
使用DistilBERT 蒸馏类 BERT 模型的代码实现

来源:DeepHub IMBA 本文约2700字,建议阅读9分钟
本文带你进入Distil细节,并给出完整的代码实现。本文为你详细介绍DistilBERT,并给出完整的代码实现。
机器学习模型已经变得越来越大,即使使用经过训练的模型当硬件不符合模型对它应该运行的期望时,推理的时间和内存成本也会飙升。为了缓解这个问题是使用蒸馏可以将网络缩小到合理的大小,同时最大限度地减少性能损失。
我们在以前的文章中介绍过 DistilBERT [1] 如何引入一种简单而有效的蒸馏技术,该技术可以轻松应用于任何类似 BERT 的模型,但没有给出任何的代码实现,在本篇文章中我们将进入细节,并给出完整的代码实现。
学生模型的初始化
由于我们想从现有模型初始化一个新模型,所以需要访问旧模型的权重。本文将使用Hugging Face 提供的 RoBERTa [2] large 作为我们的教师模型,要获得模型权重,必须知道如何访问它们。
Hugging Face的模型结构
可以尝试的第一件事是打印模型,这应该让我们深入了解它是如何工作的。当然,我们也可以深入研究 Hugging Face 文档 [3],但这太繁琐了。
from transformers import AutoModelForMaskedLMroberta = AutoModelForMaskedLM.from_pretrained("roberta-large")print(roberta)
运行此代码后得到:
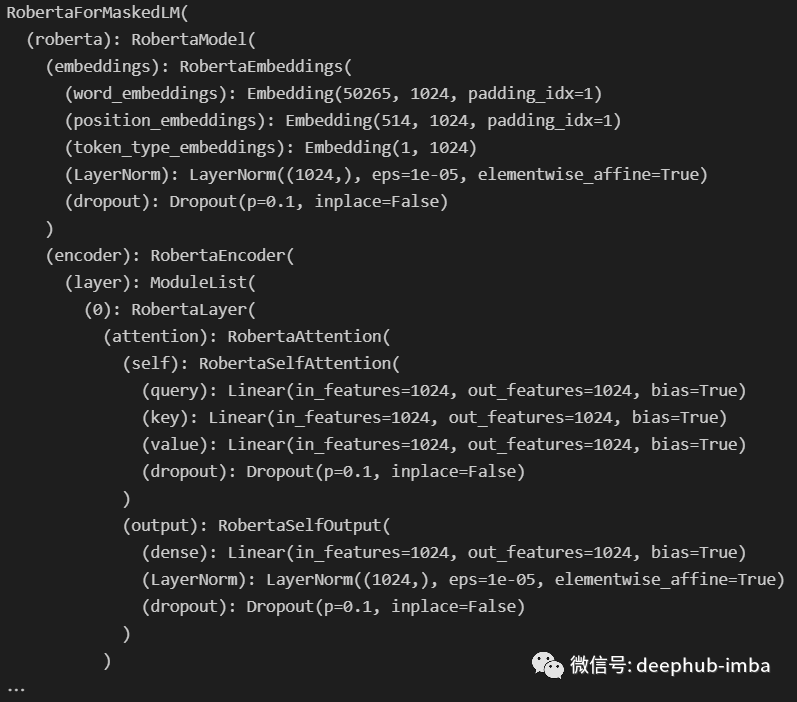
在 Hugging Face 模型中,可以使用 .children() 生成器访问模块的子组件。因此,如果我们想使用整个模型,我们需要在它上面调用 .children() ,并在每个子节点上调用,这是一个递归函数,代码如下:
from typing import Anyfrom transformers import AutoModelForMaskedLMroberta = AutoModelForMaskedLM.from_pretrained("roberta-large")def visualize_children(object : Any,level : int = 0,) -> None:"""Prints the children of (object) and their children too, if there are any.Uses the current depth (level) to print things in a ordonnate manner."""print(f"{' ' * level}{level}- {type(object).__name__}")try:for child in object.children():visualize_children(child, level + 1)except:passvisualize_children(roberta)
这样获得了如下输出:
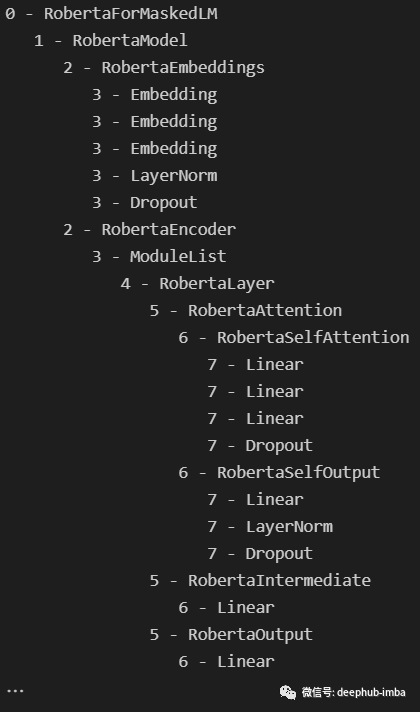
看起来 RoBERTa 模型的结构与其他类似 BERT 的模型一样,如下所示:
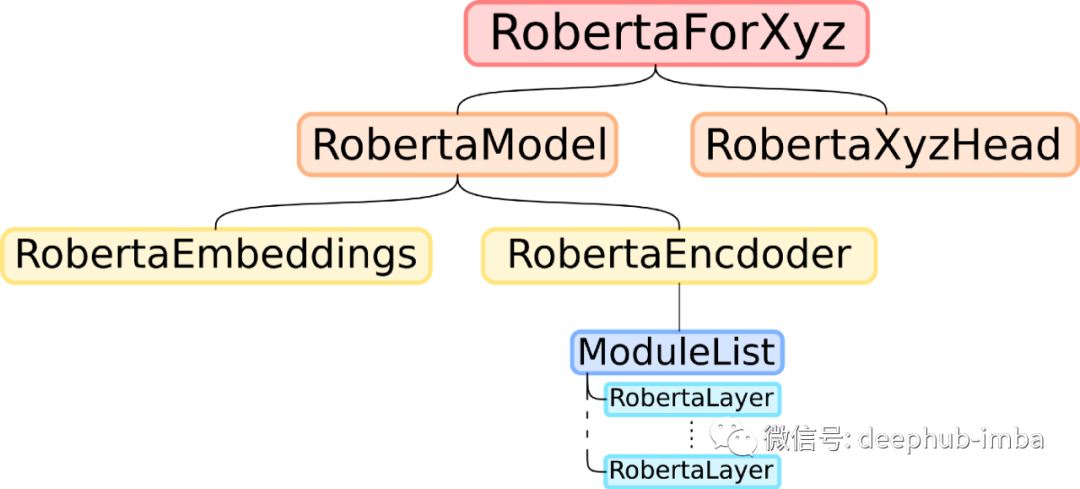
复制教师模型的权重
要以 DistilBERT [1] 的方式初始化一个类似 BERT 的模型,我们只需要复制除最深层的 Roberta 层之外的所有内容,并且删除其中的一半。所以这里的步骤如下:首先,我们需要创建学生模型,其架构与教师模型相同,但隐藏层数减半。只需要使用教师模型的配置,这是一个类似字典的对象,描述了Hugging Face模型的架构。查看 roberta.config 属性时,我们可以看到以下内容:

我们感兴趣的是numhidden -layers属性。让我们写一个函数来复制这个配置,通过将其除以2来改变属性,然后用新的配置创建一个新的模型:
from transformers.models.roberta.modeling_roberta import RobertaPreTrainedModel, RobertaConfigdef distill_roberta(teacher_model : RobertaPreTrainedModel,) -> RobertaPreTrainedModel:"""Distilates a RoBERTa (teacher_model) like would DistilBERT for a BERT model.The student model has the same configuration, except for the number of hidden layers, which is // by 2.The student layers are initilized by copying one out of two layers of the teacher, starting with layer 0.The head of the teacher is also copied."""# Get teacher configuration as a dictionnaryconfiguration = teacher_model.config.to_dict()# Half the number of hidden layerconfiguration['num_hidden_layers'] //= 2# Convert the dictionnary to the student configurationconfiguration = RobertaConfig.from_dict(configuration)# Create uninitialized student modelstudent_model = type(teacher_model)(configuration)# Initialize the student's weightsdistill_roberta_weights(teacher=teacher_model, student=student_model)# Return the student modelreturn student_model
这个函数distill_roberta_weights函数将把教师的一半权重放在学生层中,所以仍然需要对它进行编码。由于递归在探索教师模型方面工作得很好,可以使用相同的思想来探索和复制某些部分。这里将同时在老师和学生的模型中迭代,并将其从一个到另一个进行复制。唯一需要注意的是隐藏层的部分,只复制一半。
函数如下:
from transformers.models.roberta.modeling_roberta import RobertaEncoder, RobertaModelfrom torch.nn import Moduledef distill_roberta_weights(teacher : Module,student : Module,) -> None:"""Recursively copies the weights of the (teacher) to the (student).This function is meant to be first called on a RobertaFor... model, but is then called on every children of that model recursively.The only part that's not fully copied is the encoder, of which only half is copied."""# If the part is an entire RoBERTa model or a RobertaFor..., unpack and iterateif isinstance(teacher, RobertaModel) or type(teacher).__name__.startswith('RobertaFor'):for teacher_part, student_part in zip(teacher.children(), student.children()):distill_roberta_weights(teacher_part, student_part)# Else if the part is an encoder, copy one out of every layerelif isinstance(teacher, RobertaEncoder):teacher_encoding_layers = [layer for layer in next(teacher.children())]student_encoding_layers = [layer for layer in next(student.children())]for i in range(len(student_encoding_layers)):student_encoding_layers[i].load_state_dict(teacher_encoding_layers[2*i].state_dict())# Else the part is a head or something else, copy the state_dictelse:student.load_state_dict(teacher.state_dict())
这个函数通过递归和类型检查,确保学生模型与 Roberta 层的教师安全模型相同。如果想在初始化的时候改变复制哪些层,只需要更改encoder部分的for循环就可以了。
现在我们有了学生模型,我们需要对其进行训练。这部分相对简单,主要的问题就是使用的损失函数。
自定义损失函数
作为对 DistilBERT 训练过程的回顾,先看一下下图:
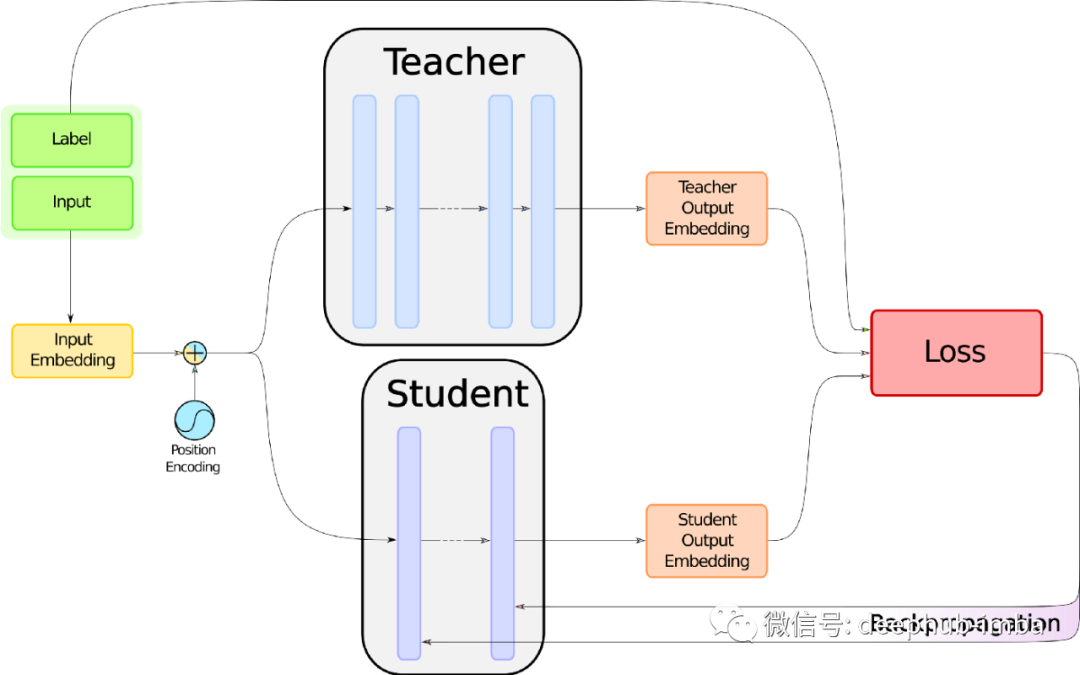
请把注意力转向上面写着“损失”的红色大盒子。但是在详细介绍里面是什么之前,需要知道如何收集我们要喂给它的东西。在这张图中可以看到需要 3 个东西:标签、学生和教师的嵌入。标签已经有了,因为是有监督的学习。现在看啊可能如何得到另外两个。
教师和学生的输入
在这里需要一个函数,给定一个类 BERT 模型的输入,包括两个张量 input_ids 和 attention_mask 以及模型本身,然后函数将返回该模型的 logits。由于我们使用的是 Hugging Face,这非常简单,我们需要的唯一知识就是能看懂下面的代码:
from torch import Tensordef get_logits(model : RobertaPreTrainedModel,input_ids : Tensor,attention_mask : Tensor,) -> Tensor:"""Given a RoBERTa (model) for classification and the couple of (input_ids) and (attention_mask),returns the logits corresponding to the prediction."""return model.classifier(model.roberta(input_ids, attention_mask)[0])
