
【CV】MTCNN:3个CNN,胜过1个诸葛亮
CW,广东深圳人,毕业于中山大学(SYSU)数据科学与计算机学院,毕业后就业于腾讯计算机系统有限公司技术工程与事业群(TEG)从事Devops工作,期间在AI LAB实习过,实操过道路交通元素与医疗病例图像分割、视频实时人脸检测与表情识别、OCR等项目。
目前也有在一些自媒体平台上参与外包项目的研发工作,项目专注于CV领域(传统图像处理与深度学习方向均有)。

前言
MTCNN(Multi-Task Cascaded Convolutional Networks)是2016年提出的,如其名,算法采用了级联CNN的结构实现了多任务学习——人脸检测 和 人脸对齐,最终能够预测出人脸框(bounding box)和关键点(landmarks)的位置。
MTCNN在 FDDB、WIDER FACE 和 AFLW 数据集上均取得了当时(2016年4月)最好的效果,而且速度也快(在当时来说),被广泛用于人脸识别流程中的前端部分。
总地来说,MTCNN的效果主要得益于以下几点:
1. 级联的CNN架构是一个coarse-to-fine(由粗到细)的过程;
2. 在训练过程中使用了在线困难样本挖掘(OHEM,Online Hard Example Mining)的策略;
3. 加入了人脸对齐的联合学习(Joint Face Alignment Learning)
下面,请诸位客官进入MTCNN的世界里进行参观。
MTCNN的“宣传海报”
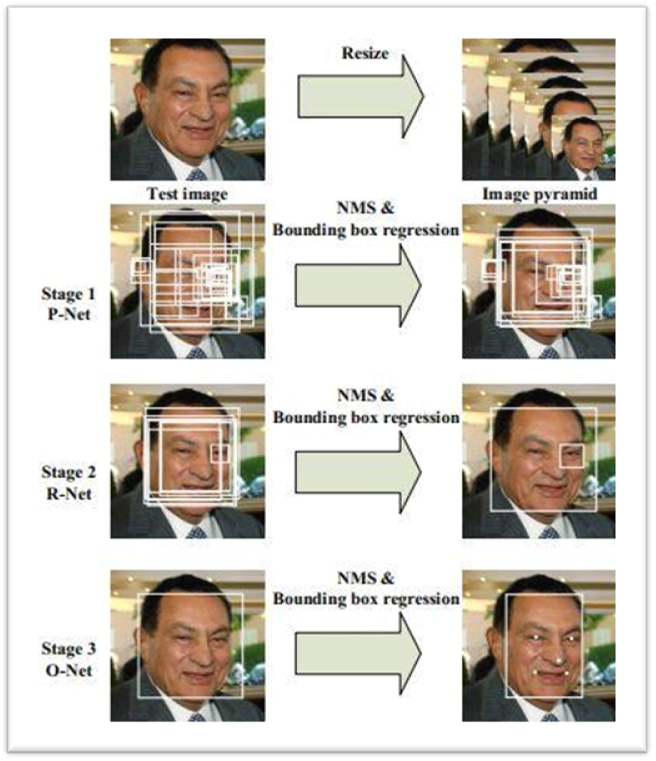
MTCNN由3个网络组成,共同构成级联的CNN架构。这3个网络依次为 P-Net、R-Net 和 O-Net,前者的输出会作为后者的输入。
P-Net(Proposal Network)
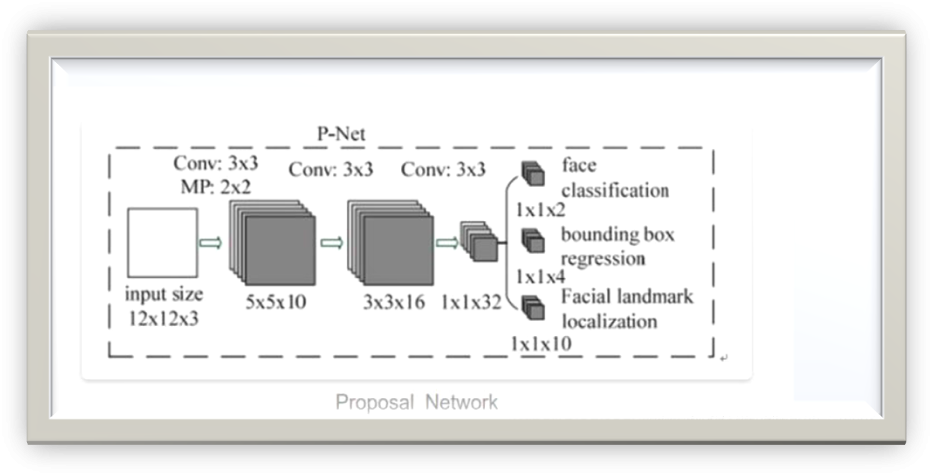 P-Net
P-NetR-Net(Refine Network)
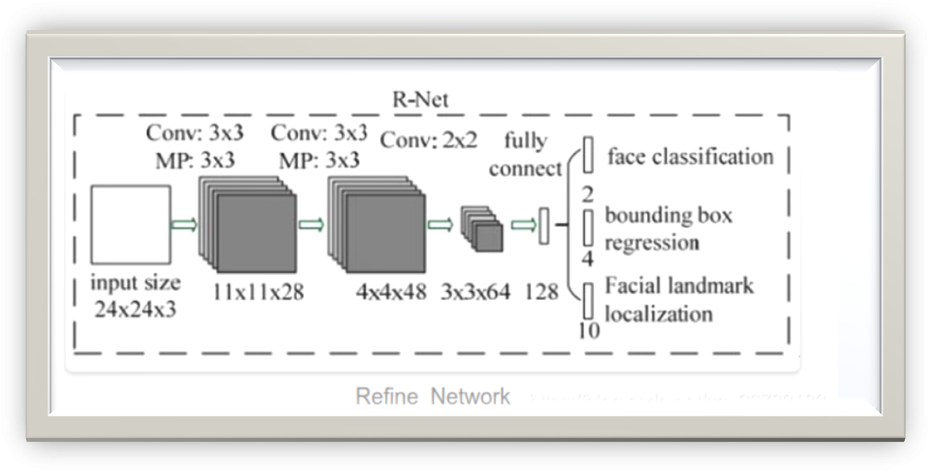 R-Net
R-NetR-Net不再是FCN,最后使用全连接层,相比于P-Net,其输入size和每层的通道数也比较大,可以认为,其拟合的结果会更精确,主要作用是对P-Net的结果进行校正,消除其中的误判(FP,False-Positive)。
O-Net(Output Network)
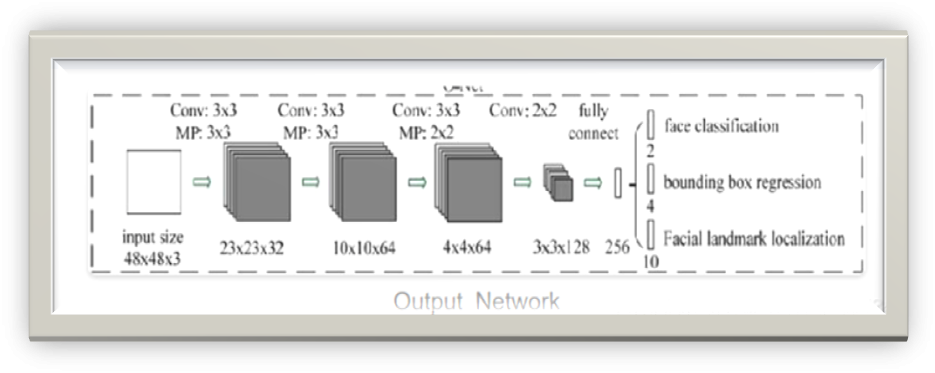 O-Net
O-Net
O-Net的结构与P-Net较为类似,只不过输入size、宽度以及深度都更大,因此可使最终输出结果更加精确。
从上述展示的结构中我们可以feel到,P-Net->R-Net->O-Net 是一个coarse-to-fine的过程。
另外,推理时P-Net和R-Net可以不必输出landmarks分量,因为此时预测的人脸框位置还不准,根据offset计算出对应的landmarks位置没有太大意义,而且也没有必要,最终的输出还是取决于O-Net。
图像金字塔
由上一节展示的P-Net网络架构可知,其是在单尺度(12x12 size)上做训练的,为了检测到不同尺寸的人脸,所以在推理时需要先生成图像金字塔,而P-Net为何设计成FCN的原因也在于此。
首先,设置一个想要检测的最小人脸尺寸min_size,比如20x20,其次,设定一个缩放因子fator,通常为0.707。
然后,将图像的最短边乘以 12 / 20,进行一次缩放,接着不断对前面缩放的尺寸乘以fator进行缩放,比如最短边初始为s,接下来就会缩放得到:s x 12 / 20、s x 12/ 20 x factor、s x 12 / 20 x factor ^2、...,直至s不大于12时停止。
记录下以上缩放过程中(最短边还大于12时)的各个scale:12 / 20、12 / 20 x factor、12 / 20 x factor^2、...,最后依次按照每个scale对图像采用双线性插值的方式进行缩放从而得到图像金字塔。提问时间到!为何缩放因子是0.707?
这个数字不觉得有点眼熟吗?是的,它约等于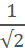 ,那么这又代表什么呢?通常,按照我们凡夫俗子的思维,缩放系数都习惯于取0.5,如果边长都缩放0.5倍的话,那么矩形框面积就缩小了1/4,跨度未免有点大,可能会漏掉许多要检测的人脸。要知道,按照P-Net的意思,每个尺度对应的就是一张人脸。于是我们可以让面积缩放1/2,减小这之间的跨度,相应地,边长的缩放系数就为。
,那么这又代表什么呢?通常,按照我们凡夫俗子的思维,缩放系数都习惯于取0.5,如果边长都缩放0.5倍的话,那么矩形框面积就缩小了1/4,跨度未免有点大,可能会漏掉许多要检测的人脸。要知道,按照P-Net的意思,每个尺度对应的就是一张人脸。于是我们可以让面积缩放1/2,减小这之间的跨度,相应地,边长的缩放系数就为。
十万个为什么系列之第二个灵魂拷问——min_size和factor对推理过程会产生什么样的影响?
由小学数学知识可知,min_size越大、fator越小,图像最短边就越快缩放到接近12,从而生成图像金字塔的耗时就越短,同时各尺度的跨度也更大。因此,加大min_size、减小factor能加速图像金字塔的生成,但同时也更易造成漏检。
好了,不问了,真要问十万个估计我的手要码到残废了..剩下的诸位自行yy。
由上述可知,图像金字塔的缺点就是慢!慢在需要不断resize生成各个尺寸的图像,还慢在这些图像是一张张输入到P-Net中进行检测的(每张的输出结果代表一张人脸候选区域),相当于做了多次推断过程,你说可不可怕..
P-Net获取人脸候选区域
将图像金字塔中每个尺寸的图像依次输入到P-Net,对于每个尺度的图像都会对应输出一个map,输出map的每点都会有分类score和回归的bbox offset。先保留置信度较高的一批位置点,然后将每点还原出对应的人脸区域,接着用NMS剔除重复的区域,得到所有尺寸图像保留下来的结果后,再用一次NMS进行去重(CW做过实验,不同scale下输出的图像之间NMS没有效果,说明不同scale下没有重复的,也符合不同scale检测不同尺寸人脸的意思),最后使用回归得到的offset对人脸候选区域进行校正得到bbox位置。十万个为什么系列再次上线——如何还原出输出map每点对应的人脸区域?
根据P-Net的结构设计可知,输出feature map的一点实际对应的是输入中12x12的区域,而P-Net中有一个池化层进行了2倍的下采样(对卷积层带来的尺寸损失不计),于是对于输出feature map的一点(x, y),我们可以这么做来进行还原:
i). 先还原出其在输入图像的位置:(x*2, y*2);
ii). 将其作为人脸区域的左上角,对应地,右下角为:(x*2 + 12, y*2 + 12);
iii). 由于在生成图像金字塔时进行了缩放,因此还要除以当时缩放的scale:(x1 = x*2 / scale, y1 = y*2 / scale)、(x2 = (x*2 + 12) / scale, y2 = (y*2 + 12) / scale)
以上(x1, y1, x2, y2)便是还原出来在原图上对应的人脸区域。
你们应该还没有吃饱,继续问——如何用回归得到的offset计算出人脸bbox位置?
x1_true = x1 + tx1*w
y1_true = y1 + ty1*h
x2_true = x2 + tx2*w
y2_true = y2 + ty2*h
使用以上公式就能计算得到结果,其中x*_true和y*_true代表人脸bbox的位置,tx*、ty*代表回归得到的offset,w和h就是人脸区域(x1, y1, x2, y2)的宽和高。
至于为什么能这么计算,这是由训练前制作label的时候决定的,在下一节讲训练过程时会说明,这里先hold着。
P-Net输出的bbox不够精准,仅作为包含人脸的候选区域,接下来交由R-Net进行校正。
R-Net基于P-Net的结果进一步校正
R-Net并不是直接将P-Net的输出结果拿来用,他还是个细心boy,先对这些输出“做了一番洗剪吹”,成为这条街上最靓的仔后再拿来用,处理过程如下:
i). 为了尽可能涵盖到人脸,将P-Net输出的候选区域都按其各自的长边resize方形;
ii). 检查这些区域的坐标是否在原图范围内,在原图内的像素值设置为原图对应位置的像素值,其它则置为0;
iii). 将以上处理得到的图片区域使用双线性插值resize到24x24大小
处理完后,所有输入都是24x24大小,网络输出的后处理与P-Net类似,先筛选置信度较高的一批结果,然后用NMS剔除重复的,最后使用offset计算出bbox位置。此处使用offset计算时用到的(x1,y1,x2,y2)就是P-Net输出的bbox。
又要问了——为何不直接对原图有效范围内的区域进行resize?
可以这么想,如果有效范围内的区域刚好正是人脸区域,丝毫不差,那么resize后必定会有像素损失,从而丢失细节。
O-Net检测出人脸和关键点位置
看到R-Net是个细心boy,O-Net当然也是很自觉地对R-Net的输出结果做了处理,处理方式与R-Net类似,只不过最终resize到的大小是48x48。
由于O-Net会输出landmarks的offset,因此还需要计算出landmarks的位置:
x_true = x_box + tx*w
y_true = y_box + ty*h
(x_true, y_true)代表一个关键点的位置,tx、ty代表对应的offset,(x_box, y_box)代表R-Net输出bbox的左上角位置,w、h代表bbox的宽、高。至于bbox位置的计算、后处理等这些也都和之前的类似,这里不再阐述了。
哦,另外,在此处NMS计算IoU时,分母可以不取并集,而是取当前置信度最高的bbox和其余bbox面积的较小者,这样分母会变大,从而导致IoU计算结果偏高,相当于变向降低NMS阀值,对重复检测的要求更为苛刻。
数据样本分类
MTCNN是集成了人脸检测和人脸对齐的多任务架构,通常使用两个数据集来训练,其中一个训练人脸检测,另一个训练人脸对齐(这部分其实也能训练人脸检测)。在处理训练数据时,会对图像进行随机裁剪,具体方法后文会讲解,这里再埋个坑。可以将训练样本分为4类:
i). Positive:裁剪后图片与人脸标注框 IoU >= 0.65,类别标签为1;
ii). Part:裁剪后图片与人脸标注框 IoU [0.4, 0.65),类别标签为-1;
[0.4, 0.65),类别标签为-1;
iii). Negative:裁剪后图片与人脸标注框 IoU < 0.3,类别标签为0;
iv). Landmarks:来自训练人脸对齐的数据集,类别标签为-2
使用Positive和Negative样本计算分类损失,使用Positive和Part样本计算bbox回归损失,而仅使用Landmarks样本计算landmarks回归损失。
十万个为什么时间到——为何只使用Postive和Negative计算分类损失?
应该是考虑到这些正负样本与标注框的IoU差别明显,区分度大,使模型更易收敛。
标签制作
填坑时间到!之前埋下的2个坑会在这里填上,打起精神咯!
P-Net、R-Net和O-Net的标签处理过程有些许差别,下面依次介绍。
P-Net
负样本Negative
1. 对图像进行随机裁剪,裁剪后为方形,边长s=(12, min(H, W) ),H、W分别为图像的高和宽。将图像左上角向右下方进行移动,移动后横、纵坐标分别为
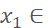 (0, W - s)、
(0, W - s)、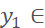 (0, H - s),于是裁剪后图像右下角坐标为(x2=x1 + s, y2=y1 + s)。
(0, H - s),于是裁剪后图像右下角坐标为(x2=x1 + s, y2=y1 + s)。
2. 计算裁剪后图像与原图中所有标注框的IoU,若最大IoU<0.3,则将这张裁剪后的图像作为负样本Negative,resize至12x12大小,对应的类别标签记为0,保存下来待训练时用。
3. 重复1、2直至生成了50个负样本图像。
4. 对图像中的每个标注框重复5次随机裁剪,也是用于生成负样本。裁剪后边长s与1中的相同,移动bbox的左上角(x1, y1),移动后(nx1=x1 + delta_x, ny1=y1 + delta_y),其中delta_x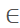 [max(-s, -x1), w),delta_y
[max(-s, -x1), w),delta_y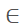 [max(-s, -y1), h),也就是对标注框左上角随机进行上下左右移动,w、h分别bbox的宽和高。对应地,bbox右下角坐标变为(nx2=nx1 + s, ny2=ny1 + s)。若右下角坐标超出原图范围,则舍弃该裁剪图片,进行下一次裁剪。
[max(-s, -y1), h),也就是对标注框左上角随机进行上下左右移动,w、h分别bbox的宽和高。对应地,bbox右下角坐标变为(nx2=nx1 + s, ny2=ny1 + s)。若右下角坐标超出原图范围,则舍弃该裁剪图片,进行下一次裁剪。
正样本Positive和Part
5. 紧接着4,在一个标注框随机裁剪5次后,再重复随机裁剪20次,用于生成正样本Postive和Part。裁剪后图像边长s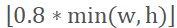
 即bbox短边的0.8倍至长边的1.25倍。对bbox的中心点随机进行左右上下移动,移动范围delta_
即bbox短边的0.8倍至长边的1.25倍。对bbox的中心点随机进行左右上下移动,移动范围delta_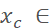 [-0.2w, 0.2w),delta_
[-0.2w, 0.2w),delta_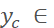 [-0.2h, 0.2h),于是移动后中心点坐标为
[-0.2h, 0.2h),于是移动后中心点坐标为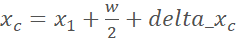 ,
, 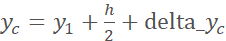 相应地,左上角和右下角坐标为
相应地,左上角和右下角坐标为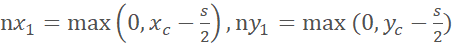 ,
,
(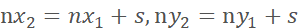 )若右下角坐标超出原图范围,则舍弃此次裁剪的结果,继续执行下一次随机裁剪。
)若右下角坐标超出原图范围,则舍弃此次裁剪的结果,继续执行下一次随机裁剪。
6. 若裁剪后图像与该bbox的IoU>=0.65,则作为正样本Positive,resize到12x12大小,类别标签记为1;否则若IoU>=0.4,则作为Part,同样也resize成12x12,类别标签记为-1;
7. 对于Postive和Part样本,计算bbox左上角和右下角的offset标签: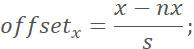
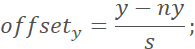
其中,(x, y)为标注框左上角/右下角的横、纵坐标,(nx, ny)为裁剪图片的左上角/右下角坐标,s为其边长。也就是标注框两个角相对于裁剪图片对应两角的归一化位移。最后将Postive和Part样本对应的裁剪图像、类别标签、offset标签保存下来待训练时用。
关键点样本Landmarks
8. Landmarks样本在另一个数据集中单独处理,每张图片是一个单独的人脸,对每张图重复10次随机裁剪,裁剪方式与生成Positive和Part样本时相同,若裁剪后图像右下角坐标不在原图范围内,或者裁剪后图像与标注框IoU<0.65,则舍弃此次裁剪结果,进行下一次随机裁剪。
9. 计算bbox和landmarks的offset标签,其中bbox的计算方式与Postive以及Part的相同,这里不再阐述,而landmarks的如下:
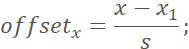
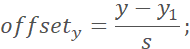
其中,(x, y)为标注的关键点坐标,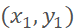 为裁剪后图像的左上角坐标,s为裁剪后图像的边长,即标注的关键点相对于裁剪图像左上角的归一化位移。
为裁剪后图像的左上角坐标,s为裁剪后图像的边长,即标注的关键点相对于裁剪图像左上角的归一化位移。
R-Net
在R-Net的标签制作前需要使用训练好的P-Net的数据集进行检测,后续的数据处理过程与P-Net类似,下面进行介绍。
1. 使用训练好的P-Net对数据集的图片进行检测,将原图、标注框以及检测出的bbox位置对应保存下来。
2. 将原图、标注以及图中检测出的bbox依次取出,对每个bbox依次处理,若尺寸小于20(min_size,代表想要检测的最小人脸size)或者 坐标不在原图范围内,则舍弃该检测出的bbox,继续处理下一个bbox;否则,将bbox对应的区域从原图中裁出并resize到24x24备用。
负样本Negative
3. 计算bbox与所有标注框的IoU,若最大IoU<0.3且当前生成的负样本数量小于60个,则将裁剪出的图像作为负样本,类别标签记为0,保存下来待训练时用。
正样本Positive和Part
4. 否则,若最大IoU>=0.65或0.4<=最大IoU<0.65,则对应地将裁剪出的图像记为正样本Positive或Part,类别标签记为1或-1。同时,取出最大IoU对应的标注框,用于计算offset,计算方式与P-Net中提到的相同,最后将裁剪出的图像、类别标签、offset标签保存好待训练时使用。
O-Net
在制作O-Net的数据标签前需要依次使用训练好的P-Net和R-Net对数据集做检测,然后将R-Net预测的bbox和对应的原图以及标注保存下来供O-Net使用。
标签制作过程和R-Net的几乎相同,只不过没有最小负样本数量的限制(P-Net有50个、R-Net有60个)。另外,若landmarks数据集的标注框最长边小于40或坐标不在原图范围内,则舍弃这个样本。
Loss函数
loss由三部分组成:分类损失、bbox回归损失、landmarks回归损失。
每个网络的loss都由这3种loss加权而成,其中分类损失使用交叉熵损失,回归损失均使用L2距离损失。
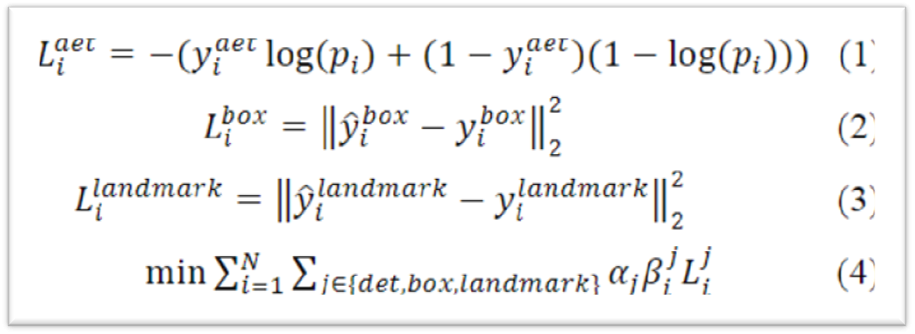 上式中,j代表不同的任务(分类、bbox回归、landmarks回归),
上式中,j代表不同的任务(分类、bbox回归、landmarks回归), 即不同任务对应的loss权重,对于P-Net和R-Net,它们的分类loss、bbox回归loss、landmarks回归loss的权重比为1:0.5:0.5,而O-Net中为1:0.5:1。
即不同任务对应的loss权重,对于P-Net和R-Net,它们的分类loss、bbox回归loss、landmarks回归loss的权重比为1:0.5:0.5,而O-Net中为1:0.5:1。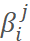 是第i个样本在任务j中是否需要贡献loss,需要则为1,否则为0。例如,对于Negative样本,它在回归任务中这个β值就为0。
是第i个样本在任务j中是否需要贡献loss,需要则为1,否则为0。例如,对于Negative样本,它在回归任务中这个β值就为0。
OHEM(Online Hard Example Mining)
在线困难样本挖掘的策略仅在计算分类loss时使用。直白来说,就是挑选损失最大的前70%作为困难样本,在反向传播时仅使用这70%困难样本产生的损失。作者在paper中的实验表明,这样做在FDDB数据集上能带来1.5个点的性能提升。
首先,对待检测图片生成图像金字塔,输入P-Net,得到输出,通过分类置信度和NMS筛选出人脸候选区域;
然后,基于这些候选区域去原图crop出对应的图像,输入R-Net,得到输出后同样是使用分类置信度和NMS,过滤掉false-positive,得到更精准的一批候选;
最后,基于得到的这批候选去原图crop出对应的图像,输入O-Net,输出最终预测的bbox和landmark位置。
往期精彩回顾
本站qq群704220115,加入微信群请扫码: