
CVPR 2021 论文大盘点-文本图像篇

来源 | OpenCV中文网
编辑 | 极市平台
极市导读
昨日进行了《CVPR 2021 论文大盘点-超分辨率篇》,今天我们继续“文本检测与识别相关论文”的盘点。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
本文收集文本检测与识别相关论文,包含任意形状文本检测、场景文本识别、手写文本识别、文本分割、文本图像检索、视频文本识别等,有趣的方向很多,共计 17 篇。
大家可以在 https://openaccess.thecvf.com/CVPR2021?day=all 按照题目下载这些论文。
用于任意形状文本检测
Fourier Contour Embedding for Arbitrary-Shaped Text Detection
任意形状的文本检测所面临的主要挑战之一是设计一个好的文本实例表示法,好使网络可以学习不同的文本几何差。现有的大多数方法在图像空间域中通过掩码或直角坐标系中的轮廓点序列来模拟文本实例。
问题:掩码表示法可能会导致昂贵的后处理,而点序列表示法对具有高度弯曲形状的文本的建模能力可能有限。
方案:作者指出在傅里叶域对文本实例进行建模,并提出Fourier Contour Embedding(FCE)方法,将任意形状的文本轮廓表示为compact signatures。进一步用骨干网、特征金字塔网络(FPN)和反傅里叶变换(IFT)和非最大抑制(NMS)的简单后处理来构建FCENet。与以前的方法不同,FCENet 首先预测文本实例的 compact Fourier signatures,然后在测试过程中通过 IFT 和 NMS 重建文本轮廓。
结果:实验表明,即使是高度弯曲的形状,在拟合场景文本的轮廓方面是准确和鲁棒的也验证了 FCENet 在任意形状文本检测方面的有效性和良好的通用性。FCENet 在 CTW1500 和 Total-Text 上优于最先进的(SOTA)方法,特别是在具有挑战性的高度弯曲的文本子集上。
作者 | Yiqin Zhu, Jianyong Chen, Lingyu Liang, Zhanghui Kuang, Lianwen Jin, Wayne Zhang
单位 | 华南理工大学;商汤;琶洲实验室;上海交通大学;上海AI实验室
论文 | https://arxiv.org/abs/2104.10442

Progressive Contour Regression for Arbitrary-Shape Scene Text Detection
问题:当前最先进的场景文本检测方法通常从自下而上的角度用局部像素或组件对文本实例进行建模,因此,对噪声很敏感,并依赖于复杂的启发式后处理,特别是对于任意形状的文本。
该研究提出一个新的用于检测任意形状的场景文本框架:Progressive Contour Regression(PCR),在 CTW1500、Total-Text、ArT 和 TD500多个公共基准上取得了最先进的性能。包括弯曲的、波浪形的、长的、定向的和多语言的场景文本。
具体来说,利用轮廓信息聚合来丰富轮廓特征表示,可以抑制冗余和嘈杂的轮廓点的影响,对任意形状的文本产生更准确的定位。同时,整合一个可靠的轮廓定位机制,通过预测轮廓的置信度来缓解假阳性。
作者 | Pengwen Dai, Sanyi Zhang, Hua Zhang, Xiaochun Cao
单位 | 中科院;国科大;鹏城实验室;天津大学
论文 | https://openaccess.thecvf.com/content/CVPR2021/papers/Dai_Progressive_Contour_Regression_for_Arbitrary-Shape_Scene_Text_Detection_CVPR_2021_paper.pdf
代码 | https://github.com/dpengwen/PCR

TextOCR: Towards large-scale end-to-end reasoning for arbitrary-shaped scene text
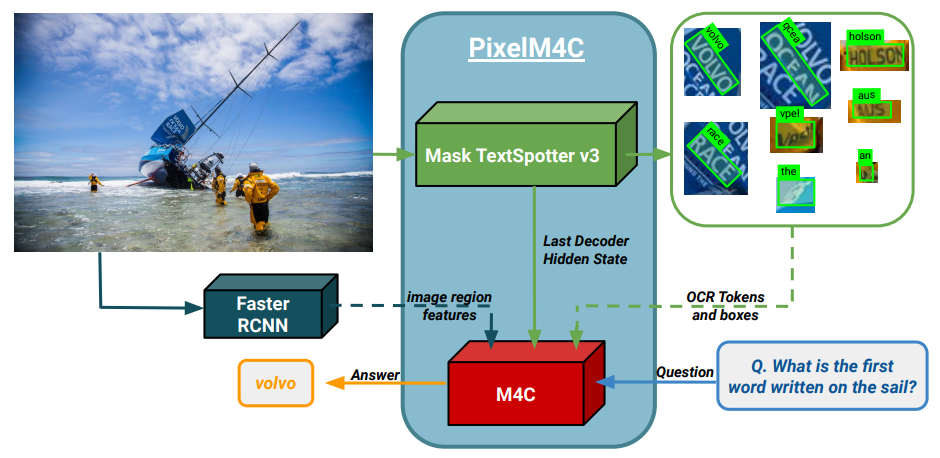
本文介绍一个在 TextVQA 图像上收集的大型任意场景文本识别数据集 TextOCR,以及一个端到端的模型 PixelM4C,该模型通过将文本识别模型作为一个模块,可以直接在图像上进行场景文本推理。
TextOCR,大型且多样化,来自 TextVQA 的 28,134 幅自然图像,有 100 万个任意形状的单词标注(比现有的数据集大3倍),每张图片有 32 个单词。作为训练数据集,在多个数据集上提高了 OCR 算法的精度 ;作为测试数据集,为社区提供新的挑战。
在TextOCR上进行训练,可以提供更好的文本识别模型,在大多数文本识别基准上超过最先进的水平。此外,在 PixelM4C 中使用 TextOCR 训练的文本识别模块,可以使用它的不同特征,甚至有可能提供反馈,这使得 PixelM4C超越了 TextVQA 的现有最先进方法。
通过 TextOCR 数据集和 PixelM4C 模型,在连接 OCR 和基于 OCR 的下游应用方面迈出了一步,并从直接在 TextOCR 上训练的 TextVQA 结果中所看到的改进,希望该研究能够同时推动这两个领域的发展。
作者 | Amanpreet Singh, Guan Pang, Mandy Toh, Jing Huang, Wojciech Galuba, Tal Hassner
单位 | Facebook
论文 | https://arxiv.org/abs/2105.05486
主页 | https://textvqa.org/textocr
场景文本识别
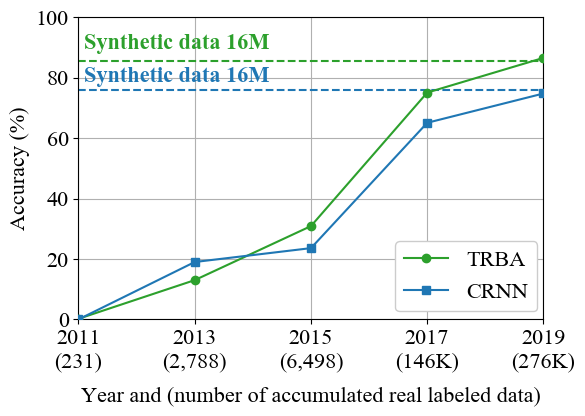
What If We Only Use Real Datasets for Scene Text Recognition? Toward Scene Text Recognition With Fewer Labels
本次工作的研究目的是使用更少的标签来运用 STR(场景文本识别) 模型。作者用只占合成数据 1.7% 的真实数据来充分地训练 STR 模型。通过使用简单的数据增广和引入半监督和自监督的方法,利用数百万真实的无标签数据,进一步提高性能。作者称该工作是迈向更少标签的 STR 的垫脚石,并希望这项工作能促进未来关于这个主题的工作。
作者 | Jeonghun Baek, Yusuke Matsui, Kiyoharu Aizawa
单位 | 东京大学
论文 | https://arxiv.org/abs/2103.04400
代码 | https://github.com/ku21fan/STR-Fewer-Labels
Read Like Humans: Autonomous, Bidirectional and Iterative Language Modeling for Scene Text Recognition
提出 ABINet,用于场景本文识别,它具有自主性、双向性以及迭代性。其中自主性是提出阻断视觉和语言模型之间的梯度流动,以执行明确的语言建模;双向性表现在,提出一种基于双向特征表示的新型 bidirectional cloze network(BCN)作为语言模型;迭代性是提出一种语言模型迭代校正的执行方式,可以有效地缓解噪声输入的影响。此外,基于迭代预测的集合,提出一种自训练方法,可以有效地从未标记的图像中学习。
结果:实验结果显明,ABINet 在低质量图像上具有优势,并在几个主流基准上取得了最先进的结果。此外,用集合自训练法训练的 ABINet 向实现人类水平的识别水平又进了一步。
作者 | Shancheng Fang, Hongtao Xie, Yuxin Wang, Zhendong Mao, Yongdong Zhang
单位 | 中国科学技术大学
论文 | https://arxiv.org/abs/2103.06495
代码 | https://github.com/FangShancheng/ABINet
备注 | CVPR 2021 Oral

MOST: A Multi-Oriented Scene Text Detector with Localization Refinement
问题:改善在极端长宽比和不同尺度的文本实例时的文本检测性能。
方案:Text Feature Alignment Module(TFAM),根据最初的原始检测结果动态地调整特征的感受野;Position-Aware Non-Maximum Suppression(PA-NMS)模块,选择性地集中可靠的原始检测,并排除不可靠的检测。此外,还提出 Instance-wise IoU 损失,用于平衡训练,以处理不同尺度的文本实例。
将此与 EAST 相结合,在各种文本检测的标准基准上实现了最先进或有竞争力的性能,同时可以保持快速的运行速度。
作者 | Minghang He, Minghui Liao, Zhibo Yang, Humen Zhong, Jun Tang, Wenqing Cheng, Cong Yao, Yongpan Wang, Xiang Bai
单位 | 华中科技大学;阿里;南大
论文 | https://arxiv.org/abs/2104.01070

Dictionary-guided Scene Text Recognition
本次研究,作者提出一种新的语言感知方法来解决场景文本识别中的视觉模糊性问题。该方法在训练和推理阶段都可以利用字典的力量,可以解决许多条件下的模糊性。另外,创建一个用于越南场景文本识别的新数据集:VinText,它在从多个类似字符中辨别一个字符方面带来了新的挑战。
在 TotalText、ICDAR13、ICDAR15 和新收集的 VinText 数据集上的实验结果证明了该字典整合方法的优点。
作者 | Nguyen Nguyen, Thu Nguyen, Vinh Tran, Minh-Triet Tran, Thanh Duc Ngo, Thien Huu Nguyen, Minh Hoa
单位 | VinAI研究等
论文 | https://openaccess.thecvf.com/content/CVPR2021/papers/Nguyen_Dictionary-Guided_Scene_Text_Recognition_CVPR_2021_paper.pdf
代码 | https://github.com/VinAIResearch/dict-guided

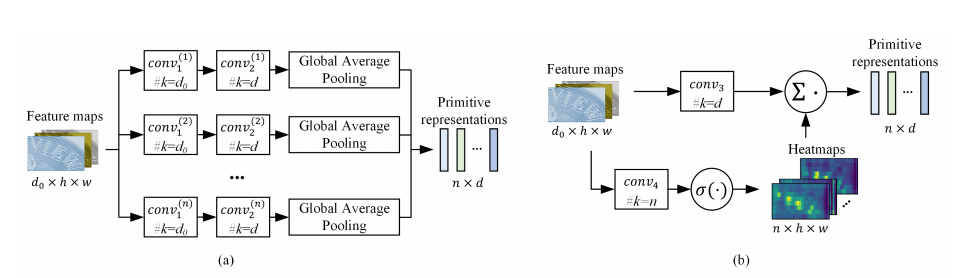
Primitive Representation Learning for Scene Text Recognition
与常用的基于 CTC 和基于注意力的方法不同,作者通过学习原始表征并形成可用于并行解码的视觉文本表征,提出一个新的场景文本识别框架。又提出一个 pooling aggregator 和一个 weighted aggregator,从 CNN 输出的特征图中学习原始表征,并使用 GCN 将原始表征转换为视觉文本表征。所提出的原始表征学习方法可以被整合到基于注意力的框架中。并在英文和中文场景文本识别任务的实验结果证明了所提出方法的有效性和高效率。
作者 | Ruijie Yan, Liangrui Peng, Shanyu Xiao, Gang Yao
单位 | 清华大学
论文 | https://arxiv.org/abs/2105.04286
文本识别与检测
Implicit Feature Alignment: Learn to Convert Text Recognizer to Text Spotter
本次工作提出一个简单而有效新范式:IFA,将 text recognizer 转变为 detection-free text spotter,利用神经网络的可学习对齐特性,可以很容易地集成到当前主流的文本识别器中。得到一种全新的推理机制:IFAinference。使普通的文本识别器能够处理多行文本。
具体来说,作者将 IFA 整合到两个最流行的文本识别流中(基于注意力和基于CTC),分别得到两种新的方法:ADP 和 ExCTC。此外,还提出基于Wasserstein 的 Hollow Aggregation Cross-Entropy(WH-ACE)来抑制负面噪音,以帮助训练 ADP 和 ExCTC。
实验结果表明 IFA 在端到端文档识别任务中取得了最先进的性能,同时保持了最快的速度,而 ADP 和 ExCTC 在不同应用场景的角度上相互补充。
作者 | Tianwei Wang, Yuanzhi Zhu, Lianwen Jin, Dezhi Peng, Zhe Li, Mengchao He, Yongpan Wang, Canjie Luo
单位 | 华南理工大学;阿里等
论文 | https://arxiv.org/abs/2106.05920

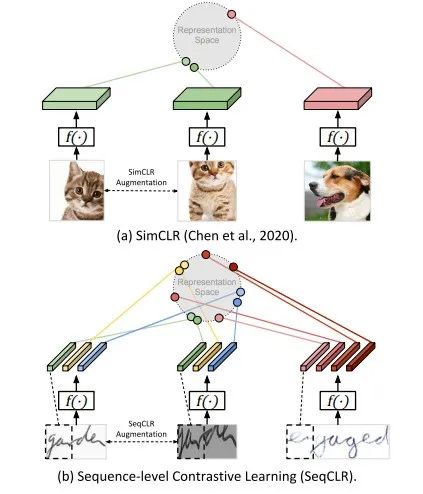
Sequence-to-Sequence Contrastive Learning for Text Recognition
本次工作提出一个对比性学习方法:SeqCLR,用于文本识别。将每个特征图看作是一系列的独立实例,得到 sub-word 级上的对比学习,例如每个图像提取几个正面的配对和多个负面的例子。另外,为获得有效的文本识别视觉表征,进一步提出新的增强启发式方法、不同的编码器架构和自定义投影头。
在手写文本和场景文本上的实验表明,当用学到的表征训练文本解码器时,所提出方法优于非序列对比法。此外,当监督量减少时,与监督训练相比,SeqCLR 明显提高了性能,而当用 100% 的标签进行微调时,SeqCLR 在标准手写文本识别基准上取得了最先进的结果。
作者 | Aviad Aberdam, Ron Litman, Shahar Tsiper, Oron Anschel, Ron Slossberg, Shai Mazor, R. Manmatha, Pietro Perona
单位 | 以色列理工学院;亚马逊等
论文 | https://arxiv.org/abs/2012.10873
Self-attention based Text Knowledge Mining for Text Detection
本文提出 STKM,可以进行端到端训练,以获得一般的文本知识,用于下游文本检测任务。是首次尝试为文本检测提供通用的预训练模型。并证明 STKM 可以在不同的基准上以很大的幅度提高各种检测器的性能。
作者 | Qi Wan, Haoqin Ji, Linlin Shen
单位 | 深圳市人工智能与机器人研究院;深圳大学
论文 | https://openaccess.thecvf.com/content/CVPR2021/papers/Wan_Self-Attention_Based_Text_Knowledge_Mining_for_Text_Detection_CVPR_2021_paper.pdf
代码 | https://github.com/CVI-SZU/STKM
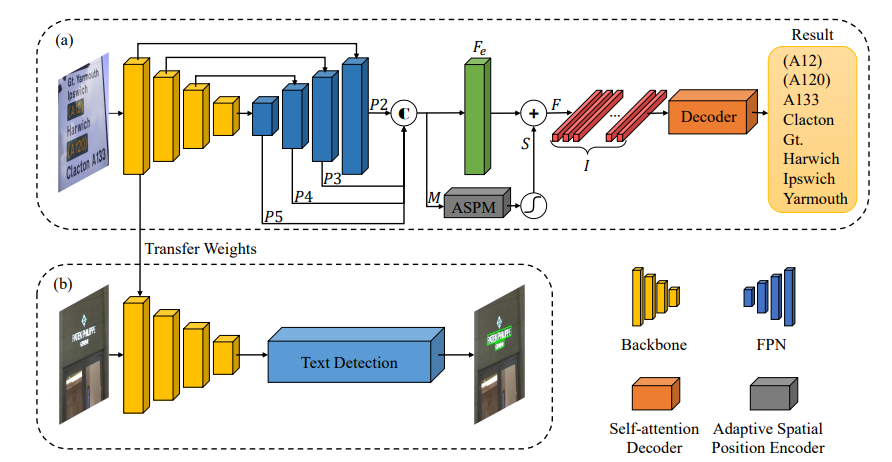
A Multiplexed Network for End-to-End, Multilingual OCR
研究问题:当前的文本检测方法主要集中在拉丁字母语言上,甚至经常只有不区分大小写的英文字符。
提出方案:E2E-Multiplexed Multilingual Mask TextSpotter,在 word 级上进行脚本识别,并以不同的识别头处理不同的脚本,同时保持一个统一的损失,以及优化脚本识别和多个识别头。
结果:实验结果表明,所提出方法在端到端识别任务中优于参数数量相似的single-head 模型,并在 MLT17 和 MLT19 联合文本检测和脚本识别基准上取得了最先进的结果。
作者 | Jing Huang, Guan Pang, Rama Kovvuri, Mandy Toh, Kevin J Liang, Praveen Krishnan, Xi Yin, Tal Hassner
单位 | Facebook
论文 | https://arxiv.org/abs/2103.15992
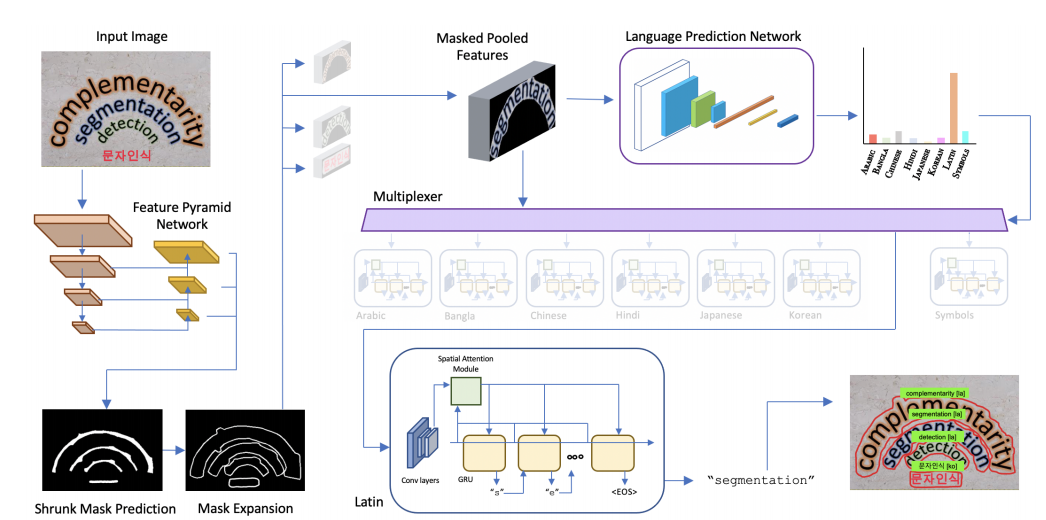
TAP: Text-Aware Pre-training for Text-VQA and Text-Caption
本次工作提出 Text-Aware Pre-training(TAP),用于 Text-VQA 和 Text-Caption 两个任务。目的是阅读和理解图像中的场景文本,分别用于回答问题和生成图像字幕。与传统的视觉语言预训练不同的是,传统的视觉语言预训练不能捕捉到场景文本及其与视觉和文本模态的关系。而 TAP 则明确地将场景文本(由OCR引擎生成)纳入预训练中。
通过masked language modeling(MLM), image-text(contrastive) matching(ITM)和relative(spatial)position prediction (RPP)三个预训练任务,TAP 可以帮助模型在三种模式中学习更好的对齐表示:文本字、视觉目标和场景文本。由于这种对齐的表征学习,在相同的下游任务数据集上进行预训练,与非 TAP 基线相比,TAP 将TextVQA 数据集的绝对准确率提高了 +5.4%。
此外,作者还创建一个基于 Conceptual Caption 数据集的大规模数据集:OCR-CC,包含 140 万个场景文本相关的图像-文本对。在 OCR-CC 数据集上进行预训练后,所提出方法在多个任务上以较大的幅度超过了现有技术水平,即在 TextVQA 上的准确率为 +8.3%,在 ST-VQA 上的准确率为+8.6%,在 TextCaps 上的 CIDEr 得分为 +10.2。
作者 | Zhengyuan Yang, Yijuan Lu, Jianfeng Wang, Xi Yin, Dinei Florencio, Lijuan Wang, Cha Zhang, Lei Zhang, Jiebo Luo
单位 | 罗切斯特大学;微软
论文 | https://arxiv.org/abs/2012.04638

场景文本检索
Scene Text Retrieval via Joint Text Detection and Similarity Learning
场景文本检索的目的是定位和搜索图像库中的所有文本实例,这些文本与给定的查询文本相同或相似。这样的任务通常是通过将查询文本与由端到端场景文本识别器输出的识别词相匹配来实现。
本次工作,作者通过直接学习查询文本和自然图像中每个文本实例之间的跨模态相似性来解决这个问题。具体来说,建立一个端到端的可训练网络,来共同优化场景文本检测和跨模态相似性学习的程序。这样一来,场景文本检索就可以通过对检测到的文本实例与学习到的相似性进行排序来简单地进行。
在三个基准数据集上的实验表明,所提出方法始终优于最先进的场景文 spotting/检索方法。特别是,所提出的联合检测和相似性学习的框架取得了明显优于分离方法的性能。
作者 | Hao Wang, Xiang Bai, Mingkun Yang, Shenggao Zhu, Jing Wang, Wenyu Liu
单位 | 华中科技大学;华为
论文 | https://arxiv.org/abs/2104.01552
代码 | https://github.com/lanfeng4659/STR-TDSL

手写文本识别
MetaHTR: Towards Writer-Adaptive Handwritten Text Recognition
本文介绍一个 writer-adaptive HTR 问题,即模型在推理过程中只用很少的样本就能适应新的书写风格。
作者 | Ayan Kumar Bhunia, Shuvozit Ghose, Amandeep Kumar, Pinaki Nath Chowdhury, Aneeshan Sain, Yi-Zhe Song
单位 | 萨里大学等
论文 | https://arxiv.org/abs/2104.01876

文本分割
Rethinking Text Segmentation: A Novel Dataset and A Text-Specific Refinement Approach
文本分割是许多现实世界中与文本相关任务的先决条件,例如文本样式的迁移和场景文本擦除。但由于缺乏高质量的数据集和专门的调查,该先决条件在许多工作中被作为一种假设,并在很大程度上被忽视。
基于上述原因,作者提出 TextSeg,一个大规模的细致标注的文本数据集,包含六种类型的标注:word- and character-wise bounding polygons, masks 和 transcriptions。还设计一个 Text Refinement Network (TexRNet),是一种全新的文本分割方法,能够适应文本的独特属性,一些往往给传统分割模型带来负担的属性,如非凸形边界、多样化的纹理等。设计有效的网络模块(即关键特征池和基于注意力的相似性检查)和损失(即 trimap loss 和 glyph discriminator)来解决这些挑战,例如,不同的纹理和任意的尺度/形状。
在 TextSeg 数据集以及其他现有的数据集上的实验证明,与其他最先进的分割方法相比,TexRNet 始终能将文本分割性能提高近 2%。
作者 | Xingqian Xu, Zhifei Zhang, Zhaowen Wang, Brian Price, Zhonghao Wang, Humphrey Shi
单位 | UIUC;Adobe;俄勒冈大学
论文 | https://arxiv.org/abs/2011.14021
代码 | https://github.com/SHI-Labs/Rethinking-Text-Segmentation

视频文本检测
Semantic-Aware Video Text Detection
一些现有的视频文本检测方法都是通过外观特征来对文本进行追踪,这些特征又很容易受到视角和光照变化的影响。而与外观特征相比,语义特征是匹配文本实例的更有力线索。
本次工作提出一个端到端的可训练的视频文本检测器,是基于语义特征来跟踪文本。
首先,引入一个新的字符中心分割分支来提取语义特征,它编码字符的类别和位置。然后,提出一个新的 appearance-semanticgeometry 描述器来跟踪文本实例,其中语义特征可以提高对外观变化的鲁棒性。
另外,为了克服字符级标注的不足,又提出一个弱监督字符中心检测模块,它只使用字级标注的真实图像来生成字符级标签。
在三个视频文本基准 ICDAR 2013 Video、Minetto 和 RT-1K,以及两个中文场景文本基准 CASIA10K 和 MSRA-TD500 上取得了最先进的性能。
作者 | Wei Feng, Fei Yin, Xu-Yao Zhang, Cheng-Lin Liu
单位 | 中科院;国科大
论文 | https://openaccess.thecvf.com/content/CVPR2021/papers/Feng_Semantic-Aware_Video_Text_Detection_CVPR_2021_paper.pdf

- END -
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
