
模型压缩大杀器!详解高效模型设计的自动机器学习流水线

极市导读
本文首先对模型压缩进行了综述,论述目前深度学习存在的挑战,同时对三种高效自动机器流水线方法ProxyLessNAS、AMC和AMC进行了详细的介绍。最后探讨了如何进行网络体系结构、剪枝和量化策略的联合搜索。>>周二直播!田值:实例分割创新式突破BoxInst,仅用Box标注,实现COCO 33.2AP!
目录
为什么要进行Model Compression?
论述当前深度学习存在的挑战。
自动机器学习流水线 (AutoML Pipeline):让模型更加高效
简述自动机器学习的流水线。
第1步:ProxyLessNAS:搜索最适宜的模型架构。
第2步:AMC:压缩模型,减少参数量。
第3步:HAQ:进一步量化模型,减小内存占用。
自动机器学习流水线的演进
论述如何进行网络体系结构、剪枝和量化策略的联合搜索。
1 为什么要进行Model Compression?
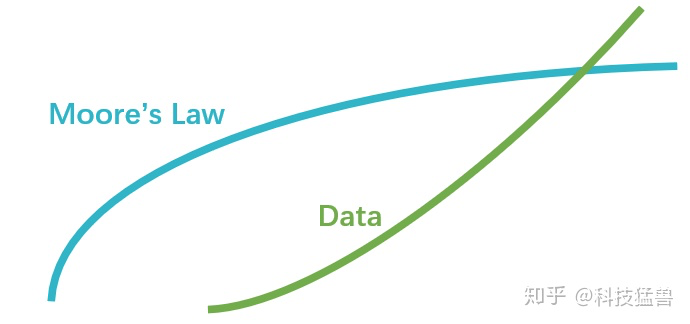
摩尔定律告诉我们:芯片的性能每隔18个月将会提高一倍。
尽管摩尔定律的现象已经被观察到了数十年,但是,它仍应该被视为一种对现象的观测或对未来的推测,而不是一个物理定律。
换句话说,未来的增长率在逻辑上无法保证会跟过去的数据一样,也就是逻辑上无法保证摩尔定律会持续下去。而且,摩尔定律已经在2013年年底放缓。
比如说英特尔在22纳米跟14纳米的CPU制程上已经放慢了技术更新的脚步,之后的时间里,晶体管数量密度预计只会每3年增加一倍。
而另一方面,在现代深度学习中,更复杂的问题往往需要更复杂的计算量来处理;摩尔定律的放缓使得当前的算力往往无法满足复杂AI问题的要求,尤其是在移动端这种算理有限的设备上面。
评价一个深度学习模型,除了Accuracy之外,我们还要考虑下面这5个方面:
延迟:Latency (ms) 能耗:Energy Consumption (J/度电) 计算量:Computational Cost (FLOPs/BitOPs) 模型参数量:Parameter (M) 运行占用内存:Memory (MB)
所以当前深度学习面临的一个挑战是:模型非常大 (Large Model Size),也就需要大量的能源消耗 (Large Energy Consumption),密集的计算量 (Computation Intensive)和密集的内存占用 (Memory Intensive)。以上问题使得模型在部署的过程中会遇到很大的挑战。
举一个例子: AlphaGo打一局比赛约需要1920块CPU和280块GPU的算力,以及3000$的电费(electric bill),对于端侧设备 (Edge-side devices)来讲,会很快耗尽电池的电量 (Drains Battery);对于数据中心来讲会增加总持有成本TCO (Total Cost of Ownership)。

所以,模型压缩对于深度学习的部署来讲意义重大,尤其是硬件资源受限的端侧设备。
模型压缩的方法有很多,可以参考下面的链接:
深入浅出的模型压缩:你一定从未见过如此通俗易懂的Slimming操作
科技猛兽:模型压缩工作总结
https://zhuanlan.zhihu.com/p/262359207
借助AutoML技术,可以使得深度学习模型变得更加高效,以部署在端侧设备上面。所以本文介绍的重点是这一流水线具体是什么样的,以及后续有哪些改进的工作。
2 自动机器学习流水线 (AutoML Pipeline):让模型更加高效
2.1 自动机器学习的流水线
自动机器学习流水线是指基于自动机器学习(AutoML)完成模型的优化过程。
输入: 模型要部署的目标硬件设备。约束条件(Latency,Energy Consumption,Model Size,Memory,FLOPs等)。
输出: 部署的模型。
中间过程:
AutoML搜索最适宜的模型架构,最大化精度。
对这个模型进行压缩,减少参数量。
对压缩后的模型进行量化,进一步减少内存占用。
2.2 第1步:ProxyLessNAS:搜索最适宜的模型架构
MIT: ProxyLessNAS: Direct Neural Architecture Search on Target Task and Hardware
刚才讲到,当把模型部署在手机,头盔,智能手表,手环等移动端设备的时候,我们不仅希望模型的准确度高,还希望它具有低的延迟和低的耗电量。以往的做法是将相同的模型不加改进而直接部署在多种设备上面,比如下图:
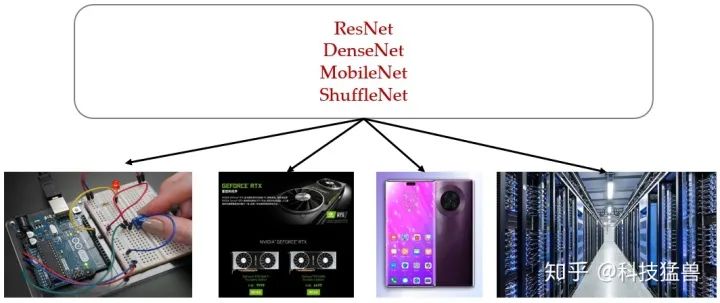
这种做法的优点是简单快捷,不需要任何额外的设计成本;但是这种做法的缺点是没有考虑到不同硬件设备之间的差异性:比如GPU的并行度 (Degree of Parallelism)比CPU要高,cache size更大,内存带宽 (Memory bandwidth,单位时间里存储器所存取的信息量,也称为存储器在单位时间内读出/写入的位数或字节数)性能也有不同。因此使用同样的模型得到的结果往往是次优的。