学生和老师都可以使用这个函数,但是第一个有梯度,第二个没有。
损失函数的代码实现
损失函数具体的介绍请见我们上次发布的文章,这里使用下面的图片进行解释:
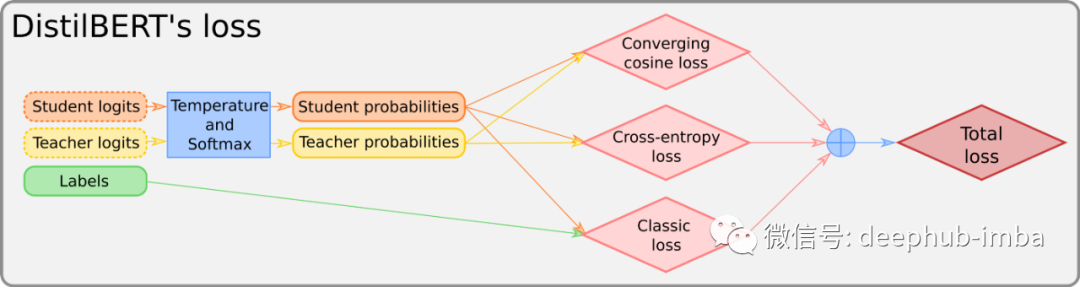
我们所说的“‘converging cosine-loss(收敛余弦损失)”是用于对齐两个输入向量的常规余弦损失。这是代码:
import torchfrom torch.nn import CrossEntropyLoss, CosineEmbeddingLossdef distillation_loss(teacher_logits : Tensor,student_logits : Tensor,labels : Tensor,temperature : float = 1.0,) -> Tensor:"""The distillation loss for distilating a BERT-like model.The loss takes the (teacher_logits), (student_logits) and (labels) for various losses.The (temperature) can be given, otherwise it's set to 1 by default."""# Temperature and sotfmaxstudent_logits, teacher_logits = (student_logits / temperature).softmax(1), (teacher_logits / temperature).softmax(1)# Classification loss (problem-specific loss)loss = CrossEntropyLoss()(student_logits, labels)# CrossEntropy teacher-student lossloss = loss + CrossEntropyLoss()(student_logits, teacher_logits)# Cosine lossloss = loss + CosineEmbeddingLoss()(teacher_logits, student_logits, torch.ones(teacher_logits.size()[0]))# Average the loss and return itloss = loss / 3return loss
以上就是 DistilBERT 的所有关键思想的实现,但是还缺少一些东西,比如 GPU 支持、整个训练例程等,所以最后完整的代码会在文章的最后提供,如果需要实际使用,建议使用最后的 Distillator 类。
结果
以这种方式提炼出来的模型最终表现如何呢?对于 DistilBERT,可以阅读原始论文 [1]。对于 RoBERTa,Hugging Face 上已经存在类似 DistilBERT 的蒸馏版本。在 GLUE 基准 [4] 上,我们可以比较两个模型:
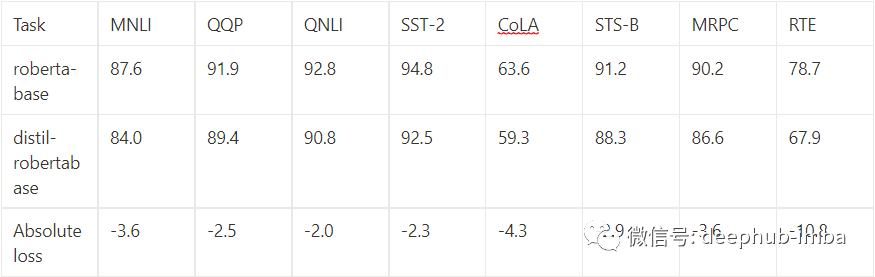
至于时间和内存成本,这个模型大约是 roberta-base 大小的三分之二,速度是两倍。
总结
通过以上的代码我们可以蒸馏任何类似 BERT 的模型。 除此以外还有很多其他更好的方法,例如 TinyBERT [5] 或 MobileBERT [6]。如果你认为其中一篇更适合您的需求,你应该阅读这些文章。甚至是完全尝试一种新的蒸馏方法,因为这是一个日益发展的领域。