【教程】Python数据可视化入门
大家好
我早期入门数据分析的时候曾对数据可视化比较痴迷,积累了很多文档、代码、图例,最近花了点时间重新整理了一遍。发现之前还真是写了很多东西,现在看来都是极简单和入门,有点不值一提。
但不知道有没有刚入门的同学恰好需要,先看下主要内容吧:
基础的散点图、折线图、柱状图、直方图、饼图、箱线图 配合实例的探索性数据分析常用图表 漏斗图、词云图、动态排序图、R风格图、交互式图、南丁格尔玫瑰图、缺失值矩阵图、漫画风格图、桑吉图、和弦图、饼树图 也有一些图没有写文档,只保留了代码,比如气泡图、山峦叠嶂图、甘特图、极坐标图 中间也涉及Matplotlib、Seaborn、Bokeh、plotly、Chartify等绘图库的入门
配套的数据集、代码、文档和示例图很完整(付费读者文末可下载),2万余字,100余张示例图。
定价29元,感兴趣的同学支持一波吧。
想白嫖的同学,可以在本公众号挨个搜索关键词,其实大部分都有写过免费文章,只是没有本文整理的完善,代码可能也不完整,不影响学习。
正文:
探索性数据分析常用图表
探索性数据分析(EDA)阶段为机器学习项目中至关重要的环节,我们以广告渠道对销量的影响数据集为例,即电视广告(TV),报纸广告(Newspaper),和广播广告(Radio)对于产品销量的影响。一个公司同时通过这三种广告媒介进行宣传,在不同的广告预算下,产品销量也不同。我们希望通过数据分析了解不同的广告渠道对销量有什么影响,并最大化广告对于销量的增益。本节,我们用可视化的方式,对数据集做个探索性数据分析。
导入库&数据
# -*- coding: utf-8 -*-
# 导入库
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
# 导入数据
df=pd.read_csv('..\Advertising.csv')
