
实践教程 | 轻松入门模型转换和可视化

来源 | CV研习社
编辑 | 极市平台
极市导读
本文给大家介绍一个模型转换格式ONNX和可视化工具Netron。ONNX是微软设计的一种多平台的通用文件格式,帮助算法人员进行模型部署和框架之间相互转换。而Netron是一款老牌的轻量化模型可视化工具,支持多种开源框架,使用上比TensorBoard简单直接。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
1 不同框架模型需要转换吗?
目前开源的深度学习框架有很多,当我们在Github上搜索一个通用网络时,会发现各种各样的版本实现。但是深度学习方法的本质都是分为训练和部署两个环节,如果以目标为导向,我们关注算法部署在哪儿,用什么部署?是x86上采样TensorRT部署还是ARM上采用端框架NCNN运行,又或者采样某个硬件厂商提供的SDK做推理。
假设童鞋A有一个检测任务需要部署在TX2的开发板上,基于TensorFlow框架把yolov5改改,训练得到了一份pb权重,接下来将pb转换成TensorRT使用的uff文件做推理。
如果A将框架换成Pytorch,按照上述流程得到了一份pt的权重,然后调用TensorRT的SDK转换成uff格式,看上去好像也很顺畅没什么问题,它们的区别就在于训练生成的权重文件格式不同,不过反正最终都转换成uff格式。
实际操作中或者部署在其他移动端时,我们会发现瓶颈在于如何才能更友好的将PC端训练的权重文件转换成部署端需要的格式。Nividia的开发板虽然基于CUDA加速,生态链完整,但是对不同的神经网络框架支持的算子力度也有区别,如果训练框架是Pytorch,在TensorRT上部署,如下图所示理论上有三条路(这里Caffe的存在是因为TRT对它的支持更友好,可以根据需求删除):
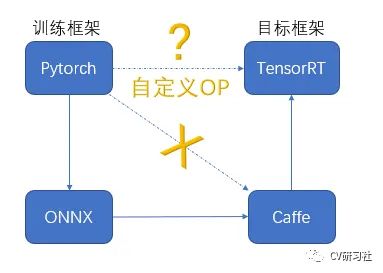
直接调用TRT提供的SDK转换接口,很大可能遇到不支持的操作算子,在Nividia显卡上还能通过CUDA编程自定义算法,换成其他硬件可能直接就不支持自定义功能。
既然直接转换走不通,那么能否将Pytorch先转成Caffe,再由Caffe转到TRT呢?
这条路也存在问题,不同神经网络框架在一些定义上存在差异,比如Pytorch的反卷积自带两次padding;最大池化时Pytorch向下取整,而Caffe向上取整等等。细节上的问题会导致转换后输出不同。
所以我们可以看到图上那条更迂回的路,经过ONNX这个较为通用的格式,因为Pytorch—>ONNX—>Caffe—>TensorRT从部署角度看才更可行。
2 什么是ONNX?
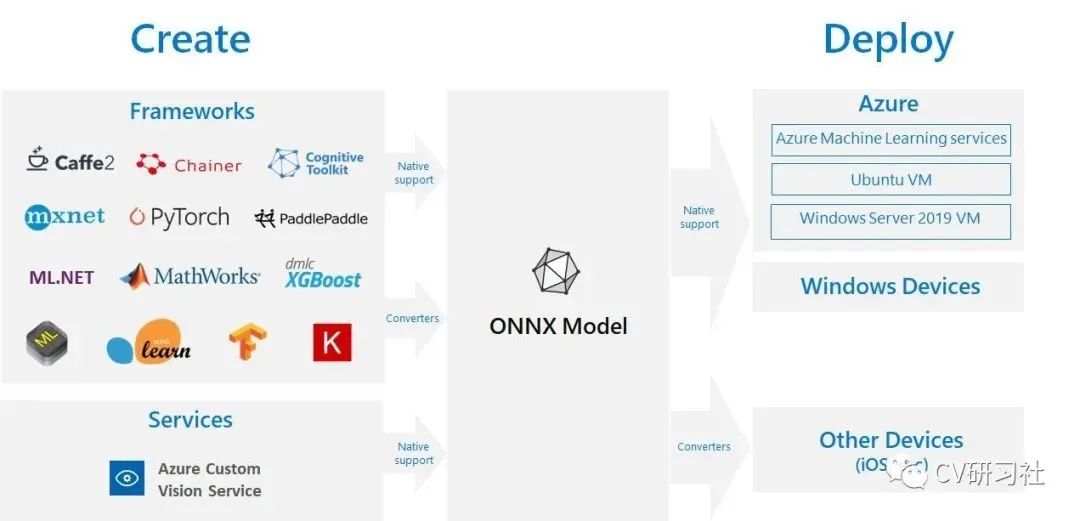
ONNX是一套神经网络模型的开放格式,支持Core ML, PaddlePaddle, SNPE, MXNet, Caffe2, PyTorch, TensorFlow, CNTK 等框架。
ONNX的安装比较简单,在Ubuntu上直接pip install onnx即可,从图上可以看出它是依赖Protobuf库的,因为它内部采用的是Protobuf作为其数据存储和传输。
ONNX是一种可扩展的计算图模型、一系列内置的运算单元和标准数据类型。每一个计算流图都定义为由节点组成的列表,并构建有向无环图。其中每一个节点都有一个或多个输入与输出,每一个节点称之为一个 运算单元。这相当于一种通用的计算图,不同深度学习框架构建的计算图都能转化为它。
为什么要把训练的模型转换成ONNX?
ONNX的作用是在五花八门的训练框架和屈指可数的部署方案之间建立桥梁。它是一个中间环节,方便模型的部署和在各个框架之间转移。
试下如果你电脑上是Tensorflow的环境,却发现最新的开源模型是用Pytorch写的,你想快速测试效果怎么办?
采用TensorFlow重写一遍吗?肯定不行,先不说实现后性能是否一致,单就花费的时间成本就很高。
那么配置一份Pytorch的运行环境跑一下结果?看起来可行,但是下一次是Caffe,CoreML呢?难不成都配置一遍吗!
再想想办法,写个脚本将Pytorch的权重转成TensorFlow的pb文件?好像也可以,但是实际操作下来会发现不同框架直接的直接转换有许多细节上的不统一。
最后大家商量一个共同使用的中间接口过度不就可以了,微软开发的ONNX因此出现了。
还有一种部署的场景是当用某个开源框架训练的模型文件转换到ONNX后,还需要将它再次转换,比如转换到TensorRT后做前向传播。为什么要转换这么多次呢?
我们反过来看就清楚了,目标平台支持哪个框架力度大,我们就通过ONNX做为中转站将当前的框架模型转换到支持算子多的框架,为了让算法在移动端部署成功。
如何转换ONNX?
这里以tensorflow为例,从tf转到onnx还处于实验阶段,我们可以依靠外部工具进行转换。
首先第一步需要安装tf2onnx包,即pip install -U tf2onnx。
然后第二步将ckpt文件冻结成pb文件,这里是因为ckpt和meta文件分别权重信息和拓扑结构分开存储,而且固化到pb中是将变量冻结成常量形式。TensorFlow官方已经提过了相关工具freeze_graph。
最后第三部执行tf2onnx.convert命令,即:
python3 -m tf2onnx.convert --input model.pb --inputs input_name:0[1,640,640,3] --outputs output_name:0 --output model.onnx
其中input_name是网络输入的名称,output_name是网络输出的名称。
3 网络可视化工具
随着深度学习从2016年的爆发到现在已有5年时间,市面上深度学习框架也是百花齐放,有TensorFlow、Caffe、Pytorch、NCNN、CoreML、MXNet、ArmNN等等,再加上各大硬件厂商集成的SDK(SNPE、TIDL、TensorRT等),加起来不少于小几十种。
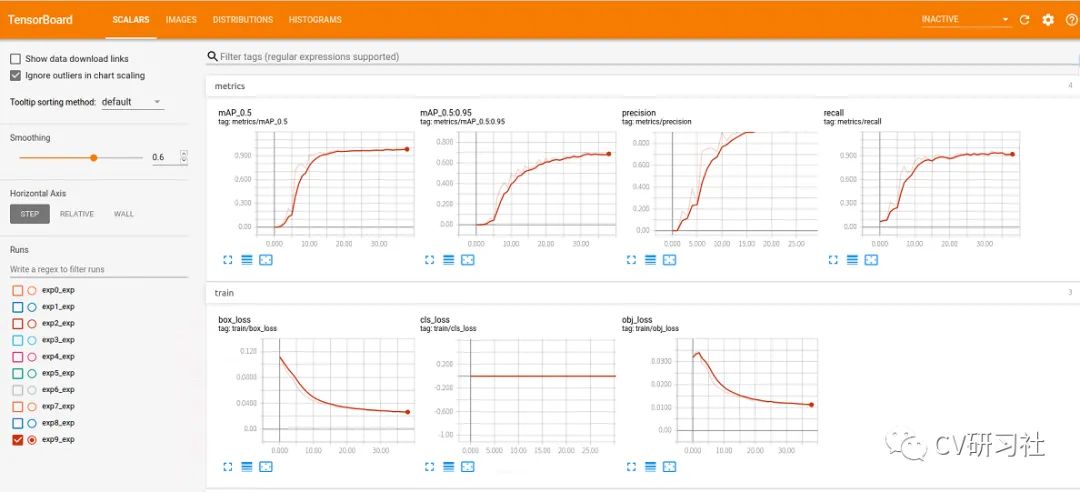
但是好用的模型可视化工具却相对非常较少,其中TensorBoard应该算炼丹师们较为熟悉的一种工具,它能够查看网络结构,损失的变化,准确率指标等变化情况。功能比较全面,界面如下图所示:
TensorBoard安装和使用
TensorBoard是随着TensorFlow一起安装的,这里我们不再啰嗦。使用时分为五步:
指定文件用于保存Tensorboard的图:writer = tf.summary.FileWriter(log_dir=log_dir)
增加需要观测的变量:
tf.summary.histogram('weights',weight)
tf.summary.scalar('loss',loss) ......
合并所有待观察的数据:
merged = tf.summary.merge_all()
运行命令:tensorboard --logdir=./logs
在浏览器输入网址:http://localhost:6006,即可查看生成图和参数
在第2步中,具体TensorBoard可以观察哪些东西呢?
标量Scalars:存储和显示诸如学习率和损失等单个值的变化趋势 图片Images:对于输入是图像的模型,显示某一步输入给模型的图像 计算图Graph:显示代码中定义的计算图,也可以显示包括每个节点的计算时间、内存使用等情况 数据分布Distribution:显示模型参数随迭代次数的变化情况 直方图Histograms:显示模型参数随迭代次数的变化情况 嵌入向量Embeddings:在3D或者2D图中展示高维数据
下面我们再推荐另一款轻量级的可视化工具Netron。
Netron安装和使用
Netron支持两种方式打开,其一是浏览器访问,无需任何安装。登录IP地址:https://netron.app/

点击Open Model选中你要可视化的模型格式,即可看到如下界面:
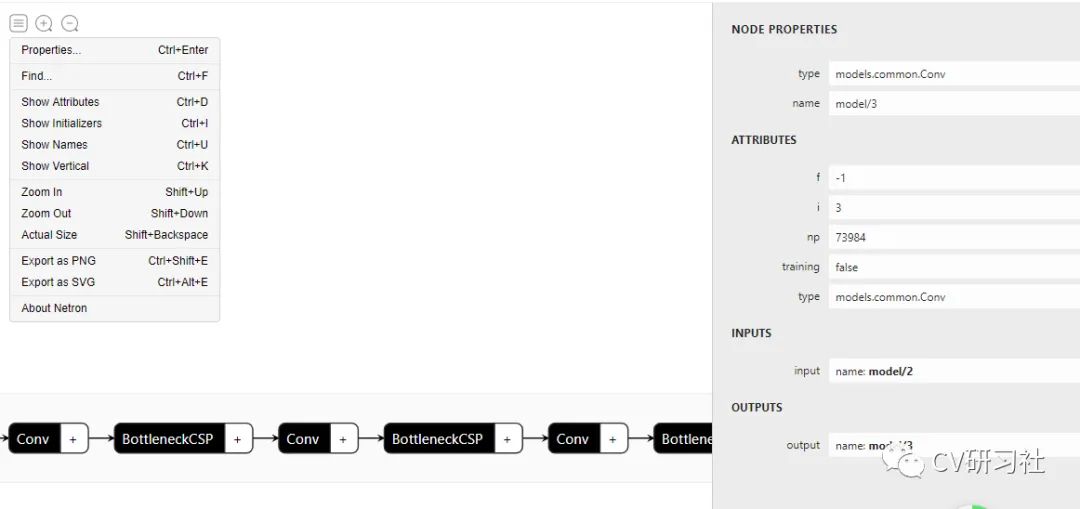
图中可以看到中间区域是网络结构的描述,左侧是菜单栏,可选择显示节点属性、名称等功能,右侧是选中的节点特性,包括类型、名称、输入、输出等。
另一种打开方式需要进行软件安装,不同操作系统安装方式不同,官网上有各个操作系统下的软件包链接:

客户端模式下加载权重文件,感觉比浏览器版本更清晰一些:
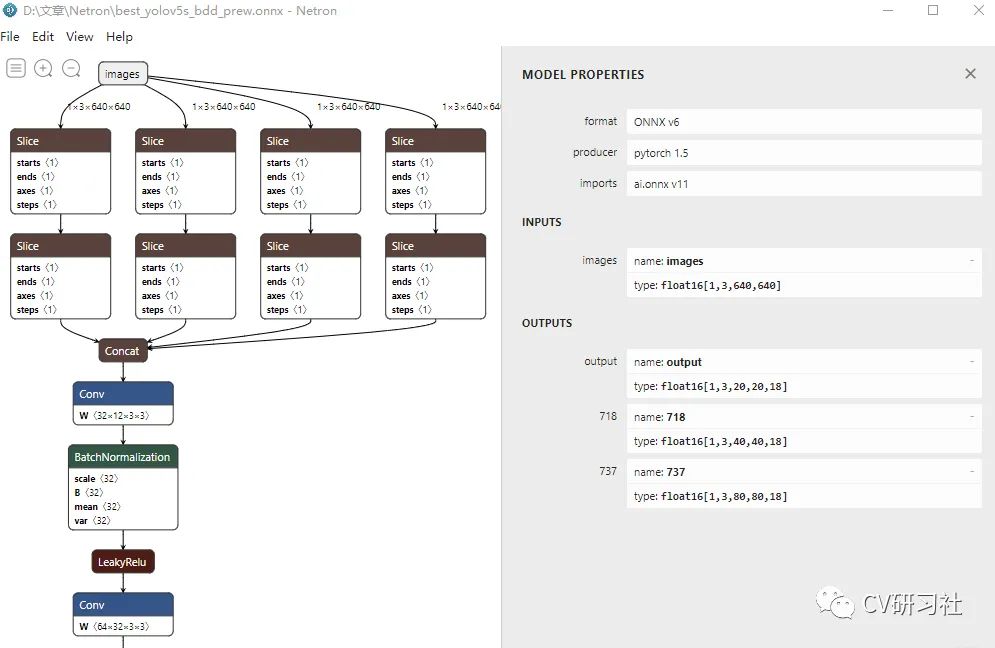
Netron支持的框架
Netron目前支持的框架有:
Keras的h5文件 Caffe的caffemodel和prototxt文件 TensorFlow Lite的tflite文件 ONNX的onnx文件 Core ML的mlmodel文件 NCNN的param文件
还有一些处于实验阶段,还不够稳定,如:
Pytorch的pt文件 TensorFlow的pb、ckpt文件 CNTK的model、cntk文件 Arm NN的armnn文件 Scikit-learn的pkl文件 Deeplearning4j的zip文件
从使用角度来说,Netron更适合在拿到一份陌生的网络时查看其结构;而TensorBoard更适合在训练的过程中实时关注训练参数的变化,以便及时作出调整。
如果觉得有用,就请分享到朋友圈吧!
公众号后台回复“CVPR21检测”获取CVPR2021目标检测论文下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
