
Python-matplotlib 学术散点图 EE 统计及绘制
大邓和他的Python
共 6131字,需浏览 13分钟
· 2020-09-07
01. 引言

02. 数据处理
要完成数据统计操作,首先要先进行三条拟合线的制作,具体如下:
#导入数据拟合函数from scipy.stats import linregressx2 = np.linspace(-10,10)#制作最佳拟合线数据y2=x2#制作上拟合线数据up_y2 = 1.15*x2 + 0.05#制作下拟合线数据down_y2 = 0.85*x2 - 0.05#进行拟合line_01 = linregress(x2,y2)line_top = linregress(x2,up_y2)line_bopptom = linregress(x2,down_y2)
其中,up_y2和down_y2 具体设置可以参考之前的推文Python-matplotlib 学术散点图完善 ,linregress () 拟合的结果如下:

slope 为斜率,intercept 为截距,rvalue 为相关系数 ,pvalue 为p值,stderr 为标准误差。
而原始的数据集如下(部分):

接下来我们根据相同的x值构建对应拟合线的三个y值,具体代码如下:
data_select = data_select.copy()data_select['true_y'] = data_select.true_data.valuesdata_select['top_y'] = data_select['true_data'].apply(lambda x : line_top[0]*x + line_top[1])data_select['bottom_y'] = data_select['true_data'].apply(lambda x : line_bopptom[0]*x + line_bopptom[1])data_select.head()
这里涉及到pandas 处理数据常用 的 apply()函数,该方法对一般的数据处理步骤中经常使用,希望大家能够掌握。构建后的数据如下:
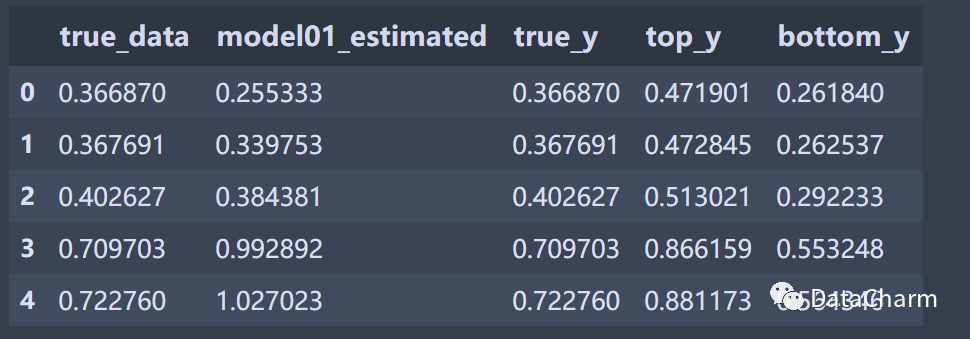
而判断 各个 Expected Error 的依据就是根据所构建的 top_y 、bottom_y和 model01_estimated 。将三者进行对比分析即可。
统计个数
所需数据构建好后,就可根据pandas 的数据选择操作进行筛选,最后统计个数即可,具体代码如下:
#构建 选择条件top_condi = (data_select['model01_estimated'] > data_select['top_y'])bottom_condi = (data_select['model01_estimated'] < data_select['bottom_y'])bottom_top = ((data_select['model01_estimated'] < data_select['top_y']) & \(data_select['model01_estimated'] > data_select['bottom_y']))all_data = len(data_select)top_counts = len(data_select[top_condi])bottom_counts = len(data_select[bottom_condi])bottom_top_counts = len(data_select[bottom_top])
进而求出不同 Expected Error 内的数据个数,本实例结果如下:
all_data = 4348top_counts = 1681bottom_counts = 404bottom_top_counts = 2263
03. 数据可视化
label_font = {'size':'22','weight':'medium','color':'black'}ax.text(.7,.25,s='Within EE = ' + '{:.0%}'.format(bottom_top_counts/all_data),transform = ax.transAxes,ha='left', va='center',fontdict=text_font)ax.text(.7,.18,s='Above EE = ' + '{:.0%}'.format(top_counts/all_data),transform = ax.transAxes,ha='left', va='center',fontdict=text_font)ax.text(.7,.11,s='Below EE = ' + '{:.0%}'.format(bottom_counts/all_data),transform = ax.transAxes,ha='left', va='center',fontdict=text_font)
import pandas as pdimport numpy as npfrom scipy import optimizeimport matplotlib.pyplot as pltfrom sklearn.metrics import mean_squared_error,r2_scorefrom matplotlib.pyplot import MultipleLocator#统一修改字体plt.rcParams['font.family'] = ['Arial']N = len(test_data['true_data'])x = test_data['true_data'].values.ravel() #真实值y = test_data['model01_estimated'].values.ravel()#预测值C=round(r2_score(x,y),4)rmse = round(np.sqrt(mean_squared_error(x,y)),3)#绘制拟合线x2 = np.linspace(-10,10)y2=x2def f_1(x, A, B):return A*x + BA1, B1 = optimize.curve_fit(f_1, x, y)[0]y3 = A1*x + B1#开始绘图fig, ax = plt.subplots(figsize=(7,5),dpi=200)ax.scatter(x, y,edgecolor=None, c='k', s=12,marker='s')ax.plot(x2,y2,color='k',linewidth=1.5,linestyle='-',zorder=2)ax.plot(x,y3,color='r',linewidth=2,linestyle='-',zorder=2)#添加上线和下线ax.plot(x2,up_y2,color='k',lw=1.,ls='--',zorder=2,alpha=.8)ax.plot(x2,down_y2,color='k',lw=1.,ls='--',zorder=2,alpha=.8)fontdict1 = {"size":17,"color":"k",}ax.set_xlabel("True Values", fontdict=fontdict1)ax.set_ylabel("Estimated Values ", fontdict=fontdict1)ax.grid(which='major',axis='y',ls='--',c='k',alpha=.7)ax.set_axisbelow(True)ax.set_xlim((0, 2.0))ax.set_ylim((0, 2.0))ax.set_xticks(np.arange(0, 2.2, step=0.2))ax.set_yticks(np.arange(0, 2.2, step=0.2))#设置刻度间隔# x_major_locator=MultipleLocator(.5)# #把x轴的刻度间隔设置为.5,并存在变量里# y_major_locator=MultipleLocator(.5)# ax.xaxis.set_major_locator(x_major_locator)# #把x轴的主刻度设置为.5的倍数# ax.yaxis.set_major_locator(y_major_locator)for spine in ['top','left','right']:ax.spines[spine].set_visible(None)ax.spines['bottom'].set_color('k')ax.tick_params(bottom=True,direction='out',labelsize=14,width=1.5,length=4,left=False)#ax.tick_params()#添加题目titlefontdict = {"size":20,"color":"k",}ax.set_title('Scatter plot of True data and Model Estimated',titlefontdict,pad=20)#ax.set_title()fontdict = {"size":16,"color":"k",'weight':'bold'}ax.text(0.1,1.8,r'$R^2=$'+str(round(C,3)),fontdict=fontdict)ax.text(0.1,1.6,"RMSE="+str(rmse),fontdict=fontdict)ax.text(0.1,1.4,r'$y=$'+str(round(A1,3))+'$x$'+" + "+str(round(B1,3)),fontdict=fontdict)ax.text(0.1,1.2,r'$N=$'+ str(N),fontdict=fontdict)#添加上下线的统计个数text_font = {'size':'15','weight':'medium','color':'black'}label_font = {'size':'22','weight':'medium','color':'black'}ax.text(.9,.9,"(a)",transform = ax.transAxes,fontdict=text_font,zorder=4)ax.text(.7,.25,s='Within EE = ' + '{:.0%}'.format(bottom_top_counts/all_data),transform = ax.transAxes,ha='left', va='center',fontdict=text_font)ax.text(.7,.18,s='Above EE = ' + '{:.0%}'.format(top_counts/all_data),transform = ax.transAxes,ha='left', va='center',fontdict=text_font)ax.text(.7,.11,s='Below EE = ' + '{:.0%}'.format(bottom_counts/all_data),transform = ax.transAxes,ha='left', va='center',fontdict=text_font)ax.text(.8,.056,'\nVisualization by DataCharm',transform = ax.transAxes,ha='center', va='center',fontsize = 10,color='black')# plt.savefig(r'E:\Data_resourses\DataCharm 公众号\Python\学术图表绘制\scatter_EE.png',# width=7,height=4,dpi=900,bbox_inches='tight')plt.show()
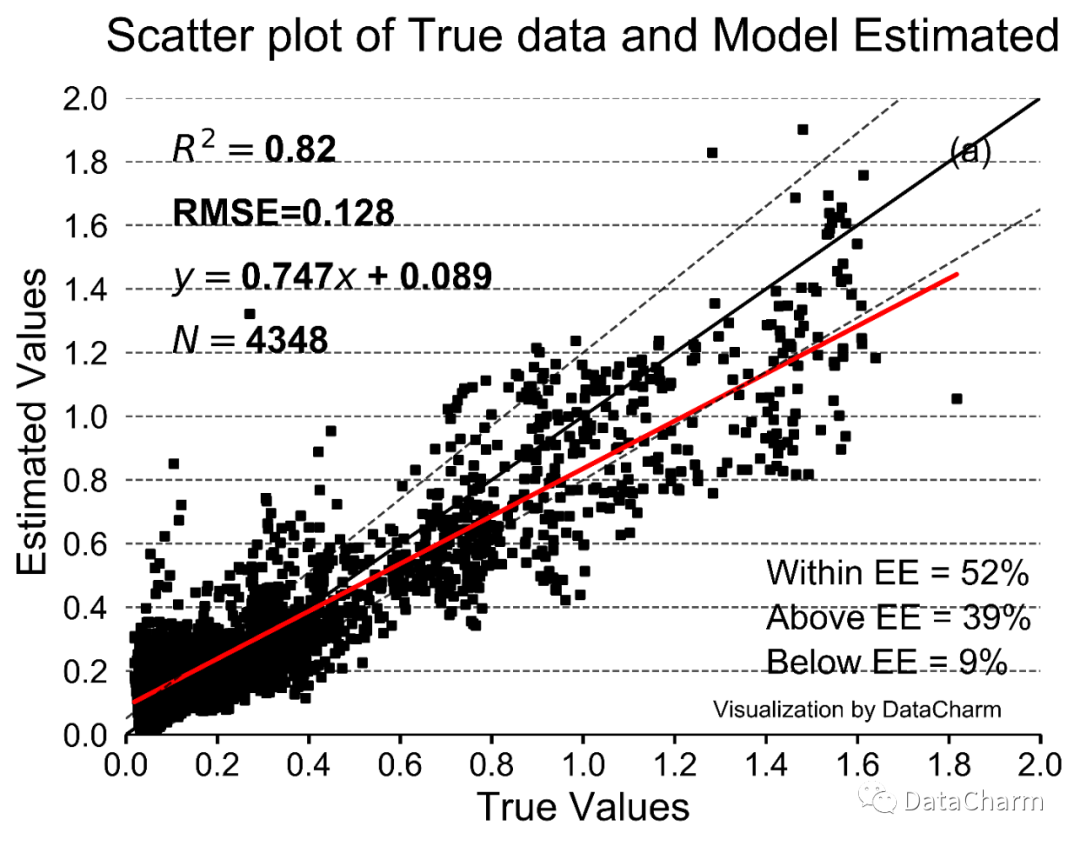
04. 总结
近期文章
Python网络爬虫与文本数据分析 rpy2库 | 在jupyter中调用R语言代码 tidytext | 耳目一新的R-style文本分析库 reticulate包 | 在Rmarkdown中调用Python代码 plydata库 | 数据操作管道操作符>> plotnine: Python版的ggplot2作图库 七夕礼物 | 全网最火的钉子绕线图制作教程 读完本文你就了解什么是文本分析 文本分析在经管领域中的应用概述 综述:文本分析在市场营销研究中的应用 plotnine: Python版的ggplot2作图库 小案例: Pandas的apply方法 stylecloud:简洁易用的词云库 用Python绘制近20年地方财政收入变迁史视频 Wow~70G上市公司定期报告数据集 漂亮~pandas可以无缝衔接Bokeh YelpDaset: 酒店管理类数据集10+G
评论
乐普心安宝及心电图机,助力安康市搭建“心电一张网”,打通全域“生命线”!
为持续推动胸痛中心建设,助力全民健康,全面提升心血管疾病等急危重症救治能力水平。4月20日,由安康市卫健委主办、安康市中医医院承办的“第七届心血管汉江学术会议暨安康市胸痛中心大会”在高新国际会议中心顺利举行。市人大常委会主任王彪、市政协副主席唐纹、市政府党组成员刘英华等领导亲临现场,受邀参会的中国科
乐普医疗AI
0
超越原生,散点图实现华夫饼图
之前我们介绍过了如何使用新卡片图实现华夫饼图。参考:超越原生,PowerBI 华夫饼图实现但是利用卡片图实现的华夫饼图有一些缺点,形状之间的大小跟间距不太好把握,而且有时形状大一点的话显示就会不正常,需要做出二次调整。今天给大家介绍一种原生视觉对象生成华夫饼图的更佳方案,既简单又美观。上图是利用散点
PowerBI战友联盟
2
无任务学习及在机器人任务和运动规划中的应用
大数据文摘授权转载自中国人工智能学会作者:张宪琦,范晓鹏摘 要:本文提出了无任务学习的方法,阐述了其与现有方法(包括自监督学习、迁移学习、模仿学习、强化学习)的区别与联系;然后,介绍了无任务学习在机器人任务和运动规划领域的应用,并分析了无任务学习在该领域的优势和主要研究难点。最后,对无任务学习在机器
大数据文摘
0
Nat. Commun. | gLM:基于宏基因组预训练语言模型的基因和蛋白调控及功能预测算法
2024年4月3日,Peter R. Girguis、Sergey Ovchinnikov、Yunha Hwang、Andre L. Cornman和Elizabeth H. Kellogg几人在Nature Communications上发表了一篇题为“Genomic language model
生信宝典
0
AI HBM及半导体耗材新标杆小龙头
公众号改版,及时收到文章推送需要给公众号加星。大家可以点击页面上方蓝色字【京北夜光】,进入公众号首页,点右上角“...”,点下方“设为星标”。坚持复盘总结分享不容易,点右上角点个在看并分享到朋友圈,看完顺手点个点赞和在看,算是个认可,感谢。三超新材今天反弹16个点,一举收复昨天的跌幅。今天就聊聊这个
IT局
10
2024最新Power BI及Tableau分析师招聘
岗位一:Power BI 分析师招聘单位:上海某数据咨询公司招聘岗位:Power BI 分析师岗位级别:初级到中级薪资范围:15到30W/年(不需要所谓纯技术资深专家)数据工程师/分析师工作职责:1、担任甲方客户公司相关数据分析或工程师工作;2、根据客户需求,进行需求评估,给出合理方案,输出需求文档
PowerBI战友联盟
3
腾讯云4月8日故障复盘及情况说明
4月8日15点23分,腾讯云团队收到告警信息,云API服务处于异常状态;随即在腾讯云工单、售后服务群以及微博等渠道开始大量出现腾讯云控制台登录不上的客户反馈。经过故障定位发现,客户登录不上控制台正是由云API异常所导致。云API是云上统一的开放接口集合,客户可以通过API以编程方式管理和操控云端资源
码农编程进阶笔记
10
李航老师的《统计学习方法》第二版的代码实现(Github标星过万!)
李航老师的《统计学习方法》第二版的代码实现更新完毕,本文提供下载。(黄海广)李航老师编写的《统计学习方法》全面系统地介绍了统计学习的主要方法,特别是监督学习方法,包括感知机、k近邻法、朴素贝叶斯法、决策树、逻辑斯谛回归与支持向量机、提升方法、em算法、隐马尔可夫模型和条件随机场等。除第1章概论和最后
机器学习初学者
10