
NLP场景中的对比学习模型SimCSE
导读:本文是“数据拾光者”专栏的第三十五篇文章,这个系列将介绍在广告行业中自然语言处理和推荐系统实践。本篇从理论到实践介绍了NLP场景下常用的对比学习模型SimCSE,对于希望将对比学习模型SimCSE应用到NLP场景的小伙伴可能有所帮助。欢迎转载,转载请注明出处以及链接,更多关于自然语言处理、推荐系统优质内容请关注如下频道。知乎专栏:数据拾光者
公众号:数据拾光者
摘要:本篇从理论到实践介绍了NLP场景下常用的对比学习模型SimCSE。首先介绍了业务背景,经过一系列调研NLP场景中简单有效的对比学习模型是SimCSE;然后重点介绍了SimCSE模型,包括评估对比学习模型的两个指标alignment和uniformity、NLP场景中使用对比学习模型的难点、SimCSE提出了一种基于dropout mask的方法来构造正负例、dropout mask方式有效性原因分析、有监督和无监督的SimCSE模型以及BERT系列模型和SimCSE模型效果对比;最后项目实践了SimCSE模型。对于希望将对比学习模型SimCSE应用到NLP场景的小伙伴可能有所帮助。
下面主要按照如下思维导图进行学习分享:
01
背景介绍及模型调研
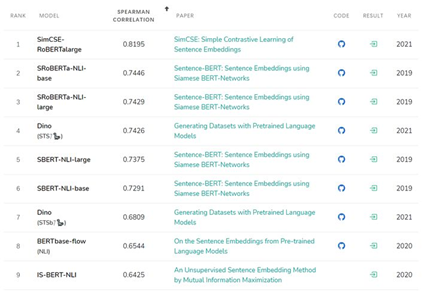
图1 STS基准任务各模型效果图
同时,苏剑林也在文献3中的中文数据集上进行了完整的实验,证明SimCSE模型的确优于其他语义相似度模型。所以调研SimCSE希望能作为SimBERT的升级版本用于线上业务。
02
详解NLP中的对比学习模型SimCSE
2.1 对比学习知识回顾
先简单回顾下对比学习,对比学习最早出现在CV领域,因为CV领域的研究者们想获得一个类似NLP领域中BERT那样的模型,可以通过无监督学习的方法利用海量的数据集构建预训练模型,从而获取图像的先验知识,然后通过迁移学习将获取的图像知识应用到下游任务中。对比学习的核心原则是:通过构造相似实例和不相似实例获得一个表示学习模型,通过这个模型可以让相似的实例在投影的向量空间中尽可能的接近,而不相似的实例尽可能的远离。为了达到这个目的,对比学习模型需要完成三件事:第一件事是如何构造相似实例和不相似实例;第二件事是如何构造满足上面对比学习核心原则的表示学习模型,也就是在向量空间中相似的实例距离尽可能接近,不相似的尽可能远离;第三件是如何防止模型坍塌。关于对比学习详细的知识小伙伴可以看下我写的上一篇文章:《广告行业中那些趣事系列34:风头正劲的对比学习和项目实践》。
本篇主要介绍的NLP场景中的对比学习模型SimCSE和经典模型SimCLR模型类似,都属于基于负例的对比学习方法。下面是SimCLR模型的整体结构图:
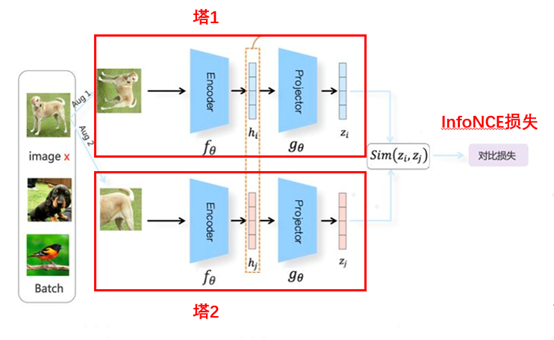
图2 SimCLR模型整体结构图
SimCLR模型最早是应用在图像领域中的基于负例的对比学习模型,通过图像样本增强技术来构造正负例,然后基于双塔模型的思想构造标准对称模型,将图像样本经过encode之后再经过projector拿到最终的特征向量zi。最后通过InfoNCE损失函数来使模型让相似的样本距离尽可能接近,不相似的样本尽可能远离。
2.2 如何评估对比学习模型的好坏
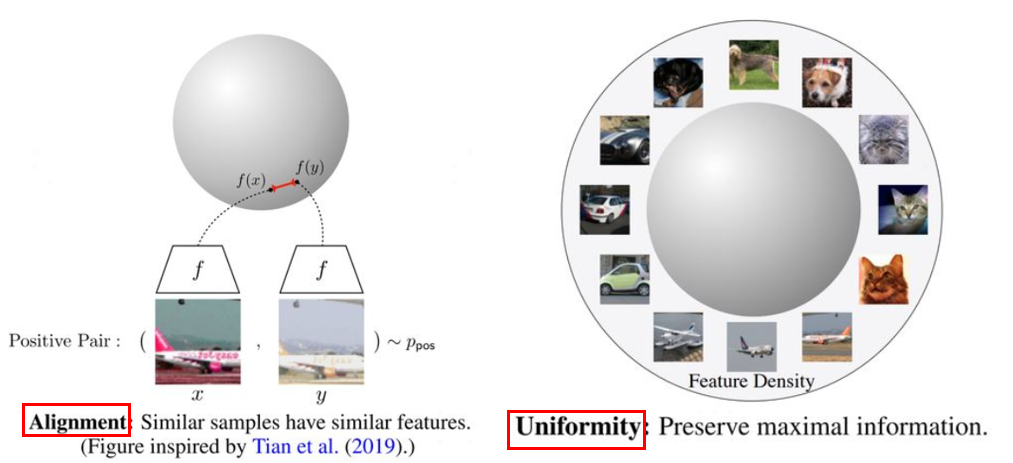
