像在计算机中的表达方式是数字,对于一张图像中的每个目标来说,计算机对他们的认识则是通过像素完成的,如下图,对图像进行标注的时候,将人用数字1表示,包用数字2,树叶用数字3表示,通过不同的数字来区分不同的类别。
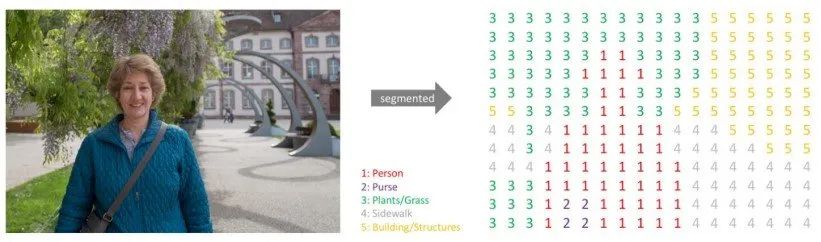
这些数字也叫做掩膜Mask,它表示图像中存在特定类别的区域,每个类别构成一个数组。
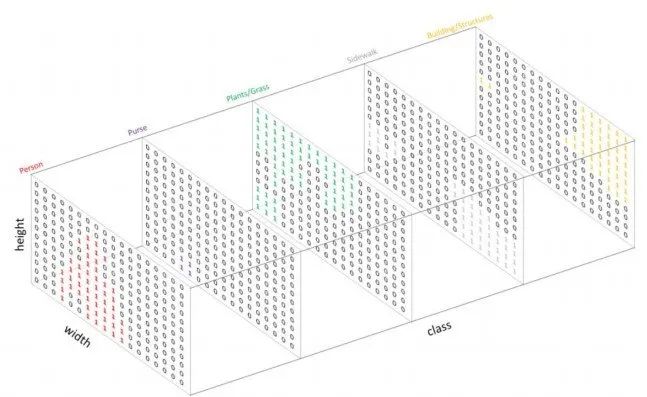
图像分割应用
关于图像分割的应用也有很多,例如自动驾驶,医学图像诊断等等,都需要分割出对我们有用的目标。
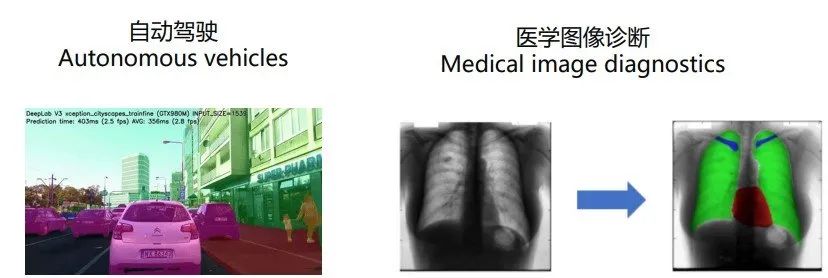
常用的图像数据集
图像分割领域常用的数据集有以下几种:
PASCAL VOC COCO BDD100K CamVid Cityscapes Dataset ApolloScape Scene Parsing
PASCAL VOC
VOC 2012 数据集分为20类,包括背景有21类,分别如下:
人:人 动物:鸟、猫、牛、狗、马、羊 车辆:飞机、自行车、船、巴士、汽车、摩托车、火车 室内:瓶子、椅子、餐桌、植物、沙发、电视
数据集的下载链接为:
http://host.robots.ox.ac.uk/pascal/VOC/voc2012/index.html
COCO
COCO 数据集起源于2014年微软出资标注的Microsoft COCO数据集,它提供的类别有80类,超过33万张图片,其中20万张有标注,整个数据集中个体数目超过150万个。
数据集的下载链接为:
http://cocodataset.org/

BDD100K
2018年5月伯克利大学AI实验室发布了目前最大规模、内容最具多样性的公开驾驶数据集BDD100K,同时设计了一个图片标注系统。BDD100K 数据集包含10万段高清视频,每个视频约40秒,720p,30 fps 。每个视频的第10秒对关键帧进行采样,得到10万张图片(图片尺寸:1280*720 ),并进行标注。
数据集的下载链接为:
https://bair.berkeley.edu/blog/2018/05/30/bdd/

