京东言犀:场景中诞生的高效大模型

谷歌于2018年提出的基于大数据量大参数量的自监督预训练语言模型(亦叫Foundation
Model或者大模型)BERT获得的成功让人工智能技术的研究和应用进入了一个全新的阶段,主要体现在三个方面:
第三,基于Transformer网络结构的大模型已经从自然语言处理领域延展至计算机视觉、语音识别、跨模态信息处理等多个AI领域。
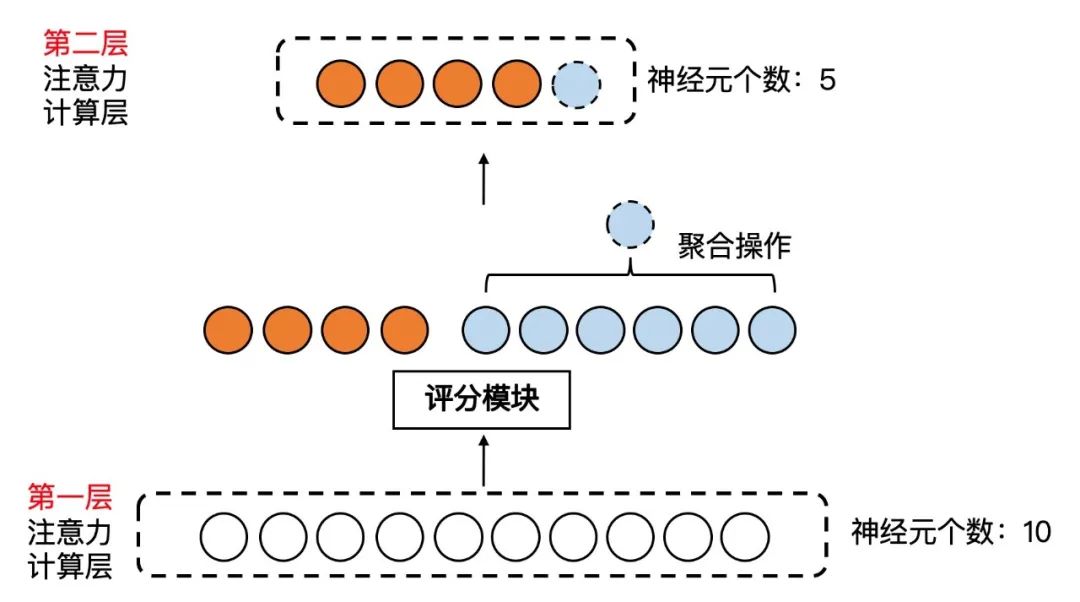
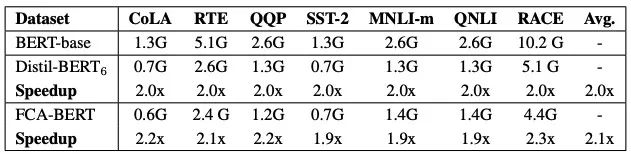
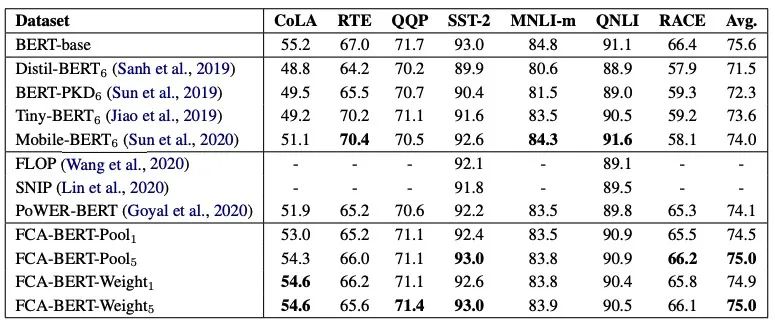
Multimedia 2021大会最佳演示奖,还通过了信通院首批数字人系统基础能力评测。
-End-




评论
 下载APP
下载APP谷歌于2018年提出的基于大数据量大参数量的自监督预训练语言模型(亦叫Foundation
Model或者大模型)BERT获得的成功让人工智能技术的研究和应用进入了一个全新的阶段,主要体现在三个方面:
第三,基于Transformer网络结构的大模型已经从自然语言处理领域延展至计算机视觉、语音识别、跨模态信息处理等多个AI领域。
-End-