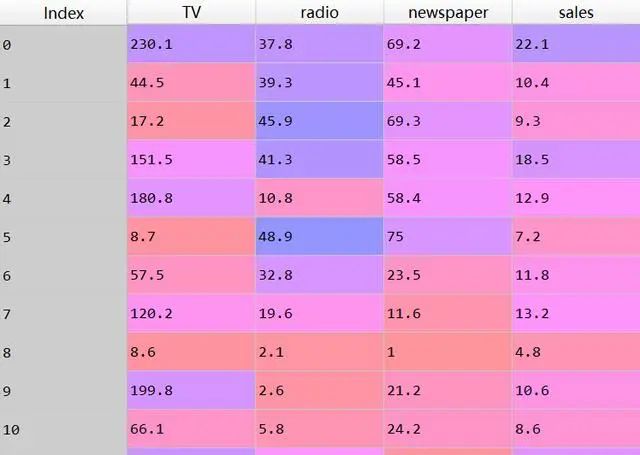
数据分布
先看一下数据分布情况
df.hist(xlabelsize=10,ylabelsize=10,figsize=(16,12))
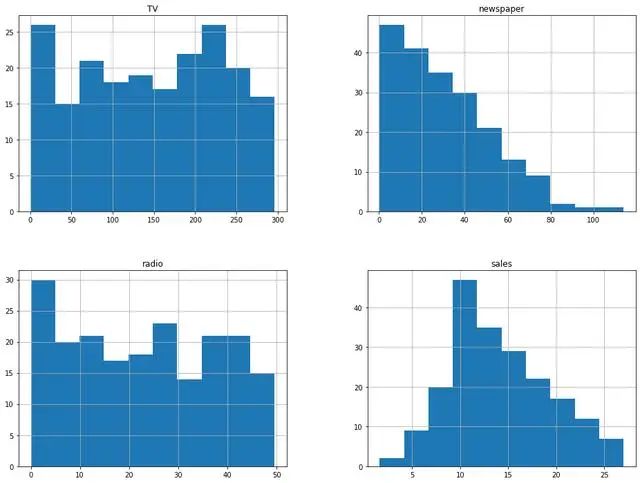
箱形图
箱形图(Box-plot)又称为盒须图、盒式图或箱线图,是一种用作显示一组数据分散情况资料的统计图。它主要用于反映原始数据分布的特征,还可以进行多组数据分布特征的比 较。箱线图的绘制方法是:先找出一组数据的上边缘、下边缘、中位数和两个四分位数;然后, 连接两个四分位数画出箱体;再将上边缘和下边缘与箱体相连接,中位数在箱体中间。
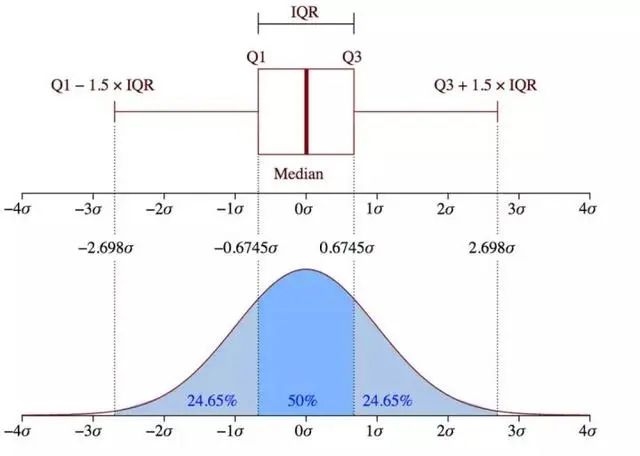
四分位距(IQR)就是上四分位与下四分位的差值。而我们通过IQR的1.5倍为标准,规定:超过(上四分位+1.5倍IQR距离,或者下四分位-1.5倍IQR距离)的点为异常值。
plt.subplots(figsize=(15,10)) sns.boxplot(data=df)
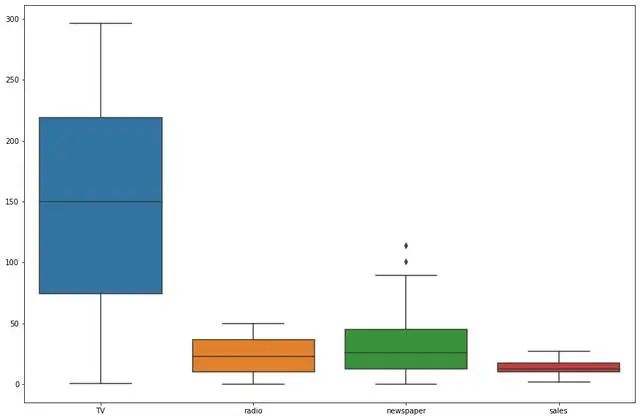
可以看出newspaper是存在异常值,异常值处理可以用missinggo处理,之后会讲,这里就不讲了。
矩阵图
矩阵图法就是从多维问题的事件中,找出成对的因素,排列成矩阵图,然后根据矩阵图来分析问题,确定关键点的方法。它是一种通过多因素综合思考,探索问题的好方法。从问题事项中找出成对的因素群,分别排列成行和列,找出其中行与列的相关性或相关程度大小的一种方法。
sns.pairplot(df, kind="reg")
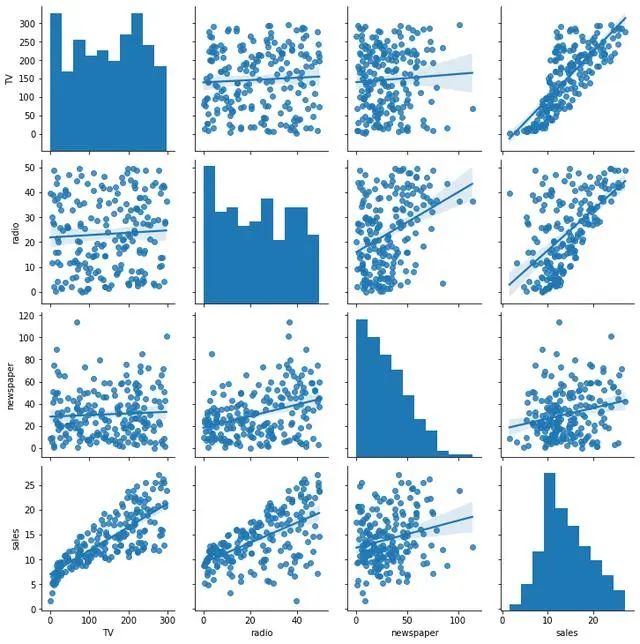
相关图
