
人脸算法系列:MTCNN人脸检测详解
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

人脸检测的概念
人脸检测是一种在多种应用中使用的计算机技术,可以识别数字图像中的人脸。人脸检测还指人类在视觉场景中定位人脸的过程。
人脸检测可以视为目标检测的一种特殊情况。在目标检测中,任务是查找图像中给定类的所有对象的位置和大小。例如行人和汽车。

人脸检测示例
在人脸检测中应用较广的算法就是MTCNN( Multi-task Cascaded Convolutional Networks的缩写)。MTCNN算法是一种基于深度学习的人脸检测和人脸对齐方法,它可以同时完成人脸检测和人脸对齐的任务,相比于传统的算法,它的性能更好,检测速度更快。
本文目的不是为了强调MTCNN模型的训练,而是如何使用MTCNN提取人脸区域和特征点,为后续例如人脸识别和人脸图片预处理做铺垫。
接下来介绍MTCNN的使用,让大家对其有一个直观的感受,再深入了解其原理。
MTCNN的使用
Paper地址:https://kpzhang93.github.io/MTCNN_face_detection_alignment/
github链接:https://github.com/kpzhang93/MTCNN_face_detection_alignment
其他版本:https://github.com/AITTSMD/MTCNN-Tensorflow
作者是基于caffe实现的,因为本人配置了多次,都失败了,因此尝试了其他框架的,采用mxnet框架,当然也附上了pytorch版本的。
本次使用的项目链接:https://github.com/YYuanAnyVision/mxnet_mtcnn_face_detection
其他参考:
pytorch版本:https://github.com/TropComplique/mtcnn-pytorch
第一步:将项目克隆下来
git clone https://github.com/YYuanAnyVision/mxnet_mtcnn_face_detection当然很有可能会中途失败,我自己也是尝试多次都没搞定,又慢又老是不行。不过之前分享过一个妙招,如果看过的小伙伴一定知道如何解决。
这里附上文章链接:
第二步:配置好所需的环境
mxnet的安装非常容易,这里以我的电脑为例安装GPU版本的mxnet
只需一行代码即可完成安装,首先查询自己所安装cuda的版本,并输入对应的指令即可
# 例如我的电脑是cuda 9.0的pip install mxnet-cu90
这里有补充说明https://pypi.org/project/mxnet-cu90/,更多内容可以百度搜索解决。
第三步:运行代码
该项目已经有预训练模型了,直接运行main.py即可。
但是你一运行,就会发现 哦豁,报错了。
这是因为该项目是用python2写的,所以存在一些需要修改的地方。
问题一:ImportError: cannot import name 'izip' (报错文件 mtcnn_detector.py)
解决方案:python3中的zip就相当于 python2 itertools里的izip
因此,只需要做以下修改即可,在mtcnn_detector.py将报错的from itertools import izip注释掉,下面加一行试试看。
具体操作,在main.py中找到 from itertools import izip,并修改成下面即可。
#from itertools import izipizip = zip
解决了之后在运行一次main.py
问题2:TypeError: 'float' object cannot be interpreted as an integer
类型错误:“float”对象不能解释为整数
解决方法:将报错的地方存在的 “/” 都修改成 “//” 即可,同类报错,相同的解决方法。
python2和python3中运算符的区别。
python3中 / 运算的结果是含有浮点数的。而python2中/是等价于python3中的 // ,python3中// 表示向下取整的除法。
# 举个例子在python3中 //print(3/2,3//2) # 输出 1.5, 1
历经千辛万苦,最终展示效果:
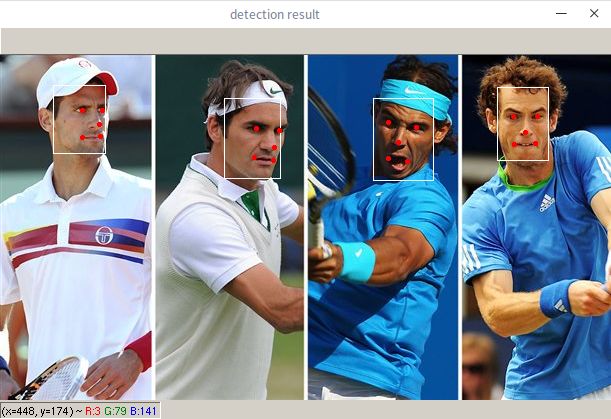
