CV(计算机视觉)领域一直是引领机器学习的弄潮儿。近年来更是因为Transformers模型的横空出世而掀起了一阵腥风血雨。小编今天就带大家初步认识一下这位初来乍到的CV当红炸子鸡~本文主要介绍Transformers背后的技术思想,Transformers在计算机视觉领域的应用情况、最新动态以及该架构相对于CNN的优势。- 为什么Transformers模型在NLP自然语言处理任务中能够力压群雄,变成SOTA模型的必备组件之一。
- 为什么说Transformers是对CNN的当头棒喝,Transformers是怎么针对CNN的各种局限性进行补全的。
- 计算机视觉领域的最新模型是如何应用Transformers提升自己的。
长期依赖和计算效率之间的权衡取舍
在自然语言处理领域中,一个重要的技术基础就是创建合理的Embedding。Embedding是NLP系统的根基,一个好的Embedding需要能够将原始文本中尽可能多的语义片段进行有效编码。这些语义信息其实并不只是代表一个词的定义跟含义,很多时候是需要结合上下文进行联系的。比如当我们孤零零的得到一个词“快”的时候,我们不知道它是指Fast还是Almost,基于这样没有上下文的孤零零的单词的Embedding,很多时候是盲目并且没有意义的。又比如说这句话:“Transformers特别牛,因为它在很多项目中都能大幅提高模型的性能”。读了这句话,我们知道文中的“它”是指Transformers,但是如果没有这一整句话的承载,而是孤零零的给你一个词“它”,估计谁都不晓得这个家伙指代的是谁,那如此Embedding出来的结果也将毫无意义。一个好的机器学习模型应该能够准确表达单词之间的依赖关系,不论是在超大型的文本中,还是在比较简短的文字片段中都是如此。这就像是一个伏笔,作者在第一章中埋下了一个伏笔,隔了四五十页之后再次提及起它的时候,读者会觉得这是神来之笔,因为能够联系起它和当前文字之间的关系。机器学习模型也应该具备这种记忆能力,以及超远文字之间的记录和依赖表达能力。或者换句话说,好的模型应该具有“长期依赖性的编码能力”。在详细介绍Transformers之前,我们先来梳理一下NLP领域在Transformers技术诞生之前所面临的问题,尤其是在挖掘数据之间的长期依赖性时所面临的问题。在NLP领域中,以LSTMs和GRU为代表的循环神经网络曾经风光无限,它们的结构内部有极其巧妙的长期状态输入和输出,能够让模型从文本中提取丰富的上下文语义。它们的工作方式都是串行的,一次处理一个单词或者输入单元,并且设计了记忆结构来存储已经看到的内容的抽象特征,这些长时的抽象信息能够在之后的数据处理中帮助模型理解当前输入,或者处理长期的数据依赖,从而将前文中的语义信息添加到当前的结果输出之中。RNN结构能够将前文的信息写入到记忆模块之中,是因为它们内部有各种门结构。其中输入门能够让神经网络有选择性的记录一些长时的有效信息,遗忘门会有针对性地抛弃一些无关的冗余信息,更新门还可以让网络对自身当前的状态根据输入进行实时更新。相对于普通RNNs来说,加入了各种门结构的LSTM和GRU更受世人的喜爱,这是因为它们能够解决梯度爆炸和梯度消失的问题,模型的鲁棒性得到了明显提升。梯度爆炸和梯度消失是长久以来困扰RNNs的一大问题。LSTM和GRU能够利用自身模型结构给梯度“续命”,有效追踪序列数据中相当长时间数据之间的依赖关系。但是我们还是发现,这种序列式的网络,以及将有效信息存储到各个零散的神经元的方式,并不能有效地保存那些超长的数据依赖。此外,序列式的网络结构也难以让LSTM和GRU网络有效地进行扩展和并行化计算。因为每一个前向的传递都是依赖于前一个时间步的处理结果,每得到一个输入,模型只能给出一步的输出。也就是每一步的计算都只能顾及当前输出,得到一个Embedding结果。卷积神经网络也是 NLP 系统中的常客,尤其是对于那些使用 GPUs 训练的模型任务来说更是如此。这是因为 CNNs 和 GPU 的组合能够天然耦合两者在计算伸缩性和高效性上的特点,所以二者逐渐成为形影不离的好基友。CNNs 常被用在图像特征提取上,与此类似,在 NLP领域中,网络也会利用 CNNs 的一维滤波器从文本中提取有效信息,此时的文本就对应地以一维时间序列的形式进行表示了。所以图像处理中使用2D CNN , NLP 中就使用1D CNN ~CNN的感受野(就是CNN能够看到的局部信息大小)是由卷积核/滤波器的尺寸,以及滤波器的通道数所决定的。增加卷积核的尺寸或者滤波器的通道数会增加模型的大小,也会让模型的复杂度大幅增加。这也许会导致梯度消失的问题,从而引发让整个网络无法训练收敛的严重后果。为解决这个问题,残差连接 Residual connections 和空洞卷积 Dilated Convolutions 应运而生。它们能够在一定程度上增强梯度的传播深度,从而在一定程度上扩大模型的感受野(后面的层就能看到更多的局部信息了嘛)。但是,卷积神经网络毕竟只是关注局部信息的网络结构,它的这种计算机制导致了它在文本信息处理上难以捕捉和存储长距离的依赖信息。人们一方面想扩大卷积核、增加通道数来捕捉长期依赖,一方面还害怕由于扩大模型所导致的维度灾难。Transformers横空出世
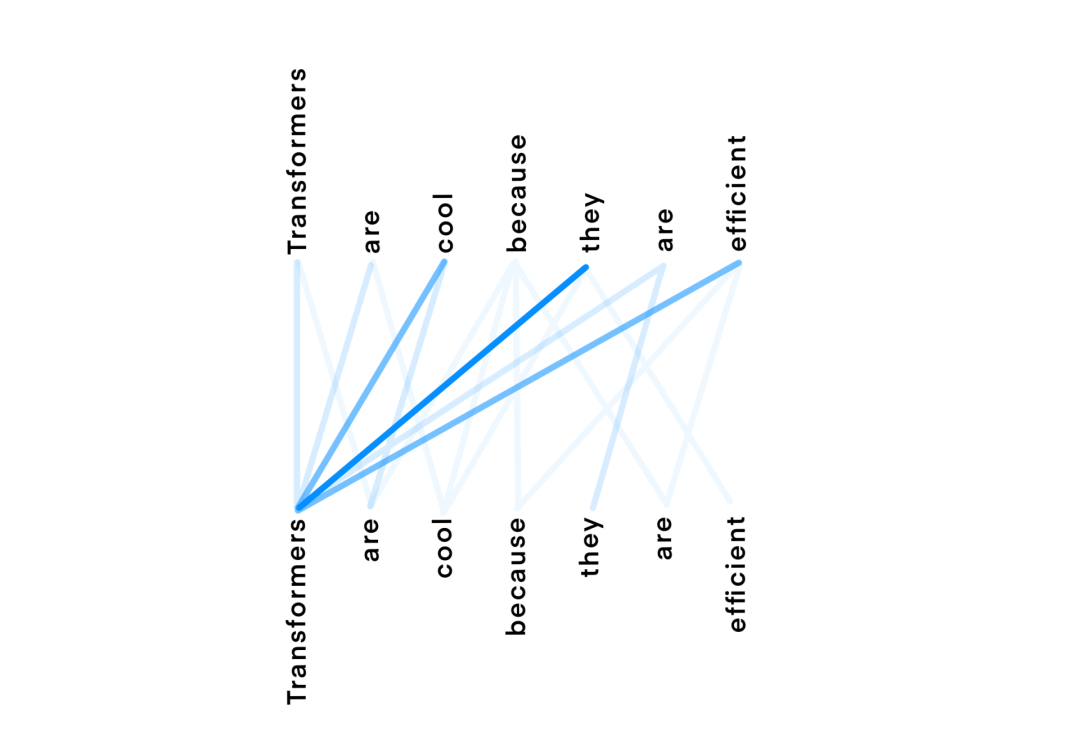
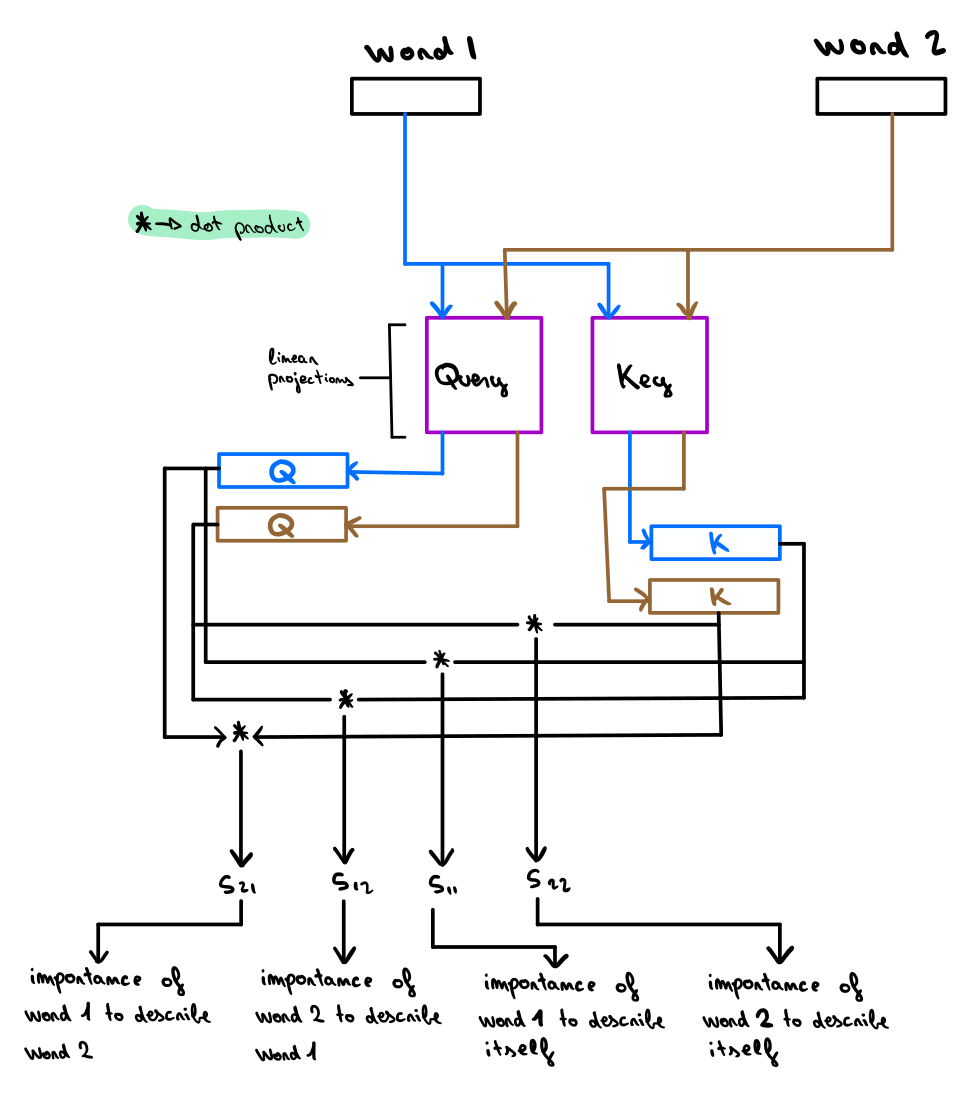
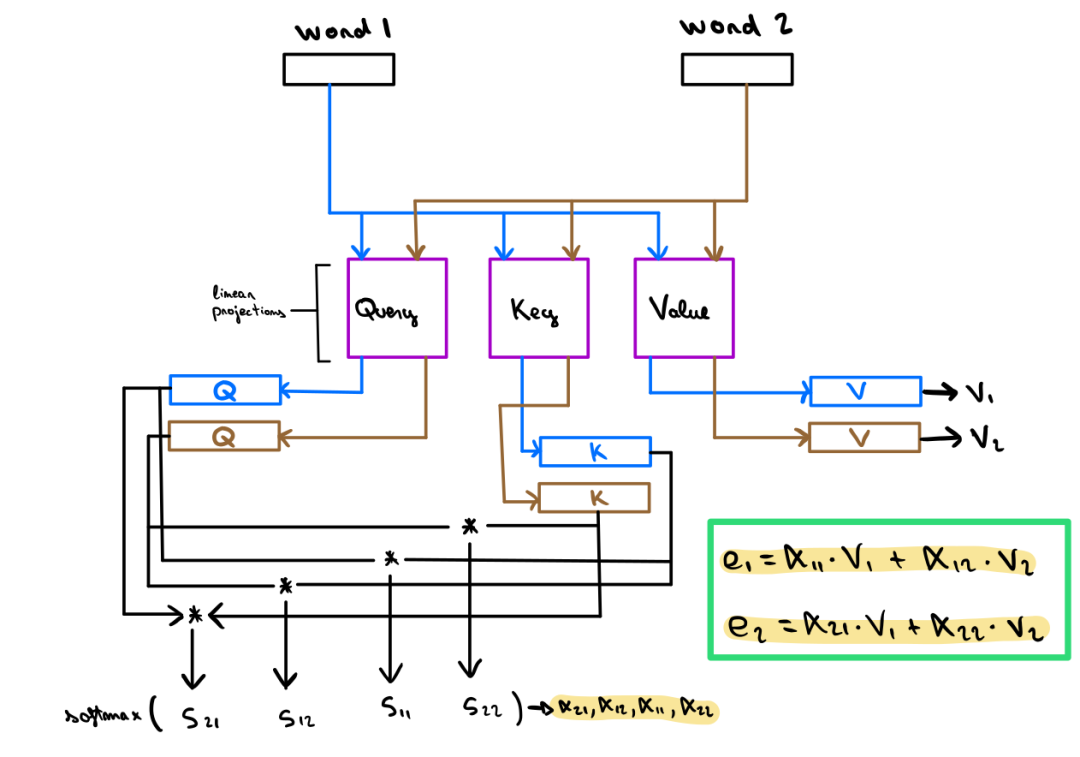
扯了半天终于要介绍我们今天的主角——Transformer 了。2017年的时候 Transformer 横空出世,当时的它被定位成一种简单并且可扩展的自然语言翻译方法,并且很快被应用到各类 NLP 任务之中,逐渐成为 SOTA 模型中的必备成员(比如 GLUE 、SQuAD 或者 sWAG )。 但并不是所有任务都是有能够喂饱深度网络的数据资本的,所以很多任务都会基于上述SOTA模型公开版本的半成品进行微调( finetuning ),从而适配自己的任务。这种做法十分常见并且有效,因为它大幅的节省了训练所需的数据量。这些模型有的已经有着数十亿个参数量了,但是似乎还没有达到性能的天花板。随着模型参数量的增加,模型的结果还会持续上升,模型由此而表现的一些新特性和学习到的新知识也会越来越丰富,具体可以看GPT3的文章。当我们给定了一个包含N个单词的文本输入时,对于每个单词W,Transformers会为文本中的每个单词Wn创建N个权重,每个权重的值取决于单词在上下文中的依赖关系(Wn),以此来表示正在处理的单词的语义信息W。下图表述了这个想法,其中,蓝色线条的颜色深度表示分配给某个单词的注意力Attention的权重。在这里,上面一行表示正在处理的单词,下面一行表示用作上下文的单词(注意,有些单词是相同的,但是如果它们正在被处理或被用于处理另一个单词的时候,它们的地位和处理方式将会有所差异)。请注意,上面一行的“They ”、“Cool”或者“Efficient”有很高的权重指向“Transformer”,因为这确实是它们所引用的目标单词。然后,这些权重被用来组合来自每对单词的值,并为每个单词( W )生成一个更新的嵌入,该单词( W )现在包含关于这些重要单词( Wn )在特定单词( W )上下文中的信息。其实,在这些现象的背后,transformers 使用了 self attention 即自注意力技术来计算这些更新的 Embedding 。Self Attention 是一种计算效率很高的模型技术,它可以并行地更新输入文本中每个单词的嵌入结果。假设我们得到了一段输入文本,并且从文本中的单词嵌入 W 开始。我们需要找到一种 Embedding 方法来度量同一文本中其他单词嵌入相对于 W 的重要度,并合并它们的信息来创建更新的嵌入W'。自注意力机制会将 Embedding 输入文本中的每个单词线性投影到三个不同的空间中,从而产生三种新的表示形式:即查询query、键key和值value。这些新的嵌入将用于获得一个得分,该得分将代表 W 和每个Wn 之间的依赖性(如果 W 依赖于 W',则结果为绝对值很高的正数,如果 W 与W'不相关,则结果为绝对值很高的负值)。这个分数将被用来组合来自不同 Wn 单词嵌入的信息,为单词 W 创建更新的嵌入W'。下面这张图展示了如何计算两个单词之间的 Attention 得分:图中的蓝色线段表示来自第一个单词 W 的信息流,棕色线代表来自第二个单词 Wn 的信息流。每个单词的嵌入将乘以一个键和一个查询矩阵,从而得到每个单词的查询值和键值。为了计算 W 和 Wn 之间的分数,将W(W_q)的查询嵌入发送到 Wn ( Wn_k )的密钥嵌入,并为两个张量使用点积相乘。点积的结果值是它与自身之间的得分,表示 W 相对于 Wn 的依赖程度。需要注意的是,我们还可以将第二个单词作为W,以及将第一个单词作为 Wn 。这样的话,我们就可以另外计算出一个分数,表示第二个单词对第一个单词的依赖性。我们甚至可以用同一个词 W 和 Wn 来计算这个词本身对它的定义有多重要~很巧妙吧。自注意力机制能够计算文本中每对单词之间的注意力得分。该得分将被软最大化处理 (Softmaxed),也就是将其转换为0到1之间的权重。下图展示了如何使用这些权重获得每个单词的最终词嵌入:请注意,每个单词的 Embedding 现在需要乘以第三个矩阵来生成它们的值表示。这个结果将用于计算每个单词的最终嵌入。对于每个单词 W,文本 Wn 中每个单词的计算权重将乘以其相应的值表示(Wn_v),然后将它们相加。这个加权和的结果将用于更新嵌入单词 W (图中用e1和e1表示)。这里我们只是简单的对计算过程进行介绍,如果有小伙伴对其中的具体过程感兴趣的话,可以看看 Jay Alamar 下面的这篇文章:https://jalammar.github.io/illustrated-transformer/。卷积归纳偏差
卷积网络模型多年来在计算机视觉领域是绝对的大哥大,获得了无数的成功,收获了无数的好评。GPU 作为 CNN 的好基友,由于可以进行有效的并行卷积计算而身价疯长。此外,CNN 也会在图像特征提取的过程中提供适当的归纳偏差( Inductive Biases )。CNN 中的卷积运算由于使用了两个重要的空间约束,从而有助于视觉特征的学习和提取:- 由于 CNN 权重共享机制,卷积层所提取的特征便具有平移不变性,它们对特征的全局位置不感冒,而只在乎这些决定性的特征是否存在。
- 由于卷积算子的性质,所以卷积的特征图具有局部敏感性,也就是每次卷积操作只会考虑原始数据的一小部分的局部信息。
正是由于此,CNN 的归纳偏差缺乏对输入数据本身的整体把握。它很擅长提取局部的有效信息,但是没能提取全局数据之间的长距离特征。比如,当我们使用 CNN 去训练一个人脸识别模型时,卷积层可以有效的提取出眼睛大小、鼻子翘不翘、嘴巴颜色等小器官的特征,但是无法将他们联系起来,无法形成"眼镜在鼻子上"、"嘴巴在眼睛下面"的这种长距离的特征。因为每个卷积核都很局部,没办法同时处理这么多个特征。为了提取和跟踪这些原始数据中的长相关特征,模型需要扩大自己的感受野,这就需要使用一些更大的卷积核,以及更深的卷积。但是由此会带来计算效率的大幅下降,会让模型的复杂度剧烈上升,甚至会让模型产生维度灾难从而无法收敛训练。计算机视觉领域中的Transformers
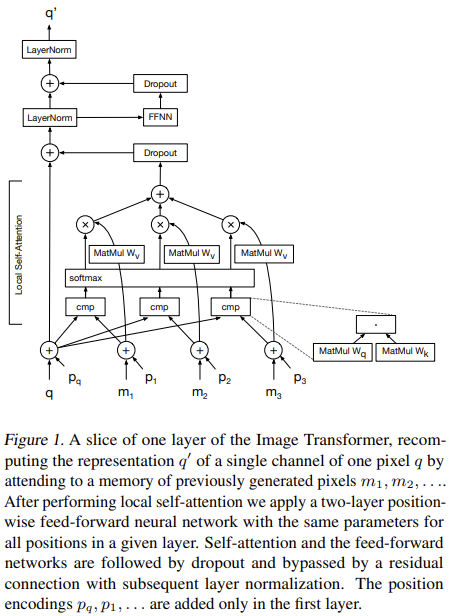
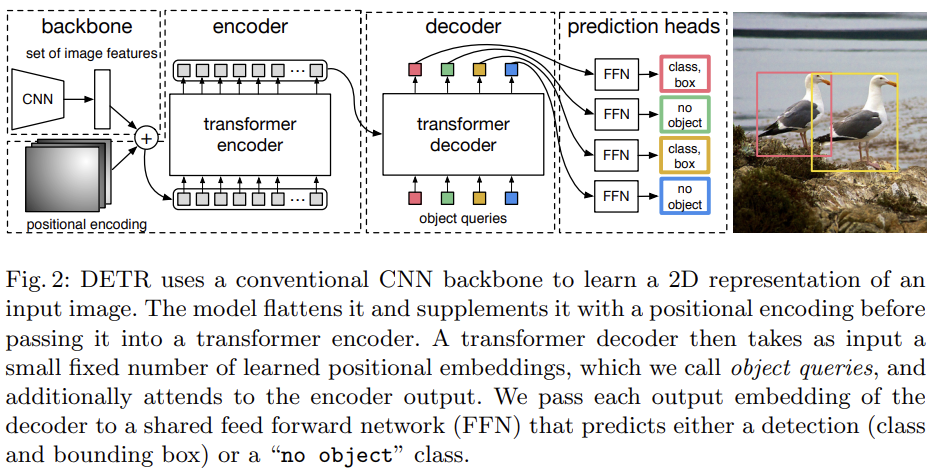
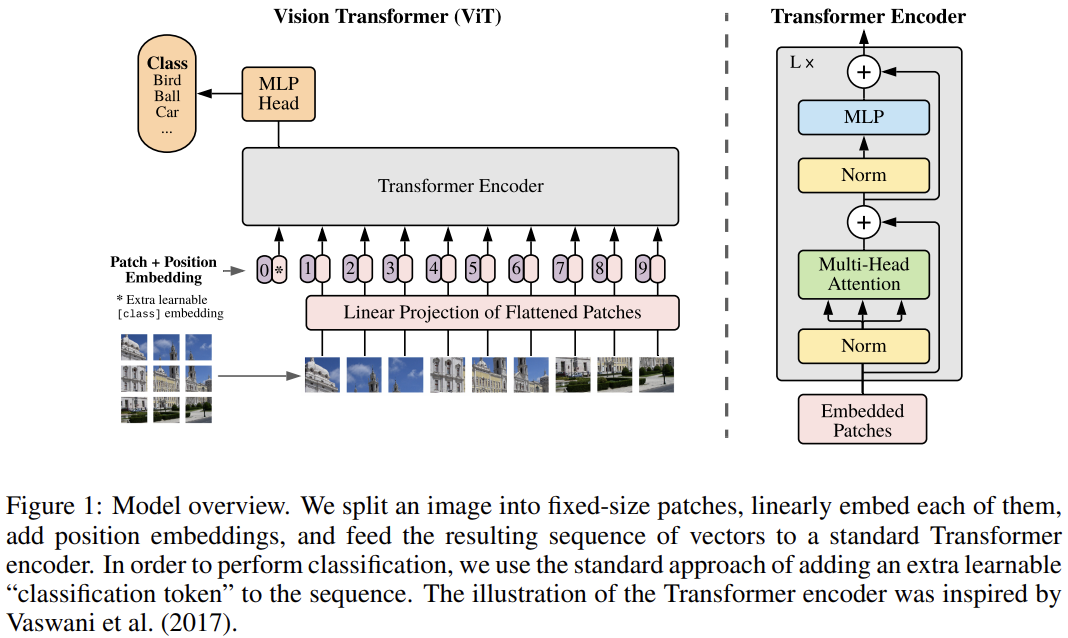
受到 Transformer 论文中使用自注意力机制来挖掘文本中的长距离相关依赖的启发,很多计算机视觉领域的任务提出使用自注意力机制来有效克服卷积归纳偏差所带来的局限性。希望能够将这种 NLP 领域中的技术思想借鉴到视觉领域中,从而提取长时依赖关系。功夫不负有心人,Transformer为视觉领域带来了革新性的变化,它让视觉领域中目标检测、视频分类、图像分类和图像生成等多个领域有了长足的进步。这些应用了 Transformer 技术的模型有的识别能达到甚至超越该领域 SOTA 解决方案的效果。更让人兴奋的是,这些技术有的甚至干脆抛弃了 CNN,直接单单使用自注意力机制来构建网络。目标检测:https://arxiv.org/pdf/2005.12872.pdf视频分类:https://arxiv.org/pdf/1711.07971.pdf图像分类:https://arxiv.org/pdf/1802.05751.pdf图像生成:https://arxiv.org/pdf/2010.11929.pdf这些使用了自注意力机制所生成的视觉特征图不会像卷积计算一样具有空间限制。相反,它们能够根据任务目标和网络中该层的位置来学习最合适的归纳偏差。研究表明,在模型的前几层中使用自注意力机制可以学习到类似于卷积计算的结果。如果小伙伴想具体了解这一领域最近的动态,可以查看这篇由 Gbriel | lharco 撰写的推文:https://arxiv.org/pdf/1911.03584.pdf计算机视觉领域中的自注意力层的输入是特征图,目的是计算每对特征之间的注意力权重,从而得到一个更新的特征映射。其中每个位置都包含关于同一图像中任何其他特征的信息。这些层可以直接代替卷积或与卷积层相结合,它们也能够处理比常规卷积更大的感受野。因此这些模型能够获取空间上具有长距离间隔的特征之间的依赖关系。比如Non-local Netorks和Attention Augmented Convolutional Networks文章中所述,自注意力层最基本的实现方法是将输入特征图的空间维度展开成为一系列的 HWxF 的特征序列,其中 HW 表示二维空间维度, F 表示特征图的深度。自注意力层可以直接作用在序列数据上来获取更新后的特征图表示。Non-local Netorks:https://arxiv.org/pdf/1711.07971.pdfAttention Augmented Convolutional Networks:https://arxiv.org/abs/1904.09925但是实际上,对于高分辨率的输入来说,自注意力机制层的计算量很大,因此它只适用于较小的空间维度输入的数据场景。很多工作也注意到这个问题,并且提出了一些解决方案,比如Axial DeepLab,它们沿着两个空间轴顺序计算Attention,而不是像普通自注意力机制一样直接处理整个图像数据,这使得计算更加高效。还有一些其他的优化解决方案,比如只处理较小的特征图Patch,而不是处理整个特征图空间。但是这样操作的代价是感受野比较小,这是在论文Stand-Alone Self-Attention in Vision Models中提出的。但是即便这样的感受野受到了限制,也比卷积操作的卷积核的感受野要大得多。Axial DeepLab:https://arxiv.org/pdf/2003.07853.pdfStand-Alone Self-Attention in Vision Models:https://arxiv.org/pdf/1906.05909.pdf当我们在模型的最后一层是用自注意力机制来将前面的各种卷积层相融合的时候,就可以得到最优的模型结果。事实上,在实验中我们会发现,自注意力机制和卷积层是很类似的,尤其是在网络的前若干层中自注意力机制学习到的归纳偏差和卷积层学习到的特征图十分类似。现有的计算机视觉工作中,除了那些将自注意力机制加入卷积流程中的工作之外,其他的方法的计算都仅仅依赖于自注意力层,并且只使用了最原始的Transformer的编码-解码器结构。当我们的模型参数量能够设置得很大,并且数据量充足的时候,这些模型在图像分类任务/目标检测等任务中所表现出来的效果能够达到SOTA的程度,甚至有时候更好。同时这些模型的结构会更加简单,训练速度还会更快。最原始的Transorfer的编码-解码器结构:https://arxiv.org/pdf/1706.03762.pdf接下来我们简要的介绍三篇重要的相关论文,它们都在自己的网络中使用了Transformer结构。这篇论文提出了一种在ImageNet数据集上的全新SOTA图像生成器,并且在超高分辨率任务上取得了很好的效果。论文地址:https://arxiv.org/pdf/1802.05751.pdf在这篇论文中,他们将图像生成任务视作一个自回归问题,图片中的每个新像素仅基于图像中先前已知的像素值生成。在每一个特征生成过程中,自注意力机制将m个展开后的特征图作为上下文,从而生成未知的像素值。为了让这些像素能够匹配自注意力层的输入,论文使用1D卷积将每个RGB值转换为d维张量,并将局部的上下文特征图的m维特征展平到一维。在图中,q表示要更新的像素embedding,它与内存中的像素m的所有其他嵌入相乘,使用查询和键矩阵(Wq和Wk)生成一个得分,然后对该得分进行softmax操作,并将其作为矩阵Wv的权重。算法最终将该Embedding加到原始的q Embedding中,从而得到最终的结果。在图中,p表示添加到每个输入嵌入中的位置编码。这种编码是从每个像素的坐标生成的。需要注意的是,通过使用自注意力机制,算法可以并行地预测多个像素值,因为算法已经知道输入图像的原始像素值,并且用于计算自我注意的Patch机制,可以处理比卷积层更高的感受野。但是在评估的操作过程中,由于图像的生成依赖于每个像素的邻居的值,因此只能单步执行。DETR是DEtection TRansformer的缩写,它是一种结构较为简单的模型,在目标检测领域中达到了SOTA的高度。论文地址:https://arxiv.org/pdf/2005.12872.pdf它搭配着使用了自注意力机制,以及从卷积神经网络提取的视觉特征。在CNN的主干模块中,算法计算的特征图会首先被展平,也就是说,如果特征地图具有形状(h x w x d),则展平结果将具有形状(hw x d)。每一个维度中都添加了一个可学习的位置编码,而编码器也会将结果序列作为输入。编码器使用多个自注意力块来组合不同Embedding之间的特征。处理后的Embedding被传递到一个解码器模块。这个解码器模块使用可学习的Embedding作为对象查询来处理所有视觉特征,从而生成一个嵌入。在该嵌入中,执行目标检测所需的所有信息都被编码。每个输出被输入到一个全连接层中,该网络模块将输出一个包含元素c和b的五维张量,其中c表示该元素的预测类个数,b表示边界框的坐标(分别是一维和四维)。c的值分配给一个“no object”标记,它表示没有找到任何有意义的检测的目标查询,所以说模型将不考虑它的坐标。这个模型能够并行计算单个图像的多个检测。但是,它可以检测到的目标个数受制于所使用的目标查询次数。论文的作者在文中表示,该模型在大尺寸目标识别的图像处理方面优于SOTA模型。他们认为这都归功于自注意力机制为模型提供了更高的感受野。3、Vision Transformer(ViT)这个模型是图像识别领域的代表性SOTA工作,它仅仅使用了自注意力机制,而且达到了目前的SOTA识别率。论文地址:https://arxiv.org/pdf/2010.11929.pdf该模型的输入是从像素大小为PxP的块中提取的平坦像素向量。每个输入像素被送入一个线性投影层,这个层将产生文中所谓的“补丁嵌入(Patch embeddings)”。注意,在序列的开头处,模型附加了一个额外可学习的嵌入。这种嵌入处于自我注意更新之后,用于预测输入图像的类别。每个Embedding中也添加了一个可学习的位置Embedding。分类只需将一个 MLP 头放在Transformer结构的顶部,具体的插入位置就是在我们添加到序列中的额外可学习的Embedding位置。此外,本文还给出了一种混合的模型结构。它使用ResNet早期的特征映射作为Transformer的输入,而没有选择输入投影的图像块。通过对 Transformer 模型和 CNN 骨干网络端到端的训练,模型能够达到最好的图像分类结果。位置编码
由于Transformers需要学习一个具体的任务,也就是需要学习该任务的归纳偏差,所以只要进行模型训练,就都会对该网络产生一定的收益。换句话说,任何可以包含在模型输入中的归纳偏差都将有助于模型的学习,并能够用于改善结果。当使用Transformers的更新功能时,输入序列的顺序信息会被丢失。对于Transformer模型来说,这个顺序信息是很难被学习到的,或者说有的时候根本不可能被学习到。所以它所做的就是将一个位置表示聚合到模型的输入嵌入中。这种位置编码可以通过学习获得,也可以从一个固定的函数中取样得到。虽然聚合操作通常只在输入到模型的嵌入处完成,但是我们其实是可以改变这个聚合操作的位置。在计算机视觉中,这些嵌入既可以表示特征在一维平坦序列中的位置,也可以表示特征的二维位置。在该领域中,大家普遍认为位置编码是很有效的一种信息。它们由可学习的若干个嵌入组成。这些嵌入特征不用编码全局的位置,转而去学习各个编码特征之间的相对距离从而达到更好的效果。结论
Transformers结构解决了一个自然语言处理和计算机视觉领域都困扰已久的问题——长期依赖。Transformer模型是一种很简单但是很灵活的方法,如果将其抽象为一系列嵌入,那么它可以应用于任何类型的数据。卷积具有平移不变性、局部敏感性,也缺少对图像的整体感知和宏观理解。Transformers可用于卷积网络中,从而让网络学习处对图像的全局理解。Transformers能够用于计算机视觉领域,就算我们把原来卷积网络中的卷积层都抛弃,只使用Transformers层的时候,模型也能得到SOTA的结果。本文部分素材来源于网络,如有侵权,联系删除。
【计算机视觉特训】
提供Jupyter NotebookCPU云平台
课件代码一应俱全
共享社群,实时答疑
01月25日(下周一)开课
长按识别二维码
咨询课程
课程详情
☟


购买,咨询,查看课程,请点击【阅读原文】
↓ ↓ ↓