
盘点 | CVPR 二十年,影响力最大的 10 篇论文!
点击左上方蓝字关注我们

虽然CVPR每年都会评选出最佳论文,但我们今天将从另一个角度来评选CVPR这二十年来的TOP10。即以Web of Science上显示的论文的引用量作为论文影响力的参考,排列出近二十年来影响力最大的十篇论文。接下来我们将依次进行介绍。
TOP10
Rethinking the Inception Architecture for Computer Vision
CVPR 2016
作者:Christian Szegedy,Vincent Vanhoucke,Sergey Ioffe,Jon Shlens,Zbigniew Wojna
机构:Google,伦敦大学
被引频次:4751

这篇论文又被称为Inception-v3,是GoogLeNet(Inception-v1)的延伸。GoogLeNet首次出现于2014年ILSVRC 比赛,并在当年的比赛中获得了冠军。Inception-v1的参数量远小于同期VGGNet,而性能却与之基本持平。相较于Inception-v1,Inception-v3做出的主要改进则是将卷积进行非对称拆分,以显著降低参数量,同时使得空间特征更为丰富。

TOP9
Densely Connected Convolutional Networks
CVPR 2017
作者:Gao Huang,Zhuang Liu,Laurens van der Maaten,Kilian Q. Weinberger
机构:康奈尔大学,清华大学,Facebook AI Research
被引频次:5181

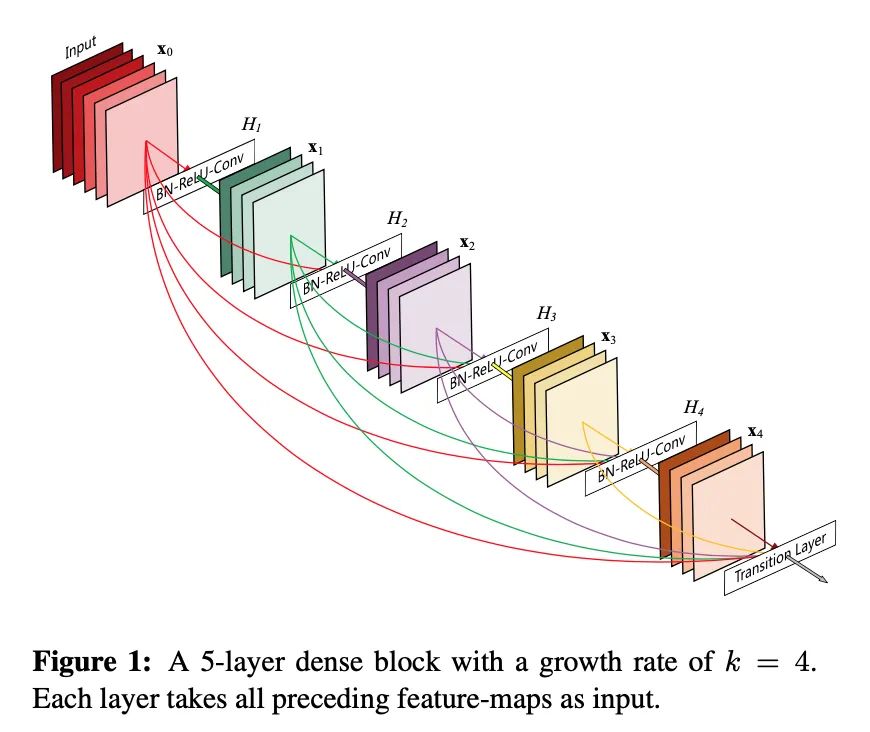
DenseNet也是CVPR2017的最佳论文之一。在当时的神经网络模型都遇到一个问题:随着网路层数的加深,训练过程中的前传信号和梯度信号在经过很多层之后可能会逐渐消失。而DenseNet的核心思想解决了这一问题。它对前每一层都加一个单独的 shortcut,使得任意两层网络都可以直接“沟通”。
而DenseNet的不足之处在于它的内存占用十分庞大。但瑕不掩瑜,DenseNet以其极具创新性的思路,不仅显著减轻了深层网络在训练过程中梯度消散而难以优化的问题,同时也取得了非常好的性能。
TOP8
You Only Look Once: Unified, Real-Time Object Detection
CVPR 2016
作者:Joseph Redmon,Santosh Divvala,Ross Girshick,Ali Farhadiq
机构:华盛顿大学,Allen Institute for AI,Facebook AI Research
被引频次:5295

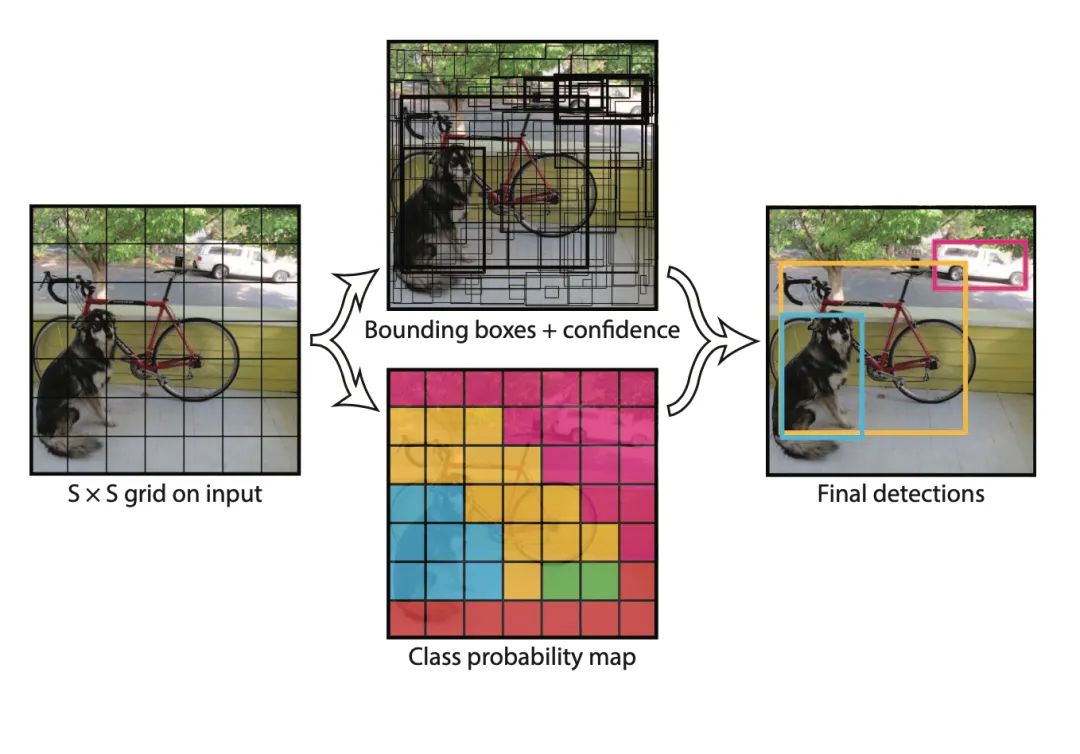
这一篇论文就是在目标检测领域大名鼎鼎的YOLO。其最新的版本已经更新到了YOLOv5,且每一代的发布都能在行业内卷齐新的热潮。
用YOLO的英文直译解释这一方法,就是只需要浏览一次就能识别出图中的物体的类别和位置。展开来说,YOLO的核心思想就是将目标检测转化为回归问题求解,并基于一个单独的端到端网络,完成从原始图像的输入到物体位置和类别的输出。这使得网络结构简单,且极大提升了检测速度。由于网络没有分支,所以训练也只需要一次即可完成。之后的很多检测算法都借鉴了这一思路。
TOP7
Rich feature hierarchies for accurate object detection and semantic segmentation
CVPR 2014
作者:Ross Girshick,Jeff Donahue,Trevor Darrell,Jitendra Malik
机构:加利福尼亚大学伯克利分校
被引频次:6876

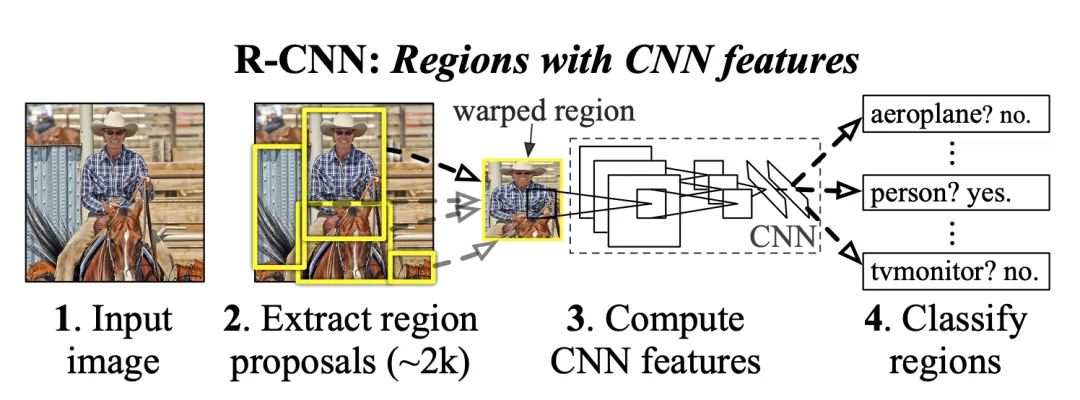
这篇文章的排名在YOLO之前,既合理又巧妙。因为在YOLO之前,目标检测领域可以说是RCNN的世界。RCNN是将CNN引入目标检测的开山之作,它改变了目标检测领域的主要研究思路。紧随其后的系列文章,如Fast RCNN和Faster RCNN等,都代表了该领域当时的最高水准。
在RCNN前经典的目标检测算法是使用滑动窗法依次判断所有可能的区域,而RCNN则采用Selective Search方法预先提取一系列较可能是物体的候选区域,之后仅在这些候选区域上提取特征,这使得检测的速度大大提升。
TOP6
Rapid object detection using a boosted cascade of simple features
CVPR 2001
作者:Paul Viola,Michael Jones
机构:三菱电气实验室 ,康柏剑桥研究实验室
被引频次:7033

