
EfficientDet : 快又准,EfficientNet在目标检测领域的探索 | CVPR 2020
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
来源:【晓飞的算法工程笔记】 公众号
Google Brain出品,EfficientNet作者在目标检测领域的作品。EfficientDet基于EfficientNet,结合论文提出的轻量级的跨尺寸融合方法BiFPN以及定制的检测版混合缩放方法,既保证高精度也保持了高性能,EfficientDet-D7达到了SOTA,51.0mAP。整体而言,论文推出的新检测框架十分实用,期待作者的开源
论文: EfficientDet: Scalable and Efficient Object Detection

论文地址:https://arxiv.org/abs/1911.09070
Introduction
目前目标检测领域,高精度的模型通常需要很大的参数量和计算量,而轻量级的网络则一般都会牺牲精度。因此,论文希望建立一个可伸缩的高精度且高性能的检测框架。论文基于one-stage的检测网络范式,进行了多种主干网络、特征融合和class/box预测的结构尝试,主要面临两个挑战:
高效多尺度特征融合(efficient multi-scale feature fusion)
FPN是目前最广泛的多尺度融合方法,最近也有PANet和NAS-FPN一类跨尺度特征融合方法。对于融合不同的特征,最初的方法都只是简单地直接相加,然而由于不同的特征是不同的分辨率,对融合输出特征的共享应该是不相等的。为了解决这一问题,论文提出简单但高效加权的bi-directional feature pyramid network(BiFPN),该方法使用可学习的权重来学习不同特征的重要性,同时反复地进行top-down和bottom-up的多尺度融合
模型缩放(model scaling)
论文认为除了缩放主干网络和输入图片的分辨率,特征网络(feature network)和box/class预测网络的缩放对准确率和性能也是很重要的。作者借鉴EfficientNet,提出针对检测网络的混合缩放方法(compound scaling method),同时对主干网络,特征网络和box/class预测网络的分辨率/深度/宽度进行缩放
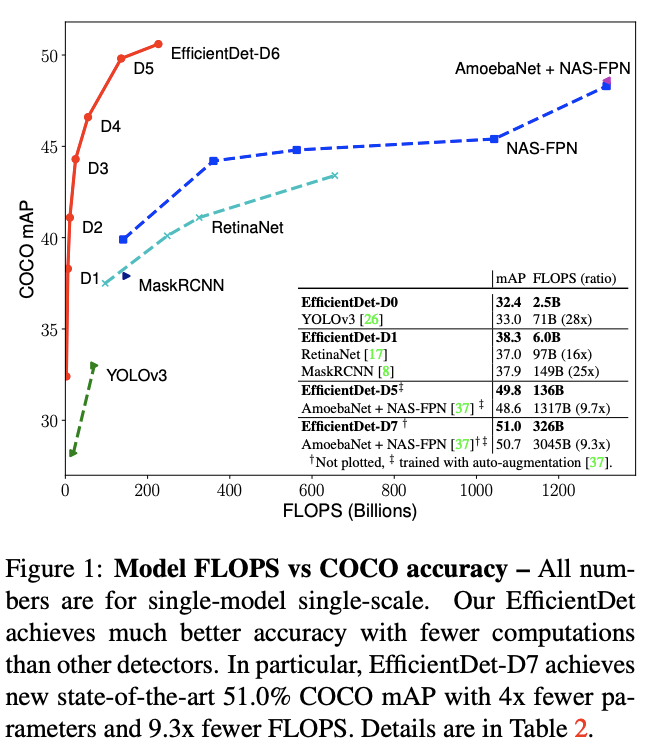
最后,论文将EfficientNet作为主干,结合BiFPN和混合缩放,提出新的检测系列EfficientDet,精度高且轻量,COCO上的结果如图1,论文的贡献有以下3点:
提出BiFPN,一个加权的双向特征网络,能够用以更快的多特征融合 提出新混合缩放方法,能同时规则地缩放主干网络、特征网络、box/class网络和分辨率 基于BiFPN和混合缩放,提出新的检测器系列EfficientDet,能够在准确率达到高精度的情况下结构更加精简
BiFPN
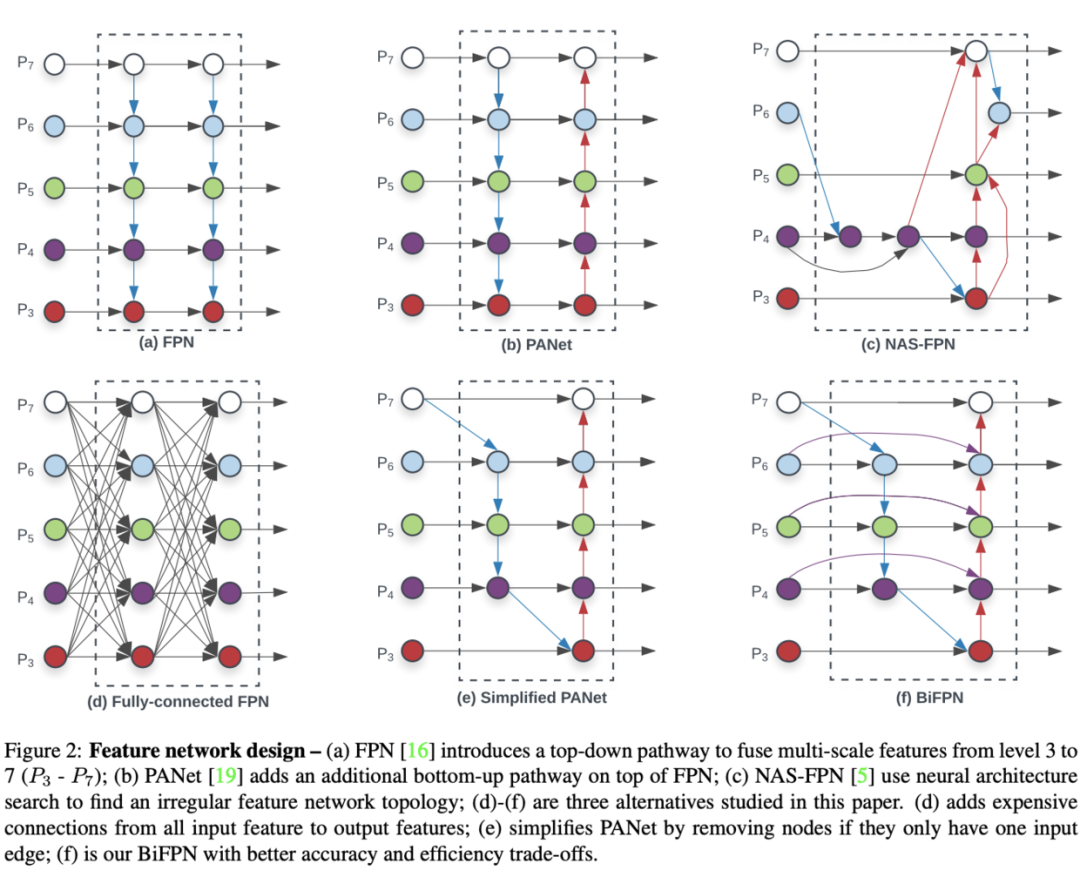
Problem Formulation
定义多尺寸特征,论文的目标是找到变化函数来高效融合不同的特征,输出新特征。具体地,图2a展示了top-down FPN网络结构,一般FPN只有一层,这里应该为了对比写了repeat形式。FPN获取3-7层的输入,代表一个分辨率为的特征层
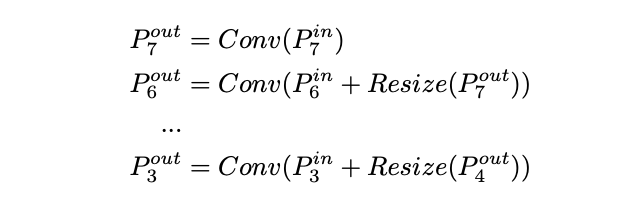
top-down FPN操作如上所示,为上采用或下采样来对齐分辨率,通常是特征处理的卷积操作
Cross-Scale Connections
top-down FPN受限于单向的信息流,为了解决这一问题,PANet(图2b)增加了额外的bottom-up路径的融合网络,NAS_FPN(图2c)使用神经架构搜索来获取更好的跨尺度特征网络的拓扑结构,但需要大量资源进行搜索。其中准确率最高的是PANet,但是其需要太多的参数和计算量,为了提高性能,论文对跨尺寸连接做了几点改进:
