
手把手教你使用 YOLOV5 训练目标检测模型
来自于点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
作者 | 肆十二
来源 | CSDN博客
conda config --remove-key channelsconda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/conda config --set show_channel_urls yespip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
conda create -n yolo5 python==3.8.5conda activate yolo5
安装之前一定要先更新你的显卡驱动,去官网下载对应型号的驱动安装
30系显卡只能使用cuda11的版本
一定要创建虚拟环境,这样的话各个深度学习框架之间不发生冲突
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可
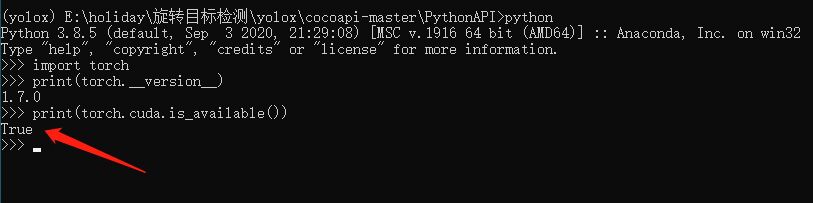
安装完毕之后,我们来测试一下GPU是否
pip install pycocotools-windowspip install -r requirements.txtpip install pyqt5pip install labelme
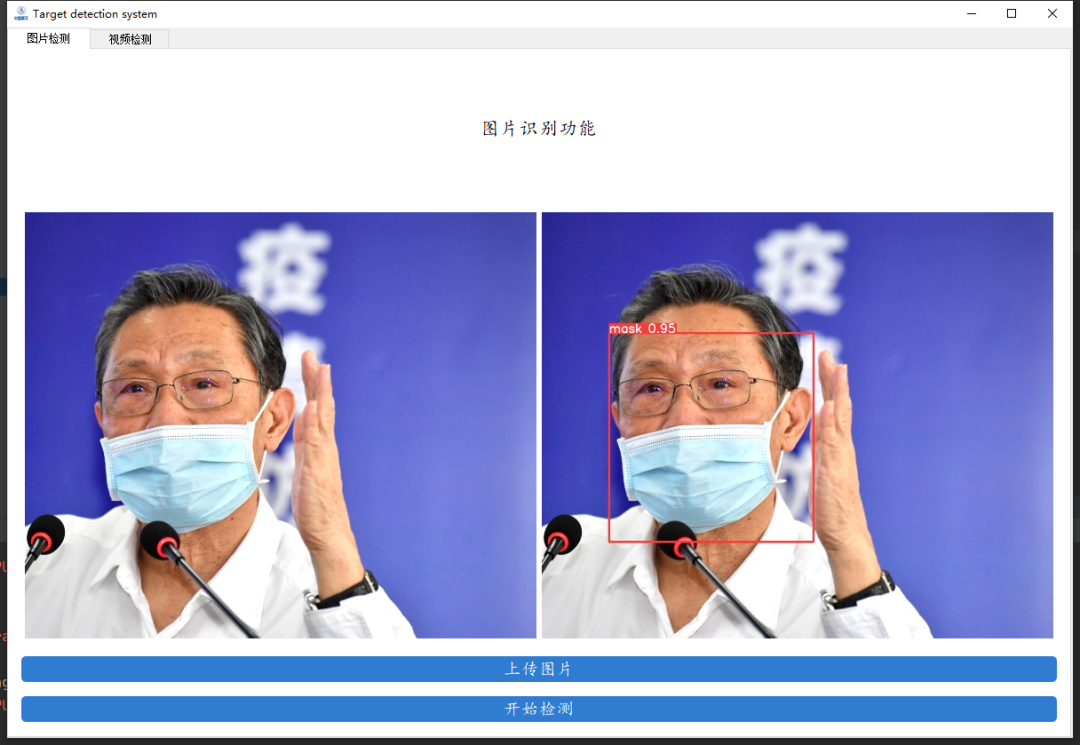
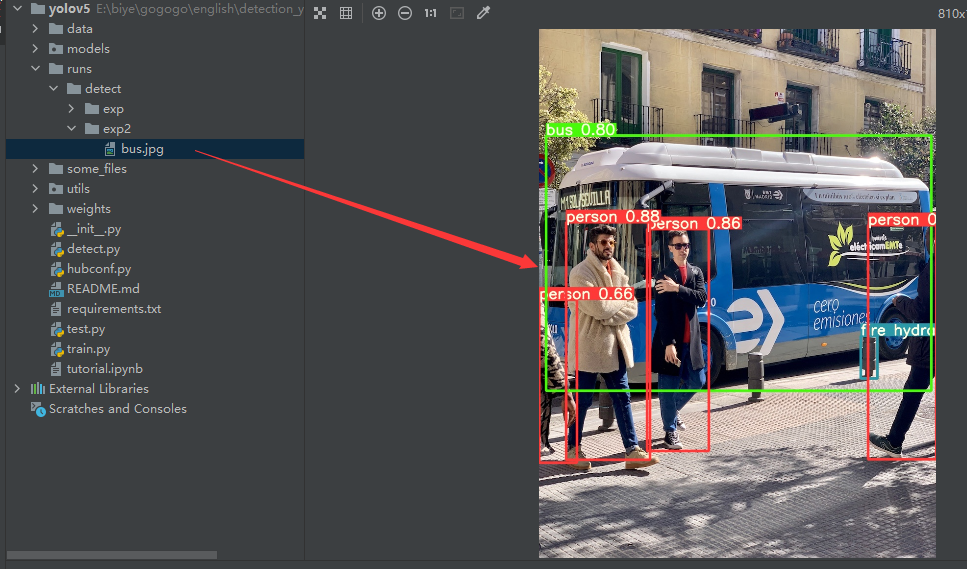
python detect.py --source data/images/bus.jpg --weights pretrained/yolov5s.pt
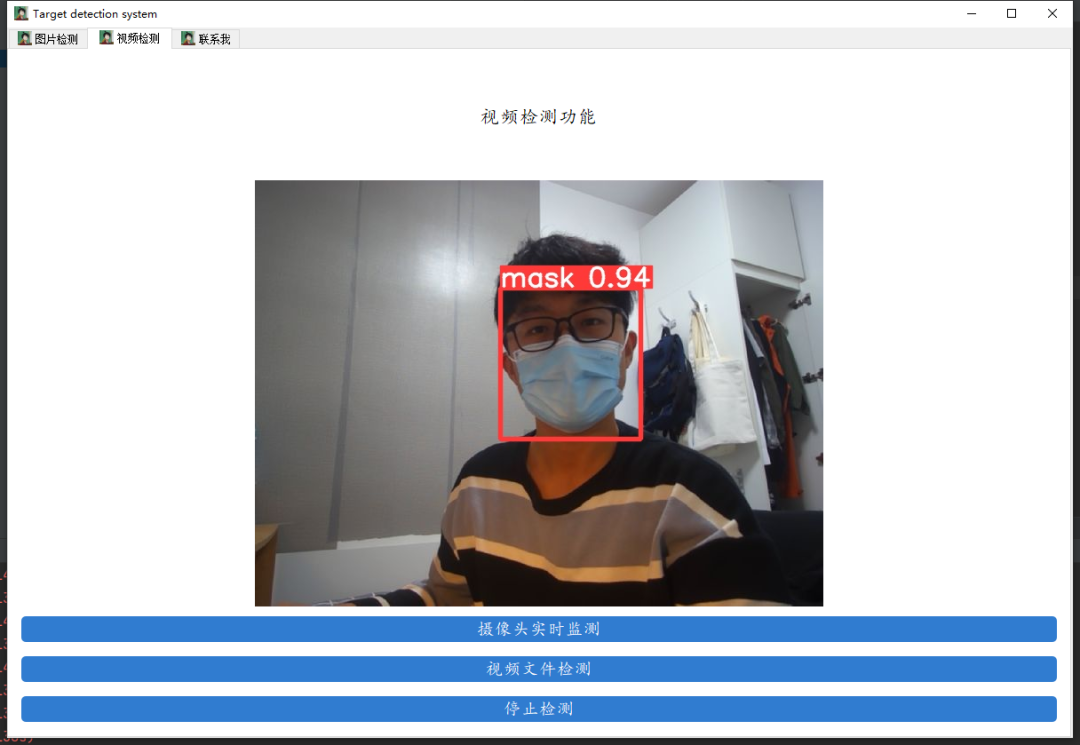
python detect.py --source 0 # webcamfile.jpg # imagefile.mp4 # videopath/ # directorypath/*.jpg # glob'https://youtu.be/NUsoVlDFqZg' # YouTube video'rtsp://example.com/media.mp4' # RTSP, RTMP, HTTP stream

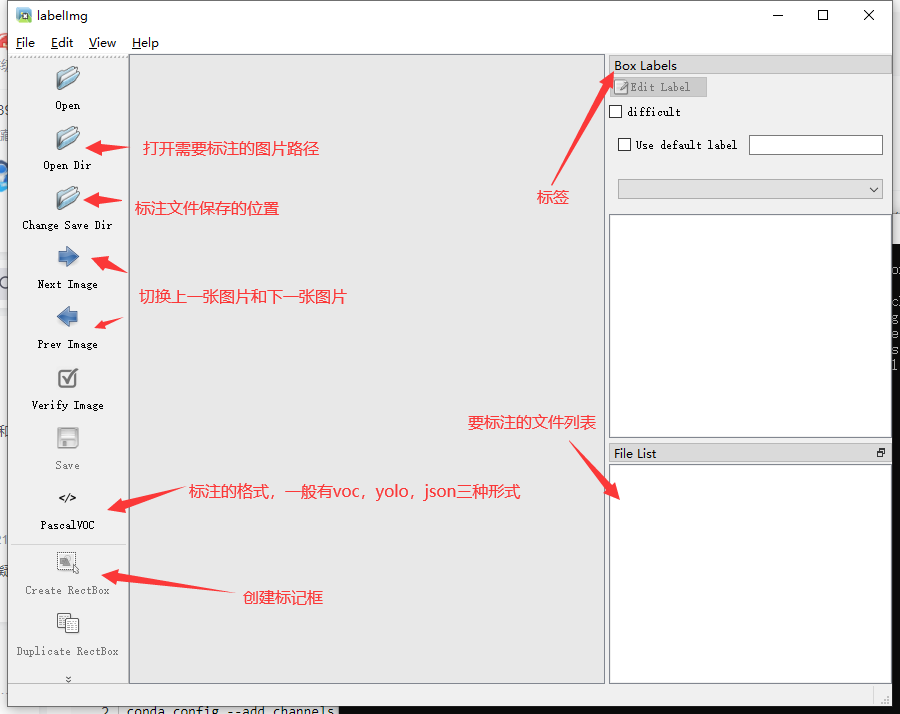
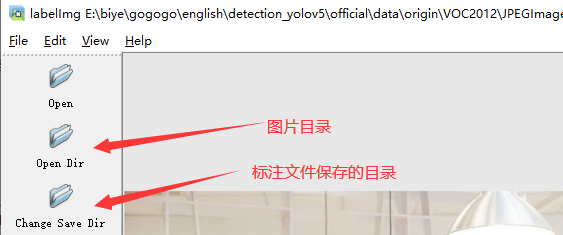
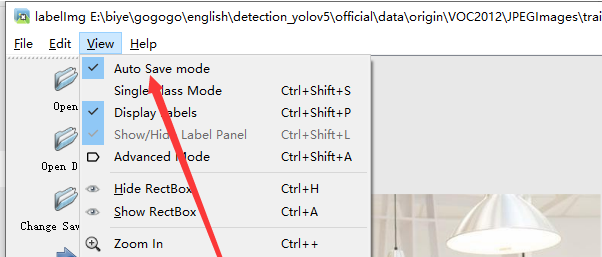

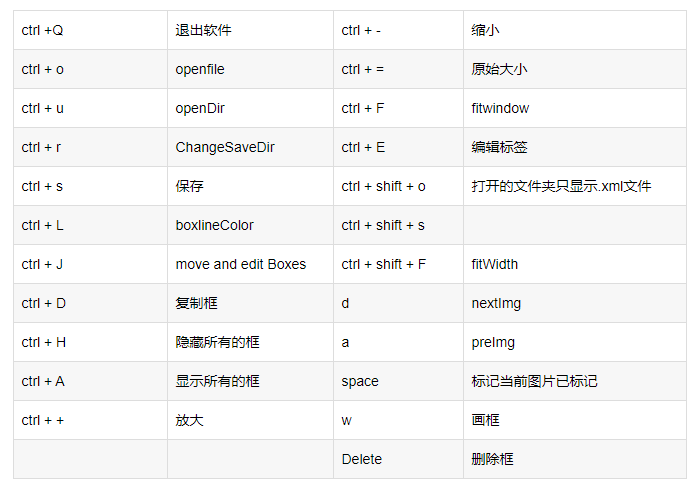
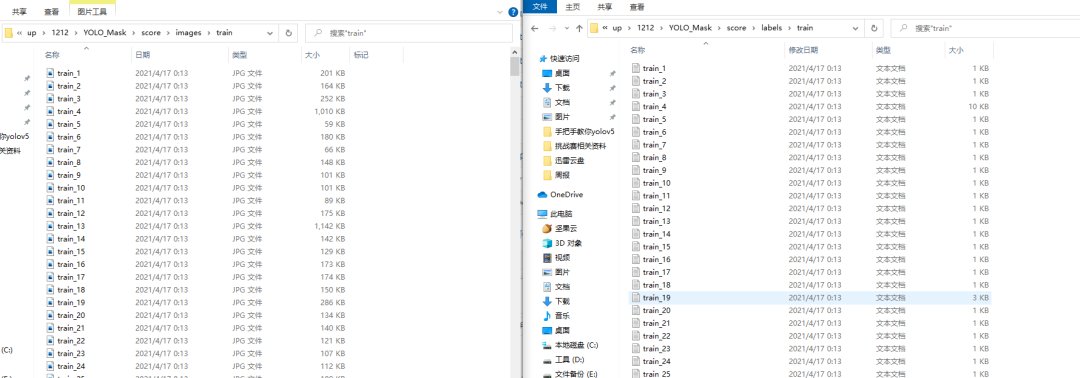

YOLO_Mask└─ score├─ images│ ├─ test # 下面放测试集图片│ ├─ train # 下面放训练集图片│ └─ val # 下面放验证集图片└─ labels├─ test # 下面放测试集标签├─ train # 下面放训练集标签├─ val # 下面放验证集标签
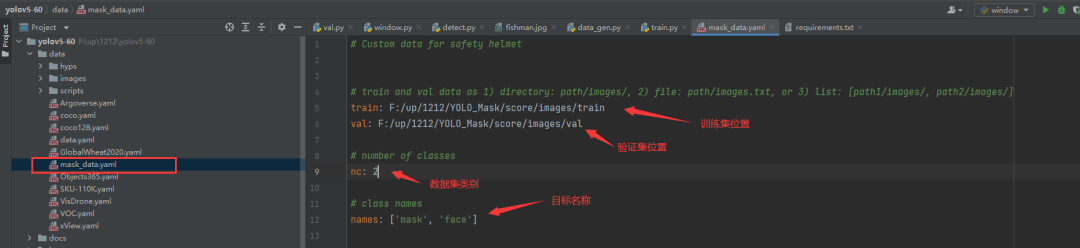
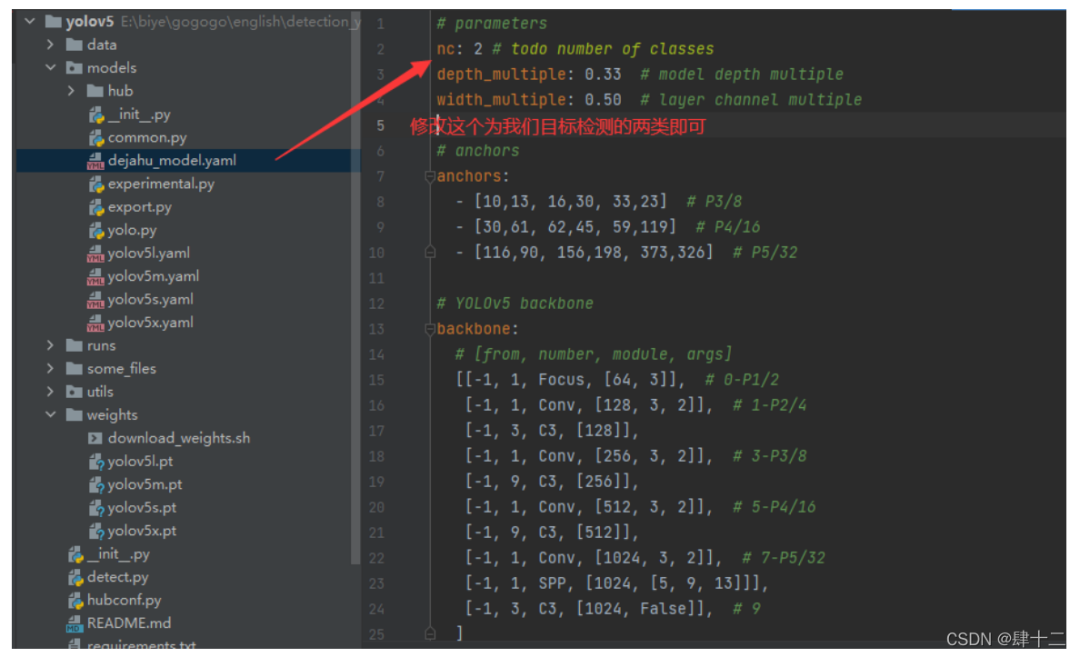
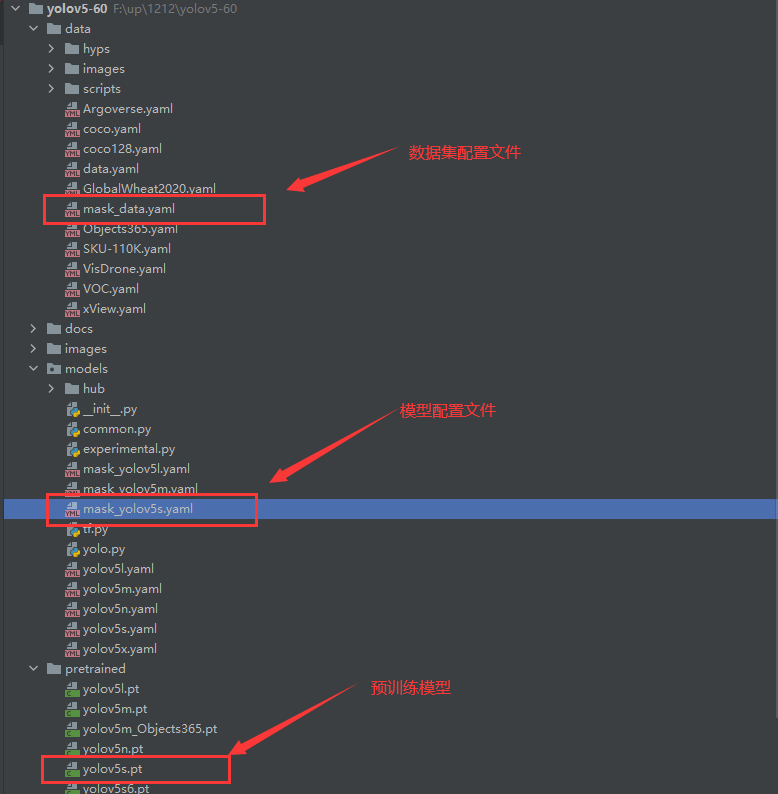
python train.py --data mask_data.yaml --cfg mask_yolov5s.yaml --weights pretrained/yolov5s.pt --epoch 100 --batch-size 4 --device cpu

本文仅做学术分享,如有侵权,请联系删文。
评论