
YOLOv6:又快又准的目标检测框架开源啦

1. 概述
精度与速度远超 YOLOv5 和 YOLOX 的新框架
2. YOLOv6关键技术介绍
2.1 Hardware-friendly 的骨干网络设计
2.2 更简洁高效的 Decoupled Head
2.3 更有效的训练策略
3. 实验结果
4. 总结与展望
1. 概述
精度与速度远超 YOLOv5 和 YOLOX 的新框架
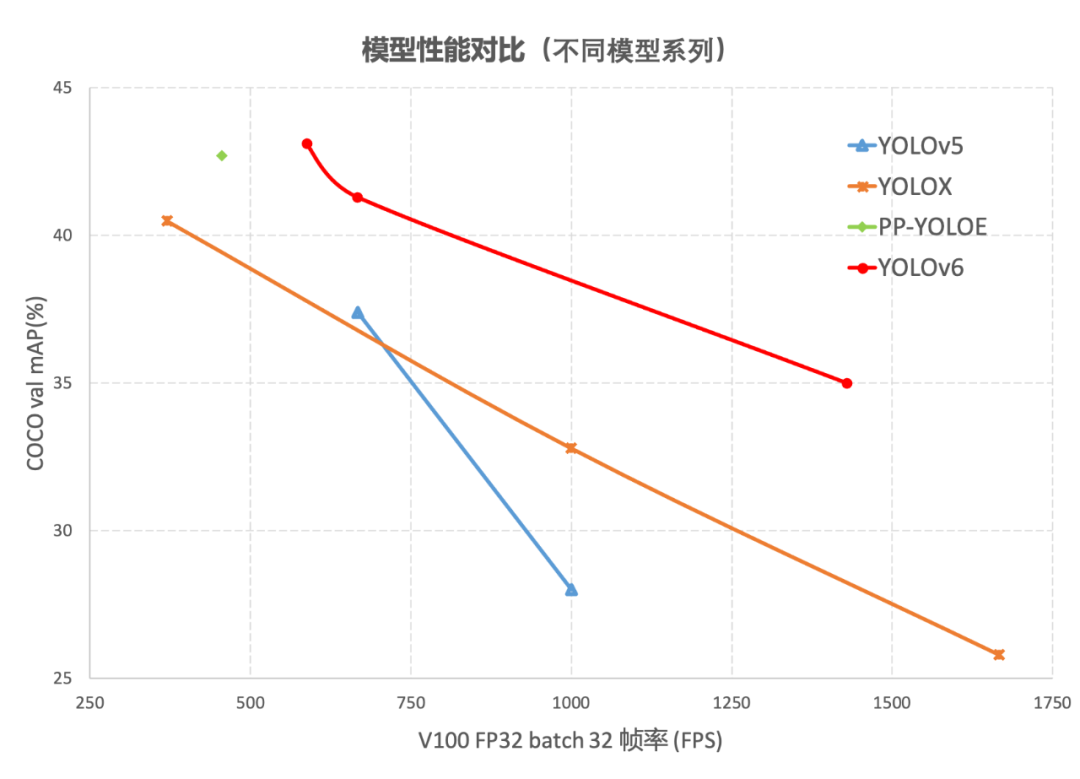
图1-1 YOLOv6 各尺寸模型与其他模型性能对比
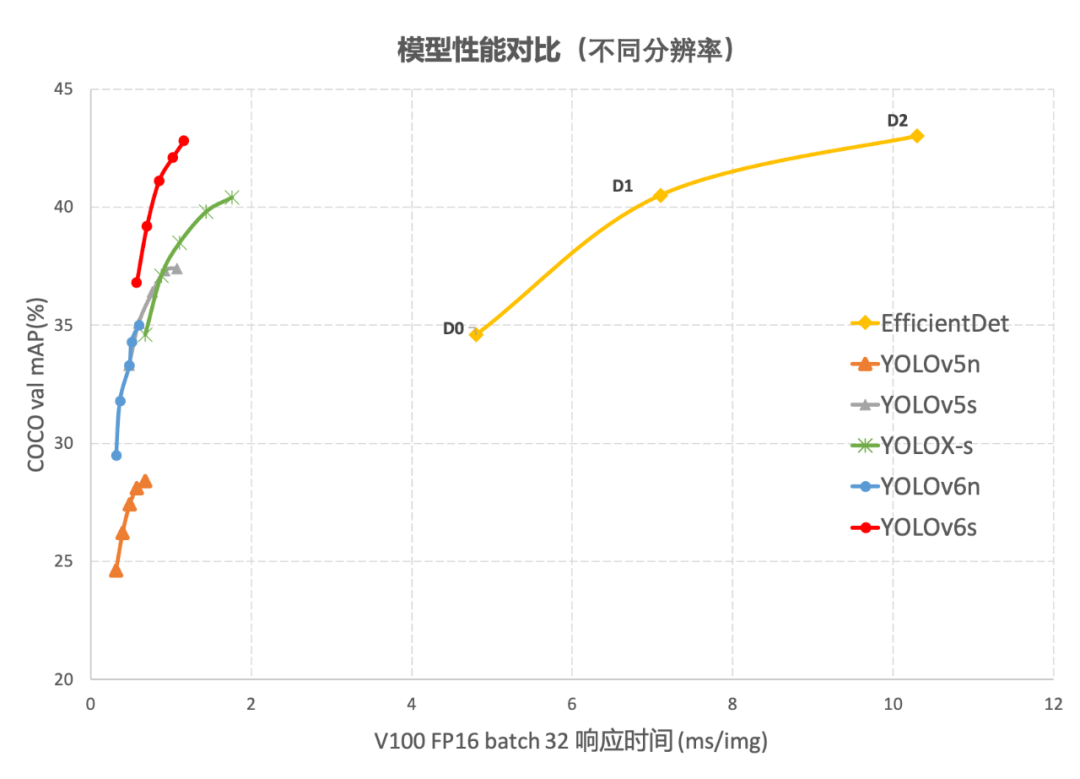
2. YOLOv6关键技术介绍
我们统一设计了更高效的 Backbone 和 Neck :受到硬件感知神经网络设计思想的启发,基于 RepVGG style[4] 