去除所有单输入的节点,原因很简单,如果节点只有单输入而不包含特征融合,对特征融合的贡献是不够,这样也算得出一个简化的PANet,如图2e 将同层的输入直接连接到输出节点,融合更多的节点而不带来过多的消耗,得出图2f结构 不像PANet只包含一个top-down和bottom-up路径,论文将此结构作为层,并且重复多次从而融合出更高维度的特征,后面会细讲
Weighted Feature Fusion
大多的特征融合方法都将输入特征平等对待,而论文观察到不同分辨率的输入对融合输出的特征的贡献应该是不同的。为了解决这一问题,论文提出在融合时对输入特征添加额外的权重预测,主要有以下方法:
Unbounded fusion
,是可学习的权重,可以是标量(per-feature),也可以是向量(per-channel),或者是多维tensor(per-pixel)。论文发现标量形式已经足够提高准确率,且不增加计算量,但是由于标量是无限制的,容易造成训练不稳定,因此,要对其进行归一化限制
Softmax-based fusion
,利用softmax来归一化所有的权重,但softmax操作会导致GPU性能的下降,后面会详细说明
Fast normalized fusion
,Relu保证,保证数值稳定。这样,归一化的权重也落在,由于没有softmax操作,效率更高,大约加速30%
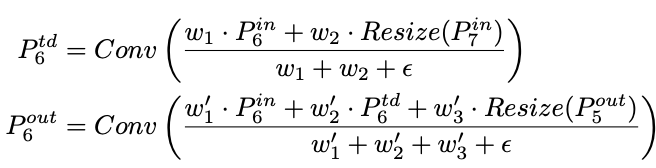
BiFPN集合了双向跨尺寸的连接和快速归一化融合,level 6的融合操作如上,为top-down路径的中间特征,是bottom-up路径的输出特征,其它层的特征也是类似的构造方法。为了进一步提高效率,论文特征融合时采用depthwise spearable convolution,并在每个卷积后面添加batch normalization和activation
EfficientDet
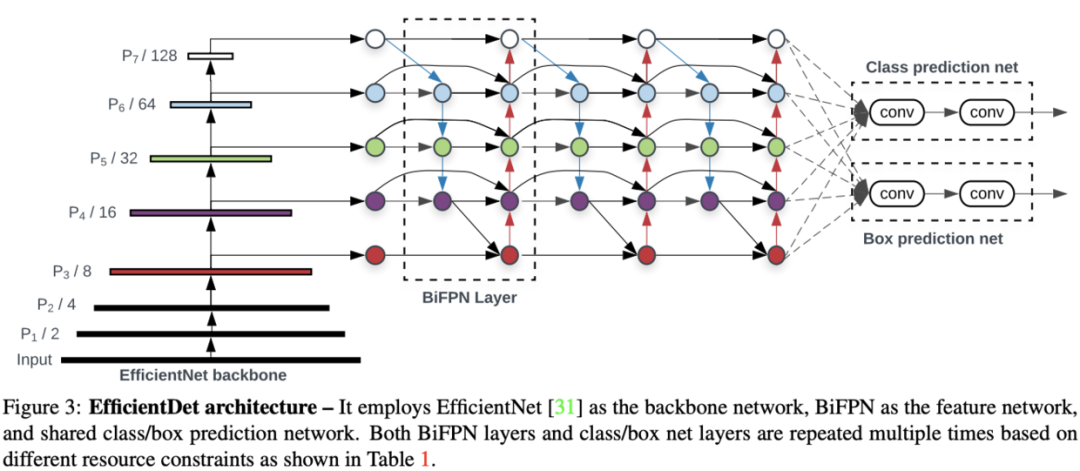
EfficientDet Architecture
EfficientDet的结构如图3所示,基于one-stage检测器的范式,将ImageNet-pretrained的EfficientNet作为主干,BiFPN将主干的3-7层特征作为输入,然后重复进行top-down和bottom-up的双向特征融合,所有层共享class和box网络
Compound Scaling
之前检测算法的缩放都是针对单一维度的,从EfficientNet得到启发,论文提出检测网络的新混合缩放方法,该方法使用混合因子来同时缩放主干网络的宽度和深度、BiFPN网络、class/box网络和分辨率。由于缩放的维度过多,EfficientNet使用的网格搜索效率太慢,论文改用heuristic-based的缩放方法来同时缩放网络的所有维度
Backbone network
EfficientDet重复使用EfficientNet的宽度和深度因子,EfficinetNet-B0至EfficientNet-B6
BiFPN network
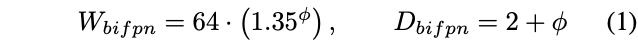
论文以指数形式来缩放BiFPN宽度(#channels),而以线性形式增加深度(#layers),因为深度需要限制在较小的数字
Box/class prediction network
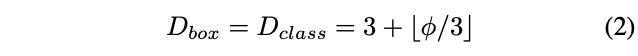
box/class预测网络的宽度固定与BiFPN的宽度一致,而用公式2线性增加深度(#layers)
Input image resolution
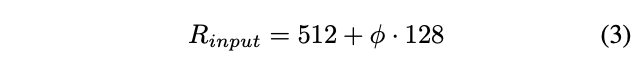
因为BiFPN使用3-7层的特征,因此输入图片的分辨率必需能被整除,所以使用公式3线性增加分辨率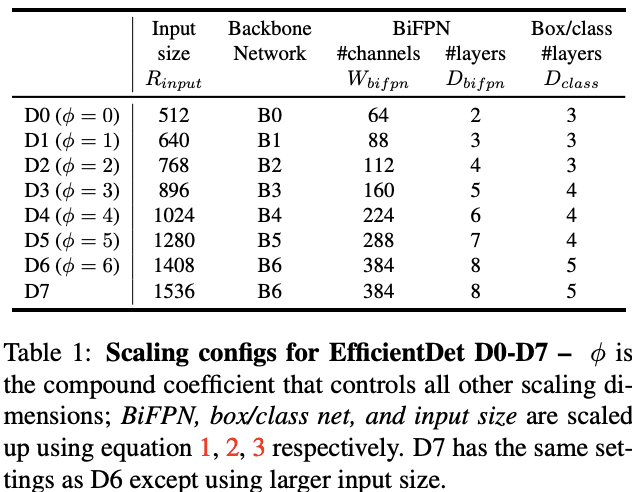
结合公式1-3和不同的,论文提出EfficientDet-D0到EfficientDet-D6,具体参数如Table 1,EfficientDet-D7没有使用,而是在D6的基础上增大输入分辨率
Experiments
模型训练使用momentum=0.9和weight decay=4e-5的SGD优化器,在初始的5%warm up阶段,学习率线性从0增加到0.008,之后使用余弦衰减规律(cosine decay rule)下降,每个卷积后面都添加Batch normalization,batch norm decay=0.997,epsilon=1e-4,梯度使用指数滑动平均,decay=0.9998,采用和的focal loss,bbox的长宽比为,32块GPU,batch size=128,D0-D4采用RetinaNet的预处理方法,D5-D7采用NAS-FPN的增强方法
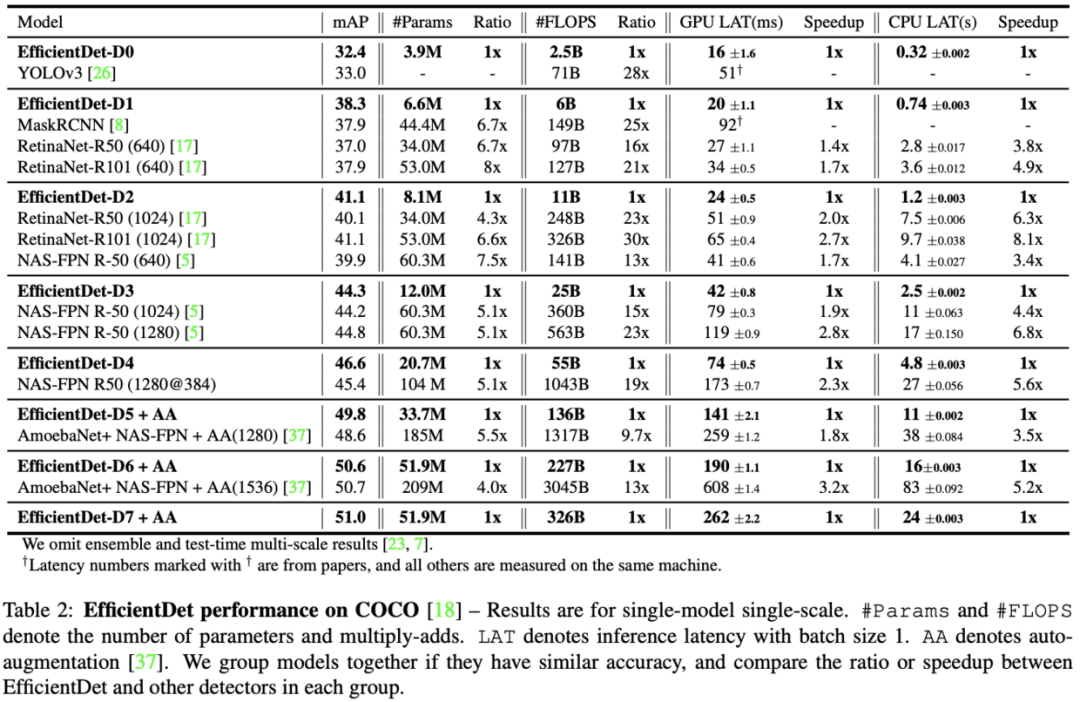
Table 2展示了EfficientDet与其它算法的对比结果,EfficientDet准确率更高且性能更好。在低准确率区域,Efficient-D0跟YOLOv3的相同准确率但是只用了1/28的计算量。而与RetianaNet和Mask-RCNN对比,相同的准确率只使用了1/8参数和1/25的计算量。在高准确率区域,EfficientDet-D7达到了51.0mAP,比NAS-FPN少使用4x参数量和9.3x计算量,而anchor也仅使用3x3,非9x9
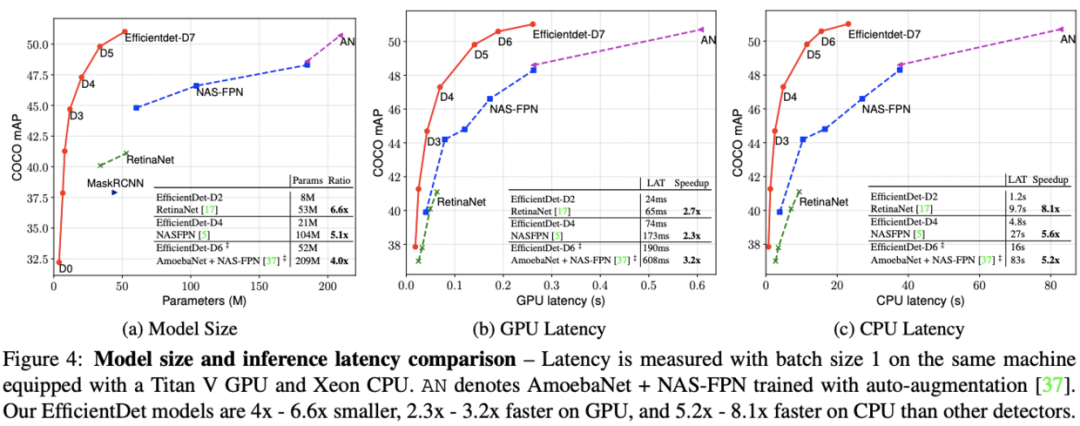
论文在实际的机器上对模型的推理速度进行了对比,结果如图4所示,EfficientDet在GPU和CPU上分别有3.2x和8.1x加速
Ablation Study
Disentangling Backbone and BiFPN

论文对主干网络和BiFPN的具体贡献进行了实验对比,结果表明主干网络和BiFPN都是很重要的。这里要注意的是,第一个模型应该是RetinaNet-R50(640),第二和第三个模型应该是896输入,所以准确率的提升有一部分是这个原因。另外使用BiFPN后模型精简了很多,主要得益于channel的降低,FPN的channel都是256和512的,而BiFPN只使用160维,这里应该没有repeat
BiFPN Cross-Scale Connections
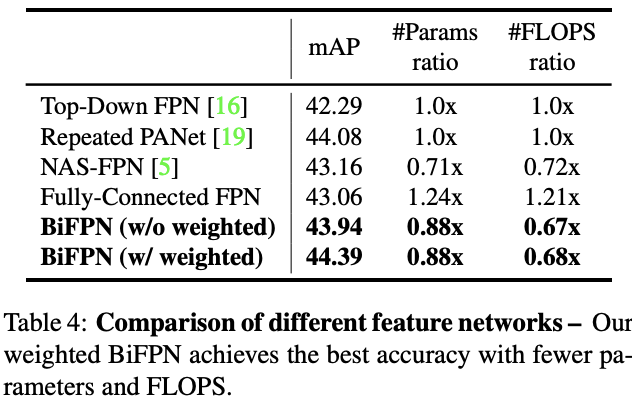
Table 4展示了Figure 2中同一网络使用不同跨尺寸连接的准确率和复杂度,BiFPN在准确率和复杂度上都是相当不错的
Softmax vs Fast Normalized Fusion

Table 5展示了不同model size下两种加权方法的对比,在精度损失不大的情况下,论文提出的fast normalized fusion能提升26%-31%的速度
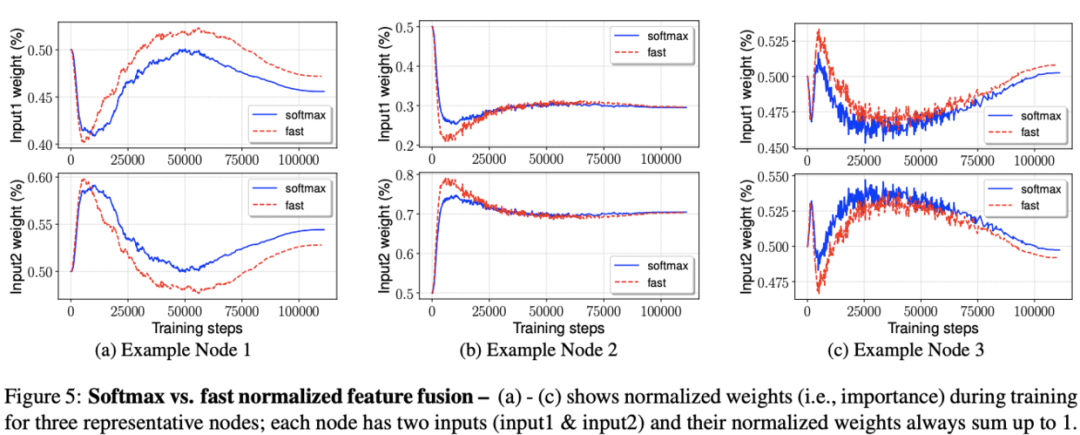
figure 5展示了两种方法在训练时的权重变化过程,fast normalizaed fusion的变化过程与softmax方法十分相似。另外,可以看到权重的变化十分快速,这证明不同的特征的确贡献是不同的,
Compound Scaling
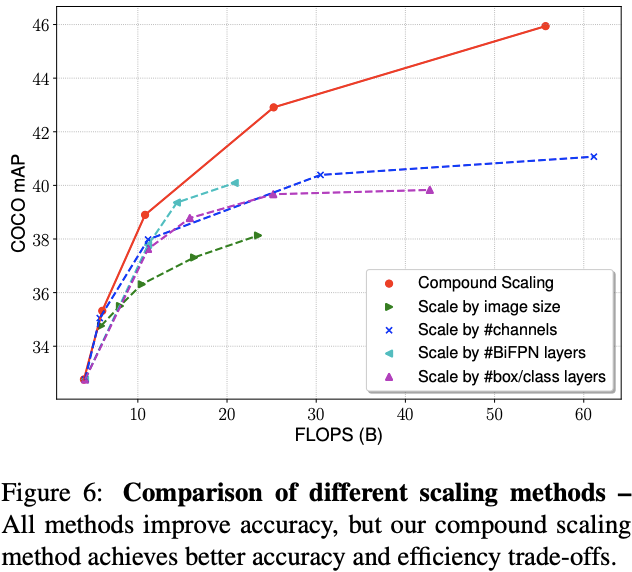
论文对比了混合缩放方法与其它方法,尽管开始的时候相差不多,但是随着模型的增大,混合精度的作用越来越明显
CONCLUSION
论文提出BiFPN这一轻量级的跨尺寸FPN以及定制的检测版混合缩放方法,基于这些优化,推出了EfficientDet系列算法,既保持高精度也保持了高性能,EfficientDet-D7达到了SOTA。整体而言,论文的idea基于之前的EfficientNet,创新点可能没有之前那么惊艳,但是从实验来看,论文推出的新检测框架十分实用,期待作者的开源
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