相关图是研究相关关系的直观工具。一般在进行详细的定量分析之前,可利用相关图对现象之间存在的相关关系的方向、形式和密切程度进行大致的判断。变量之间的相关关系可以简单分为四种表现形式,分别有:正线性相关、负线性相关、非线性相关和不相关,从图形上各点的分散程度即可判断两变量间关系的密切程度。
plt.subplots(figsize=(15,10))
sns.heatmap(df.corr(), xticklabels=df.corr().columns, yticklabels=df.corr().columns, cmap='RdYlGn', center=0, annot=True)
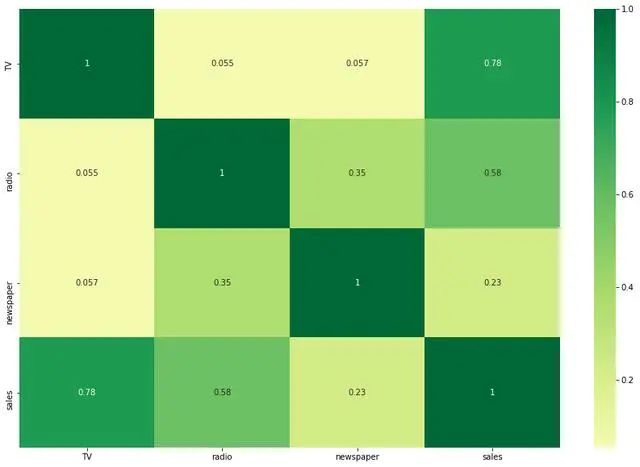
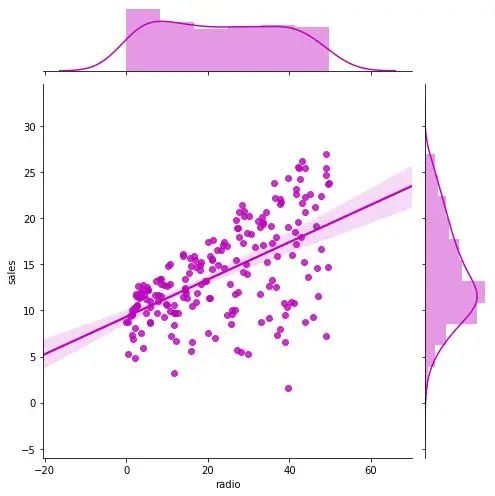
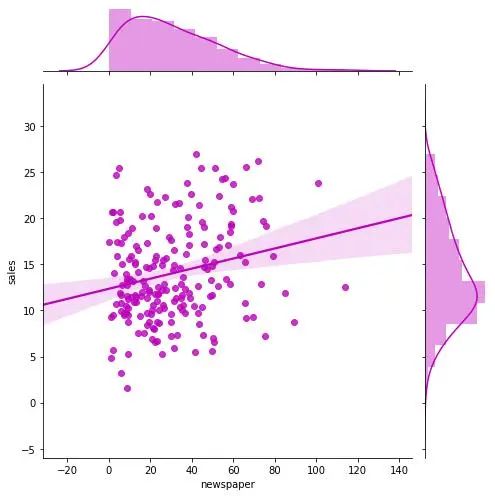
带线性回归最佳拟合线的散点图
如果你想了解两个变量如何相互改变,那么最佳拟合线就是常用的方法。我在图中还加入了 沿 X 和 Y 轴变量的边缘直方图,用于可视化 X 和 Y 之间的关系以及单独的 X 和 Y 的单变量分布。
g_TV = sns.jointplot("TV", "sales", data=df,
kind="reg", truncate=False,
color="m", height=7)
g_radio = sns.jointplot("radio", "sales", data=df,
kind="reg", truncate=False,
color="m", height=7)
g_newspaper = sns.jointplot("newspaper", "sales", data=df,
kind="reg", truncate=False,
color="m", height=7)
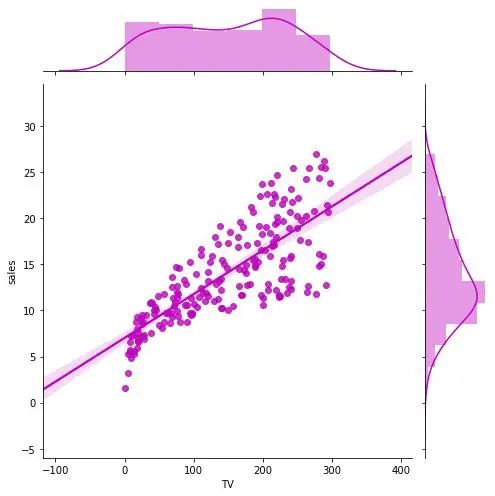
重温探索性数据分析
探索性数据分析是进行建模分析之前的相当关键的步骤,它是帮助大家熟悉数据并且探索数据的过程。在EDA的过程中,你能探索到越多的数据特性,在建模的过程中就越高效。
我们以UCI机器学习库中「银行营销数据集」为例,根据相关的信息预测通过电话推销,用户是否会在银行进行存款。我们用可视化的方式,认识一下几个重要特征。
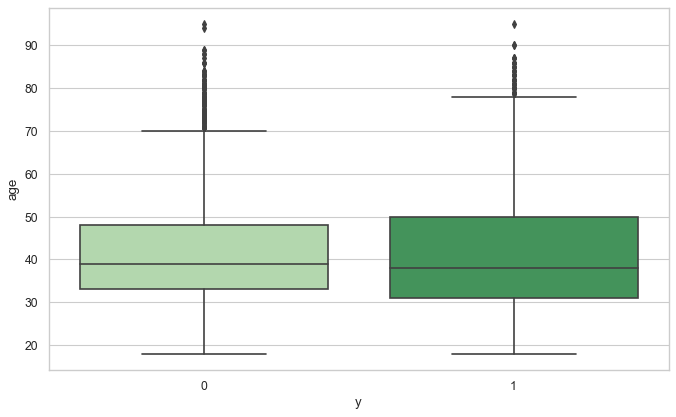
数值型的特征可以用箱型图查看其分布情况,这样也可以查找异常值。
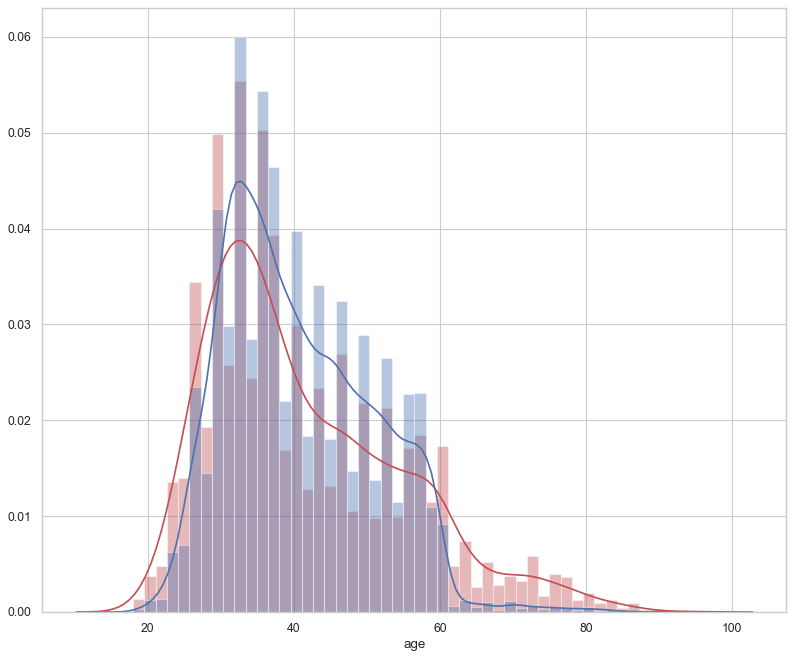
 概率密度图也是不错的选择
概率密度图也是不错的选择
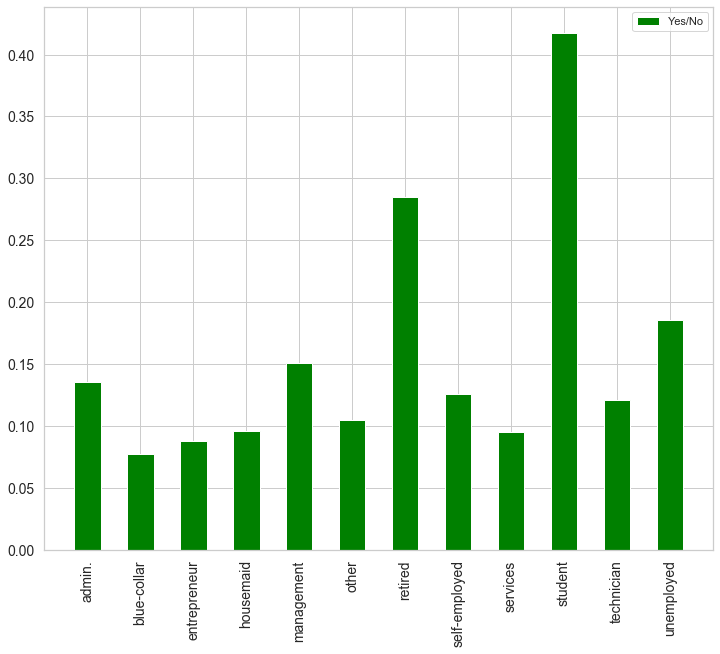
 分类型数据的分布情况探查主要是查看各个分类值出现的频次及趋势,可以用柱状图直观展示。
分类型数据的分布情况探查主要是查看各个分类值出现的频次及趋势,可以用柱状图直观展示。
如果要同时观察多个变量之间的相互关系,比较常用的就是seaborn中的pairplot方法。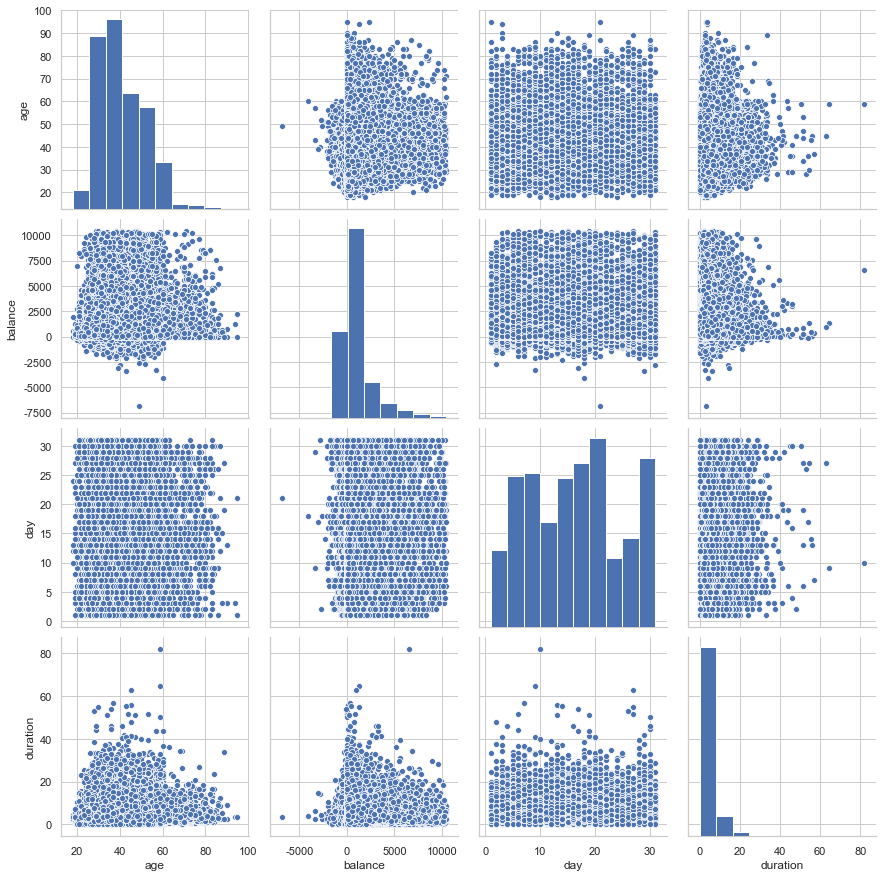
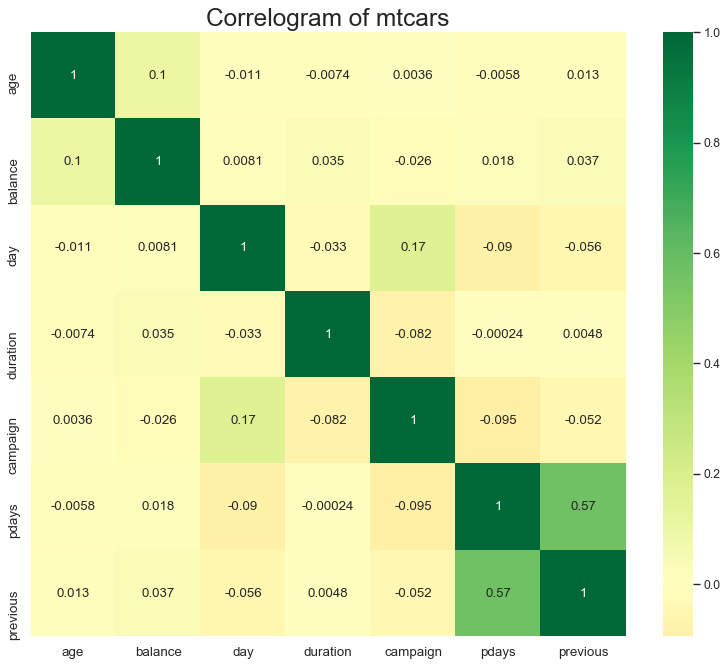
想要具体查看多个联系性特征之间的相关系数,heatmap是个不错的选择。
特征深入研究
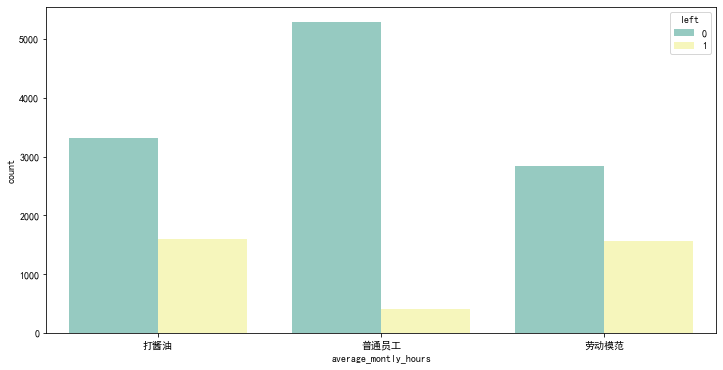
这一部分我使用了员工离职数据集,数据主要包括影响员工离职的各种因素(工资、绩效、工作满意度、参加项目数、工作时长、是否升职等)以及员工是否已经离职的对应记录。我们需要分析这14999个样本以及10个特征, 通过现有员工已经是否离职的数据, 寻找员工离职原因。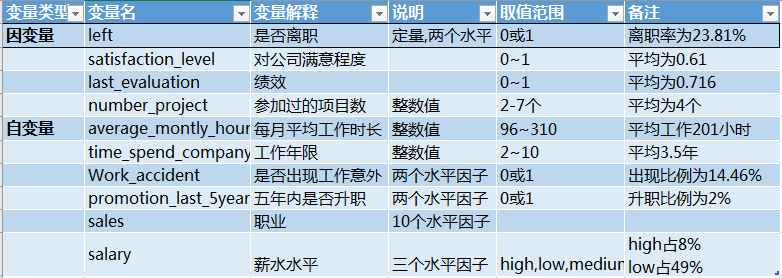
大家可以猜一下,以下几个特征的可视化是用什么方法实现的?