因为对比学习的目标是获得一个优质的语义表示学习空间,在这个空间中相似的样本尽量拉近,不相似样本尽量拉远,那么如何评估这个空间是否优质?文献2中提出了两个评估对比学习模型优劣的指标:alignment和uniformity。下面是两个指标的可视化视图:
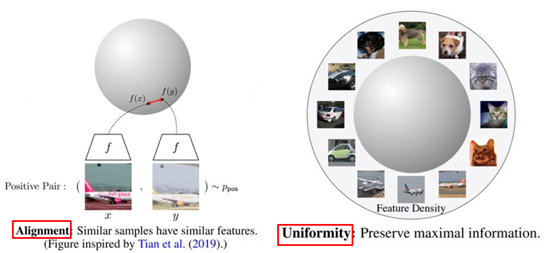
图3 对比学习模型的两个评估指标
上图中左边部分是alignment指标,这个指标希望在向量空间中两个相似的向量距离应该尽可能拉近,很好理解,基本就是对比学习的指导原则。右边部分是uniformity指标,这个指标希望样本应该均匀的分布在向量空间中,主要原因是样本分布越均匀信息熵越高。举一个通俗的例子,现在有个动物园,我们希望动物园里面各类动物能尽量聚集在一起,同时我们还希望能更好的利用动物园,也就是让动物们均匀的分布在动物园里,让空间更好的被利用。
2.3 NLP场景中应用对比学习的难点
上面已经讲了在CV领域应用对比学习,其实将对比学习应用到NLP场景中也非常简单,套路是通过样本增强技术来构造正负例,然后构造标准对称结构,可以直接用BERT模型来进行encoder流程,至于是否需要再用BERT模型来进行projector流程可以根据实验结果来决定是否需要添加。这样的模型结构已经应用在微博的CD-TOM模型中了。这里其他还好说,最麻烦的是如何构造正负例,因为CV领域中可以很轻松的进行图像增强,比如对图片进行旋转、缩放、灰度变换等操作,这些图像增强技术不仅简单而且并不会带来太大的噪声。但是NLP领域中的样本增强技术则复杂的多,效果也降低严重。这时候就期待一种简单有效的获取相似文本的技术了。
2.4 基于dropout mask构造正负例的SimCSE模型
关于文本增强技术其实之前也分享过一篇文章《广告行业中那些趣事系列13:NLP中超实用的样本增强技术》,里面讲了包括样本回译、随机替换等等操作。通过这些方法也可以进行文本增强构造正负例,但是整体来看这些方法效果并不是很理想,而SimCSE模型作者提出了一种通过随机采样dropout mask的操作来构造相似样本。具体操作是在标准的Transformer中会在全连接层和注意力求和操作上进行dropout mask操作,模型训练的时候会将一条样本x复制两份,然后将这两条样本放到同一个编码器中就可以得到两个不同的表示向量z和zi。这么做的原因是BERT内部每次dropout时都会随机生成一个不同的dropout mask,所以不需要改变原始的BERT模型,只需要把样本喂给模型两次,就可以得到两个不同dropout mask的结果,这样就得到了相似样本对。这种方式的好处是相似样本的语义完全一致,只是生成的embedding不同而已,可以认为是数据增强的最小形式。
2.5 为什么随机dropout mask方式有效
小伙伴可能有疑问了,为什么SimCSE这种随机dropout mask方式会有效?为了证明随机dropout mask方式的有效性,SimCSE模型的作者通过实验进行论证。下图是在STS-B数据集上几种不同的样本增强方法对比图:
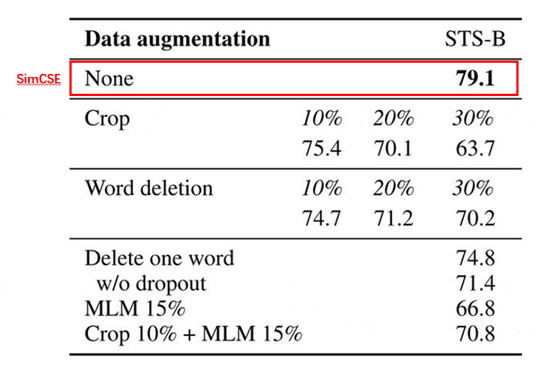
图4 几种不同的样本增强方法效果对比
