
Transformer为何能闯入CV界秒杀CNN?
转载自 | AI科技评论
文章主要介绍Transformers背后的技术思想,Transformers在计算机视觉领域的应用情况、最新动态以及该架构相对于CNN的优势。
为什么Transformers模型在NLP自然语言处理任务中能够力压群雄,变成SOTA模型的必备组件之一。 Transformers模型的计算原理。 为什么说Transformers是对CNN的当头棒喝,Transformers是怎么针对CNN的各种局限性进行补全的。 计算机视觉领域的最新模型是如何应用Transformers提升自己的。
长期依赖和计算效率之间的权衡取舍
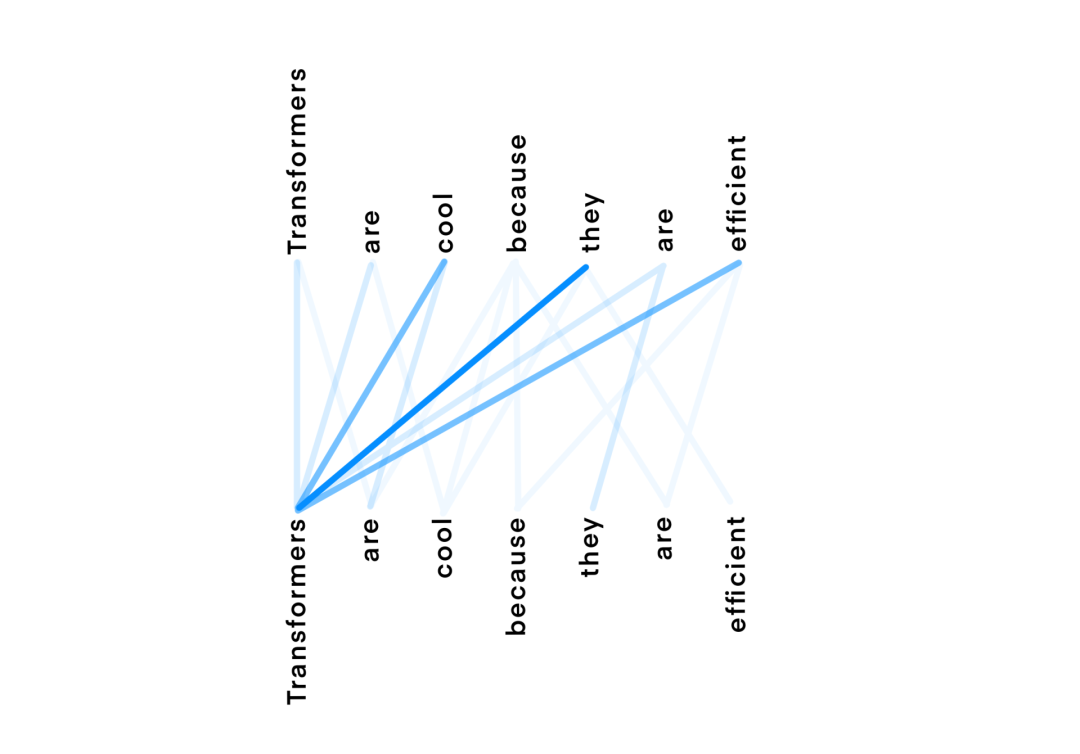
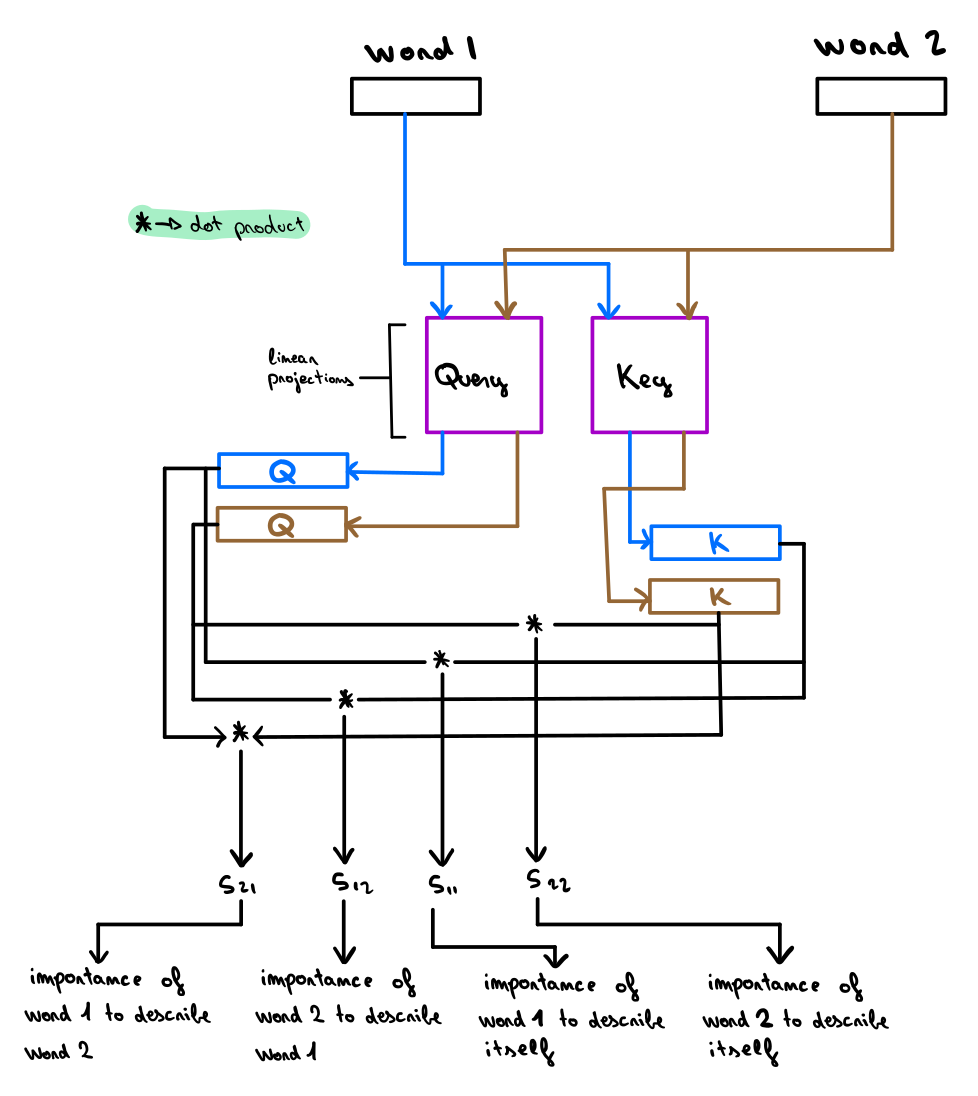
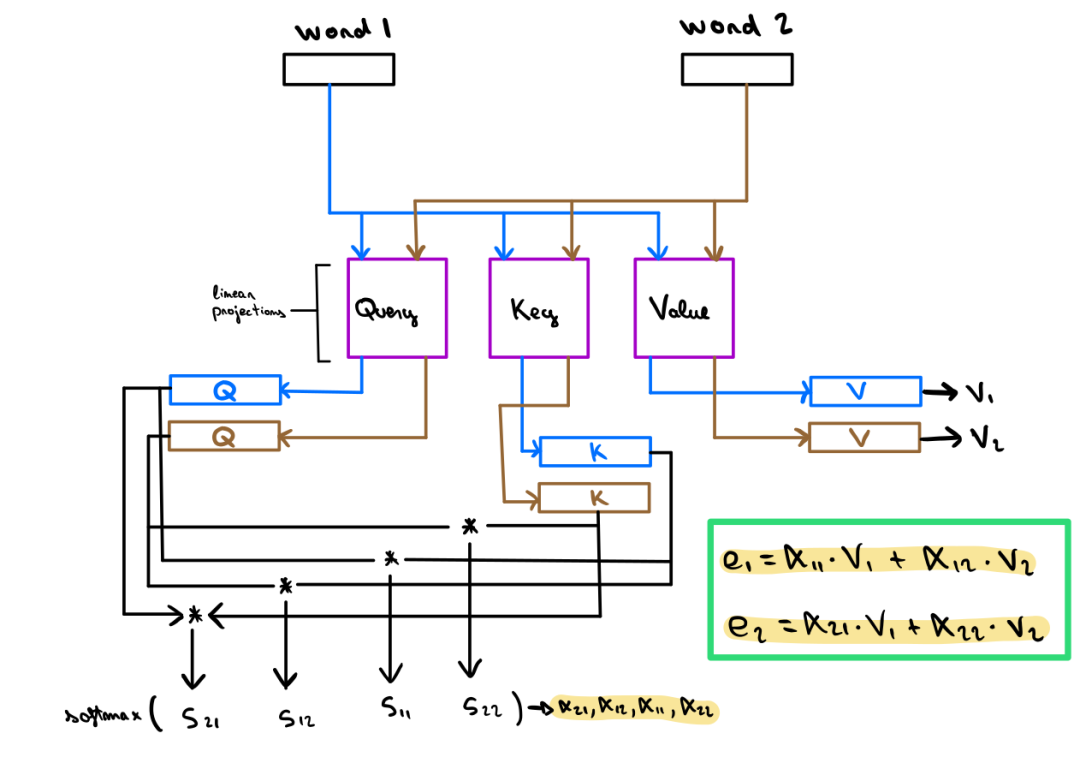
Transformers横空出世
卷积归纳偏差
由于 CNN 权重共享机制,卷积层所提取的特征便具有平移不变性,它们对特征的全局位置不感冒,而只在乎这些决定性的特征是否存在。 由于卷积算子的性质,所以卷积的特征图具有局部敏感性,也就是每次卷积操作只会考虑原始数据的一小部分的局部信息。
计算机视觉领域中的Transformers
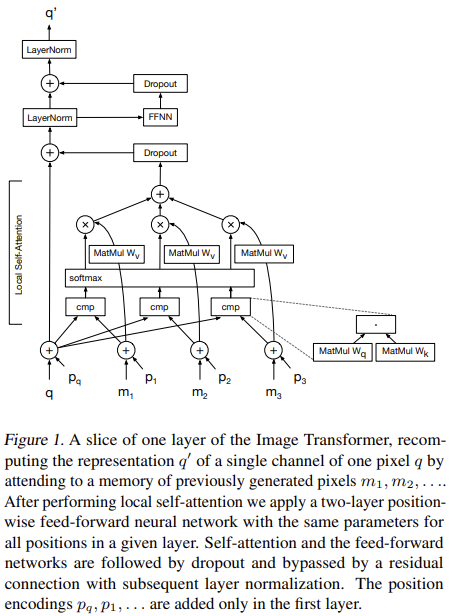
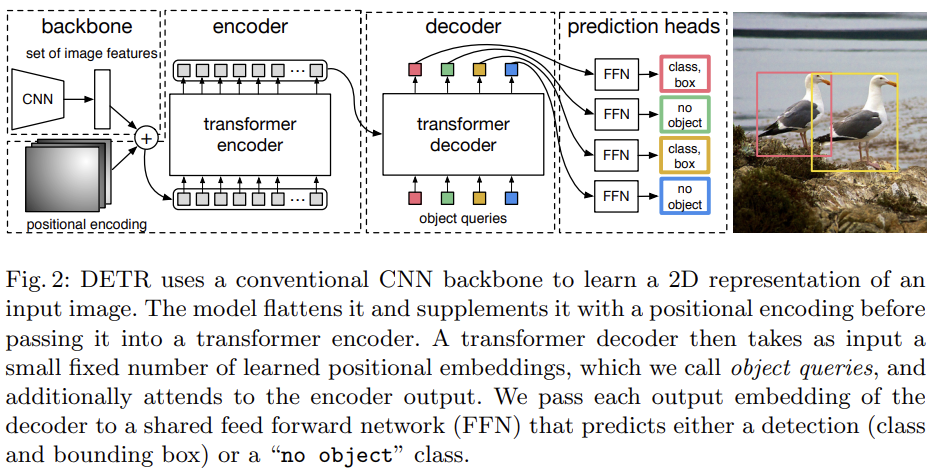
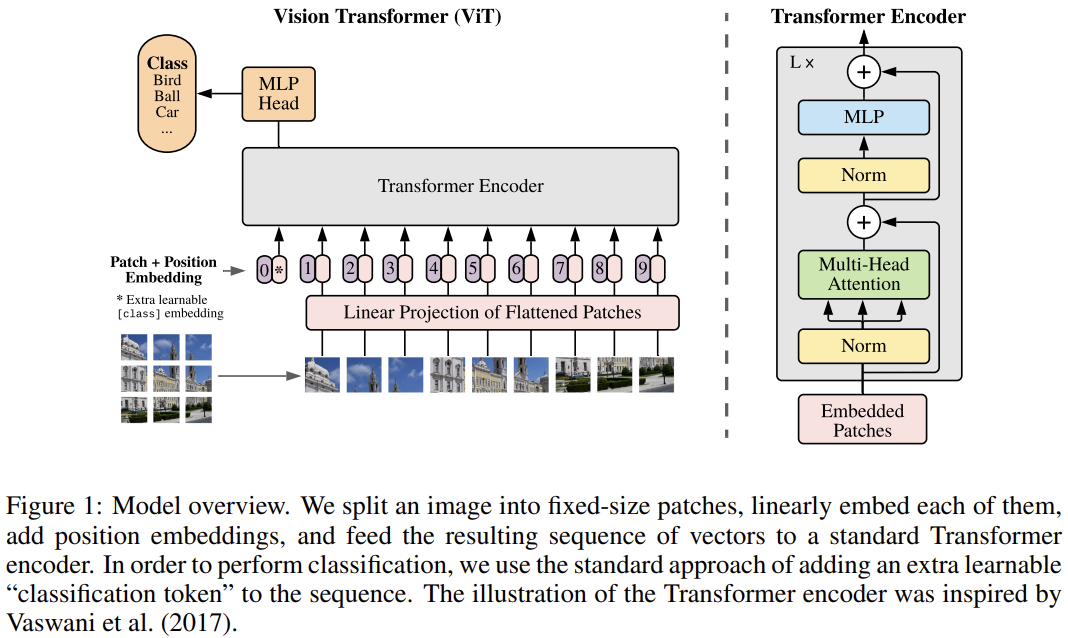
位置编码
结论
双一流高校研究生团队创建 ↓
专注于计算机视觉原创并分享相关知识 ☞
整理不易,点赞三连!
评论