
ECCV 2020 论文大盘点 - OCR 篇
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:我爱计算机视觉
本文盘点 ECCV 2020 与 OCR 相关论文,包括 Text Detection(文本检测)、Text Recognition(文本识别)、神经架构搜索+文本识别、文本超分辨率、Scene text spotting(将检测和识别放一起,端到端文本识别)。

An End-to-End OCR Text Re-organization Sequence Learning for Rich-text Detail Image Comprehension
作者 | Liangcheng Li, Feiyu Gao, Jiajun Bu, Yongpan Wang, Zhi Yu, Qi Zheng
单位 | 浙江大学;阿里巴巴等
论文 | https://www.ecva.net/papers/eccv_2020/
papers_ECCV/papers/123700086.pdf
备注 | ECCV 2020

PlugNet: Degradation Aware Scene Text Recognition Supervised by a Pluggable Super-Resolution Unit
作者 | Yongqiang Mou, Lei Tan, Hui Yang, Jingying Chen, Leyuan Liu, Rui Yan, Yaohong Huang
单位 | ImageDT图匠数据;华中师范大学
论文 | https://www.ecva.net/papers/eccv_2020/
papers_ECCV/papers/123600154.pdf
备注 | ECCV 2020
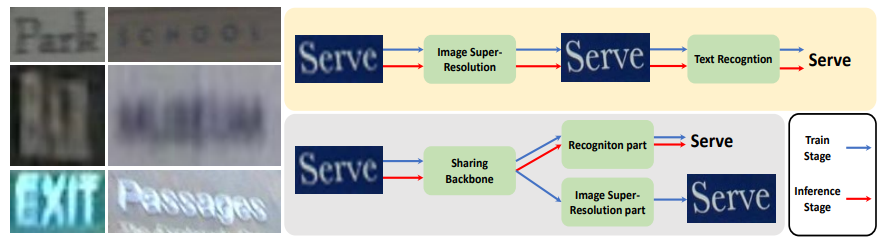
作者提出一个含有可插拔超分辨单元的端到端学习的文本识别方法(PlugNet),极大的解决了低质量图像识别的难题。
Adaptive Text Recognition through Visual Matching
作者 | Chuhan Zhang, Ankush Gupta, Andrew Zisserman
单位 | 牛津大学;DeepMind
论文 | https://arxiv.org/abs/2009.06610
代码 | https://github.com/Chuhanxx/FontAdaptor
主页 | http://www.robots.ox.ac.uk/~vgg/research/FontAdaptor20/
备注 | ECCV 2020
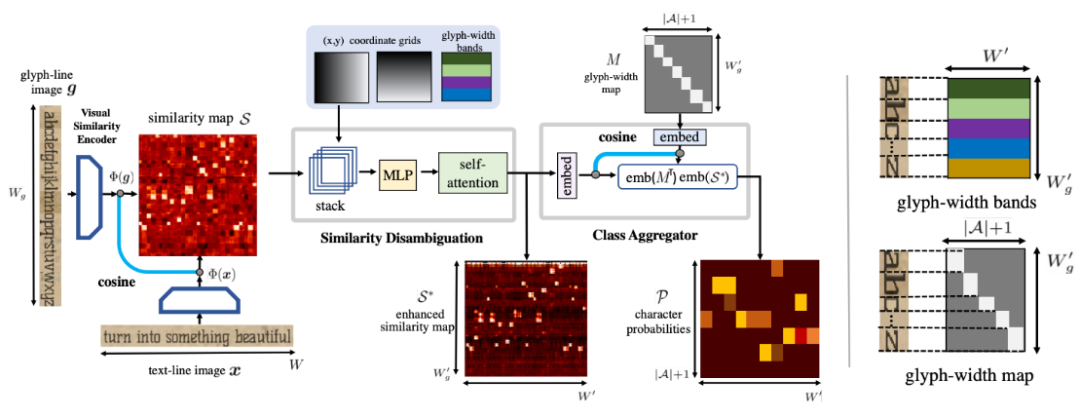
本文旨在解决文档中文本识别的广泛性与灵活性。引入一个新模型,利用语言中字符的重复性,将视觉表征学习和语言建模阶段分离,将文本识别变成 shape matching 问题。
RobustScanner: Dynamically Enhancing Positional Clues for Robust Text Recognition
作者 | Xiaoyu Yue, Zhanghui Kuang, Chenhao Lin, Hongbin Sun, Wayne Zhang
单位 | 商汤;西安交通大学
论文 | https://arxiv.org/abs/2007.07542
备注 | ECCV 2020

