
CV岗位面试题:FCN与CNN最大的区别?

文 | 七月在线
编 | 小七
解析:
FCN中用卷积层替换了CNN中的全连接层
1、FCN概述
CNN做图像分类甚至做目标检测的效果已经被证明并广泛应用,图像语义分割本质上也可以认为是稠密的目标识别(需要预测每个像素点的类别)。
传统的基于CNN的语义分割方法是:将像素周围一个小区域(如25*25)作为CNN输入,做训练和预测。这样做有3个问题:
- 像素区域的大小如何确定 ;
- 存储及计算量非常大 ;
- 像素区域的大小限制了感受野的大小,从而只能提取一些局部特征;
2、FCN原理及网络结构
一句话概括原理:FCN将传统卷积网络后面的全连接层换成了卷积层,这样网络输出不再是类别而是 heatmap;同时为了解决因为卷积和池化对图像尺寸的影响,提出使用上采样的方式恢复。核心思想:
- 不含全连接层(fc)的全卷积(fully conv)网络,可适应任意尺寸输入。
- 增大数据尺寸的反卷积(deconv)层,能够输出精细的结果。
- 结合不同深度层结果的跳级(skip)结构,同时确保鲁棒性和精确性。
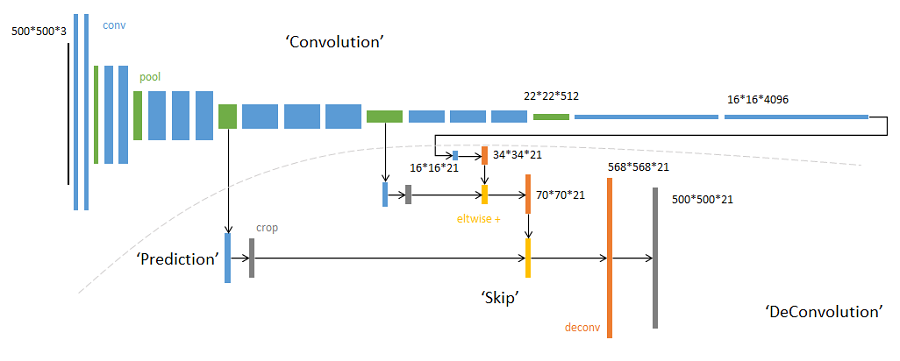
网络结构示意图:
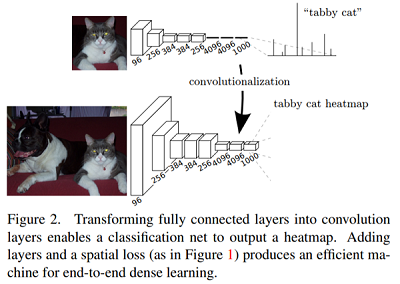
网络结构详图:输入可为任意尺寸图像彩色图像;输出与输入尺寸相同,深度为:20类目标+背景=21类。
3 CNN 与 FCN
CNN
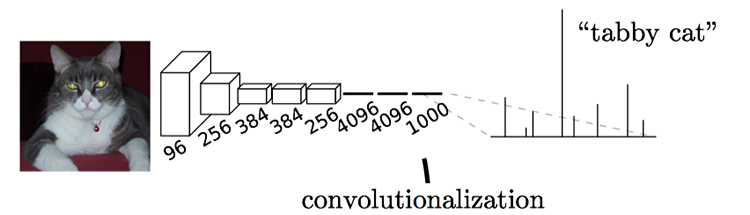
通常CNN网络在卷积层之后会接上若干个全连接层, 将卷积层产生的特征图(feature map)映射成一个固定长度的特征向量。以AlexNet为代表的经典CNN结构适合于图像级的分类和回归任务,因为它们最后都期望得到整个输入图像的一个数值描述(概率),比如AlexNet的ImageNet模型输出一个1000维的向量表示输入图像属于每一类的概率(softmax归一化)。
比如:下图中的猫, 输入AlexNet, 得到一个长为1000的输出向量, 表示输入图像属于每一类的概率, 其中在“tabby cat”这一类统计概率最高。
FCN
FCN对图像进行像素级的分类,从而解决了语义级别的图像分割(semantic segmentation)问题。与经典的CNN在卷积层之后使用全连接层得到固定长度的特征向量进行分类(全联接层+softmax输出)不同,FCN可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的feature map进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 然后在上采样的特征图上进行逐像素分类。
最后逐个像素计算softmax分类的损失, 相当于每一个像素对应一个训练样本。下图是Longjon用于语义分割所采用的全卷积网络(FCN)的结构示意图:
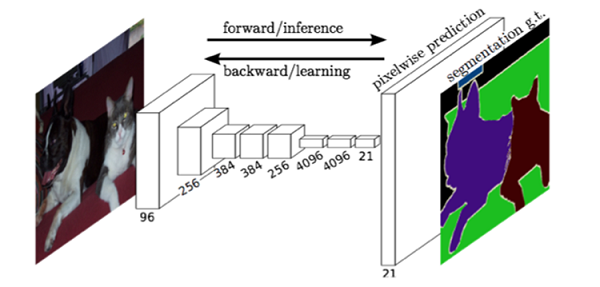
简单的来说,FCN与CNN的区域在把于CNN最后的全连接层换成卷积层,输出的是一张已经Label好的图片:
这些抽象的特征对分类很有帮助,可以很好地判断出一幅图像中包含什么类别的物体,但是因为丢失了一些物体的细节,不能很好地给出物体的具体轮廓、指出每个像素具体属于哪个物体,因此做到精确的分割就很有难度。
基于CNN的分割方法与FCN的比较
传统的基于CNN的分割方法:为了对一个像素分类,使用该像素周围的一个图像块作为CNN的输入用于训练和预测。这种方法有几个缺点:
1、存储开销很大。例如对每个像素使用的图像块的大小为15x15,然后不断滑动窗口,每次滑动的窗口给CNN进行判别分类,因此则所需的存储空间根据滑动窗口的次数和大小急剧上升。
2、计算效率低下。相邻的像素块基本上是重复的,针对每个像素块逐个计算卷积,这种计算也有很大程度上的重复。
3、像素块大小的限制了感知区域的大小。通常像素块的大小比整幅图像的大小小很多,只能提取一些局部的特征,从而导致分类的性能受到限制。
而全卷积网络(FCN)则是从抽象的特征中恢复出每个像素所属的类别。即从图像级别的分类进一步延伸到像素级别的分类。