
高效大语言模型的前世今生
文末《大模型项目开发线上营》秒杀!!!
前20人报名,除了VIP年卡外,还多送两个大模型小课:类ChatGPT微调实战、LLM与langchain/知识图谱/数据库的实战,如已有这两课,可以选同等价位别的课
序言
1
语言模型
在计算机科学的早期阶段,人们尝试教会机器处理自然语言。1950年代,Alan Turing提出了著名的图灵测试,该测试旨在评估机器是否能以一种与人类无法区分的方式进行对话。然而,由于当时计算机性能和知识表示的限制,早期语言模型往往表现欠佳。20世纪70年代末至80年代初,随着计算机计算能力的提升,基于统计的语言模型开始受到关注。N-gram模型、隐马尔可夫模型等应运而生,通过分析大量文本语料库中的统计信息,使得计算机更加懂得语言的结构和规律。当时的模型虽然在一定程度上提升了自然语言处理的准确性,但仍然存在缺点,如对上下文的限制、处理长文本耗时较长等问题。
随着深度学习技术的发展,神经网络模型改变了自然语言处理的格局并提出了多个序列到序列(Sequence-to-Sequence)的基础模型架构,比如Transformer模型。凭借其强大的学习能力、并行计算的优势以及对长文本处理的能力,Transformer成为了现代大语言模型的基础架构。2020年,OpenAI发布了第一个大语言模型GPT-3[1](Generative Pre-trained Transformer),引起了业界的广泛关注。GPT系列模型通过大规模无监督学习,在海量的文本数据中自动学习语言的特征和规律,从而可以生成和理解自然语言。这使得高效大语言模型不仅能够应对对话和翻译等传统任务,还可以创造性地生成新的文本内容,成为了多个领域的助手。然而,基于Transformer的大语言模型带来的挑战也不容忽视。其庞大的参数量和计算资源需求使得训练和部署成本变得极高;同时,模型的数据和计算复杂度也带来了隐私和安全的风险。为此,研究者们在模型优化、压缩、加密和隐私保护等方向进行了探索,以寻求更加高效和可信的解决方案。
2
高效的序列建模
高效的序列建模可以分为四大主要路线:
-
稀疏Transformer(Sparse Trasnformer);
-
线性Transformer(Linear Transformer);
-
长卷积(Long Convolution);
-
循环神经网络(RNN)。
在以下的章节中,我们将回顾这些路线并介绍代表性方法,以及在大规模自然语言模型中应用中的难点。下图显示了高效序列建模的发展时间线。
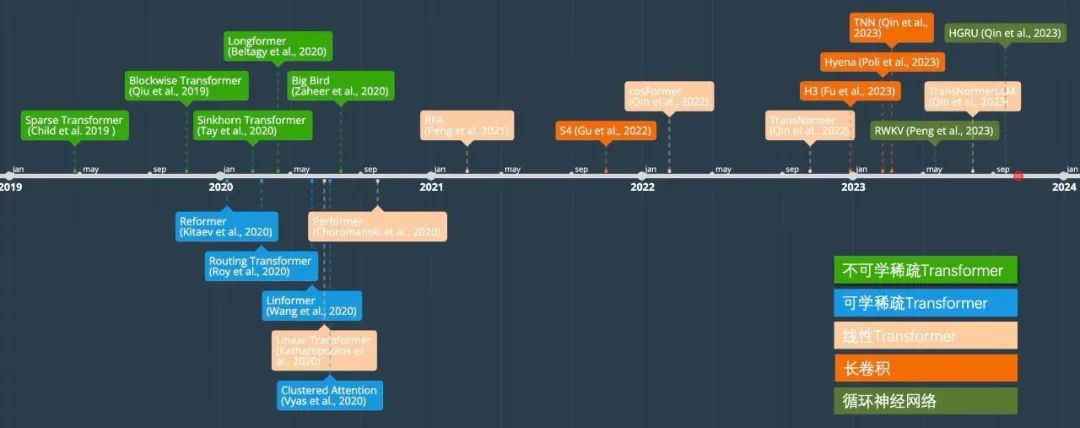
稀疏Transformer
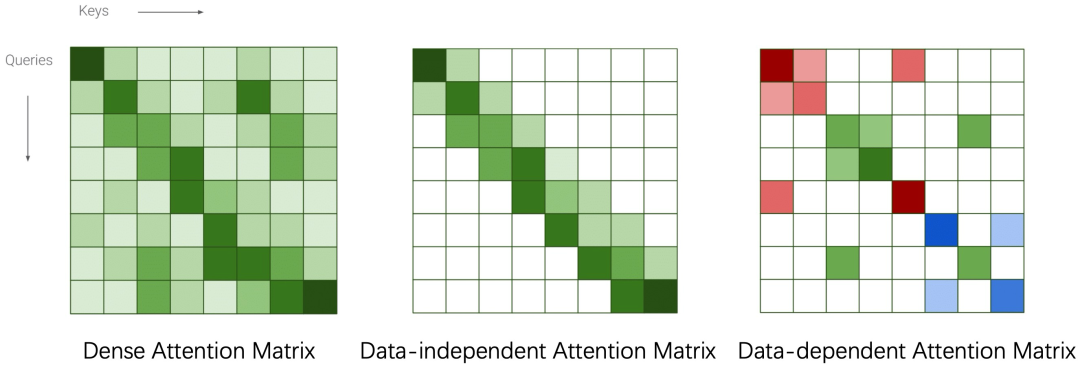
稀疏Transformer的核心思想是通过一些方式将稠密的注意力矩阵变稀疏从而减少理论复杂度。根据稀疏方式的不同分为Data-independent Pattern和Data-dependent Pattern。前者包括Blockwise Transformer[2]、Sparse Transformer[3]、Longformer[4]和Big Bird[5]。后者则包括Linformer[6]、Reformer[7]、Routing Transformer[8]、Clustered Attention[9]、Sinkhorn Transformer[10]。值得注意的是稀疏Transformer的实际效率与显存占用与具体实现方式相关,在很多情况下相比于标准Transformer在速度上有提升但是显存占用不一定符合理论分析。在LLM模型中,GPT3采用的是Sparse Transformer。由于稀疏Transformer的效果必然会比标准Transformer差,在之后的研究中逐渐被抛弃。
线性Transformer
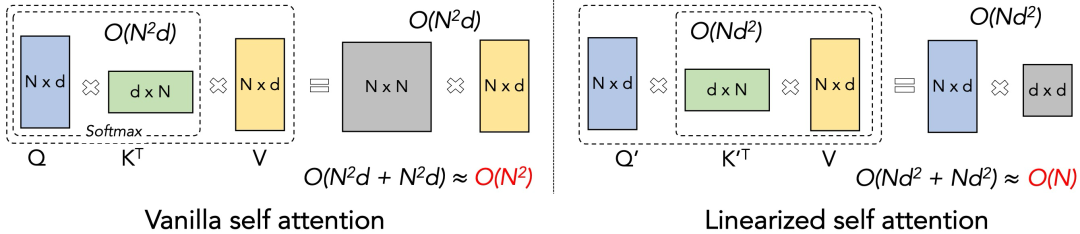
线性Transformer的核心思想是通过Kernel trick的方式,如上图所示,将QKV的左乘变成右乘,从而将理论计算复杂度降为线性。由于SoftMax操作中的exp(<·,·>)运算不满足(Q·K)·V = Q·(K·V)的条件,在cosFormer[11]提出之前,主流解决方案是通过一些满足条件的操作来近似SoftMax。例如RFA[12] 利用Rahimi & Recht 在2007年提出的Gaussian kernel的无偏估计来高效的近似SoftMax注意力。类似的方法还有Linear Transformer[13]、Performer[14]等。这些方案的主要缺陷在于它们都是对softmax的近似,所以效果的天花板即为标准Transformer。同时,因为它引入了额外的计算,所以在d (feature维度)较大的情况下相比于transformer不会有太大的效率优势。实际上,在我们的实验中,大部分方法在实际场景下均比Transformer慢。同时由于这些方法对于超参和网络初始化非常敏感,需要精细化的调参才能得到较好的结果,所以这些在benchmark (Long-Range Arena)的理想情况下效果不错的方法并没有研究人员把它们应用在LLM中。
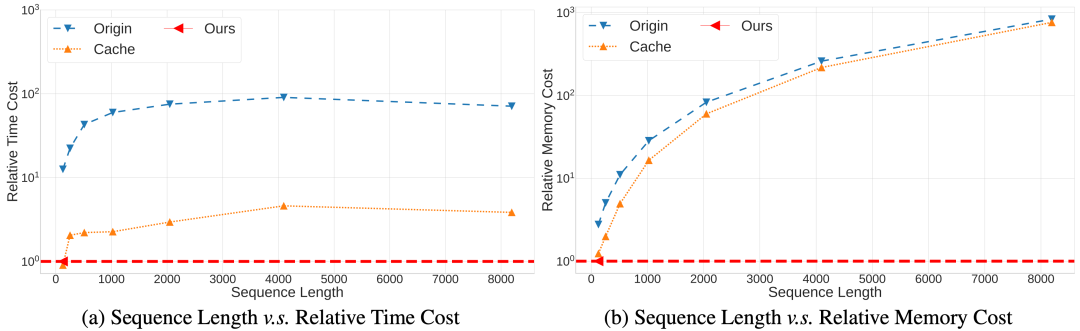
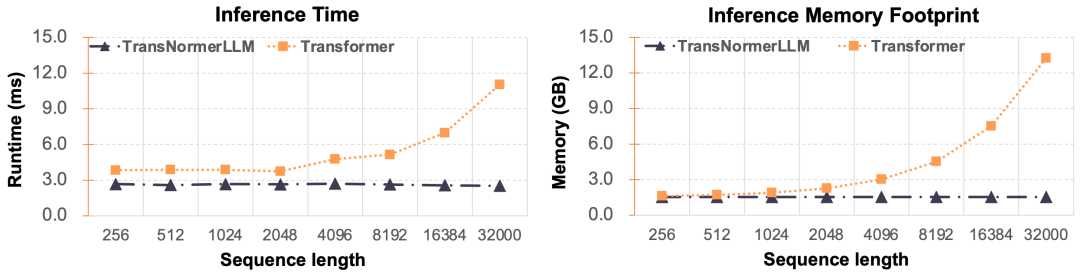
然而,线性Transformer最大的优势在于恒定的推理速度,这样在长序列的预测中相比于Transformer会有巨大的效率优势。如下图所示,Ours为一种线性Transformer,在序列长度增加的情况下,保持了恒定的推理速度、显存占用;同时标准的Transformer以及采用了KV Cache优化的标准Transformer则在序列长度增加的情况下需要数倍至数十倍的时间和显存。
在这个优势下,线性Transformer作为一种有希望的高效序列建模的方向,得到了很多研究人员的关注,并期望可以在LLM下得到实际应用。这项研究的转机出现在cosFormer的提出。研究人员跳出了近似SoftMax的窠臼,采用简单的ReLU激活函数配合cosine函数对邻域加权即可得到类似于Transformer的效果。这种方案极大的简化了线性Transformer的计算,让实际速度超越标准Transformer成为了可能。同时,由于这种方案无需近似SoftMax, 让实际效果超越Transformer亦成为了可能。同年,Qin et al. 在EMNLP会议上提出了TransNormer[15],针对线性Transformer效果达不到标准Transformer给出了理论和实验证明,首次在小规模模型和数据集上超越了标准Transformer。次年,TransNormerLLM[16]集成了多个相对位置编码以及深度的工程优化,提出Lighting Attention的线性注意力架构,首次在效率与模型精度上全面超越标准Transformer,并在175B的超大规模参数和1.6T训练数据下做了初步验证,让线性Transformer进入LLM成为了可能。
长卷积
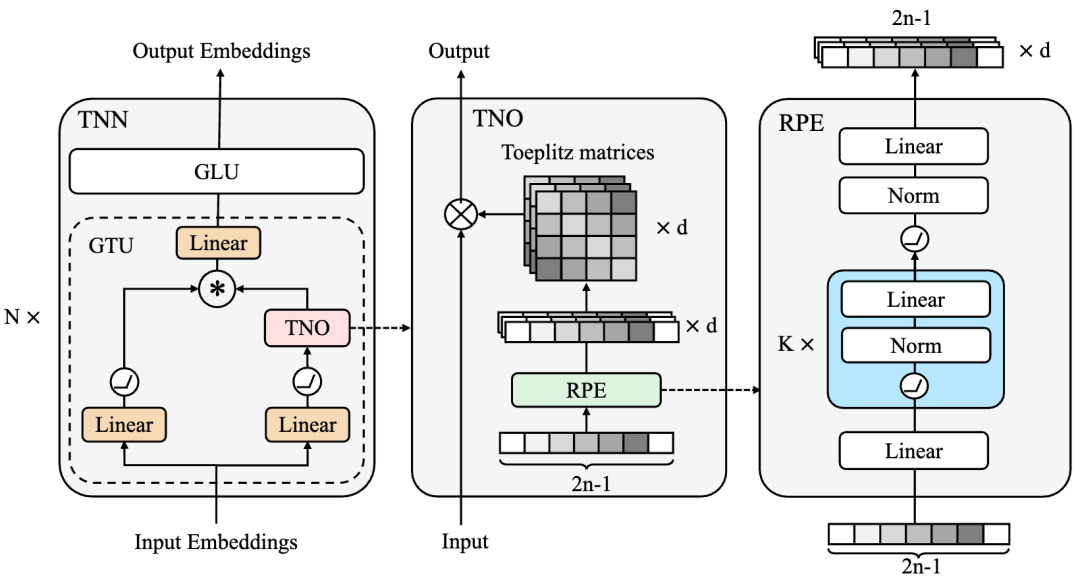
长卷积 (LongConv) 是近期提出一种序列建模方式,其核心思想是通过设计一个核长度为整个输入序列长度的卷积神经网络来建模序列。这种方式的理论计算复杂度为
,空间复杂度为
,n为序列长度,d为特征维度。相比于线性Transformer的
计算和空间复杂度,长卷积在特征维度较大的LLM中会有一定的速度优势。目前基于长卷积的序列建模方法有TNN[17]、H3[18]、Hyena[19]、S4[20]等,值得注意的是,著名的开源项目RWKV也可以写成长卷积的形式。其中TNN采用Toeplitz matrix来刻画相对位置信息并将其作为长卷积的卷积核。S4则采用了一个全新的基于State Space Model (SSM)网络层,将序列建模成一个连续的状态空间的离散表示。
然而想要将这些方法推广到LLM下仍然存在各种困难。例如,LLM训练对于模型的稳定性要求非常高,然而S4因为SSM的数学结构复杂,在生成卷积核的时候需要非常细致的参数初始化才能得到较好的结果,这让S4很难将参数量扩增到千亿规模。TNN虽然对参数不敏感,训练稳定,并且在fp32下相对于Transformer有速度和精度的优势,但是由于其引入了fft,在fp16或者bf16下,速度都很难超越通过Flash Attention优化过的Transformer。如何将TNN做进一步的IO优化使其显示出理论的计算复杂度优势是未来的研究方向之一。除此之外,长卷积的推理理论计算复杂度为O(nd log n),这让这种方法的推理速度略慢于线性Transformer。最新的研究表明,长卷积都可以无损的在推理的时候转化为RNN的模式,从而让它们的推理速度与线性Transformer一致。从当前的研究发现来看,长卷积是一个很有希望的,可以应用在LLM中的结构,但是仍然需要大量的工程优化使其达到理论速度。
循环神经网络
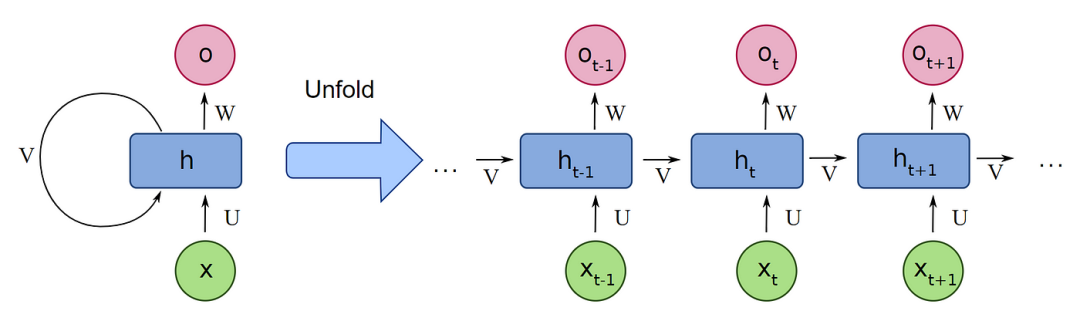
循环神经网络 (RNN) 是一个历史悠久的序列建模方式,其最大的优势在于恒定的推理速度:其推理速度仅跟隐状态大小相关。由于RNN的序列特性,即当前状态基于上一个状态的结果(如下图所示),使得它无法像Transformer一样做到完全并行化处理,并且对GPU处理不友好,从而在深度神经网络的年代逐步被Transformer给取代。
然而,最近的研究表明,RNN以及它们的变种可以被大幅简化而不影响结果。Klaus et al.[21] 在2015年证明了LSTM结构中存在大量多余的门控并强调了遗忘门的重要性。Eric et al.[22] 在ICLR 2018上证明了RNN中间层的非线性并不必须。Shuai et al.[23] 2018 则证明了RNN的循环权重矩阵需要是对角阵,这样RNN不同状态之间可以保证相互独立。同年, Tao et al.[24] 在EMNLP会议上证明了在这种情况下,RNN的隐状态更新可以表示为逐元素的向量积,从而做到完全并行化处理,至此RNN重新站上深度神经网络平台。同时,这种RNN被定义为线性RNN。上文提到的S4也可以写成线性形式,另外一个比较出名的序列建模结构RWKV也归属于这一类。当前先进的RNN架构的问题在于1.绝大多数RNN在语言建模上仍然难以达到比肩Transformer的水平;2. 需要非常精细化的初始化以达到较好的收敛;3. 虽然RNN的理论计算复杂度为
,空间复杂度为
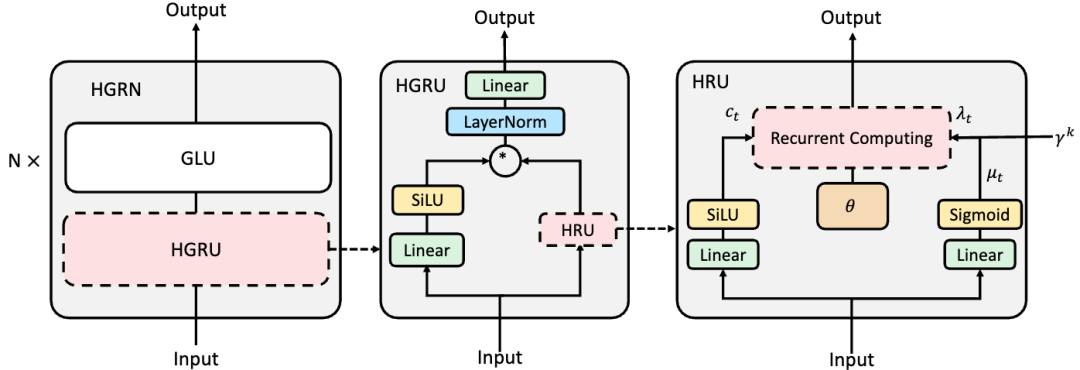
(其中d为隐空间维度大小),为所有的方法中最小,但是在实际效率上仍然难以比肩经过多年优化之后的Transformer。值得注意的是,这一方法在近期的进展迅速,其中Qin提出了如下图所示的分层门控循环神经网络 HGRN[25],首次在较大规模的网络(10亿参数)和大规模语料(3000亿token)上表现出了比Transformer更优的结果,且不需要精细的初始化即可进行稳定的训练,为线性RNN成为LLM的基础架构铺平了道路。
3
高效大语言模型进展
近年来,高效序列建模的算法层出不穷,但是可以落地到大语言模型上的凤毛麟角。主要原因在于LLM的主流还是Transformer架构,并且是已经优化了多年的Transformer架构,甚至在硬件上都有进一步的优化,使得Transformer在效率和效果上都已经接近算法的极限。相比之下,高效序列建模算法作为一个刚起步的算法,即使在理论计算复杂度上有优势,在实际应用中也很难做到效率或者效果上超过优化后的Transformer。同时,训练LLM是一个综合实力的体现,不但需要专业的数据处理团队来采集并处理大量的预训练语料,研究数据配比,也需要模型并行优化工程师针对新推出的结构进行并行优化。更重要的是,训练LLM需要投入大量的资金,高效序列建模的算法往往只在小规模上进行了验证,它们是否在大规模参数和语料下保持一致的训练稳定性和优异性仍然是一个未知数。在这种情况下,采用万无一失的Transformer架构远比新架构的风险低,导致在LLM竞争激烈的当前,Transformer仍为LLM的首选架构。
在高效大语言模型的研发上,RWKV是第一个将参数量扩充到140亿的非Transformer架构的模型,其在开放语料Pile上进行了预训练,达到了和Transformer相当的水准。近日,上海人工智能实验室提出TransNormerLLM,首次将线性Transformer的参数量扩充到了1750亿,并实现了模型并行速度优化,在速度和精度上均超越了基于Flash attention的Transformer。其中训练速度比Flash attention Transformer快20%,困惑度 (ppl)比Flash attention Transformer低9%。在推理速度上,如下图所示,由于TransNormerLLM的恒定的推理速度优势,在长序列上有着数倍的效率提升,且序列越长,提升越明显。
LLM的效率体现在训练效率和推理效率上。由于架构的特性,TransNormerLLM在推理上对于Transformer有无可比拟的速度优势,如此以来,在高效LLM的优化中,我们只需要着重考虑训练效率的提升以及推理的稳定性。根据优化方向的不同,我们将影响的LLM的训练速度的因素分为三大块:1. 网络结构优化,包括位置编码的设计、门控机制、激活函数、张量归一化的方式等;2. 算法工程优化,包括attention算子的实现方式、归一化函数的实现方式等;3. 分布式系统的优化,包括张量并行、模型并行方式的实现等。通过上述方面的高度优化,TransNormerLLM做到了在生产环境下的训练效率上超过了经过Flash attention加持的Transformer架构。同时,我们提出了新的鲁棒推理算法,从理论上证明了新算法可以极大的维持LLM的推理数值稳定性。接下来,我们将介绍TransNormerLLM优化的技术细节。
结构优化
-
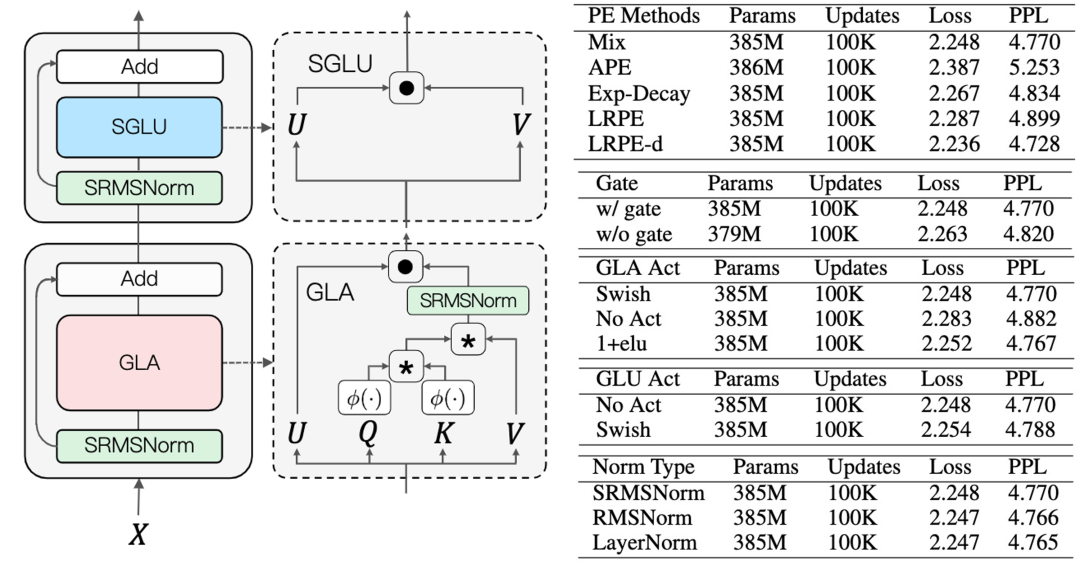
位置编码:线性Transformer有注意力分散的先天缺陷。为了解决这个问题,原版TransNormer的解决方案是在网络的前几层采用稀疏注意力结构中的对角注意力。但是由于采用的仍然是SoftMax注意力机制,这种方案对长序列不友好,同时也舍弃了Transformer中token的全局交互能力。在TransNormerLLM中,我们改进了这个方案,采用我们在TMLR 2023上提出的LRPE位置编码并结合指数衰减来达到同样的目的,同时保留token的全局交互能力。相比于绝对位置编码,我们发现采用上述的位置编码可提升10%的模型效果(ppl)。同时经过进一步的实验我们发现,只在网络的第一层加入LRPE,剩余的层采用指数衰减可以加速模型20%并且没有明显的性能损失。因此,我们最终的模型即采用的上述位置编码方案。
-
门控机制:我们引入了门控机制来提升模型的性能和训练的稳定性。如下图所示,我们分别在GLA (Gated Linear Attention)和GLU (Gated Linear Unit)中添加了门控机制。在GLA中,我们同时对比了多种门控激活函数,相比于不添加激活函数,采用Swish激活函数可以将性能提升3%。为了加速模型,我们将GLU中的激活函数取消,我们发现在GLU中不加激活函数对模型性能影响不大。
-
张量归一化:为了解决线性Transformer中梯度无界导致训练收敛不佳的问题,TransNormer采用直接对于QKV的乘积做归一化的方式来让梯度收敛,其采用的归一化方式为RMSNorm。在TransNormerLLM中,我们发现将RMSNorm中的可学权重参数去掉并不会影响结果,为了简化模型,我们去掉了这个权重参数并将这种归一化方式称为SRMSNorm (Simple RMSNorm)。 这样,TransNormerLLM的最终结构为下左图所示。
算法优化
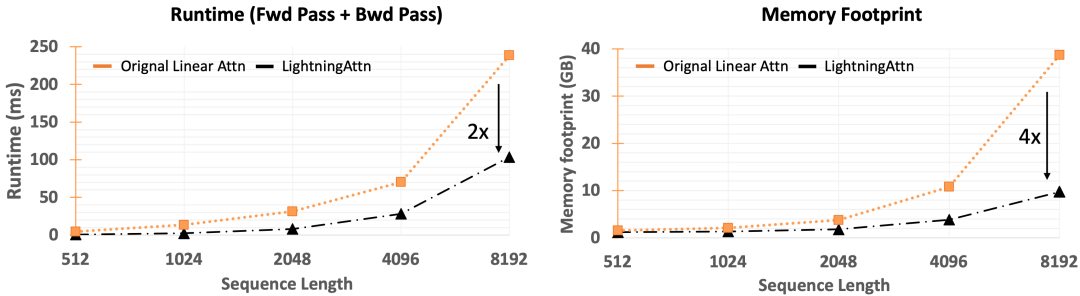
算法的性能与算法的工程优化程度高度相关,之前的高效序列建模的方法在生产环境中相比于Transformer无法显示出其本身的效率优势的一大因素就是缺乏工程优化。在TransNormerLLM中,我们针对线性Attention和归一化函数做了细致的工程优化:1. 我们提出了Lightning Attention并用Triton做了大量的IO优化,实现了2倍的速度提升以及减少了3/4的显存占用;2. 我们优化了SRMSNorm的实现方式,实现了数十倍的效率提升。
-
Lightning Attention 线性Attention的理论计算效率优势体现在QKV的右乘上,将理论计算复杂度从O(n^2d)降到了O(nd^2)。但是在语言模型中,右乘的运算需要通过一系列的对并行不友好的循环来实现,在实际的大规模并行运算中,往往比左乘更慢。所以在我们的实现中,仍然采用左乘的形式。具体算法如下:

下图显示了经过我们的工程优化,当前的Triton版Lightning attention比Pytorch版提升了2倍的速度和4倍的显存优势。
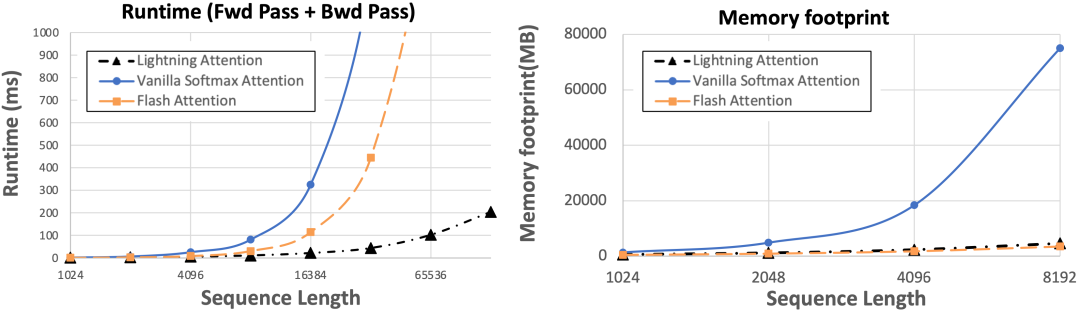
值得注意的是,我们也有右乘的实现,解决了右乘并行运算问题,将Lightning Attention做了进一步的加速。如下图所示,Lightning算法在常见的8k序列长度的时候已经比Transformer下最先进的Flash attention 2快了1倍,当序列长度继续增加的时候,Lightning attention的优势持续增大,在132k下达到了十倍以上的差异。
-
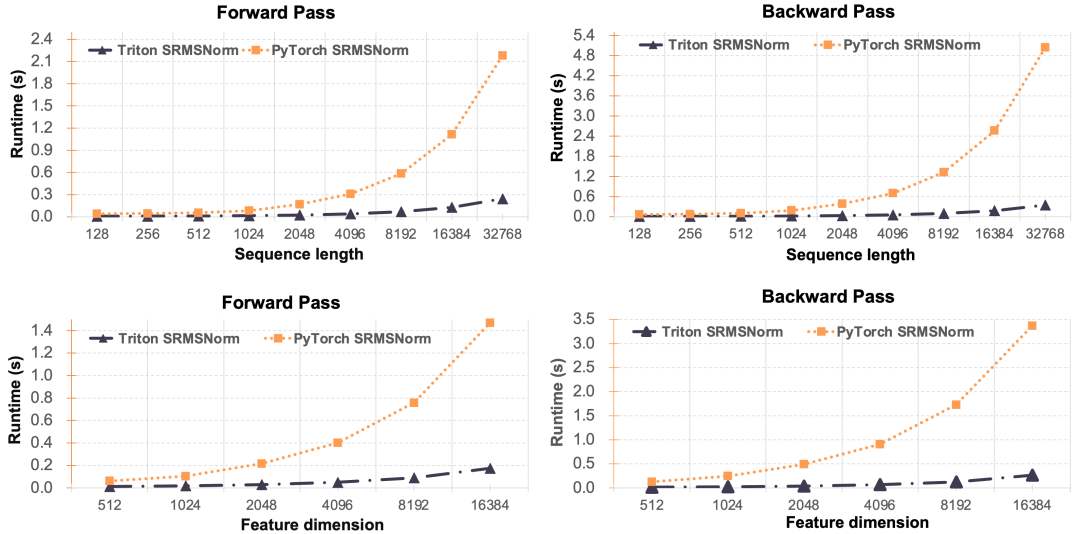
SRMSNorm 类似于Lightning Attention,我们同样对于SRMSNorm做了工程优化,如下图所示,我们的Triton版SRMSNorm相比于Pytorch版实现的令人惊异的优势。
系统优化
我们的TransNormerLLM模型采用Fully Sharded Data Parallel (FSDP)技术来在整个集群中分配参数、梯度和优化器状态。我们也采用了Activation Checkpointing技术来减少误差反传的显存占用。另外,不同于之前的高效序列建模方法往往只能工作在fp32下或者只在fp32下才能显示出效率优势,我们的算法实现了Automatic Mixed Precision (AMP)来减少显存开销,并且在BFloat16下同样显示出了训练的高效性和稳定性。除此之外,我们还针对TransNormerLLM做了模型并行。值得注意的是,由于Transformer跟TransNormer在网络基础架构上的差异,我们无法沿用之前Transformer的模型并行方案,但是我们的模型并行很大程度上受到了Nvidia 的 MegatronLM 模型并行的启发。在传统Transformer架构中,每一层都包括一个自注意力模块和两层多层感知器(MLP)模块,使用时Megatron-LM在这两个模块上独立使用模型并行。同样,TransNormerLLM每一层也包含两个模块SGLU和GLA,我们分别对每个模块执行模型并行。下图我们对比了不同的模型大小和速度,以及最大的训练序列长度。

推理优化
线性Transformer的一大优势就是在推理的时候可以转化为RNN的形式,让推理速度跟序列长度无关。但是在实际中我们发现,直接的转化(下图左)会造成数值精度不稳定问题。为了解决这个问题,我们提出了一个新的鲁棒推理算法(下图右)来保证推理时候的数值稳定性。
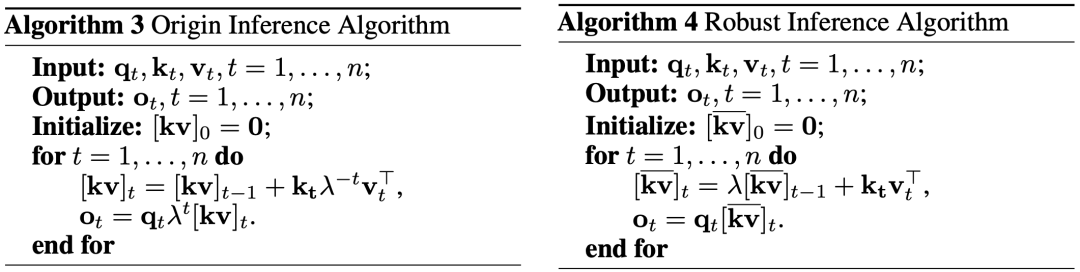
4
数据处理
LLM的最终效果跟模型结构和预训练数据相关。其中,预训练数据的质量与数量对最终LLM的效果的影响远大与模型结构。我们在标准学术数据集的评测中已经展现出了当前的模型结构无论在效率还是效果上均优于Transformer架构,为了训练高质量的高效LLM模型,我们仍然需要高质量的预训练数据来训练LLM。由于当前各个公司和研究机构的LLM的预训练语料都处于非公开状态,我们独立从互联网上收集了大量可公开访问的文本,总计超过 700TB。收集到的数据经过我们如下图所示的数据预处理程序进行处理,留下 6TB 的清理语料库,其中包含大约 2 万亿个token。
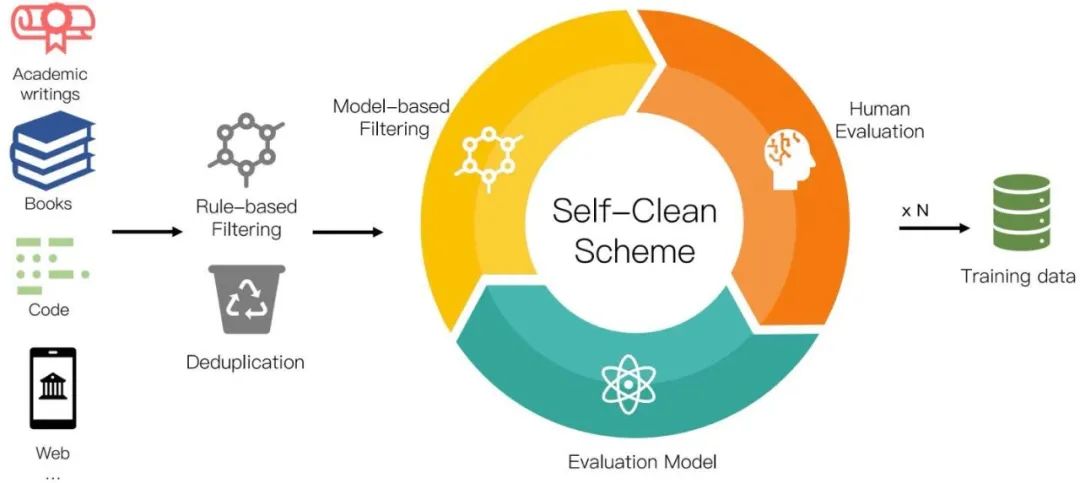
我们的数据预处理过程包括三个步骤:1). 基于规则的过滤,2). 重复数据删除、和 3). 自清洁过滤。具体数据处理方法见论文。在添加到训练语料库之前,清理后的语料库需要由人类来评价。我们最终的数据分布如下图所示:
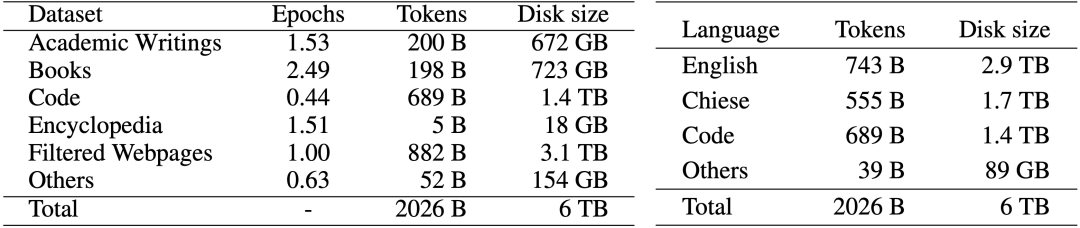
5
Benchmark结果
我们在自己的预训练数据集上训练了385M,1B,以及7B大小的模型,并在标准的LLM学术Benchmark上评测了我们的结果。针对常识性任务,我们选取BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC easy and challenge, 和OpenBookQA Benchmarks。我们采用0-shot LM-Eval-Harness作为我们的评测方式。对于综合任务,我们选取5-shot 的MMLU,CMMLU和C-Eval Benchmark的结果作为我们的中英文评测结果。 如下表所示,我们的模型在385M,1B,7B均体现出了非常有竞争力的结果。在英文上,我们的模型仅次于LLaMA2,ChatGLM2,和Baichuan2;在中文上,我们仅次于ChatGLM2和Baichuan2。其中PS表示模型大小,单位是Billion,T表示训练的token数,单位是Trillion。HS表示HellaSwag,WG表示WinoGrande。值得注意的是,当前我们的7B模型在预训练阶段的序列长度为8K。在我们的Lightning Attention V2中,已经实现了训练速度与序列长度无关,所以未来的TransNormerLLM将可以采用硬件限制下的最大预训练长度,在无损速度的情况下进行全量预训练。
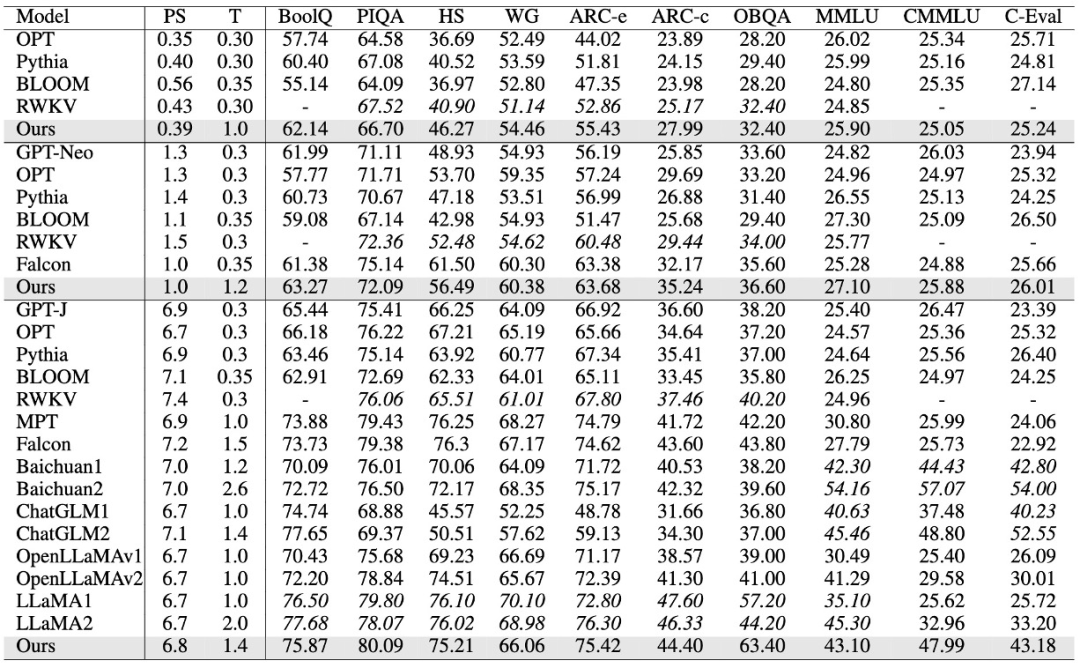
6
高效大语言模型展望
无可否认,TransNormerLLM的提出和开源将是大语言模型发展历程中的重要里程碑。而这一转变,预示着我们正从标准Transformer架构的优化阶段步入到高效大语言模型的优化上。我们相信,在广大研究者的共同努力下,高效大语言模型的技术将日臻成熟,应用领域将更加广泛。这样的变革,如同一场盛大的交响乐,我们期待着下一个音符的出现,期待着高效大语言模型的下一个篇章。
7
相关资料
论文地址:
https://openreview.net/pdf?id=OROKjdAfjs
开源代码:
https://github.com/OpenNLPLab/TransnormerLLM
开源模型:
https://huggingface.co/OpenNLPLab
参考文献:
Language Models are Few-Shot Learners: https://arxiv.org/abs/2005.14165
[2]Blockwise Self-Attention for Long Document Understanding: https://arxiv.org/abs/1911.02972
[3]Generating Long Sequences with Sparse Transformers: https://arxiv.org/abs/1904.10509
[4]Longformer: The Long-Document Transformer: https://arxiv.org/abs/2004.05150
[5]Big Bird: Transformers for Longer Sequences: https://arxiv.org/abs/2007.14062
[6]Linformer: Self-attention with linear complexity: https://arxiv.org/abs/2006.04768
[7]Reformer: The efficient transformer: https://arxiv.org/abs/2001.04451
[8]Efficient content-based sparse attention with routing transformers: https://arxiv.org/abs/2003.05997
[9]Fast transformers with clustered attention: https://arxiv.org/abs/2007.04825
[10]Sparse sinkhorn attention: https://arxiv.org/abs/2002.11296
[11]cosformer: Rethinking softmax in attention: https://arxiv.org/abs/2202.08791
[12]Random feature attention: https://arxiv.org/abs/2103.02143
[13]Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention: https://arxiv.org/abs/2006.16236
[14]Rethinking attention with performers: https://arxiv.org/abs/2009.14794
[15]The devil in linear transformer: https://arxiv.org/abs/2210.10340
[16]Scaling TransNormer to 175 Billion Parameters: https://arxiv.org/abs/2307.14995
[17]Toeplitz Neural Network for Sequence Modeling: https://arxiv.org/abs/2305.04749
[18]Hungry Hungry Hippos: Towards Language Modeling with State Space Models: https://arxiv.org/abs/2212.14052
[19]Hyena Hierarchy: Towards Larger Convolutional Language Models: https://arxiv.org/abs/2302.10866
[20]Efficiently Modeling Long Sequences with Structured State Spaces: https://arxiv.org/abs/2111.00396
[21]LSTM: A Search Space Odyssey: https://arxiv.org/abs/1503.04069
[22]Parallelizing Linear Recurrent Neural Nets Over Sequence Length: https://arxiv.org/abs/1709.04057
[23]Independently Recurrent Neural Network (IndRNN): Building A Longer and Deeper RNN: https://arxiv.org/abs/1803.04831
[24]Simple Recurrent Units for Highly Parallelizable Recurrence: https://arxiv.org/abs/1709.02755
[25]Hierarchically Gated Recurrent Neural Network for Sequence Modeling: https://neurips.cc/virtual/2023/poster/71783
更多大模型内容在「大模型项目开发线上营」
前20人报名,除了VIP年卡外,还多送两个大模型小课:类ChatGPT微调实战、LLM与langchain/知识图谱/数据库的实战,如已有这两课,可以选同等价位别的课
↓↓↓扫码抢购↓↓↓
课程咨询可找苏苏老师VX:julyedukefu008或七月在线其他老师
点击“阅读原文”了解课程详情~