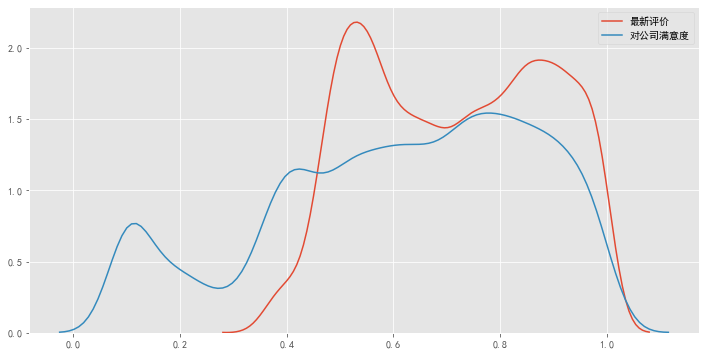
数据特征分析:对公司的满意度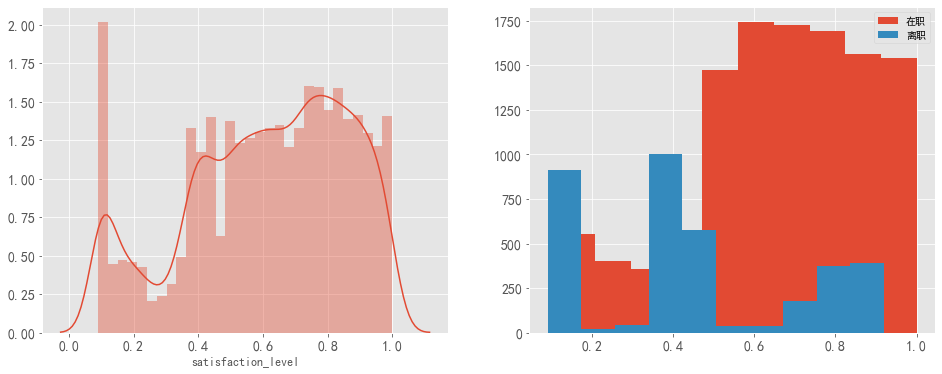
数据特征分析:最新考核评估
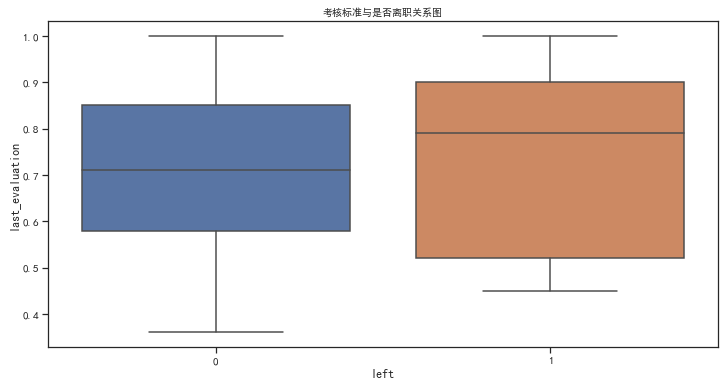
数据特征分析:工作年限、每月平均工作时长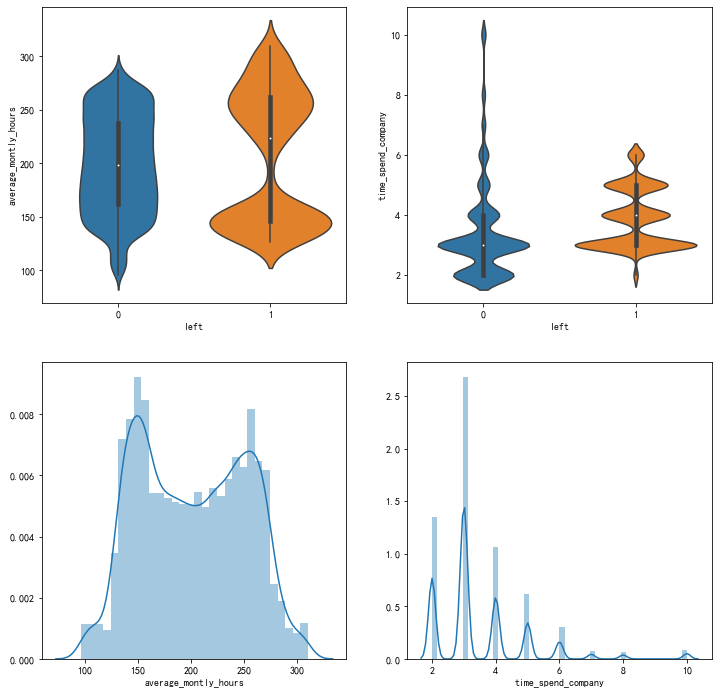
数据特征分析:工作事故、五年内是否升职、工资水平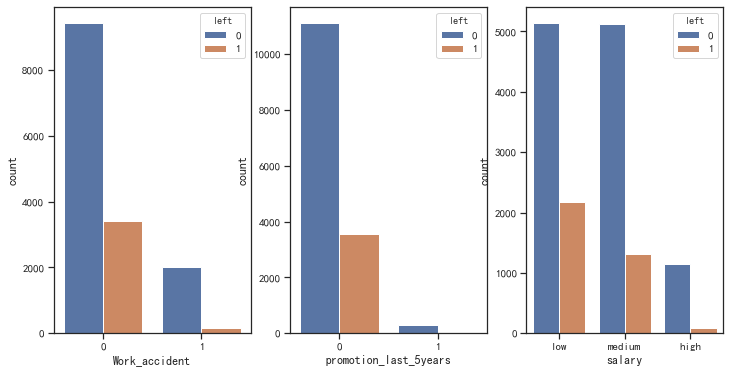
数据变换、数据标准化、特征离散
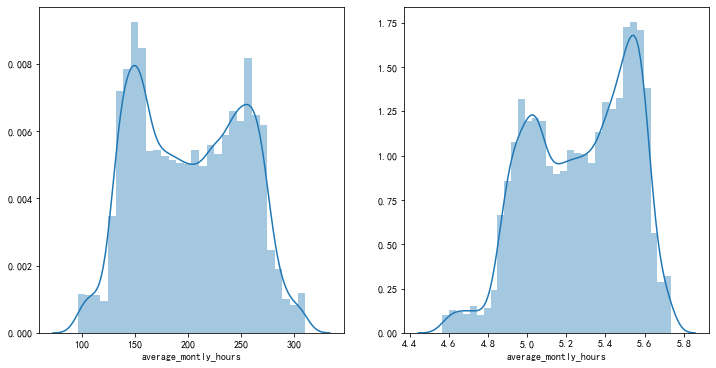
数据可视化还可以用于观察数据变换的前后对比,这里我依然使用员工离职数据集。
数据log变换的可视化
数据标准化的可视化
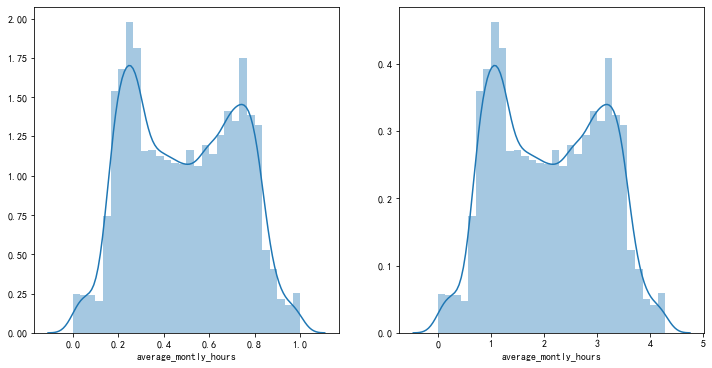
特征离散化的可视化
matplotlib、seaborn、pyecharts、Altair分别绘制柱状图。
导入库&数据
# 引入模块
import numpy as np
import pandas as pd
import altair as alt
import plotly.express as px
import matplotlib.pyplot as plt
## 导入数据
path=r"...\datasets\海外疫情数据.csv"
df = pd.read_csv(path,encoding='utf-8',header=0)
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显负数
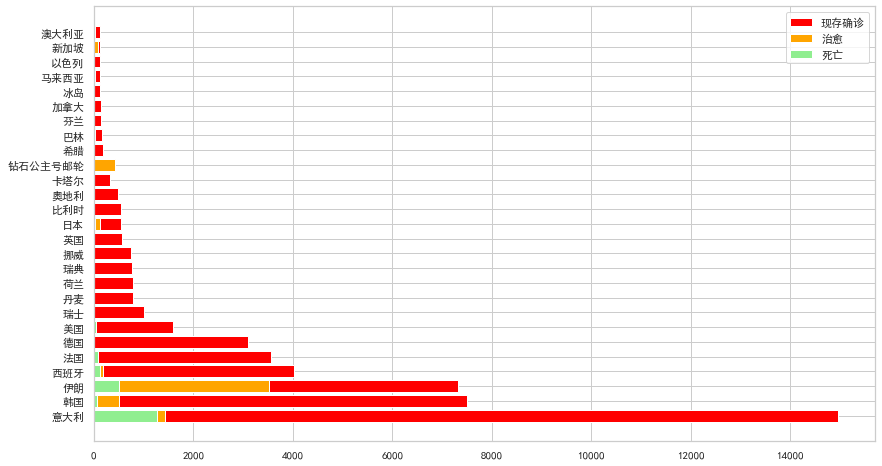
我们使用的是海外国家新冠肺炎疫情数据,包括了现存确诊、累计确诊、治愈、死亡数据。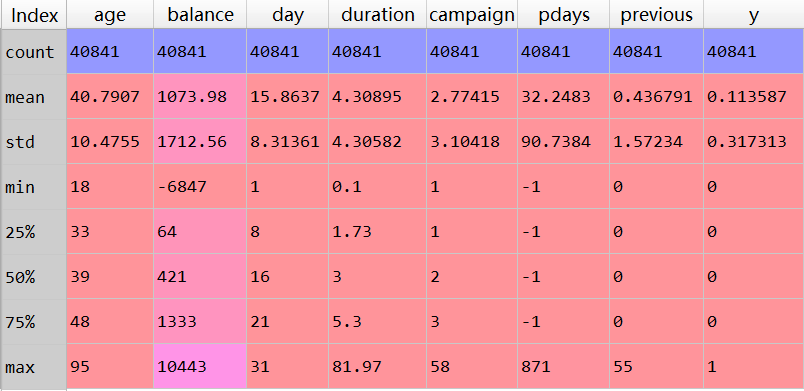
matplotlib
Matplotlib就不用多介绍了,使用最频繁的Python可视化库库。
fig, ax = plt.subplots(figsize=(14,8))
ax.barh( df.国家,df.现存确诊,label="现存确诊", color='red')
ax.barh( df.国家,df.治愈,label="治愈", color='orange')
ax.barh( df.国家,df.死亡,label="死亡", color='lightgreen')
plt.legend(loc="upper right")
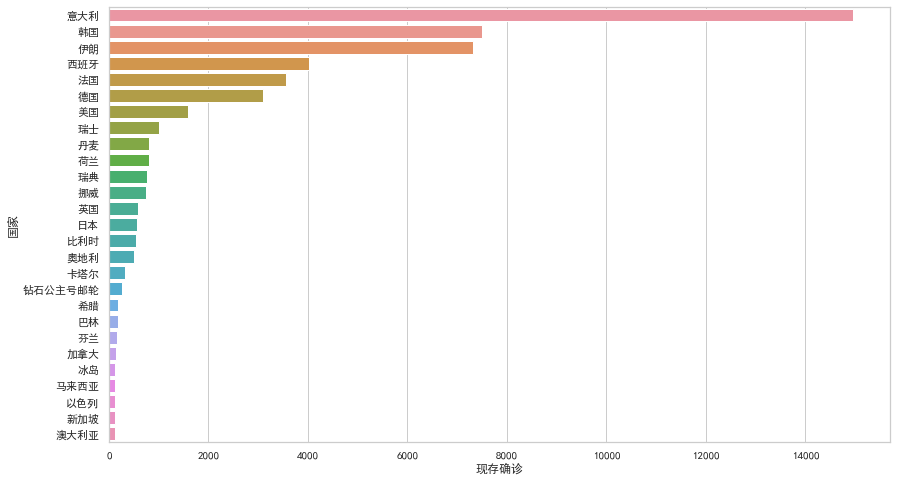
Seaborn
Seaborn利用matplotlib的强大功能,可以只用几行代码就创建漂亮的图表。关键区别在于Seaborn的默认款式和调色板设计更加美观和现代。由于Seaborn是在matplotlib之上构建的,因此还需要了解matplotlib以便调整Seaborn的默认值。
plt.figure(figsize=(14,8))
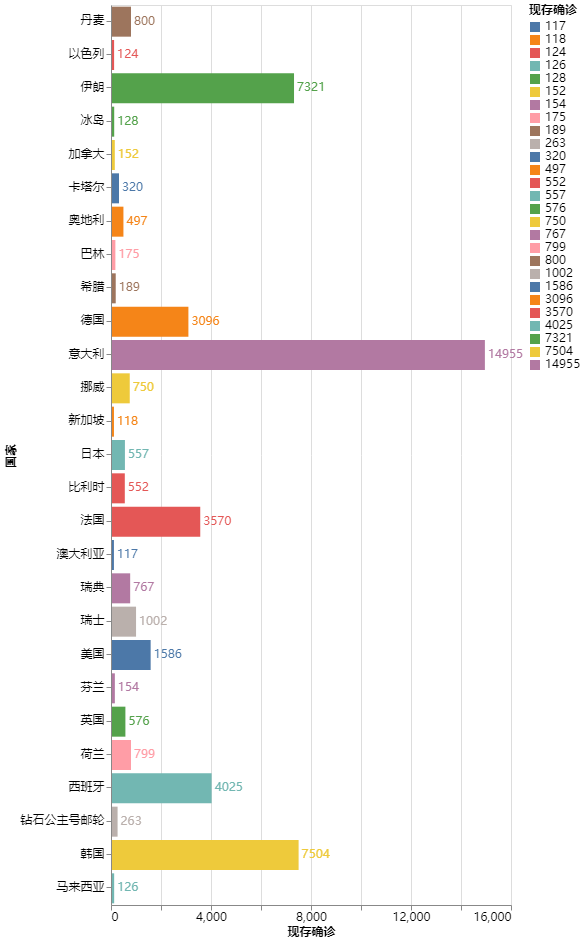
ax = sns.barplot(x="现存确诊", y="国家", data=df)
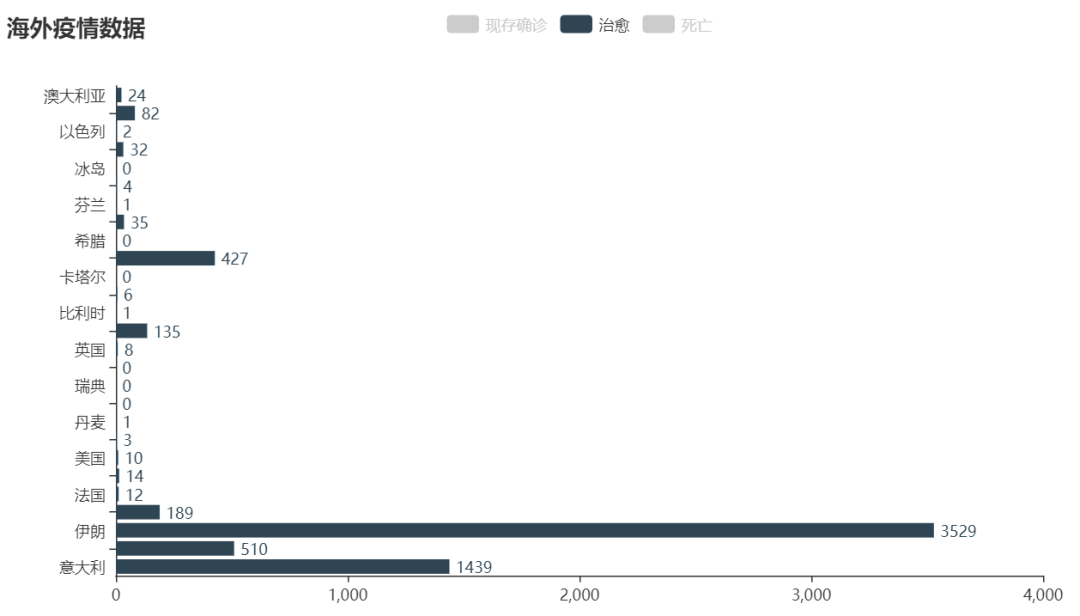
pyecharts
pyecharts 是一个用于生成 Echarts 图表的类库。Echarts 是百度开源的一个数据可视化 JS 库。用 Echarts 生成的图可视化效果非常棒。
Altair
Altair是一个基于 Vega-lite 的声明性统计(declarative statistical)可视化python库。声明意味着只需要提供数据列与编码通道之间的链接,例如x轴,y轴,颜色等,其余的绘图细节它会自动处理。声明使Altair变得简单,友好和一致。使用Altair可以轻松设计出有效且美观的可视化代码。
普通散点图
散点图是用于研究两个变量之间关系的经典的和基本的图表。 如果数据中有多个组,则可能需要以不同颜色可视化每个组。
今天我们画普通散点图、边际分布线性回归散点图、散点图矩阵、带线性回归最佳拟合线的散点图。
在 matplotlib 中,可以使用 plt.scatterplot() 方便地执行此操作。
import matplotlib.pyplot as plt
import numpy as np
N = 10
x = np.random.rand(N)
y = np.random.rand(N)
plt.scatter(x, y)
plt.show()
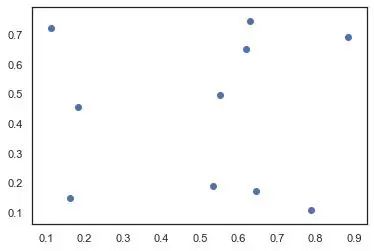
matplotlib散点图升级版
散点的大小、形状、颜色和透明度都是可以修改的,来看一个升级版。
import numpy as np
import matplotlib.pyplot as plt
# Fixing random state for reproducibility
np.random.seed(19680801)
N = 50
x = np.random.rand(N)
y = np.random.rand(N)
colors = np.random.rand(N)
area = (30 * np.random.rand(N))**2 # 0 to 15 point radii
plt.scatter(x, y, s=area, c=colors, alpha=0.5)
plt.show()
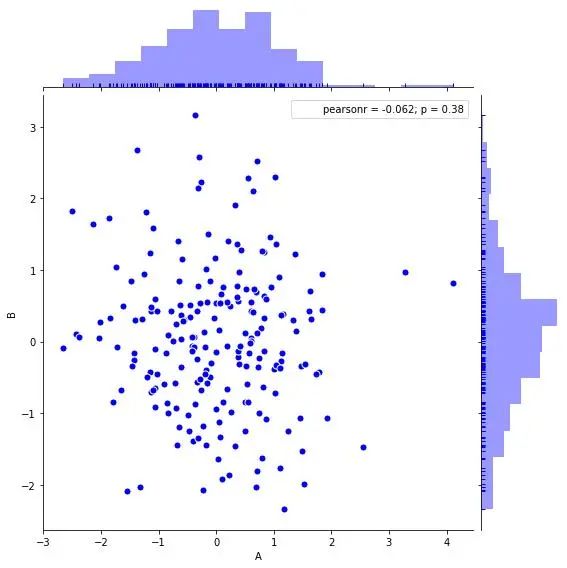
Seaborn散点图 + 分布图
#创建数据
rs = np.random.RandomState(2)
df = pd.DataFrame(rs.randn(200,2), columns = ['A','B'])
sns.jointplot(x=df['A'], y=df['B'], #设置xy轴,显示columns名称
data = df, #设置数据
color = 'b', #设置颜色
s = 50, edgecolor = 'w', linewidth = 1,#设置散点大小、边缘颜色及宽度(只针对scatter)
stat_func=sci.pearsonr,
kind = 'scatter',#设置类型:'scatter','reg','resid','kde','hex'
#stat_func=<function pearsonr>,
space = 0.1, #设置散点图和布局图的间距
size = 8, #图表大小(自动调整为正方形))
ratio = 5, #散点图与布局图高度比,整型
marginal_kws = dict(bins=15, rug =True), #设置柱状图箱数,是否设置rug
)
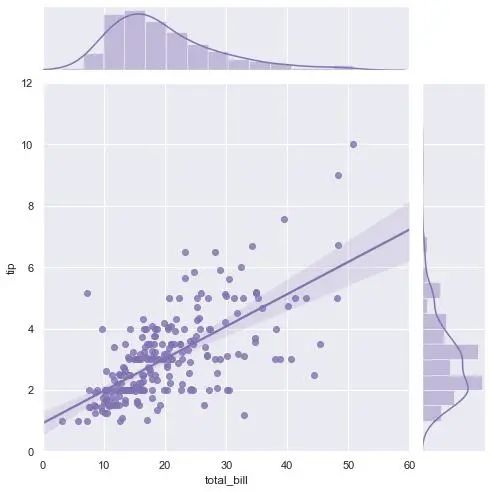
带线性回归最佳拟合线的散点图
如果你想了解两个变量如何相互改变,那么最佳拟合线就是常用的方法。 下图显示了数据中各组之间最佳拟合线的差异。 要禁用分组并仅为整个数据集绘制一条最佳拟合线,
import seaborn as sns
sns.set(style="darkgrid")
tips = sns.load_dataset("tips")
g = sns.jointplot("total_bill", "tip", data=tips,
kind="reg", truncate=False,
xlim=(0, 60), ylim=(0, 12),
color="m", height=7)
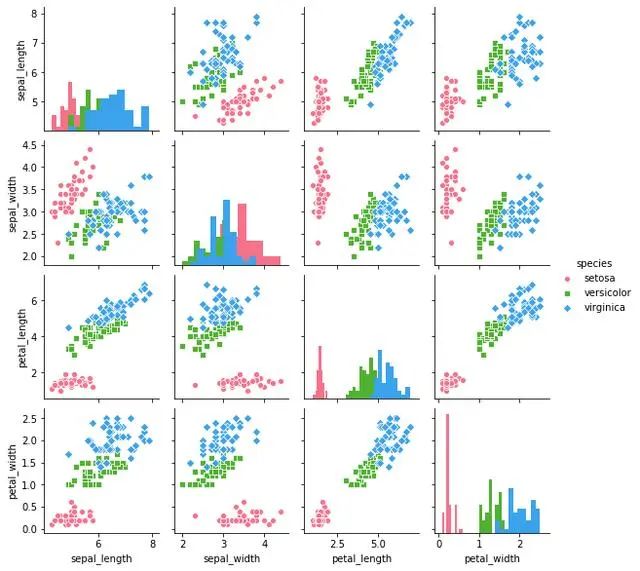
矩阵散点图 - pairplot()
#设置风格
sns.set_style('white')
#读取数据
iris = sns.load_dataset('iris')
print(iris.head())
sns.pairplot(iris,
kind = 'scatter', #散点图/回归分布图{'scatter', 'reg'})
diag_kind = 'hist', #直方图/密度图{'hist', 'kde'}
hue = 'species', #按照某一字段进行分类
palette = 'husl', #设置调色板
markers = ['o', 's', 'D'], #设置不同系列的点样式(这里根据参考分类个数)
size = 2 #图标大小)