AutoSTR: Efficient Backbone Search for Scene Text Recognition
作者 | Hui Zhang, Quanming Yao, Mingkun Yang, Yongchao Xu, Xiang Bai
单位 | 华中科技大学;第四范式(北京)技术有限公司
论文 | https://arxiv.org/abs/2003.06567
代码 | https://github.com/AutoML-4Paradigm/AutoSTR
备注 | ECCV 2020
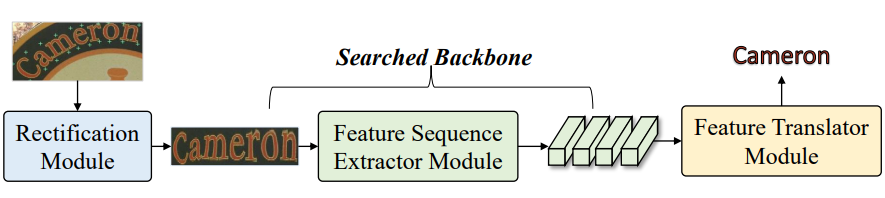
本项工作,作者受神经架构搜索(NAS)的成功启发,可以识别出比人类设计更好的架构。提出自动STR(AutoSTR)来搜索依赖于数据的框架,以提高文本识别性能。
为STR设计了一个特定领域的搜索空间,其中包含了对操作的选择和对下采样路径的约束。然后,提出一种两步搜索算法,将操作和下采样路径解耦,在给定空间中进行高效搜索。
实验证明,通过搜索数据相关的骨干,AutoSTR可以在标准基准上以更少的FLOPS和模型参数超越最先进的方法。
Scene Text Image Super-resolution in the wild
作者 | Wenjia Wang, Enze Xie, Xuebo Liu, Wenhai Wang, Ding Liang, Chunhua Shen, Xiang Bai
单位 | 商汤;香港大学;南京大学;阿德莱德大学;华中科技大学
论文 | https://arxiv.org/abs/2005.03341
代码 | https://github.com/JasonBoy1/TextZoom
备注 | ECCV 2020
介绍了第一个真正意义上的配对场景文本超分辨率数据集TextZoom,采用不同的焦距。用三个子集来标注和分配数据集:分别是简单、中等和困难。
通过比较和分析在合成LR和提出的LR图像上训练的模型,证明了所提出的数据集 TextZoom 的优越性,并从不同方面证明了场景文本SR的必要性。
另外该问还提出一个新的文本超分辨率网络,有三个新颖的模块。通过在TextZoom上的训练和测试,以及公平的比较,证明它明显超过了7种有代表性的SR方法。

Scene text spotting
Mask TextSpotter v3: Segmentation Proposal Network for Robust Scene Text Spotting
作者 | Minghui Liao, Guan Pang, Jing Huang, Tal Hassner, Xiang Bai
单位 | 华中科技大学;Facebook AI
论文 | https://arxiv.org/abs/2007.09482
代码 | https://github.com/MhLiao/MaskTextSpotterV3
解读|Mask TextSpotter v3 来了!最强端到端文本识别模型
备注 | ECCV 2020
目前的方法多用 RPN 来进行 integrating detection and recognition(集检测与识别一体)的场景文本检测,但在极端长宽比或不规则形状的文本以及密集定向的文本中进行操作有一定的困难。
因此,本文提出Mask TextSpotter v3,一个端到端可训练的场景文本发现器,采用 Segmentation Proposal Network (SPN) 来代替 RPN。SPN是无锚的,可以准确地表示任意形状的提案,所以优于 RPN。Mask TextSpotter v3 可以处理极端长宽比或不规则形状的文本实例,并且识别精度不会受到附近文本或背景噪声的影响。
具体来说,在Rotated ICDAR 2013数据集上的表现比最先进的方法高出21.9%(旋转鲁棒性),在Total-Text数据集上的表现比最先进的方法高出5.9%(形状鲁棒性),在MSRA-TD500数据集上的表现也达到了最先进的水平(长宽比鲁棒性)。

AE TextSpotter: Learning Visual and Linguistic Representation for Ambiguous Text Spotting
作者 | Wenhai Wang, Xuebo Liu, Xiaozhong Ji, Enze Xie, Ding Liang, Zhibo Yang, Tong Lu, Chunhua Shen, Ping Luo
单位 | 南京大学;商汤;香港大学;阿里巴巴;阿德莱德大学
论文 | https://arxiv.org/abs/2008.00714
代码 | https://github.com/whai362/TDA-ReCTS
备注 | ECCV 2020
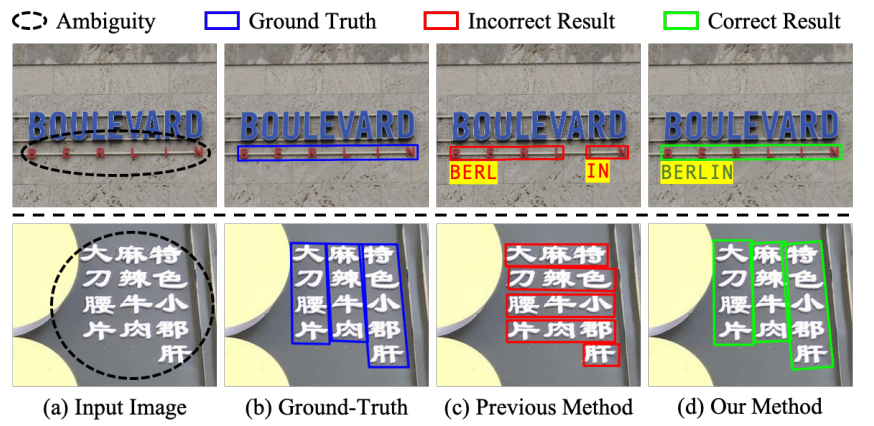
问题:字符之间的间距较大或字符均匀分布在多行多列时,会发生歧义,使得许多视觉上可信的字符分组。
方案:提出一种新型文本发现器,消除歧义文本发现器(AE TextSpotter),可以同时学习视觉和语言特征,以显著降低文本检测的歧义性。
优点:1、语言表征与视觉表征在同一框架,作者表示是第一次利用语言模型来改进文本检测。
2、利用精心设计的语言模块降低了错误文本行的检测置信度,使其在检测阶段容易被修剪。
3、实验表明,AE TextSpotter比其他SOTA方法有很大的优势。例如,从IC19-ReCTS数据集中精心挑选了一组极度模糊的样本进行验证,所提出方法超过其他方法4%以上。

下载1:OpenCV黑魔法
在「AI算法与图像处理」公众号后台回复:OpenCV黑魔法,即可下载小编精心编写整理的计算机视觉趣味实战教程
下载2 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得有趣就点亮在看吧