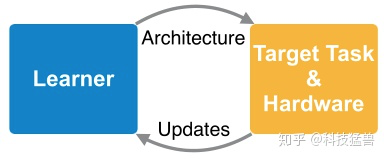
ProxyLessNAS解决的就是这个问题,即希望针对不同的硬件设备专业化神经网络模型,以在目标硬件设备上面获得更好的准确率和较高的硬件效率。
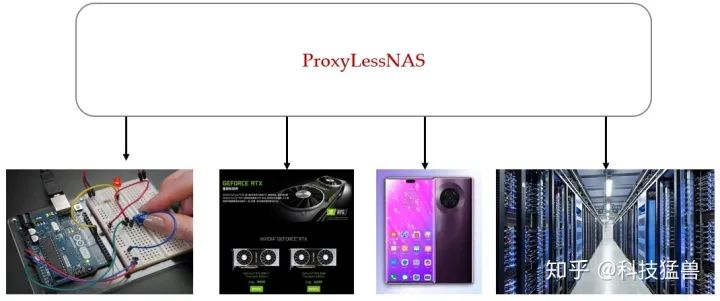
为每个硬件设计专门的深度学习模型代价是十分高昂的,往往需要请一个组的深度学习专家来进行模型设计和调参,显然是无法承受的。于是我们考虑使用AutoML的方法,自动化地设计神经网络的模型,来替代人类专家进行神经网络架构的设计,一定程度上能够解决人力资源不足的问题。
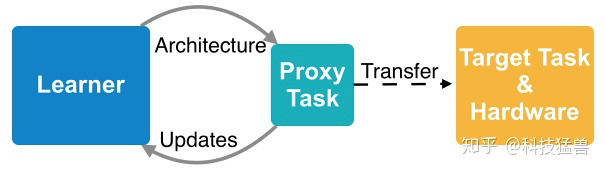
但是,神经架构搜索的成本是十分高昂的,谷歌提出的NASNet在小规模数据集CIFAR-10上面搜索一次所需要的时间,换算成单块GPU大约需要5年。所以,考虑到这样巨大的计算资源的要求,之前的神经架构搜索算法大多采用基于代理 (Proxy)的方法。
代理任务 (Proxy Task)相比于目标任务 (Target Task),一般具有:
更小的数据集 (e.g. CIFAR→ImageNet) 训练更少的epochs 更小的搜索空间 使用更浅的模型。
总之,代理任务相当于是目标任务的缩小简化版。之后,把代理任务搜索得到的结果迁移到目标任务上面,如下图所示:
这样做的问题有3点:
在代理任务上搜索得到的最优结果在目标任务上是次优的,尤其是当考虑Latency时。 需要堆叠重复的单元,限制了块的多样性,从而降低了性能。 不能根据目标任务的实际硬件要求进行优化。
ProxyLessNAS提出的动机就是为了解决以上的3点限制,作者希望能直接在目标任务和硬件 ( target task and hardware)上搜索出最优模型的架构,而避免使用代理Proxy,这解决了上面的第1个问题。同时,ProxyLessNAS不去堆叠重复的单元,每个block都可以被搜索,这解决了上面的第2个问题。最后,ProxyLessNAS还能考虑目标硬件的Latency,这解决了上面的第3个问题。ProxyLessNAS实现的结果如下图:
首先简述ProxyLessNAS的做法:
把NAS的过程视为路径级剪枝的过程 (Path-level Pruning)。首先训练一个包含所有的操作的超网络 (over-parameterized network)。每个操作有自己的二值化架构参数和权重参数,并采样梯度下降的方法训练二值化的架构参数,那些架构参数比较低的操作到最后将会被剪掉。
在训练这个超网络的时候,由于操作数量很多,会导致GPU显存不足 (GPU memory explosion),这个问题很常见,因为GPU显存会随着候选操作的数量呈线性增长。解决的办法是每次只激活一条路径进行训练,即:每个操作的架构参数是二值化的。每次更新参数时,只允许一个操作处于激活状态。这样一来,GPU的显存的需求的复杂度就会从 变为 。
在One-Shot NAS方法中:
在DARTS方法中:
二值化就是每次只激活一条路径,表达式是:
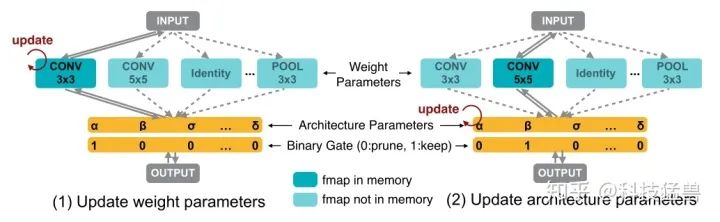
图7所表达的含义就是每次只激活一条路径进行更新参数。具体怎么更新呢?
首先取一个batch的数据,根据 式采样出一个 ,这时候就相当于只激活了一条路径,其他未被激活的路径的参数被freeze了。 使用training set 来update采样的这条路径的参数,如上图左所示。 再根据 式采样出一个 ,使用validation set 来update架构参数,如上图右所示。 上述3步迭代执行。
更新架构参数时,首先要明确这里的架构参数是什么?答案是: ,这些 通过 的操作得到 ,再通过采样得到 ,最后, 再参与计算图。所以,在反向传播时,我们手里有的只是 。可我们要计算的是 。
那么具体的方法是:
在反向传播时,以上所有的参数都已知了,于是可以求出 。
但这样做也存在一个问题,即你需要保存所有的 ,使得GPU memory变成了 ,即显存使用量依然与 相关。
为了解决这个问题,作者采取的做法是:
首先根据(3)式sample出2条路径,屏蔽其他的路径,这样强制使得 。 采样之后, 和 将会被重置。 根据(4)式更新这2条路径的架构参数 ,更新完后,乘上一个系数,保持二者之和不变,即始终保持未被采样的路径的架构参数之和不变。
一个采样路径被增强(路径权重增加),另一个采样路径被衰减(路径权重降低),而所有其他路径保持不变。以这种方式,不管 的值如何,在架构参数的每个更新步骤中只涉及两条路径,从而将存储器需求降低到训练紧凑模型的相同水平。
说白了,就是我更新架构参数的时候不更新所有的架构参数,只采样2条路径,更新这2条路径的架构参数,同时保持未被采样的路径的架构参数之和不变。
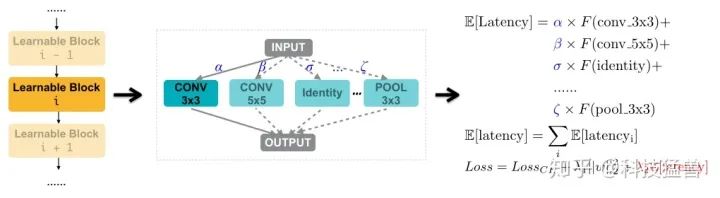
除此之外,为了解决第3个问题,就必须把延迟Latency作为目标函数要考虑的部分。但是,Latency这个指标是不可微分的 (non-differentiable),因此,得想个办法把Latency这东西变得可微分。
做法是:首先在目标硬件上收集各种候选操作的延迟Latency,构成一个数据集,去搭建一个延迟预测的模型。这样一来,基于这个模型就可以获得网络的延迟预测期望值。这个期望值就可以作为一个正则项,整合到损失函数当中,通过梯度进行直接的优化。
假设网络一共有 个Block,对于第 个Block来讲,我们求出它的Latency的期望值:
式中的 表示第 个候选操作。 表示这个predictor的预测值。
在反向传播求微分时,表达式就变为了:
而式中的 是已知的。
最后,总的网络的Latency可以写成:
这一流程可以表示为图8:
损失函数为:
通过调节超参数 就能根据目标任务的实际硬件调整模型的复杂度。
实验结果:
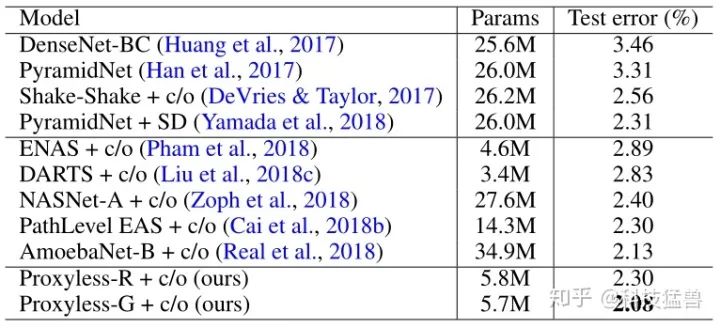
实验1: 首先在CIFAR上进行验证,只使用 的参数就能达到之前的准确率的效果。
实验2: 接着在ImageNet上进行搜索,在实验中作者使用了3种硬件平台,分别是mobile phone, GPU 和 CPU。Latency的测试,分别使用:
V100 (GPU,batch size=8) Intel(R) Xeon(R) CPU E5-2640 v4 (CPU,batch size=1) Google Pixel 1 phone (mobile phone,batch size=1)
通过下图10 (mobile phone测试) 可以清晰地看出ProxyLessNAS在延迟和精度方面的提升:
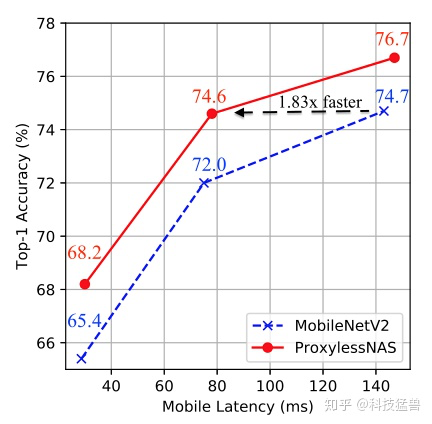
通过下图11 (GPU测试) 可以清晰地看出ProxyLessNAS在延迟和精度方面的提升:
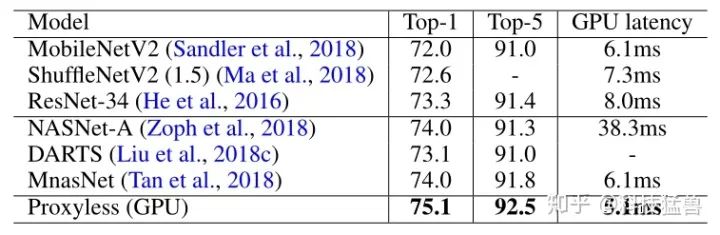
因为对比的网络都是为mobile phone设计的,所以在GPU上ProxyLessNAS的优势更加明显。
实验3: 对比ProxyLessNAS在不同硬件设备上的结果:
一个有趣的发现是:GPU上搜到的模型只在GPU上高效;CPU上搜到的模型只在CPU上高效;mobile phone上搜到的模型只在mobile phone上高效,这就表明了我们一开始的结论:为不同硬件设计专门化的神经网络的正确性和必要性。


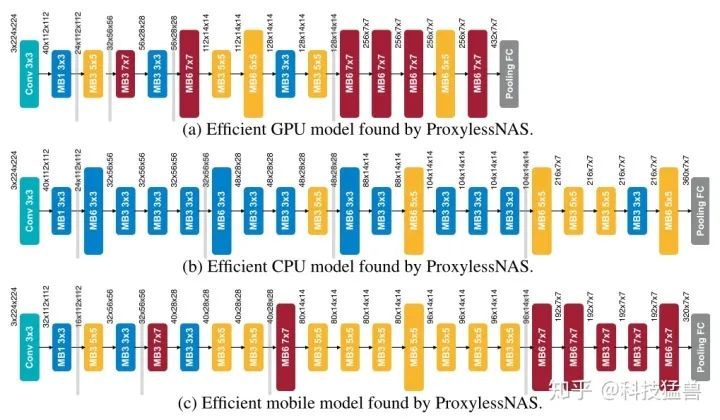
图13展示了搜索出的适合不同硬件设备 (GPU,CPU,mobile phone)的专门化的网络。不同硬件平台在搜索过程中,模型会逐渐表现出不同的特性。
搜索空间的设计方面,为了使网络可深可浅,候选操作中加入 即可。
比如最上方的代表GPU端最适宜的模型,它倾向于选择更浅的模型和更大的块 (shallow and wide model with early pooling)。
比如最中间的代表CPU端最适宜的模型,它倾向于选择更深的模型和更小的块 (deep and narrow model with late pooling)。
这是因为GPU比CPU具有高得多的并行性,因此它可以利用大的MBConv操作。
至此,我们完成了AutoML Pipeline的第1步:搜索出适宜该硬件的最佳模型,接下来进入压缩过程。
2.3:第2步:AMC:压缩模型,减少参数量
MIT: AMC: AutoML for Model Compression and Acceleration on Mobile Devices
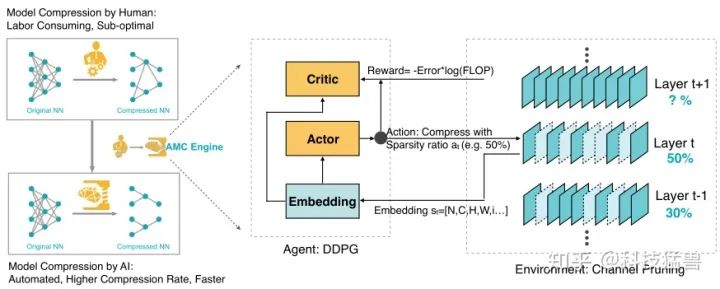
在神经网络的压缩过程中,每一层的压缩比可以是由有经验的工程师来决定。所以,人力资源成为了这项任务的瓶颈。手工压缩方法需要相关领域的专家知识,需要人工在推理速度,大小与准确率之间权衡,因此人工给出的压缩比往往是次优的。因此,我们希望借助AutoML技术,找到一种自动给出神经网络每层压缩比的方法,用AI来优化AI,以减少人力资源的消耗。这就是AMC (AutoML for Model Compression and Acceleration on Mobile Devices)方法的初衷。
在之前的工作中有许多基于规则的模型压缩方法,比如在神经网络的第一层剪枝量小;在FC层中剪枝量大;在对剪枝量比较敏感的层中剪枝量小等等。然而,这样的剪枝方法是次优的。所以我们希望AutoML自动地给出每一层剪枝量的数值。
AMC通过使用强化学习的方法,设置一个DDPG的agent。压缩模型的精度对于每一层的稀疏度非常敏感,要求一个细粒度的动作空间。所以,把每一层的剪枝率建模为连续的数值 (continuous compression ratio) ,并在强化学习的奖励信息时,综合考虑模型的精确度和模型复杂度。在agent运行时,为agent输入某一个Layer 的相关信息,它可以自动输出这个Layer的剪枝率 。之后,再为agent输入下一个Layer 的相关信息,这样不断循环完整个网络。
AMC针对不同的场景提出了2种compression policy:
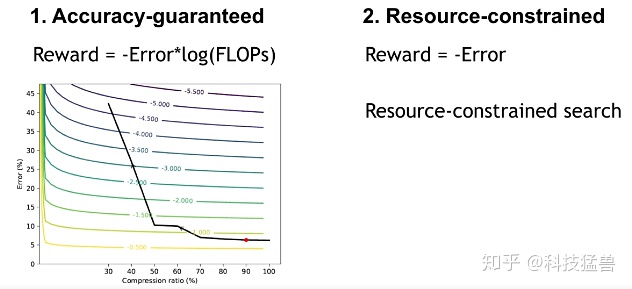