上图中None是SimCSE模型的效果指标,Crop k%表示随机减掉百分比k长度的span,Word deletion表示随机减掉百分比的词,Delete one word表示随机减掉一个词,MLM 15%表示BERT模型随机替换掉15%的词等等。通过对比这些眼花缭乱的样本增强技术,最后证明SimCSE这种随机采样dropout mask的效果是最好的。
接着作者证明了采样比例对模型效果的影响,下图是对比不同的采样比例模型效果图:
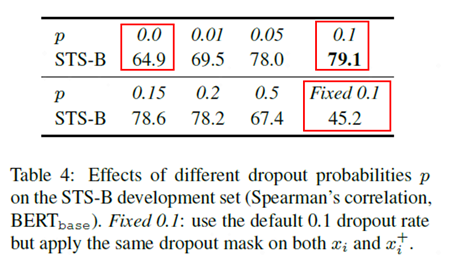
图5 对比不同的采样比例模型效果
从上图可以看出,作者对比了从0到0.5不同随机采样比例下模型效果,其中效果最好的是使用0.1的随机采样比例。除此之外图中还有两种特殊指标:p=0和固定0.1时模型效果指标较差。p=0时相当于取消了随机dropout mask,固定0.1相当于对样本进行一样的随机dropout mask,这两种操作都会让得到的模型效果变差,主要原因是两者得到的相似样本对一模一样,模型很难学到知识。
SimCSE模型作者通过可视化的方式从alignment和uniformity两个指标对比了几种不同样本增强的方法:
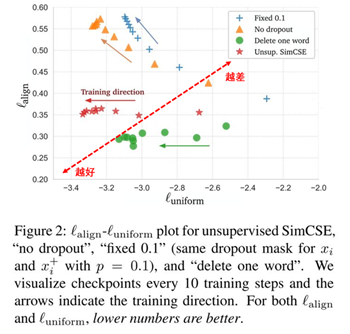
图6 从alignment和uniformity对比模型效果
上图中横轴代表uniformity,纵轴代表alignment,模型效果越接近左下角越好,相反越接近右上角越差。整体来看通过SimCSE的随机dropout mask操作模型的效果是最好的。Fixed 0.1和No dropout随着uniformity效果提升alignment急速下降,而SimCSE因为dropout噪声使得uniformity效果提升同时alignment稳定在一个较好的范围内。虽然Delete one word的alignment相比于SimCSE有较小提升,但是uniformity却差于SimCSE模型。
2.6 有监督和无监督两种SimCSE模型结构
SimCSE模型提供了有监督和无监督两种语义相似度模型,下面是模型结构图:
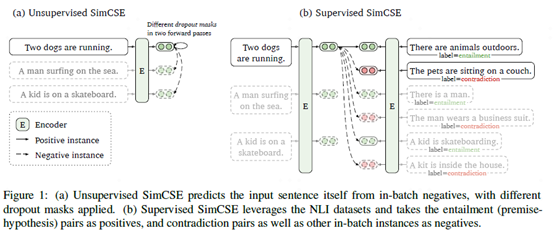
图7 有监督和无监督SimCSE模型结构
上图中左边部分是无监督SimCSE模型,通过给定输入x用BERT预训练模型随机dropout mask编码两次得到相似样本作为正例,batch内其他样本作为负例。训练目标函数为:
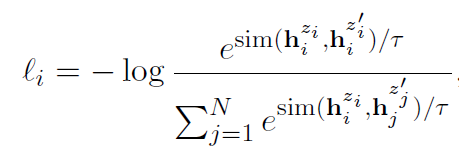
图8 无监督SimCSE模型训练目标函数
右边部分是有监督SimCSE模型,使用NLI数据集中entailment关系样例对作为正例。负例包括两部分,第一部分是batch内其他样本作为负例,第二部分是NLI数据集中关系为contradiction的样例对。训练目标函数为:
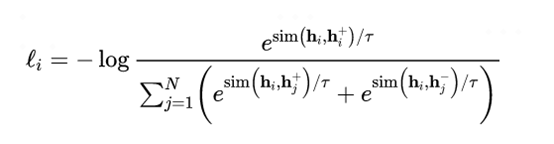
图9 有监督SimCSE模型训练目标函数
2.7 BERT系列模型和SimCSE模型效果对比
学习SimCSE模型的一个重要原因是用于替代业务上常用的基于语义相似度匹配任务的SimBERT模型。SimBERT模型是追一科技苏剑林开源的有监督语义相似匹配模型,文献3苏神也在各种公共数据集上证明了SimCSE的确是目前SOTA。SimCSE模型作者从alignment和uniformity两个指标对比了各种BERT系列模型,下面是模型效果对比图:
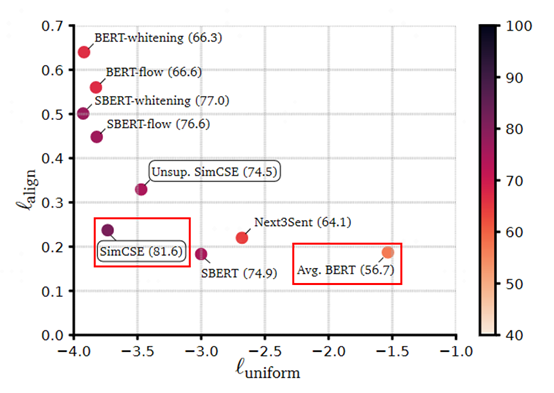
图10 从alignment和uniformity对比BERT系列模型
从上图中可以看出直接通过BERT模型来做无监督语义相似度效果会比较差,主要原因是任意两个句子的BERT句向量相似度比较高,向量分布的非线性和奇异性,使得BERT句向量并没有均匀的分布在向量空间中,对应的信息熵也比较低。针对这个问题,BERT-flow通过normalizing flow把向量分布映射到规整的高斯分布中,有效的提升了uniformity。后来苏神提出了BERT-whitening对向量分布进行了PCA降维消除了冗余信息,进一步提升了uniformity,但是alignment有一定降低。而SimCSE则提出了一种更高效的方案,使得alignment保持在较好效果上还能大幅度提升uniformity,达到了当前的SOTA效果。
03
项目实践SimCSE
上一节详解了NLP场景中的对比学习模型SimCSE,这节从项目实践的角度分享下SimCSE。SimCSE的作者进行了项目开源,github地址如下:
https://github.com/princeton-nlp/SimCSE
使用起来非常简单,先安装对应的包:pip install simcse
下面是SimCSE模型应用代码:
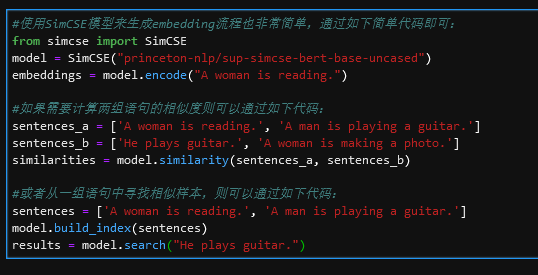
图11 SimCSE模型应用代码
除了SimCSE作者开源的代码,苏神也开源了基于bert4keras框架的SimCSE模型代码,并在公共数据集上补充了实验结果,感兴趣的小伙伴可以看下文献3。开源github地址如下:https://github.com/bojone/SimCSE
04
总结及反思
本篇从理论到实践介绍了NLP场景下常用的对比学习模型SimCSE。首先介绍了业务背景,经过一系列调研NLP场景中简单有效的对比学习模型是SimCSE;然后重点介绍了SimCSE模型,包括评估对比学习模型的两个指标alignment和uniformity、NLP场景中使用对比学习模型的难点、SimCSE提出了一种基于dropout mask的方法来构造正负例、dropout mask方式有效性原因分析、有监督和无监督的SimCSE模型以及BERT系列模型和SimCSE模型效果对比;最后项目实践了SimCSE模型。对于希望将对比学习模型SimCSE应用到NLP场景的小伙伴可能有所帮助。
05
参考资料
[1] SimCSE: Simple Contrastive Learning of Sentence Embeddings
[2] Understanding Contrastive Representation Learning throughAlignment and Uniformity on the Hypersphere
[3] 苏剑林. (Apr. 26, 2021). 《中文任务还是SOTA吗?我们给SimCSE补充了一些实验 》[Blog post]. Retrieved from https://www.kexue.fm/archives/8348