设计了可重参数化、更高效的骨干网络 EfficientRep Backbone 和 Rep-PAN Neck。 优化设计了更简洁有效的 Efficient Decoupled Head,在维持精度的同时,进一步降低了一般解耦头带来的额外延时开销。 在训练策略上,我们采用Anchor-free 无锚范式,同时辅以 SimOTA[2] 标签分配策略以及 SIoU[9] 边界框回归损失来进一步提高检测精度。
2.1 Hardware-friendly 的骨干网络设计
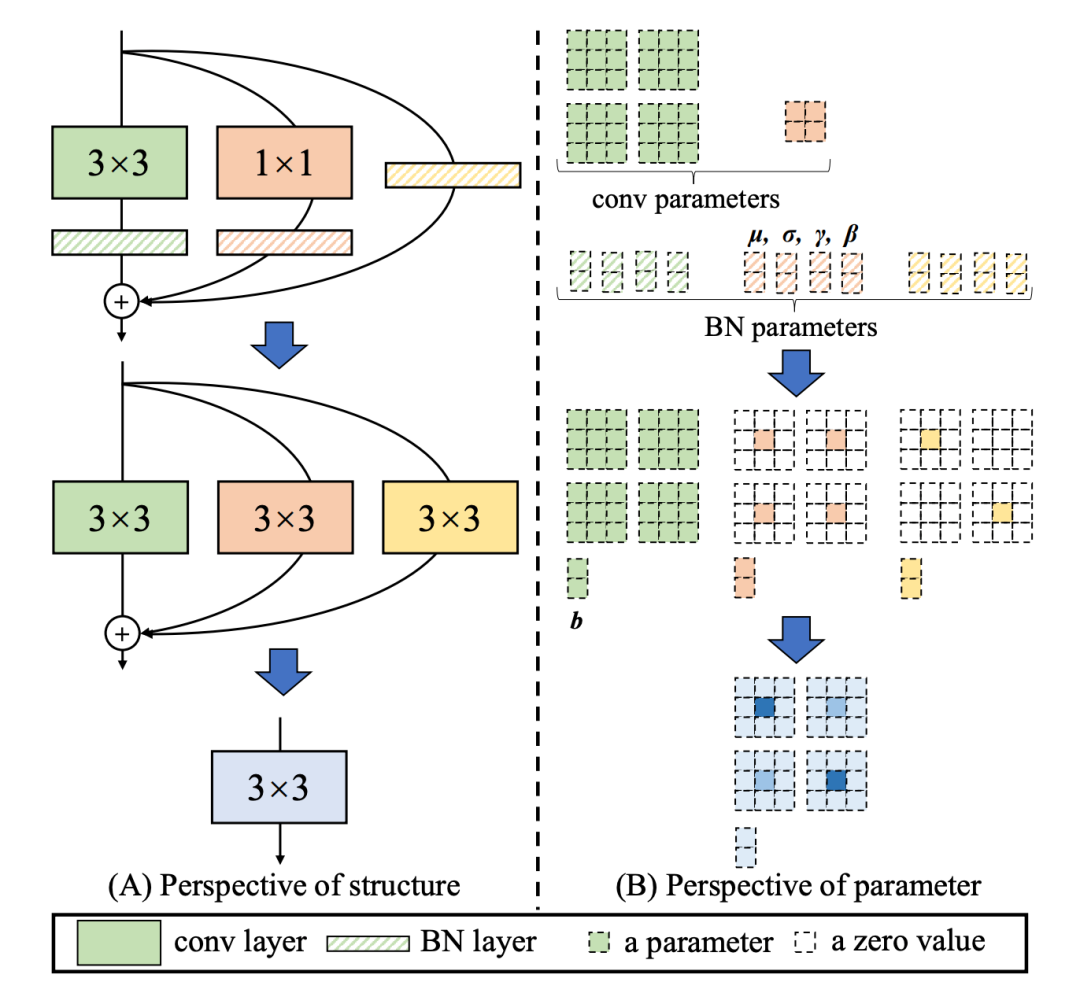
引入了 RepVGG[4] style 结构。 基于硬件感知思想重新设计了 Backbone 和 Neck。
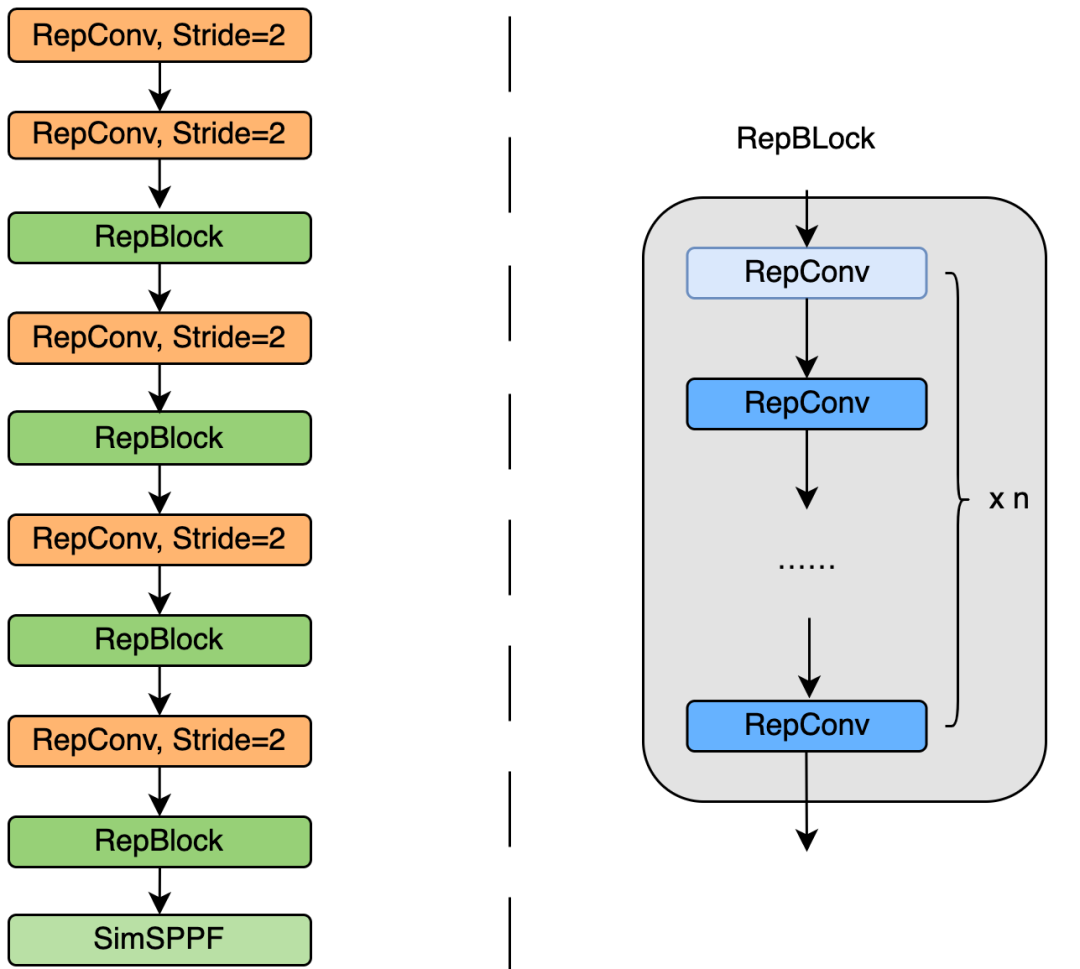
2.2 更简洁高效的 Decoupled Head
2.3 更有效的训练策略
3. 实验结果

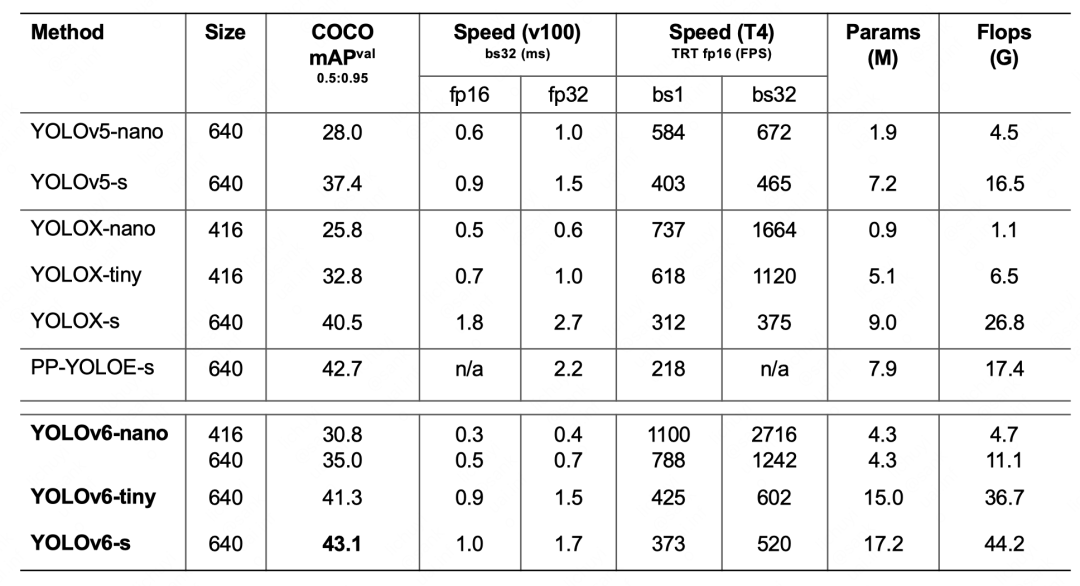
YOLOv6-nano 在 COCO val 上 取得了 35.0% AP 的精度,同时在 T4 上使用 TRT FP16 batchsize=32 进行推理,可达到 1242FPS 的性能,相较于 YOLOv5-nano 精度提升 7% AP,速度提升 85%。 YOLOv6-tiny 在 COCO val 上 取得了 41.3% AP 的精度, 同时在 T4 上使用 TRT FP16 batchsize=32 进行推理,可达到 602FPS 的性能,相较于 YOLOv5-s 精度提升 3.9% AP,速度提升 29.4%。 YOLOv6-s 在 COCO val 上 取得了 43.1% AP 的精度, 同时在 T4 上使用 TRT FP16 batchsize=32 进行推理,可达到 520FPS 的性能,相较于 YOLOX-s 精度提升 2.6% AP,速度提升 38.6%;相较于 PP-YOLOE-s 精度提升 0.4% AP的条件下,在T4上使用 TRT FP16 进行单 batch 推理,速度提升 71.3%。
4. 总结与展望
完善 YOLOv6 全系列模型,持续提升检测性能。 在多种硬件平台上,设计硬件友好的模型。 支持 ARM 平台部署以及量化蒸馏等全链条适配。 横向拓展和引入关联技术,如半监督、自监督学习等等。 探索 YOLOv6 在更多的未知业务场景上的泛化性能。
5. 参考文献
6. 作者简介
推荐阅读
辅助模块加速收敛,精度大幅提升!移动端实时的NanoDet-Plus来了!
机器学习算法工程师
一个用心的公众号

评论