这篇论文是本次盘点中最先发表的一篇,比其他九篇文章都早了十年左右,它在传统人脸检测中具有里程碑意义,因而本文提出的思想聚焦于传统的目标检测。
这篇论文主要解决了三个问题:一是减少了计算特征的时间,二是构建了简单又很有效的单分支决策树分类器,最后是从简单到复杂把多个分类器级联,对可能包含人脸的区域进行重点检测,从而显著提升了检测速度。
TOP5
Going Deeper with Convolutions
CVPR 2015
作者:Christian Szegedy,Dragomir Anguelov, Dumitru Erhan,Vincent Vanhoucke,Yangqing Jia,Pierre Sermanet,Wei Liu,Scott Reed,Andrew Rabinovich
机构:Google,北卡罗来纳大学,密歇根大学
发布时间:2015年
被引频次:7269

可能大家已经发现了亮点,这篇论文的系列工作在前面就出现过。这篇论文就是开辟Inception家族,并在CNN分类器发展史上留下浓墨重彩的一笔的GoogLeNet。
在 Inception 出现之前,大部分流行 CNN 是将卷积层不断堆叠,让网络越来越深来得到更好的性能。而GoogLeNet 最大的特点就是使用 Inception 模块,并设计一种具有优良局部拓扑结构的网络,对输入图像并行地执行多个卷积运算或池化操作,将所有输出结果拼接为一个非常深的特征图。通过这种方式,GoogLeNet取得了非常惊艳的效果。
TOP4
ImageNet: A Large-Scale Hierarchical Image Database
CVPR 2009
作者:Jia Deng,Wei Dong,Richard Socher,Li-Jia Li,Kai Li,Li Fei-Fei
机构:普林斯顿大学
发布时间:2009年
被引频次:8222

ImageNet是AI女神李飞飞团队构建的计算机视觉领域非常著名的海量的带标注图像数据集。它在图像分类、目标分割和目标检测中都有着无法撼动的地位。ImageNet从 2007 年开始到 2009 年完成,有超过 1500 万张图片。
可以毫不夸张的说,ImageNet 是图像处理算法的试金石。另外,从 2010 年起,每年 ImageNet 官方会举办挑战赛。Hinton团队提出的AlexNet也是在2012年的ImageNet挑战赛上一举成名,自此深度学习的热潮被点燃。

TOP3
Fully Convolutional Networks for Semantic Segmentation
CVPR 2015
作者:Jonathan Long,Evan Shelhamer,Trevor Darrell
发布时间:2015年
被引频次:9027

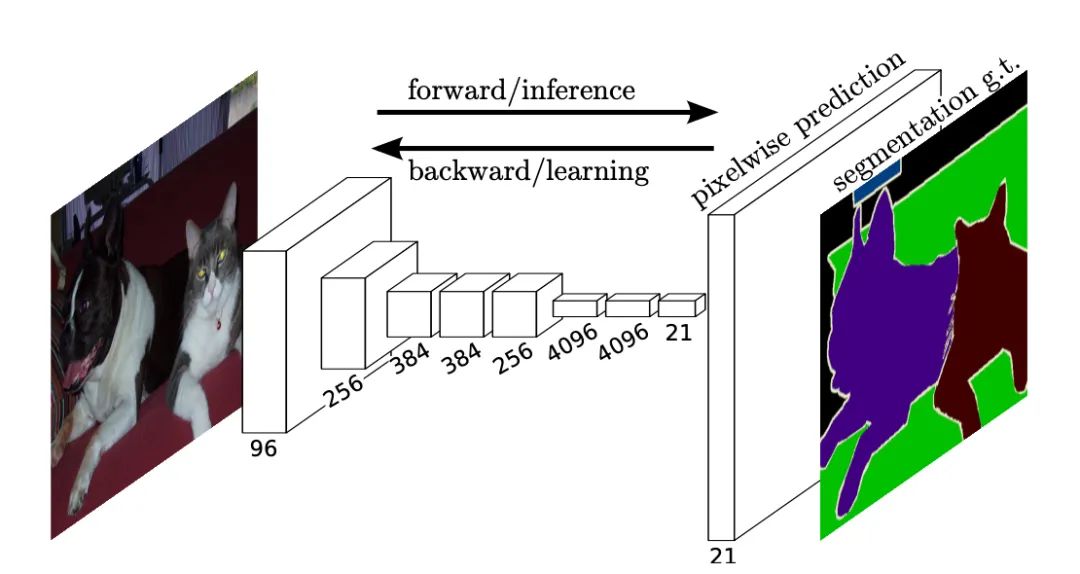
FCN在我们之前盘点的图像分割TOP10中就出现过,并高居第一位。作为语义分割的开山之作,无论是图像分割TOP1,还是CVPRTOP3,FCN都是当之无愧的。FCN所提出的全卷积网络的概念,开创了用FCN做实例和像素级别理解系列方法的先河。后续非常多的方法都受到了FCN的思路启发。FCN的提出为目标识别、检测与分割也都做出了巨大的贡献。
TOP2
Histograms of oriented gradients for human detection
CVPR 2005
作者:Navneet Dalal,Bill Triggs
被引频次:13389