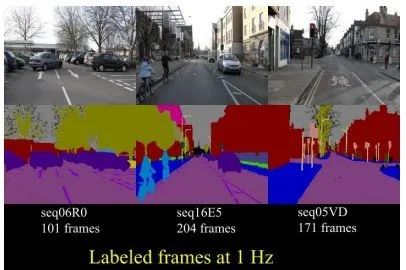
CamVid
CamVid 是第一个具有目标类别语义标签的视频集合。数据库提供32个ground truth语义标签,将每个像素与语义类别之一相关联。
该数据库解决了对实验数据的需求,以定量评估新兴算法。数据是从驾驶汽车的角度拍摄的。
数据集的下载链接为:
http://mi.eng.cam.ac.uk/research/projects/VideoRec/CamVid/
Cityscapes Dataset
包含戴姆勒在内的三家德国单位联合提供,包含50多个城市的立体视觉数据;像素级标注;提供算法评估接口。
数据集的下载链接为:
https://www.cityscapes-dataset.com/

ApolloScape Scene Parsing
百度公司提供的 ApolloScape 数据集将包括具有高分辨率图像和每像素标注的 RGB 视频,具有语义分割的测量级密集3D点,立体视频和全景图像。
Scene Parsing 数据集是 ApolloScape 的一部分,它为高级自动驾驶研究提供了一套工具和数据集。场景解析旨在为图像中的每个像素或点云中的每个点分配类别(语义)标签。
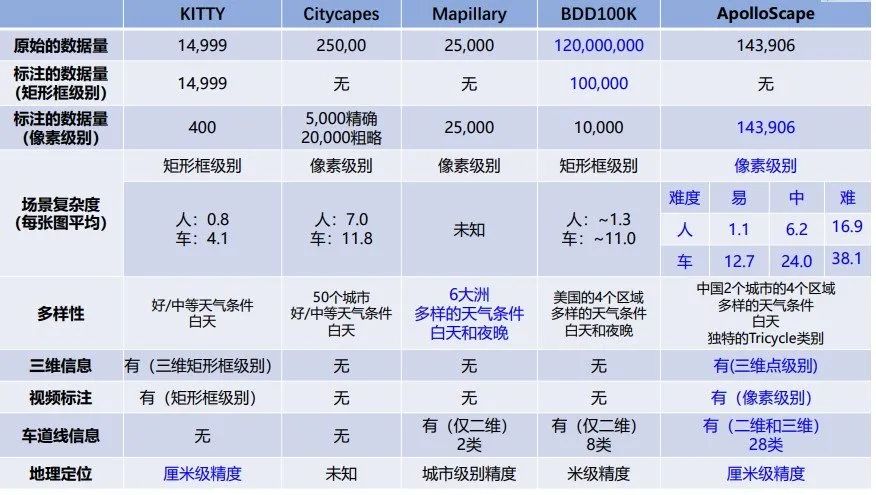
下面是几种数据集的比较,可以针对不同使用场景,选择合适的数据集进行训练。
常用的图像标注工具
这里小编为大家总结了几种常用的图像标注工具,以满足不同任务的需求。
Labelme:
适合通用物体的标注,需要用多边形拟合物体。支持对象检测、图像语义分割数据标注,实现语言为 Python 与 QT,支持导出 VOC 与 COCO 格式数据实例分割。
链接:https://github.com/wkentaro/labelme
LabelImg:
适用于图像检测任务的数据集制作,其中标签存储功能和“Next Image”、“Prev Image”的设计使用起来比较方便。该软件最后保存的 xml 文件格式和 ImageNet 数据集是一样的。
链接:https://github.com/tzutalin/labelImg
RectLabel:
支持导出 YOLO、KITTI、COCOJSON 与 CSV 格式,读写 Pascal VOC 格式的 XML 文件。
链接:https://rectlabel.com/
VIA:
VGG发布的一种基于 WEB 方式的图像标注工具,使用起来方便快捷,适用于实例分割等标注任务。
链接:http://www.robots.ox.ac.uk/~vgg/software/via/
OpenCV/CVAT:
高效的计算机视觉标注工具,支持图像分类、对象检测框、图像语义分割、实例分割数据标注在线标注工具。支持图像与视频数据标注,最重要的是支持本地部署,无需担心数据外泄。
链接:https://github.com/opencv/cvat
VOTT:
微软发布的基于 WEB 方式本地部署的视觉数据标注工具。支持图像与视频数据标注,支持导出 CNTK/Pascal VOC 格式,支持导出TFRecord、CSV、VoTT 格式,当前主要分支版本有 V1 与 V2 版本。
链接:https://github.com/microsoft/VoTT
往期精彩回顾
本站qq群851320808,加入微信群请扫码: