
TensorFlow和Keras入门必读教程
导读:本文对TensorFlow的框架和基本示例进行简要介绍。

01 TensorFlow
TensorFlow最初由Google开发,旨在让研究人员和开发人员进行机器学习研究。它最初被定义为描述机器学习算法的接口,以及执行该算法的实现。
TensorFlow的主要预期目标是简化机器学习解决方案在各种平台上的部署,如计算机CPU、计算机GPU、移动设备以及最近的浏览器中的部署。最重要的是,TensorFlow提供了许多有用的功能来创建机器学习模型并大规模运行它们。TensorFlow 2于2019年发布,它专注于易用性,并能保持良好的性能。
这个库于2015年11月开源。从那时起,它已被世界各地的用户改进和使用。它被认为是开展研究的首选平台之一。就GitHub活跃度而言,它也是最活跃的深度学习框架之一。
TensorFlow既可供初学者使用,也可供专家使用。TensorFlow API具有不同级别的复杂度,从而使初学者可以从简单的API开始,同时也可以让专家创建非常复杂的模型。我们来探索一下这些不同级别的模型。
1. TensorFlow主要架构
TensorFlow架构(见图2-1)具有多个抽象层级。我们首先介绍底层,然后逐渐通往最上层。
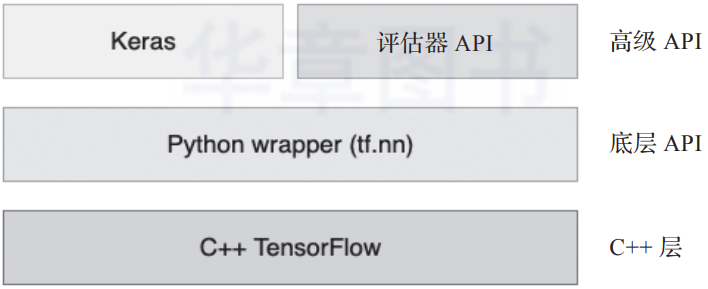
▲图2-1 TensorFlow架构图
大多数深度学习计算都是用C++编码的。为了在GPU上进行运算,TensorFlow使用了由NVIDIA开发的库CUDA。这就是如果想要利用GPU功能就需要安装CUDA,以及不能使用其他硬件制造商GPU的原因。
然后,Python底层API(low-level API)封装了C++源代码。当调用TensorFlow的Python方法时,通常会在后台调用C++代码。这个封装层使用户可以更快地工作,因为Python被认为更易于使用并且不需要编译。该Python封装器可以创建非常基本的运算,例如矩阵乘法和加法。
最上层是高级API(high-level API),由Keras和评估器API(estimator API)两个组件组成。Keras是TensorFlow的一个用户友好型、模块化且可扩展的封装器,评估器API包含多个预制组件,可让你轻松地构建机器学习模型。你可以将它们视为构建块或模板。
tip:在深度学习中,模型通常是指经过数据训练的神经网络。模型由架构、矩阵权重和参数组成。
2. Keras介绍
Keras于2015年首次发布,它被设计为一种接口,可用于使用神经网络进行快速实验。因此,它依赖TensorFlow或Theano(另一个深度学习框架,现已弃用)来运行深度学习操作。Keras以其用户友好性著称,是初学者的首选库。
自2017年以来,TensorFlow完全集成了Keras,这意味着无须安装TensorFlow以外的任何库就可使用它。我们将依赖tf.keras而不是Keras的独立版本。这两个版本之间有一些细微的差异,例如与TensorFlow的其他模块的兼容性以及模型的保存方式。因此,读者必须确保使用正确的版本,具体方法如下:
在代码中,导入tf.keras而不是keras。
浏览TensorFlow网站上的tf.keras文档,而不是keras.io文档。
在使用外部Keras库时,请确保它们与tf.keras兼容。
某些保存的模型在Keras版本之间可能不兼容。
这两个版本在可预见的未来将继续共存,而tf.keras与TensorFlow集成将越来越密切。为了说明Keras的强大功能和简单性,我们将使用该库实现一个简单的神经网络。
02 基于Keras的简单计算机视觉模型
在深入探讨TensorFlow的核心概念之前,我们先从一个计算机视觉的经典示例开始,它使用数据集MNIST进行数字识别。
1. 准备数据
首先,导入数据。它由用于训练集的60 000幅图像和用于测试集的10 000幅图像组成:
import tensorflow as tf
num_classes = 10
img_rows, img_cols = 28, 28
num_channels = 1
input_shape = (img_rows, img_cols, num_channels)
(x_train, y_train),(x_test, y_test) = tf.keras.datasets.mnist.load_data()
x_train, x_test = x_train / 255.0, x_test / 255.0
tip:常见的做法是使用别名tf来导入TensorFlow,从而加快读取和键入速度。通常用x表示输入数据,用y表示标签。
tf.keras.datasets模块提供快速访问,以下载和实例化一些经典数据集。使用load_data导入数据后,请注意,我们将数组除以255.0,得到的数字范围为[0, 1]而不是[0, 255]。将数据归一化在[0, 1]范围或[-1, 1]范围是一种常见的做法。
2. 构建模型
现在,我们可以继续构建实际模型。我们将使用一个非常简单的架构,该架构由两个全连接层(也称为稠密层)组成。在详细介绍架构之前,我们来看一下代码。可以看到,Keras代码非常简洁:
model = tf.keras.models.Sequential()
model.add(tf.keras.layers.Flatten())
model.add(tf.keras.layers.Dense(128, activation='relu'))
model.add(tf.keras.layers.Dense(num_classes, activation='softmax'))
由于模型是层的线性堆栈,因此我们首先调用Sequential函数。然后,依次添加每一层。模型由两个全连接层组成。我们逐层构建:
展平层(Flatten):它将接受表示图像像素的二维矩阵,并将其转换为一维数组。我们需要在添加全连接层之前执行此操作。28×28的图像被转换为大小为784的向量。
大小为128的稠密层(Dense):它使用大小为128×784的权重矩阵和大小为128的偏置矩阵,将784个像素值转换为128个激活值。这意味着有100 480个参数。
大小为10的稠密层(Dense):它将把128个激活值转变为最终预测。注意,因为概率总和为1,所以我们将使用softmax激活函数。
tip:softmax函数获取某层的输出,并返回总和为1的概率。它是分类模型最后一层的选择的激活函数。
请注意,使用model.summary()可以获得有关模型、输出及其权重的描述。下面是输出:

设置好架构并初始化权重后,模型现在就可以针对所选任务进行训练了。
3. 训练模型
Keras让训练变得非常简单:
model.compile(optimizer='sgd',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
callbacks = [tf.keras.callbacks.TensorBoard('./keras')]
model.fit(x_train, y_train, epochs=25, verbose=1, validation_data=(x_test, y_test), callbacks=callbacks)
在刚刚创建的模型上调用.compile()是一个必需的步骤。必须指定几个参数:
优化器(optimizer):运行梯度下降的组件。
损失(loss):优化的指标。在本例中,选择交叉熵,就像上一章一样。
评估指标(metrics):在训练过程进行评估的附加评估函数,以进一步查看有关模型性能(与损失不同,它们不在优化过程中使用)。
名为sparse_categorical_crossentropy的Keras损失执行与categorical_crossentropy相同的交叉熵运算,但是前者直接将真值标签作为输入,而后者则要求真值标签先变成独热(one-hot)编码。因此,使用sparse_...损失可以免于手动转换标签的麻烦。
tip:将'sgd'传递给Keras等同于传递tf.keras.optimizers.SGD()。前一个选项更易于阅读,而后一个选项则可以指定参数,如自定义学习率。传递给Keras方法的损失、评估指标和大多数参数也是如此。
然后,我们调用.fit()方法。它与另一个流行的机器学习库scikit-learn中所使用的接口非常相似。我们将训练5轮,这意味着将对整个训练数据集进行5次迭代。
请注意,我们将verbose设置为1。这将让我们获得一个进度条,其中包含先前选择的指标、损失和预计完成时间(Estimated Time of Arrival,ETA)。ETA是对轮次结束之前剩余时间的估计。进度条如图2-2所示。

▲图2-2 Keras在详细模式下显示的进度条屏幕截图
4. 模型性能
如第1章中所述,你会注意到模型是过拟合的——即训练准确率大于测试准确率。如果对模型训练5轮,则最终在测试集上的准确率为97%。这比上一章(95%)高了约2个百分点。最先进的算法可达到99.79%的准确率。
我们遵循了三个主要步骤:
加载数据:在本例中,数据集已经可用。在未来的项目中,你可能需要其他的步骤来收集和清理数据。
创建模型:使用Keras可以让这一步骤变得容易——按顺序添加层即可定义模型的架构。然后,选择损失、优化器和评估指标进行监控。
训练模型:模型第一次运行效果很好。在更复杂的数据集上,通常需要在训练过程中微调参数。
借助TensorFlow的高级API——Keras,整个过程非常简单。在这个简单API的背后,该库隐藏了很多复杂操作。


干货直达👇