这篇论文所提出的方法简称HOG,是一种是非常经典的图像特征提取方法,在行人识别领域被应用得尤为多。虽然文章已经发表了十五年,但仍然常常被人们用于最新工作的思路参考。HOG将图像分成小的连通区域,将它称为细胞单元,然后采集细胞单元中各像素点的梯度的或边缘的方向直方图,把这些直方图组合起来就可以构成特征描述器。
TOP1
Deep Residual Learning for Image Recognition
CVPR2016
作者:Kaiming He,Xiangyu Zhang,Shaoqing Ren,Jian Sun
被引频次:32065

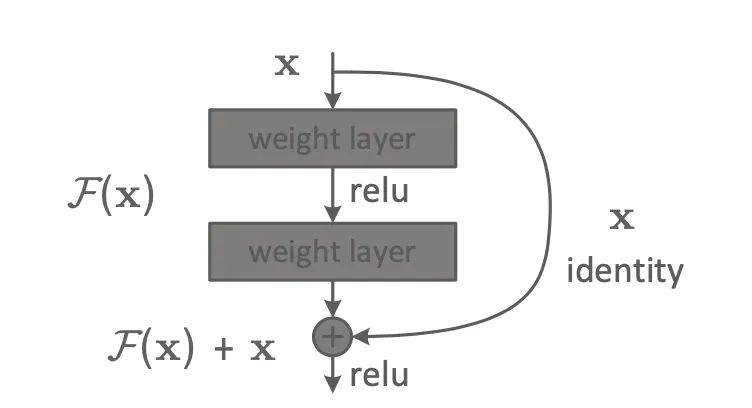
这篇论文作为第一名,的确是当之无愧。作为CVPR2016的最佳论文,它所提出的ResNet不仅在计算机视觉领域,而是在深度学习领域中都带来了颠覆式影响。
在当年,ResNet横扫 ImageNet 2015和COCO 榜单。也是从ResNet开始,神经网络在视觉分类任务上的性能第一次超越了人类。它也让当时第二次获得CVPR Best Paper的何恺明正式踏上了大神之路。
最初 ResNet 的设计是用来处理深层 CNN 结构中梯度消失和梯度爆炸的问题,它将输入从卷积层的每个块添加到输出,让每一层更容易学习恒等映射,并且还减少了梯度消失的问题。而如今,残差模块已经成为几乎所有 CNN 结构中的基本构造。
最后,我们来进行一下简要地总结。虽然本次盘点的是20年内CVPRTOP10,但是有超过半数的论文都是在近十年发表的,由此可以窥见深度学习在近年来的飞跃式发展。因此我们可以期待在未来的计算机视觉领域,一定会有更多更强的工作,为我们的科研与生活带来更快更好的提升。
参考资料
[1] https://zhuanlan.zhihu.com/p/41691301
[2] https://www.zhihu.com/question/60109389/answer/203099761
[3] https://zhuanlan.zhihu.com/p/31427164
[4] https://zhuanlan.zhihu.com/p/23006190
[5] https://blog.csdn.net/weixin_37763809/article/details/88256828
[6] https://zhuanlan.zhihu.com/p/37505777
[7] https://zhuanlan.zhihu.com/p/77221549
[8] https://www.zhihu.com/question/433702668/answer/1617092684
[9] https://blog.csdn.net/zouxy09/article/details/7929348
[10] https://www.jiqizhixin.com/articles/2020-01-01
END
整理不易,点赞三连↓