到这里我们已经能够检测到人脸了,对于自己的图片,只需要修改main.py中读入的图片路径即可。更多自定义操作,例如批量处理和保存,可以根据自己的需求来添加。
MTCNN的原理
对于如此经典的网络仅仅掌握其使用还是不够的,因此接下来将详细的说明一下其内在的原理。
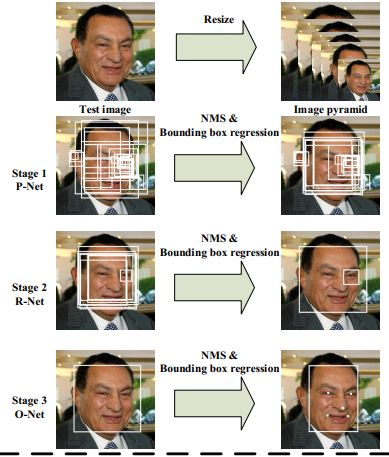
图片来源与论文原文
从上图可以知道主要包括四个操作,三个步骤。
1、图像金字塔
对图片进行Resize操作,将原始图像缩放成不同的尺度,生成图像金字塔。然后将不同尺度的图像送入到这三个子网络中进行训练,目的是为了可以检测到不同大小的人脸,从而实现多尺度目标检测。
图像金字塔是图像中多尺度表达的一种。对于图像金字塔的具体原理这里不详细展开,有兴趣可以参考这篇文章:https://zhuanlan.zhihu.com/p/80362140
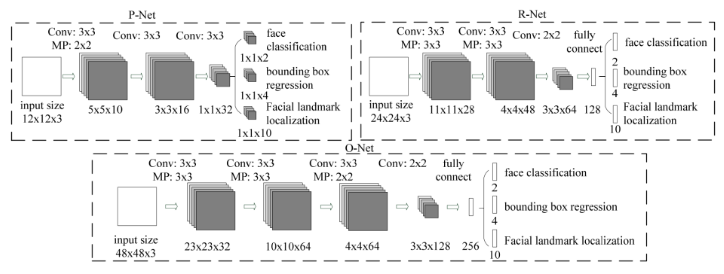
三个子网络图
2、P-Net(Proposal Network)
论文原文对P-Net的描述:该网络结构主要获得了人脸区域的候选框和边界框的回归向量。然后基于预测边界框回归向量对候选框进行矫正。在这之后,我们采用NMS来合并重叠率高的候选框。
P-Net是一个人脸区域的候选网络,该网络的输入一个12x12x3的图像,通过3层的卷积之后,判断这个12x12的图像中是否存在人脸,并且给出人脸框的回归和人脸关键点。
网络的第一部分输出是用来判断该图像是否存在人脸,输出向量大小1x1x2,也就是两个值。
网络的第二部分给出框的精确位置,一般称为框回归。P-Net输入的12×12的图像块可能并不是完美的人脸框的位置,如有的时候人脸并不正好为方形,有可能12×12的图像偏左或偏右,因此需要输出当前框位置相对完美的人脸框位置的偏移。这个偏移大小为1×1×4,即表示框左上角的横坐标的相对偏移,框左上角的纵坐标的相对偏移、框的宽度的误差、框的高度的误差。
网络的第三部分给出人脸的5个关键点的位置。5个关键点分别对应着左眼的位置、右眼的位置、鼻子的位置、左嘴巴的位置、右嘴巴的位置。每个关键点需要两维来表示,因此输出是向量大小为1×1×10。
3、R-Net(Refine Network)
论文原文对P-Net的描述:P-Net的所有候选框都输入到R-Net中,该网络结构还是通过边界框回归和NMS来去掉大量的false-positive区域。
从网络图可以看到,只是由于该网络结构和P-Net网络结构有差异,多了一个全连接层,所以会取得更好的抑制false-positive的作用。在输入R-Net之前,都需要缩放到24x24x3,网络的输出与P-Net是相同的,R-Net的目的是为了去除大量的非人脸框。
4、O-Net(Output Network)
论文原文对O-Net的描述:这个阶段类似于第二阶段,但是在这个阶段在此阶段,我们目的通过更多的监督来识别面部区域。特别是,网络将输出五个面部关键点的位置。
从网络图可以看到,该层比R-Net层有多了一层卷积层,所以处理的结果会更加精细。输入的图像大小48x48x3,输出包括N个边界框的坐标信息,score以及关键点位置。
总结:
从P-Net到R-Net,再到最后的O-Net,网络输入的图像越来越大,卷积层的通道数越来越多,网络的深度(层数)也越来越深,因此识别人脸的准确率应该也是越来越高的。
对各个网络结果的作用理解之后,我们深入了解一下其所采用的损失函数。
MTCNN的损失函数
针对人脸识别问题,直接使用交叉熵代价函数,对于框回归和关键点定位,使用L2损失。最后把这三部分的损失各自乘以自身的权重累加起来,形成最后的总损失。
1、人脸识别损失函数(cross-entry loss)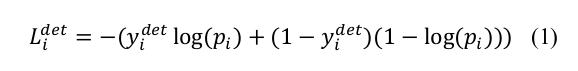
2、回归框的损失函数 (Euclidean loss)

3、关键点的损失函数 (Euclidean loss)
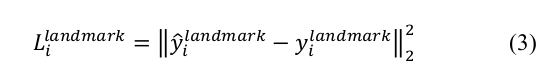
4、总损失
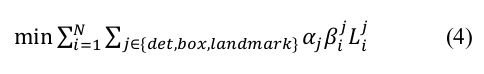
具体的各个公式的含义,大家应该都明白,这里强调一下,最后的总损失前添加了一个权重 α ,即损失函数所对应的权重是不一致的。详细设置可以参看论文原文。

参考文献:
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~