对于延迟关键型 (Latency-critical) 的AI应用 (手机应用,自动驾驶,广告排名等),目标是在给定硬件设备资源限制 (FLOPs, latency, and model size)的条件下获得最高精度。此时作者限制了搜索空间,其动作空间(修剪比例)被限制,从而使代理下的压缩模型总是在资源预算下。
对于质量关键型 (Quality-critical) 的AI应用 (Google Photo等),目标是在不损失精度的前提下得到最小的模型。此时作者定义了一个关于精度和硬件资源的奖励函数,在不伤害模型精度的情况下能够探索压缩限制。
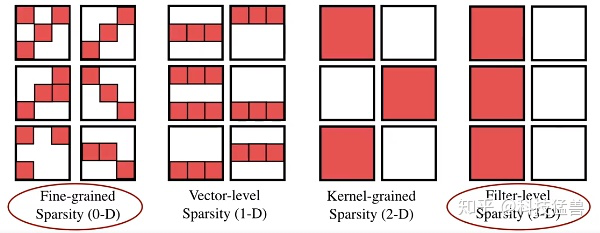
剪枝的方法分为2类:fine-grained pruning (细粒度剪枝)和structured pruning (粗粒度结构化剪枝)。
Fine-grained pruning [5]就是剪掉权值矩阵 (weight tensor)中的不重要的某个元素,这种方法可以在不损失精度的前提下得到高精度。但是这种细粒度的方法会导致不规则的稀疏矩阵,且往往需要专门设计的硬件 [6]。一般用于减小模型大小。
Coarse-grained pruning 旨在剪去权重张量中的整个规则区域,比如说整个channel,block等等。这里我们研究结构化修剪方法,剪枝每个卷积层和全连接层的输入通道。这种方法不需要专门设计的硬件。
比如,对于一个卷积层 ,细粒度剪枝的稀疏度定义为: ,即0元素的个数除以总的元素个数。对于结构化剪枝,压缩channel数之后为 稀疏度定义为: 。一般用于模型加速。

如图16所示为AMC的整体流程,主要有2部分组成,左侧是一个DDPG的强化学习Agent,右侧是一个神经网络压缩的环境,以channel pruning为例。我们将神经网络的压缩建模为一个自底向上,逐层进行的过程。
状态空间:
其中:
该层的kernel的维度为: 。
该层的输入为 。
是第几个Layer。
是该层的计算量。
Reduced是先前层减少的计算量。
Rest是下面层的剩余的总数量。
状态空间里的每一维都会归一化到[0, 1]。
动作空间:
作者提出使用连续的动作空间 ,支持更细粒度的和更精确的压缩。
环境 Environment:
硬件设备就相当于是强化学习的Environment,给RL Agent反馈,使之满足资源约束。
搜索协议:
资源受限型压缩: 通过限制动作空间(每层的稀疏比),我们可以精确地到达目标压缩比。我们使用以下的奖励:
这个奖励并没有提供model size reduction的激励,因此我们可以通过限制动作空间来达到目标压缩比。下面的算法描述了该过程:在最开始几层作者允许任意的压缩比 。用最大的压缩比压缩完接下来所有的层后,如果网络的压缩比满足给定的硬件限制,则使用 对这一层进行压缩。否则就增大 。
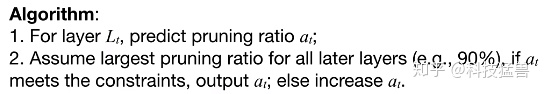
精度保证型压缩: 通过调整奖励函数,我们可以精确地发现压缩的极限而无精度损失。
这个奖励函数对误差更敏感,与此同时,它提供了一个对于减少运算量或模型大小的激励。agent可以自动化地找到压缩的极限。
AMC的具体算法是:

实验结果:
实验1:CIFAR-10:
作者在 CIFAR-10 上对 AMC 进行了全面分析,以验证 2 种搜索策略的有效性。 CIFAR 数据集包括 50k 训练和 10k 测试 10 个类别的 32×32 微小图像。 作者将训练图像分成 45k / 5k 训练/验证。 在验证图像上获得准确性奖励。 作者的方法具有很高的计算效率:RL 可以在 1 小时内在单个 GeForce GTX TITAN Xp GPU 上完成搜索。
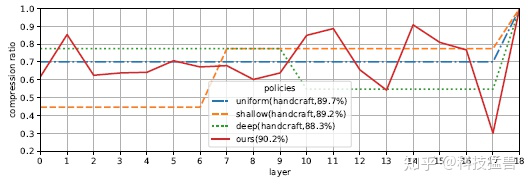
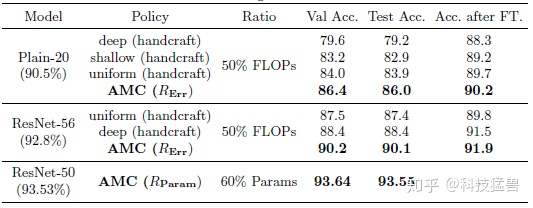
如上图19所示为在 CIFAR-10 上进行的FLOPs-Constrained Compression的实验。对比了三个经验策略:uniform 为均匀设置压缩比,deep,shallow 分别表示大尺度裁剪深层或浅层参数。使用奖励 准确地找到稀疏度,并裁剪 Plain-20 和 ResNet-56的 50%参数,并将其与经验剪枝方法进行比较。 结果是AMC 得到的最佳裁剪方式不同于人工设定的裁剪它学习了瓶颈结构。
如上图20所示为在 CIFAR-10 上进行的Accuracy-Guaranteed Compression的实验。使用奖励 。AMC在压缩60%的参数量的前提下基本没有精确度上的损失。
实验2:ImageNet:
为了得到满意的性能,作者采用:剪枝-finetune迭代的方法,一共迭代4次。在这4次中整个模型的总密度设置为[50%,35%,25%和 20%]。。对于每个阶段,在给定整体稀疏度条件下, AMC确定每个层的稀疏度。 然后根据某个策略对模型进行剪枝和finetune 30个epoch。
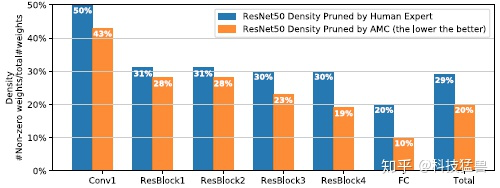
根据这个思路,作者将 ImageNet 上 ResNet-50 压缩率增加到5倍(人工调参得到的模型压缩率为 3.4,如下图所示)而不会损失模型精度(原始 ResNet50 的[top-1,top-5] 准确度= [76.13%,92.86%]; AMC 压缩后模型的准确度= [76.11%,92.89%])。下图21为每个块的密度信息,我们可以发现 AMC 的密度分布与手工设定模型压缩的结果完全不同,这表明 AMC 可以充分探索设计空间并分配稀疏度。
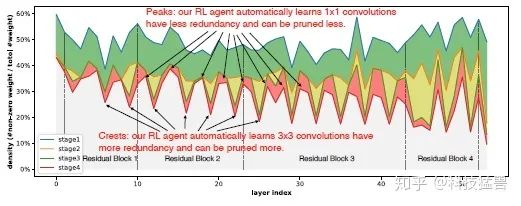
每个阶段每层的密度如下图22所示。峰显示出不同层的剪枝率的大小,3×3 卷积层的剪枝率较大,因为其具有较高的冗余度。而对于 1×1 卷积,结构更紧,稀疏度较低。
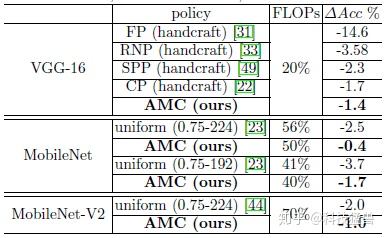
下图为AMC与其他SOTA剪枝方法 (FP,RNP,SPP,CP)的对比:AMC超过了基于规则的剪枝方法。
至此,我们完成了AutoML Pipeline的第2步:对搜索得到的模型进行压缩,下面是量化过程。
2.4:HAQ:进一步量化模型,减小内存占用
MIT: HAQ: Hardware-Aware Automated Quantization with Mixed Precision
在传统的方法中,我们采样单一精度的量化,即使用相同的比特数(比如8 bit)对所有层的参数进行量化。如下图所示:
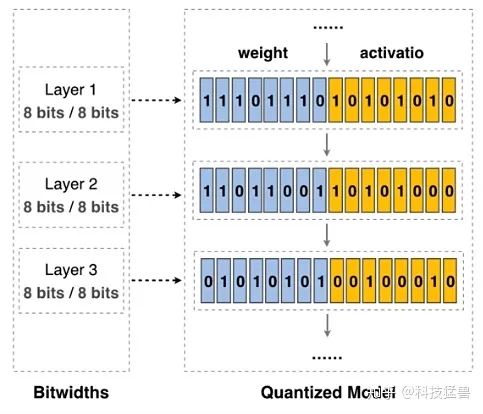
但这会带来一个问题:即是否使用相同的比特数对于每一层来讲都是最优的呢?
这个问题的解决方案与AMC十分相似,就是进行Layer-wise的量化过程,即依然使用DDPG的方法来决定每一层的量化精度。
问: 如何确定不同硬件加速器上每一层的权重和输出值的位宽?
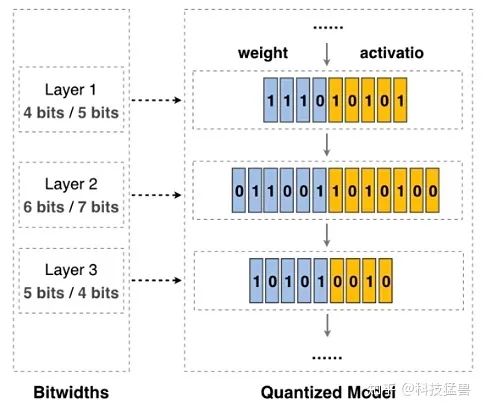
如下图所示,对于第1层,我们用4 bit表示weight,用5 bit表示activation;对于第2层,我们用6 bit表示weight,用7 bit表示activation;对于第3层,我们用5 bit表示weight,用4 bit表示activation。如果能够合理地安排每一层的bit数,就可以取得很好的准确率。
而且,最近已经有许多硬件设备开始支持混合精度的计算,比如说:
NVIDIA最近推出了支持1位、4位、8位和16位算术运算的图灵GPU架构:Tensor Core。 Apple的A12 Bionic。
所以有了硬件的支持,下一个问题是如何提供软件的支持。

我们回到上面的问题:如何确定不同硬件加速器上每一层的权重和输出值的位宽?
注意这个问题有3个关键词:
方法要针对不同的硬件设备:hardware-specialized。 方法要是Layer-wise的。 方法要能决定weight和activation的位宽。
首先混合精度要解决的第一个问题是会带来一个较大的设计空间:我们来计算下这个空间的具体大小:
比如说:每一层的weight参数有1 bit-8 bit这8种情况。同理,每一层的activation参数也有1 bit-8 bit这8种情况。那么每一层的参数有64种情况。假设神经网络有 层,那么一共就有 种情况。
状态空间:
再对比一下AMC的状态空间:
前8项和最后一项是相同的,只是换了说法,它们分别代表:
第 层的索引。 输入channel数。 输出channel数。 卷积核尺寸 。 卷积核stride 。 feature map的大小 。 该层的参数: 。 上一层的动作: 。
除此以外, 代表的是这一层是否是Depthwise Convolution。 代表量化的是weight还是activation。与AMC一样,状态空间里的每一维都会归一化到[0, 1]。
如果这一层是FC层,那么:
动作空间:
与AMC一样,动作空间也采用连续值的设计,因为离散值会失去顺序信息。从输出的动作值 到离散的量化精度 的转化公式为:
式中, 。
量化操作:
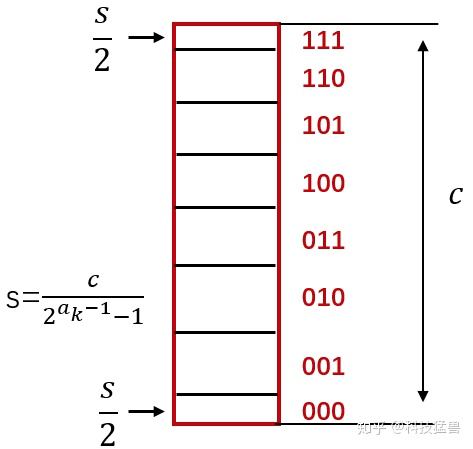
假设第 层的某个权值 ,量化精度是 bits,我们首先将它truncate到 的范围内。scale factor 。
那么量化结果可以表示为:
比如下图所示: ,图中没有画出符号位,所以数值位只剩下了3位。scale factor代表每一个离散值 (比如101)包含的连续值的宽度。注意为了保证量化结果的正确性,000和111代表的连续值的范围区间与其他值不同。
而 的选择主要是根据下式,即使得量化后的权值与未量化的权重的分布尽量接近。
为了限制模型的资源消耗,作者模仿AMC中的做法,即:RL agent给出每一层的量化精度 ,如果超过了限制,就从头sequentially减小量化位宽,直到满足资源限制为止。
奖励函数:
式中, 是量化以后finetune的模型的精度, 是full-precision模型的精度。
实验结果:
整体的实验是基于MobileNet-v1和MobileNet-v2。
实验1:Latency-Constrained Quantization
下图为HAQ在MobileNet-v1上的结果:
下图为HAQ在MobileNet-v2上的结果:
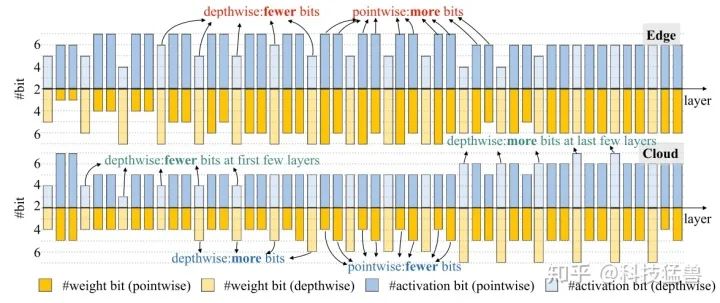
图29:MobileNet-v2上的结果
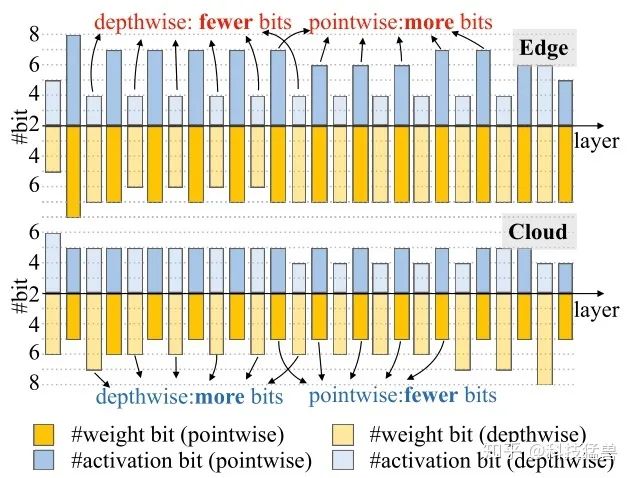
我们可以发现在端侧设备 (Edge:Xilinx Zynq-7020 FPGA) 上和在云(Cloud:Xilinx VU9P) 上搜索得到的结构是非常不同的。在端侧设备上HAQ会给depthwise卷积层赋予更低的量化精度,给pointwise卷积层赋予更高的量化精度。而云上前若干层的现象很相似,但是最后几层恰恰相反,HAQ会给depthwise卷积层赋予更高的量化精度,给pointwise卷积层赋予更低的量化精度。这也鼓励我们要根据不同的硬件给出specialized的解决方案,因为它们的特性是不一样的,具体体现在batch size,memory bandwidth,peak FLOPs等许多方面。
量化的结果如下图所示:
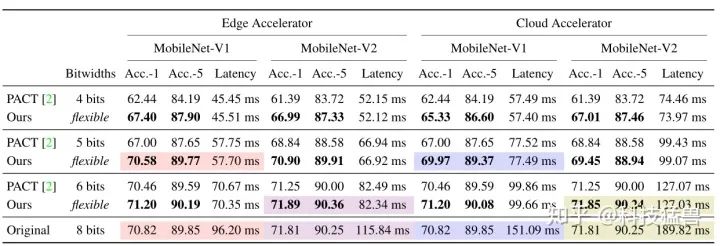
与baseline PACT相比,HAQ获得了精度和Latency的提升。
实验2:Energy-Constrained Quantization
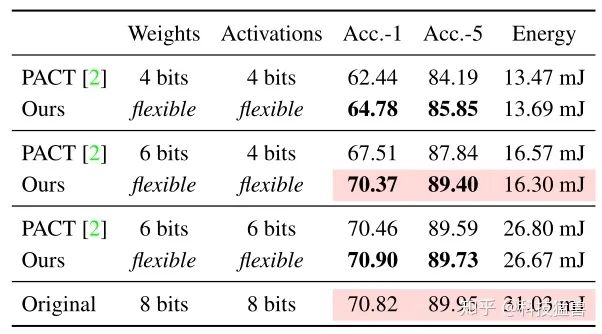
可以清楚地看到,HAQ优于基于规则的量化baseline:它在消耗相似的Energy的同时获得了
更好的性能。HAQ的能量消耗接近原始的MobileNet-V1模型的一半而几乎没有精度损失,证明混合精度在专门化的硬件设备上的有效性。
实验3:Model Size-Constrained Quantization
这次, 作者用k-means算法将值量化为k个不同的质心,而不是使用线性量化进行压缩,因为k-means量化可以更有效地减小模型大小。
与韩松老师的Deep Compression的结果对比如下:
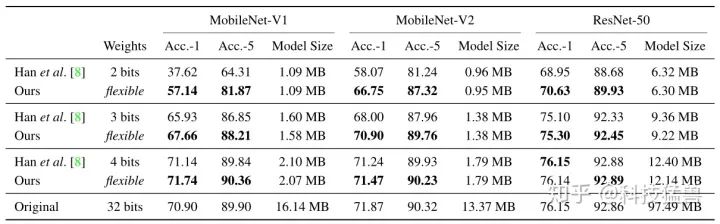
可以发现比HAQ比Deep Compression性能好得多:它在相同的模型大小下实现了更高的精度。对于像MobileNets这样的紧凑模型,Deep Compression会显著降低性能,尤其是在大幅度量化的情况下,而HAQ可以更好地保持精度。
例如,当Deep Compression将MobileNet-v1的权重量化为2 bit时,精确度从70.90显著下降到37.62;而HAQ在相同的模型大小下仍然可以达到57.14的精确度。这是因为HAQ通过系统地搜索最优量化策略来充分利用混合精度。
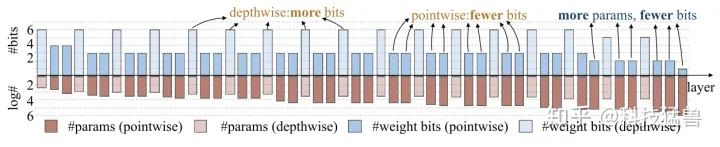
如图32为Model Size-Constrained Quantization的量化可视化结果。HAQ给depthwise convolution 分配了更多的量化位数,给pointwise convolution 分配了更少的量化位数。
直观来说,这是因为前者的参数个数比后者少很多。比较图29和图32,在不同的优化目标下,策略有很大的不同(在延迟优化下,depthwise convolution的位数较少,在模型大小优化下,depthwise convolution的位数较多)。
表明HAQ可以做到针对不用的硬件设备 (云,端侧),不同的约束条件 (Latency,Energy,Model size),不同的模型给出最适宜的量化策略。
至此,我们完成了AutoML Pipeline的最后一步量化的工作。总结一下:
流水线的输入是
模型要部署的目标硬件设备。
约束条件(Latency,Energy Consumption,Model Size,Memory,FLOPs等)。
1 我们先利用AutoML设计为给定的硬件,在给定的条件下设计最适宜的架构。
2 再使用AMC为给定的硬件,在给定的条件下搜索最适宜剪枝的策略,以保持高精度。
3 最后使用HAQ为给定的硬件,在给定的条件下搜索最适宜量化的策略,以保持高精度。
至此,一个AutoML Pipeline完成,输出最终的模型,纵观整个过程,每一步都使用了AutoML技术。
自动机器学习流水线的演进
MIT: APQ: Joint Search for Network Architecture, Pruning and Quantization Policy
在上面介绍的自动机器学习流水线中,给定目标硬件设备 和目标资源约束 ,我们依次对模型进行了架构搜索,结构化剪枝,混合精度量化的过程。这一系列过程进行完后,我们得到了适用于 的最优模型,且它的资源消耗满足 的限制。
自动机器学习流水线的中间过程:
AutoML搜索最适宜的模型架构,最大化精度。
对这个模型进行压缩,减少参数量。
对压缩后的模型进行量化,进一步减少内存占用。
不足是:
这一过程分3步进行略微繁琐。 需要调节大量的hyper-parameters,超过了可接受的人力范围。
那么,接下来的想法是:这3步可否合并为一步进行呢?即:联合搜索网络架构,剪枝和量化策略?
我们希望的中间过程:
但是,直接使用NAS联合搜索这3个维度会带来以下的问题:
搜索空间变得很大,使搜索过程很难进行。因为剪枝和量化过程需要finetune的过程,极大增加了搜索的成本,如下图所示。
每一步都有不同的目标函数,使得流水线最终的策略是次优的。浮点模型的最佳神经架构对于量化模型可能不是最佳的。
所以,我们可以采用APQ的策略,把架构搜索,剪枝,量化这3步可否合并为一步进行。
问:面对这样巨大的联合搜索空间,如何加快搜索过程?
答:核心思想是训练一个quantization-aware accuracy predictor加速搜索过程。
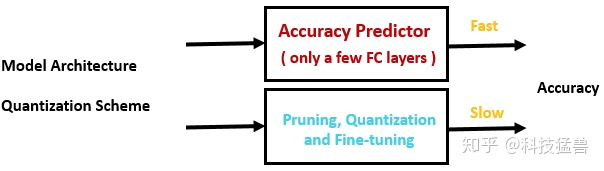
但是,训练一个quantization-aware accuracy predictor并不容易,因为我们需要大量的 (模型,精度) 数据集,而每得到这样的一个样本,就需要做以下2件事情:
训练这个模型,得到初始的fp32 weights。 量化并fine-tune得到int8 weights,并验证Accuracy。
做完这2步 (hundreds of GPU hours),才算得到一组数据。而我们要构建这样一个数据集,无疑会花费巨大的成本。
训练Quantization-Aware的Accuracy Predictor:
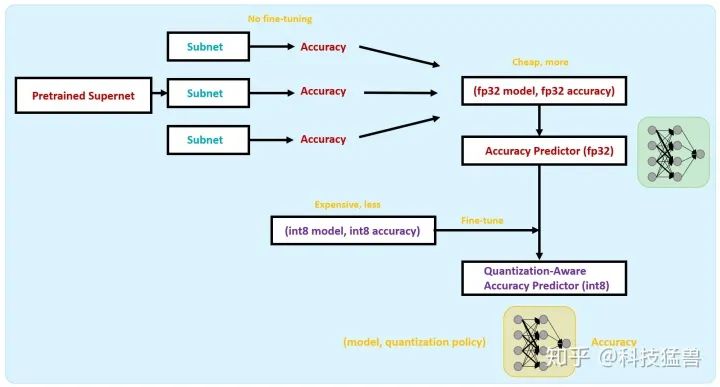
所以,为了减少第1步的计算量,这里借鉴One-Shot NAS的方法:训练一个supernet,其中包含许多个subnet,这些subnet直接继承supernet的权重,不做任何fine-tune,在验证集上评估精确度,即可得到一组数据 (fp32 model, fp32 accuracy)。这样一来,将计算成本降低至 。利用这些大量的低成本 的数据集 (fp32 model, fp32 accuracy), 我们可以训练出一个Accuracy Predictor (fp32),它的输入是模型架构,输出是预测精度。
为了减少第2步的计算量,需要获得(quantized model, quantized accuracy)的数据。这里不能借鉴One-Shot NAS的方法,因为量化的模型,如果不做fine-tune,精度会很差。所以我们使用上一步得到的Accuracy Predictor (fp32),使用少量的高成本 的数据集 (int8 model, int8 accuracy) 对它进行fine-tune,类似于迁移到量化数据上。
fine-tune结束后,即得到Quantization-Aware的Accuracy Predictor (int8),它的输入是模型,量化精度,输出是预测的精确度。整个过程如下图35所示:
使用上述的方法,就可以不用去费力地获得数据点:(NN architecture, quantization
policy, quantized accuracy),而省去了复杂的训练过程。
我们得到了Quantization-Aware Accuracy Predictor以后,就可以利用它,输入模型的架构,即可得到模型的accuracy,这一过程可以表示为:
下一步要做的就是把这三个自变量进行编码,对搜索空间进行建模:
搜索空间: once-for-all network
Backbone设置为MobileNetV2,kernel size={3, 5, 7},channel number={4B, 6B, 8B}
depth={2 stages, 3 stages, 4 stages},once-for-all network的性质有:
对于每个提取的子网络,可以直接评估性能,而无需重新训练,因此训练成本只需支付一次。 支持operator,channel的搜索。
由于once-for-all network的网络训练的性质,很难同时实现这两个目标:因为如果搜索空间变得太大,精度近似将是不准确的。
为了解决这个问题,我们采用Progressive Shrinking (PS) 算法来训练一次性网络。具体来说,我们首先在once-for-all network的网络中训练一个具有最大kernel大小、channel数量和depth的完整子网络,并将其用作teacher,从once-for-all network的网络中逐步发展更小的子网络样本。在蒸馏过程中,经过训练的子网络仍然会更新权重,以防止精度损失。Progressive Shrinking (PS)算法有效降低了一次性网络训练过程中的方差。通过这样做,我们可以确保从一劳永逸的网络中提取的子网络保持竞争精度,而无需重新训练。
有了搜索空间的定义,具体的编码方式是:
将depthwise convolution和pointwise convolution的kernel size,channel number,quantization bits进行编码成one-hot vector,再concate在一起。作为这个block的encoding。
例如: 一个block有3个选择的kernel size大小 (3,5,7)和4个选择的channel number (16,24,32,40),如果我们选择kernel size = 3,channel number = 32,那么我们得到两个向量[1,0,0]和[0,0,1,0],我们将它们concate在一起,并使用[1,0,0,0,1,0]来表示这个块的体系结构。 假设pointwise/depthwise层的weights/activations 的位宽选择是4或8,我们使用[1,0,0,1,0,1,1,0]来表示量化策略的选择(4,8,8,4)。 那么对于一个5层网络,我们可以用一个75-dim (5×(3+4+2×4)=75)的向量来表示这样的编码。
在我们的设置中,kernel size的选择是[3,5,7],channel number的选择取决于每个块的基本通道号,位宽的选择是[4,6,8],总共有21个块要设计。
Quantization-Aware Accuracy Predictor的结构如下图所示:隐藏层为400个神经元。
左侧为Full-precision accuracy predictor,右侧为Quantization-Aware Accuracy Predictor。输入层添加了量化的编码,利用左侧网络的预训练权重,加上(int8 model, int8 accuracy)的数据集,进行fine-tune后得到。值得注意的是不需要很多(int8 model, int8 accuracy)的数据集,这极大地缩小了训练的成本。
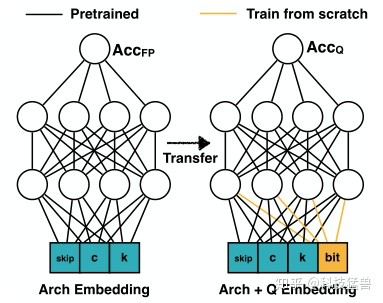
这样,得到了Quantization-Aware Accuracy Predictor以后,也建模了编码方式,我们就能根据遗传算法在三个维度上联合搜索最适宜的架构。为了衡量Latency和Energy的信息,作者仿照ProxyLessNAS,首先构建一个查找表,其中包含不同架构配置和位宽下每层的Latency和Energy。需要这些信息时直接查表即可。在遗传算法迭代的过程中,Latency和Energy超过限制的个体将会被直接排除掉。遗传算法具体如下:

APQ的具体流程如下图38所示:
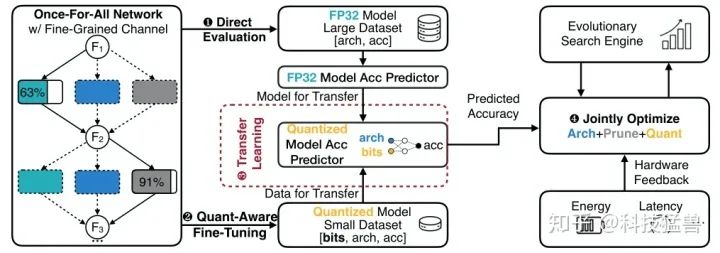
1 首先训练好一个once-for-all network 。
2 利用 生成用于训练Full-precision accuracy predictor的数据集 和生成用于训练Quantization-Aware Accuracy Predictor的数据集 。
3 使用数据集 训练Full-precision accuracy predictor 。
4 使用Full-precision accuracy predictor在数据集 上finetune得到Quantization-Aware Accuracy Predictor 。
5 根据遗传算法首先初始化一代,共 个样本。
6 使用 选出这一代的精英Topk。
7 变异出 个下一代新个体,杂交出 个下一代新个体。
8 循环进入第6步,循环 次。
9 从精英Topk中选出最优个体作为结果输出。
量化方案:
与HAQ一致,设权值为 ,量化精度为 ,则量化之后的权值在 为:
实验结果:
整体的实验是基于ImageNet,BitFusion的硬件平台。
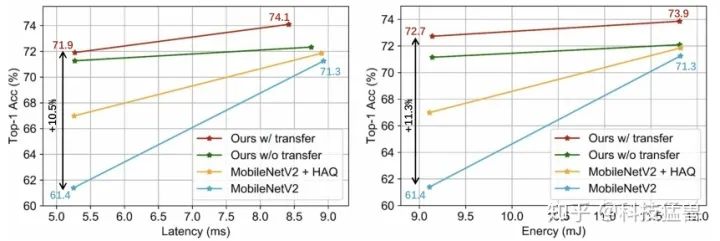
实验1:与MobileNetV2+HAQ的对比:
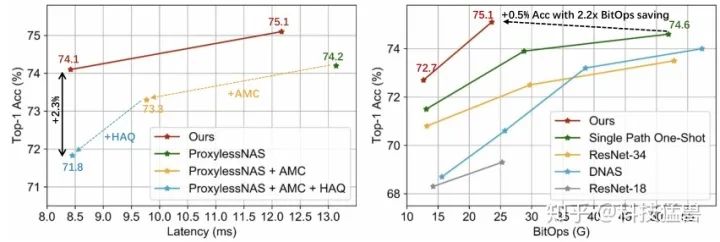
实验2: 与Multi-Stage Optimized Model的对比:
实验3: Predictor-Transfer的对比实验
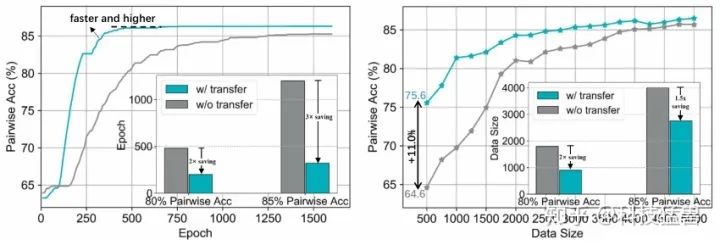
作者尝试了使用Predictor-Transfer技术与不使用的对比,当使用Predictor-Transfer时,左图显示可以获得更快和更高的收敛速度,而右图显示需要更少的数据量。使用Predictor-Transfer时,我们可以使用少于3000个数据点实现85%的pair-wise accuracy (从候选数据集随机选择2个样本,Predictor能够正确识别哪一个更好的比例),而如果没有这种技术,至少需要4000个数据。
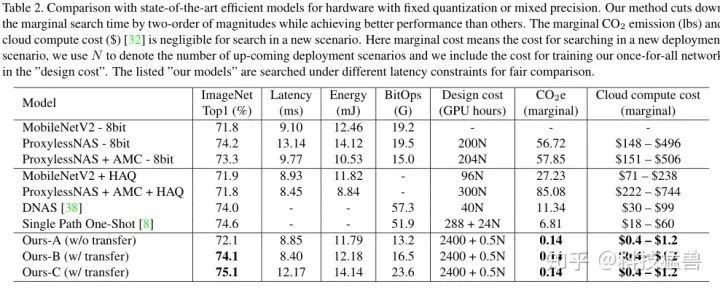
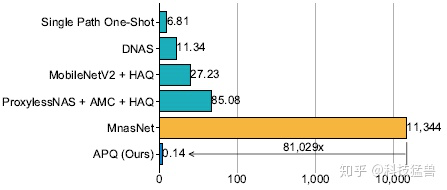
可以发现,APQ在精确度上超过了SOTA,且极大地减少了 排放和云计算的边际成本。
至此,我们完成了对AutoML Pipeline的优化过程。
总结:
本文介绍了自动机器学习流水线 (AutoML Pipeline),它的输入是给定的硬件条件和资源限制,输出是最优的模型,主要分为架构搜索,剪枝,混合精度量化三个部分。还介绍了它的改进,即联合搜索三个部分的最优策略。
参考文献:
[1] ProxyLessNAS: Direct Neural Architecture Search on Target Task and Hardware
[2] AMC: AutoML for Model Compression and Acceleration on Mobile Devices
[3] HAQ: Hardware-Aware Automated Quantization with Mixed Precision
[4] APQ: Joint Search for Network Architecture, Pruning and Quantization Policy
[5] EIE: efficient inference engine on compressed deep neural network
[6] Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding
推荐阅读
