使用YOLOv5模型进行目标检测!
目标检测是计算机视觉领域的一大任务,大致分为一阶段目标检测与两阶段目标检测。其中一阶段目标检测模型以YOLO系列为代表。最新的YOLOv5在各个数据集上体现出收敛速度快、模型可定制性强的特点,值得关注。本文主要讲解如何从零训练自己的YOLOv5模型与一些重要参数的含义。

本文的训练数据使用的是开源数据集SHWD,已上传开源数据平台Graviti,在文末可下载。
在学习或研究目标检测的同学,后台回复“210702”可进群一起交流。
一、配置环境
1.1 创建虚拟环境
俗话说,环境配不对,学习两行泪,首先我们需要安装Anaconda(Anaconda安装非常简单并且百度上有大量资料),然后创建一个专门用来训练YOLOv5的虚拟环境。按win+r打开“运行对话框”,输入“cmd”打开cmd。输入下面代码创建虚拟环境:
conda create -n course_yolov5 python==3.8
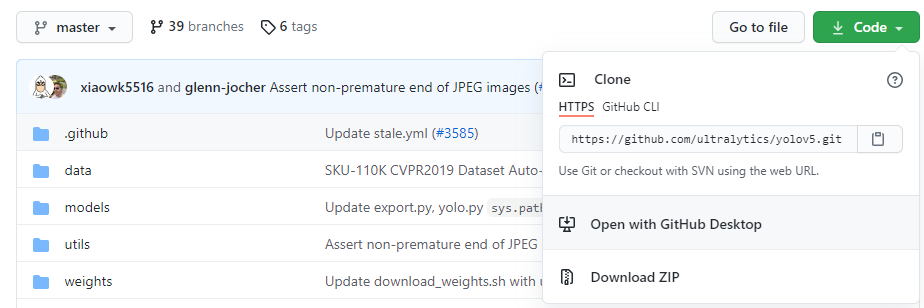
其中“course_yolov5”是虚拟环境的名称,“python==3.8”是虚拟环境的python版本。然后我们需要将Ultralytics开源的YOLOv5代码Clone或下载到本地,可以直接点击Download ZIP进行下载,
下载地址:https://github.com/ultralytics/yolov5
接下来激活刚刚创建的虚拟环境并解压刚下好的压缩文件,将工作路径切换到解压好的文件夹下:
conda activate course_yolov5
cd D:\Study\PyCharm20\PycharmProjects\course_yolov5\yolov5-master
d:
注意:这里需要将" D:\Study\PyCharm20\PycharmProjects\course_yolov5"替换为自己的路径。
1.2 安装模块:
在安装模块之前,最好先更换pip源为阿里源或国科大源,然后安装yolov5需要的模块,记住工作路径要在yolov5文件夹下:
python -m pip install -r requirements.txt
如果没有安装cuda默认安装pytorch-cpu版,如果有gpu可以安装pytorch-gpu版。
二、检测
2.1 COCO数据集
在正确配置好环境后就可以检测自己的图片或视频了。YOLOv5已经在COCO数据集上训练好,COCO数据集一共有80个类别,如果您需要的类别也在其中的话,可以直接用训练好的模型进行检测。这80个类分别是:
['person', 'bicycle', 'car', 'motorcycle', 'airplane', 'bus', 'train', 'truck', 'boat', 'traffic light', 'fire hydrant', 'stop sign', 'parking meter', 'bench', 'bird', 'cat', 'dog', 'horse', 'sheep', 'cow', 'elephant', 'bear', 'zebra', 'giraffe', 'backpack', 'umbrella', 'handbag', 'tie', 'suitcase', 'frisbee', 'skis', 'snowboard', 'sports ball', 'kite', 'baseball bat', 'baseball glove', 'skateboard', 'surfboard', 'tennis racket', 'bottle', 'wine glass', 'cup', 'fork', 'knife', 'spoon', 'bowl', 'banana', 'apple', 'sandwich', 'orange', 'broccoli', 'carrot', 'hot dog', 'pizza', 'donut', 'cake', 'chair', 'couch', 'potted plant', 'bed', 'dining table', 'toilet', 'tv', 'laptop', 'mouse', 'remote', 'keyboard', 'cell phone', 'microwave', 'oven', 'toaster', 'sink', 'refrigerator', 'book', 'clock', 'vase', 'scissors', 'teddy bear', 'hair drier', 'toothbrush']
2.2 用预训练模型进行测试
下面我们先演示如何检测图片中的目标。我们一般将要检测的数据放在'./data/images'路径下,其中 '.' 代表当前路径即解压好的yolov5-master文件夹,然后我们在cmd中输入下面代码:
python detect.py --source ./data/images/example.jpg --weights weights/yolov5s.pt --conf-thres 0.25
如果没有下载预训练模型需要等预训练模型下好,没有报错就说明我们的图像检测成功了!检测好的图片会放在'./runs/detect'下,各个参数的含义下面会有具体的介绍。

我们也可以对视频进行检测:
python detect.py --source ./data/images/happysheep.mp4 --weights weights/yolov5s.pt --conf-thres 0.25
或一个文件夹中的所有图片和视频(图片支持的格式:'bmp', 'jpg', 'jpeg', 'png', 'tif', 'tiff', 'dng', 'webp', 'mpo',视频支持的格式:'mov', 'avi', 'mp4', 'mpg', 'mpeg', 'm4v', 'wmv', 'mkv'),检测结果同样放在'./runs/detect'下。
python detect.py --source ./data/images/ --weights weights/yolov5s.pt --conf-thres 0.25
 仔细观察图中,我们可以发现,官方训练好的模型虽然能将物体框出来,但是对物体的分类存在问题。一会儿将那只边牧预测为奶牛,一会儿预测为绵羊。
仔细观察图中,我们可以发现,官方训练好的模型虽然能将物体框出来,但是对物体的分类存在问题。一会儿将那只边牧预测为奶牛,一会儿预测为绵羊。
这是目标检测现阶段的难点之一,即不容易区分图像中与目标物体外形相似的非目标物体,对于这个问题,我们可以在检测出目标区域后再接一个分类器对物体进行分类。另外,地上的树枝被误认为是小鸟,我们可以通过调整置信度阈值来解决这一问题。
2.3 检测文件参数说明
yolov5的参数是由argparse包传入的,我们可以通过命令行传入参数,也可以直接设置参数默认值。我们打开yolov5-master文件加下的detect.py文件,传参的代码在主函数中,几个关键参数如下:
parser.add_argument('--weights', nargs='+', type=str, default='yolov5x.pt', help='model.pt path(s)')
parser.add_argument('--source', type=str, default='data/images/happysheep.mp4', help='source')
parser.add_argument('--img-size', type=int, default=640, help='inference size (pixels)')
parser.add_argument('--conf-thres', type=float, default=0.25, help='object confidence threshold')
parser.add_argument('--iou-thres', type=float, default=0.45, help='IOU threshold for NMS')
weights参数是我们训练好的权重文件,yolov5共有四种模型:yolov5s、yolov5m、yolov5l、yolov5x,它们的网络主干深度和宽度依次递增,一般情况下检测效果也递增,yolov5x的效果最好,yolov5s最差,但是yolov5s网络参数最少(14MB),yolov5x参数最多(166MB)。官方提供的预训练模型也有四种,大家可以根据需要设置。
source参数为检测数据路径。img-size参数为检测时图像大小,最好与训练时相同,默认为640。conf-thres为检测置信度阈值,预测出的置信度高于这个阈值的物体就会显示在图中。iou-thres是NMS的IOU阈值,一般为0.3~0.5。
3 训练自己的数据集
3.1 使用labelimg标注图片
我们训练模型的第一步就是获取数据集,数据集一般通过拍照、爬虫或直接下载等方式获得,直接下载的数据集如比赛数据集都会有标注,我们可以直接使用所给的数据进行训练,但是通过拍照和爬虫获得的数据需要我们自己进行数据标注。目标检测标注工具有很多,今天主要讲解labelimg的标注步骤(文末附labeling下载地址)。
下载并解压完后打开data文件夹中的predefined_classes.txt文件,可以在文件中写入自己要定义的类名,如安全帽检测中有两类:安全帽和人,我们就在predefined_classes.txt文件中的第一行写helmet,第二行写person。
标注图片步骤如下:
把要标注的数据放在img_whole/datasets文件夹中,打开labelimg.exe, 点击“Open Dir”打开img_whole/datasets文件夹,屏幕中就会显示图片, 点击“Create RectBox”将需要标注的物体框出来并注明其类别, 在标注完所有物体后点击“Save”保存标注文件至img_whole/xml文件夹中,标注文件格式为xml, 点击“Next Image”标注下一张图片,然后继续进行步骤3直至标注完全部图片。

3.2 将xml文件转换为YOLO标注文件
我们随便打开一个xml文件,xml文件是DOM树结构,python的xml模块可以解析它。
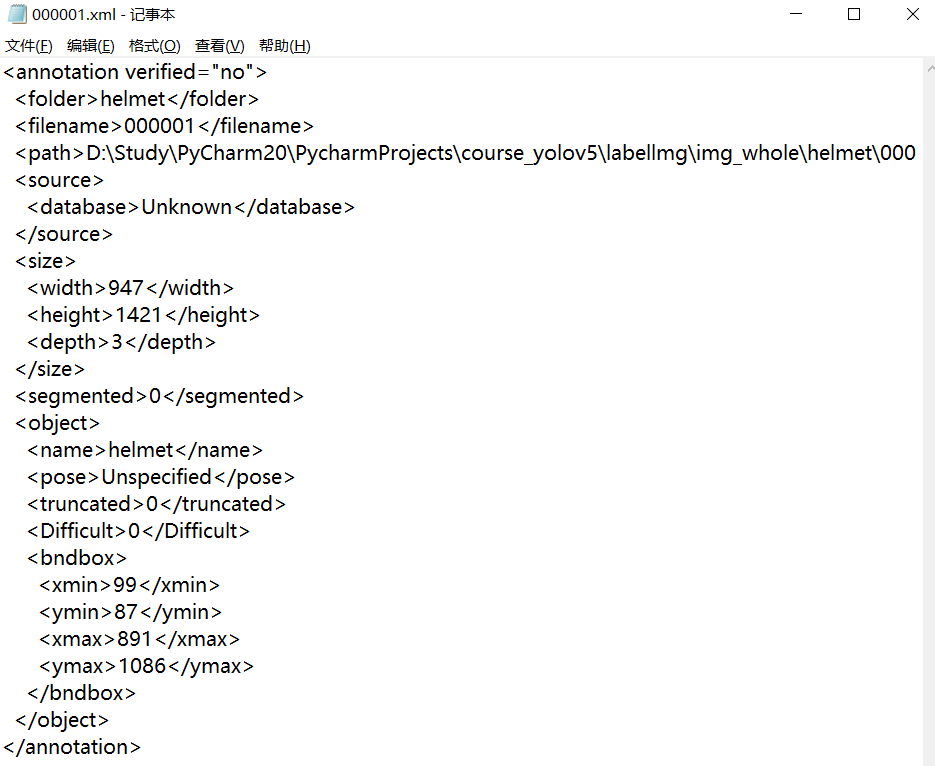
我们需要的信息是图像宽度width、图像高度height、检测框左上角坐标xmin和ymin以及检测框右下角坐标xmax、ymax。我们运行voc_label.py便可在labels文件夹中生成YOLOv5标签文件,标签文件中每一行的数据为class, x, y, w, h,class是该物体的类别,x,y是检测框中心坐标,w,h是检测框的宽和高。voc_label.py代码:
import xml.etree.ElementTree as ET
import os
from os import getcwd
from tqdm import tqdm
classes = ["helmet", "person"]
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = './xml/%s.xml' % (image_id)
out_file = open('./labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
wd = getcwd()
print(wd)
if not os.path.exists('./labels/'):
os.makedirs('./labels/')
image_ids = os.listdir('./datasets')
for image_id in tqdm(image_ids):
convert_annotation(image_id.split('.')[0])
3.3 训练
本文的训练数据使用的是开源数据集SHWD,数据已上传开源数据平台Graviti,在文末可下载。当我们数据很多的时候我们可以将数据集划分为训练集、验证集和测试集,比例大致为98:1:1,数据较少划分时比例大概为6:2:2。我们新建一个文件夹datasets,将划分好的图片和标签放入其中,文件夹结构如下:
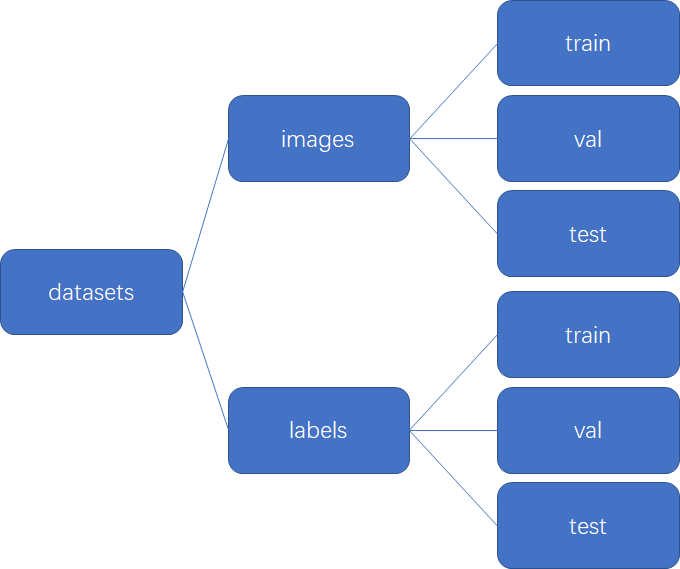
以训练集为例,标签文件名需要与图片对应:
然后将datasets文件夹放入yolov5-master中的data文件夹中,数据准备阶段就算完成了。
下面需要修改YOLOv5的配置文件,需要修改的配置文件有两个,我们先复制一份data/coco.yaml,这里将其重命名为helmet.yaml,修改图中横线中的参数:

在 download前加上一个#注释掉这段代码
将train、val、test修改为自己的路径,以train为例 ./data/helmet/images/train
将nc修改为数据的类别数,如安全帽检测只检测人和安全帽,故修改为2
将names修改自己数据的类名,如['helmet', 'person']
修改后的文件如下:

下一个需要修改的文件为模型配置文件,在models文件夹中有四个模型的配置文件:yolov5s.yaml、yolov5m.yaml、yolov5l.yaml和yolov5x.yaml,可以根据需要选择相应的模型,这里以yolovx.yaml为例,打开文件,修改文件中的nc为自己的类别数即可。
yolov5加入了自动判断是否需要重新k-means聚类anchors的功能,所以该文件中的anchors参数可以不做修改。如果有需要只需将这里anchors修改为自己计算出的即可。
在修改完这两个配置文件后就可以开始训练了!我们在cmd中输入(记住在yolov5-master路径下):
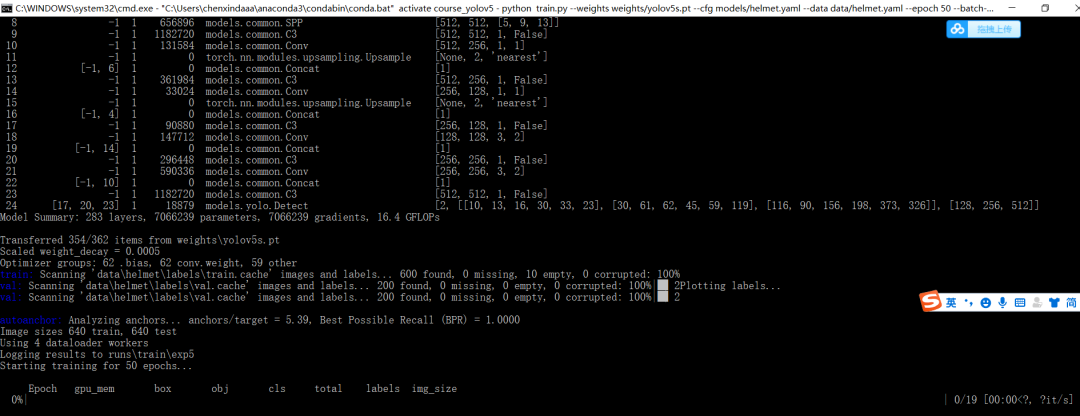
python train.py --weights weights/yolov5x.pt --cfg models/yolov5x.yaml --data data/helmet.yaml --epoch 50 --batch-size 32
如果出现下面界面,说明已经开始训练了:
3.4 训练参数解释
我们打开train.py文件,滑到主函数部分就可以看到需要传入的参数,下面一一介绍一下这些参数:
weights:权重文件路径,如果是''则重头训练参数,如果不为空则做迁移学习,权重文件的模型需与cfg参数中的模型对应
cfg:存储模型结构的配置文件
data:训练、验证数据配置文件
hyp:超参数配置文件,其中的参数意义下面会解释
epochs:指的就是训练过程中整个数据集将被迭代多少次
batch-size:每次梯度更新的批量数,太大会导致显存不足
img-size:训练图片的尺寸
rect:进行矩形训练
resume:恢复最近保存的模型开始训练
nosave:仅保存最终checkpoint
notest:仅测试最后的epoch
noautoanchor:不进行anchors的k-means聚类
evolve:进化超参数
bucket:gsutil bucket
cache-images:缓存图像以加快训练速度
image-weights:给图片加上权重进行训练
device:cuda device, i.e. 0 or 0,1,2,3 or cpu
multi-scale:多尺度训练,img-size +/- 50%
single-cls:单类别的训练集
adam:使用adam优化器
name:重命名results.txt to results_name.txt
超参数配置文件./data/hyp.scratch.yaml参数解释:
lr0:学习率,可以理解为模型的学习速度
lrf:OneCycleLR学习率变化策略的最终学习率系数
momentum:动量,梯度下降法中一种常用的加速技术,加快收敛
weight_decay:权值衰减,防止过拟合。在损失函数中,weight decay是正则项(regularization)前的一个系数
warmup_epochs:预热学习轮数
warmup_momentum:预热学习初始动量
warmup_bias_lr:预热学习初始偏差学习率
giou:GIoU损失收益
cls:类别损失收益
cls_pw:类别交叉熵损失正类权重
obj:是否有物体损失收益
obj_pw:是否有物体交叉熵正类权重
iou_t:iou阈值
anchor_t:多尺度anchor阈值
fl_gamma:focal loss gamma系数
hsv_h:色调Hue,增强系数
hsv_s:饱和度Saturation,增强系数
hsv_v:明度Value,增强系数
degrees:图片旋转角度
translate:图片转换
scale:图片缩放
shear:图片仿射变换
perspec:透视变换
mosaic:mosaic数据增强
mixup:mixup数据增强
由于时间和能力有限,上面的解释没有包含所有参数,读者可以通过阅读源代码进行进一步理解。
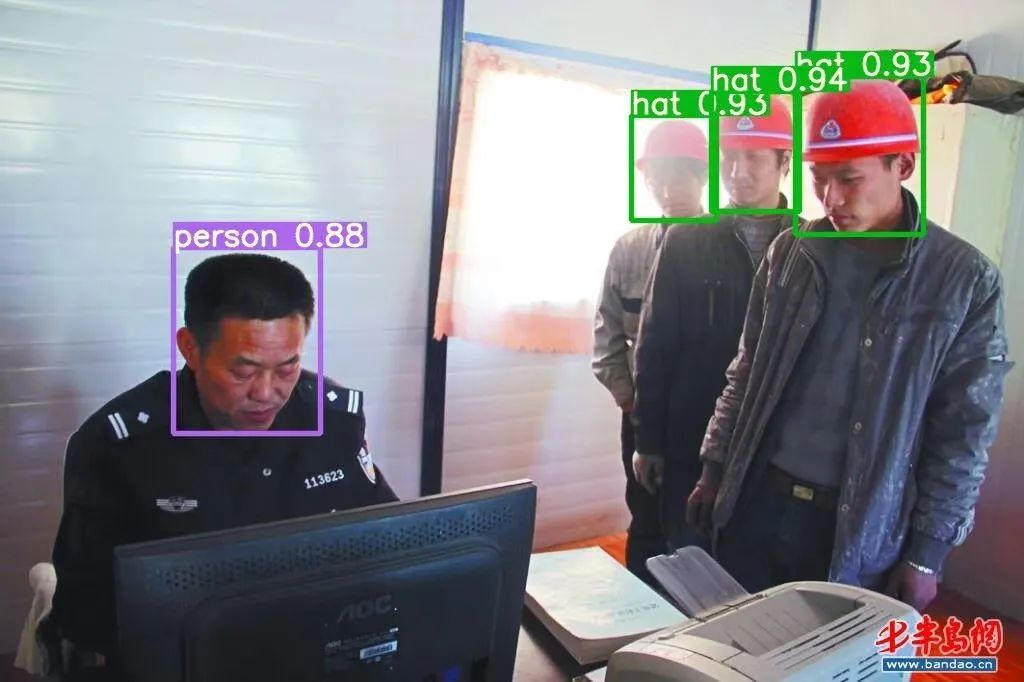
4 训练结果与测试
训练结束后,在runs/train文件夹下会自动生成训练结果,其中包括模型权重、混淆矩阵、PR曲线等。测试代码与2.2中的类似,只需将权重文件路径修改为训练好的权重文件路径即可,安全帽检测结果如下: