来源:arxiv
编辑:LRS
【新智元导读】知识蒸馏已经成了目前常用的模型压缩方法,但相关研究还局限在图像分类任务上。最近旷视孙剑博士联手西安交大发表了一篇论文,提出新模型LGD,无需一个强力的teacher模型也能在目标检测任务上取得超强效果,并且训练速度提升51%,内存消耗降低34%!
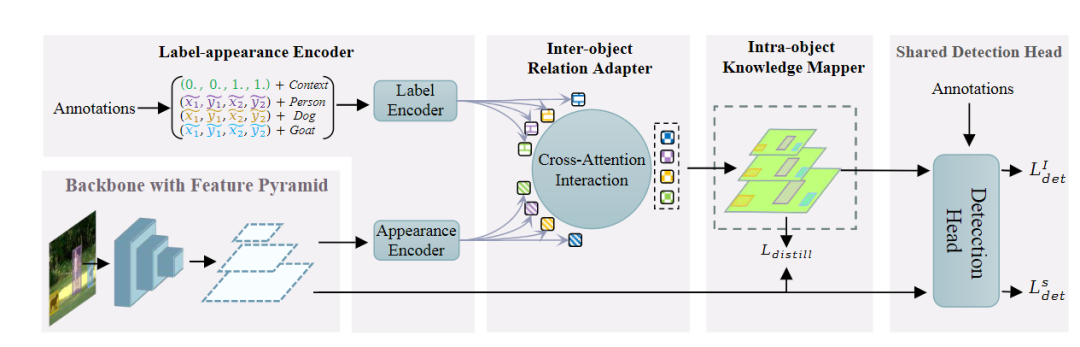
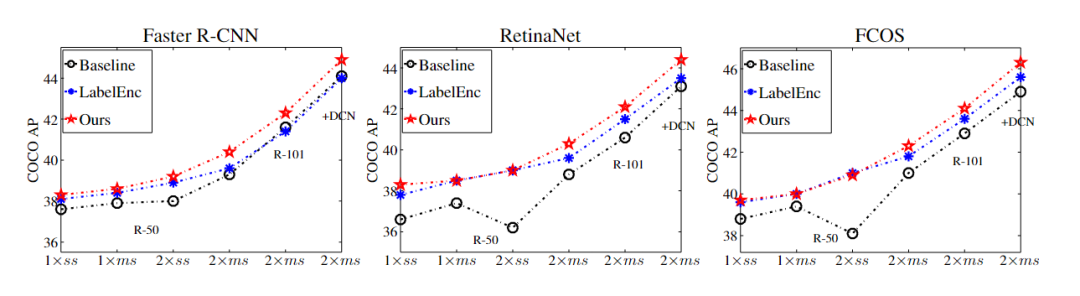
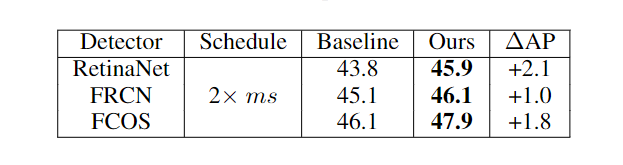
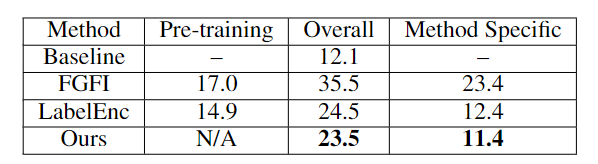
知识蒸馏(Knowledge distillation, KD)刚开始被用于图像分类任务时就取得了不错的效果,通常流程就是将指导性知识从预训练的模型作为教师teacher转移到较小的学生student模型,从而在性能下降较少的情况下完成模型压缩。随着研究的发展,知识蒸馏在目标检测任务上也取得了一些进展,但目前的模型仍然存在一个缺陷,就是需要一个训练的非常好的teacher,因为有研究表明,更强的teacher 可以提高蒸馏效率。但现实世界中的应用场景很难训练得到一个完美的teacher,所以无需预训练的教师的通用检测知识蒸馏(KD for generic detection without pretrained teacher)的问题几乎没有得到研究。为了缓解对teacher模型的依赖,一些研究关注teacher-free schemes,主要包括1)自蒸馏 self-distillation;2)协作学习 colorative learning;3)标签正则化 label regularization,其中指导性的知识(instructive knowledge)可以是跨层特征、竞争对手(competitive counterparts) 和调制标签分布(modulated label distribution)。针对这个问题,旷视科技联合西安交大提出了一个新的无教师目标检测方法 Label-Guided self-Distillation (LGD)。通过高效的设计,LGD 能够与学生模型联合训练,简化流程,降低训练成本。在推理过程中,只保留学生检测器,不会带来额外开销。这篇论文由孙剑博士指导,他是旷视首席科学家、旷视研究院院长,全面负责旷视技术研发,带领旷视研究院发展成为全球规模最大的计算机视觉研究院。在孙剑博士的带领下,旷视研究院研发了包括移动端高效卷积神经网络ShuffleNet、开源深度学习框架天元MegEngine、AI生产力平台Brain++等多项创新技术,引领前沿人工智能应用。他的主要研究方向是计算机视觉和计算摄影学,拥有超过40项专利,自2002年以来在顶级学术会议和期刊上发表学术论文100余篇。1、标签外观编码器Label-appearance encoder这个编码器主要计算标签和外观的embedding。对于每个对象,把真值框标准化为两个坐标点(x1,y1,x2,y2)和one-hot 类别向量连接起来作为描述符。面向对象的描述符被传递到标签编码模块中用于优化标签嵌入。为了引入标签描述符之间的基本关系建模并保持置换不变性,LGD 采用经典的PointNet作为标签编码模块。通过多层perceptron 处理描述符,通过空间Transformer 网络进行局部全局建模。根据经验,使用PointNet作为编码器比MLP或transformer编码器表现稍好。细节上,研究人员将BatchNorm替换为LayerNorm,以适应小批量检测的设置。值得注意的是,上述1D object-wise的标签编码方式比LabelEnc中的方式更有效,LabelEnc构建了一个特殊的颜色映射用于描述标签。除了标签编码之外,研究人员还从包含感知对象外观特征的学生检测器的特征pyramid中检索appearance embedding,主要采用一个掩码池从特征映射中提取面向对象的嵌入。预先计算对象屏蔽 object-wise mask 用于总共N个对象和一个虚拟上下文对象,位置覆盖整个图像。对于每个对象 ,建立一个二进制矩阵,其值在基本真值区域内设置为1,否则设置为0。对所有pyramid levels 同时进行掩码池,输入的对象掩码被缩小以对应分辨率,成为特定于比例的掩码。2、对象间关系适配器 Inter-object relation adapter 在给定标签和appearance embedding的情况下,可以通过交叉注意过程来描述对象间关系的自适应。该过程在每个学生出现金字塔尺度上执行以检索交互嵌入。在交叉注意过程中,利用一系列键和查询标记来计算KQ注意关系,从而聚合值以获得注意输出。为了实现标签引导的信息自适应,研究人员利用当前尺度下的appearance embedding 作为query,尺度不变的标签嵌入L作为key和value。attention schema测量对象之间较低层次的结构外观信息和较高层次的标签语义之间的相关性,然后重新组装信息标签嵌入以进行动态适应。3、对象内知识映射器 Intra-object knowledge mapper为了使1D交互embedding 适用于广泛使用的中间特征提取进行检测,研究人员将appearance embedding 映射到2D特征映射空间以获取指导性知识。对于每个金字塔比例p, 结果map 的分辨率仅限于与相应的学生特征map相同。直观地说,由于紧凑表示的标签编码中未对显式空间拓扑进行建模,因此恢复每个对象的定位信息以实现几何透视对齐非常重要。将每个对象绑定交互嵌入填充到零初始化特征映射上对应的真值框区域中。对于每个对象,通过计算向量化对象掩码之间的矩阵乘法来获得其p尺度的特征映射,投射和交互的embedding。所有这些面向对象的映射被添加到一个统一的映射中以形成结构化知识。知识映射器将交互嵌入映射到特征映射空间,作为最终的指导知识,同时考虑对象内表示一致性和定位启发式。由于上述关系建模,最终的指导性知识自然地适应了学生的代表性,有助于有效地提炼出强大的学生检测器和减少语义差异。从经验上看,LGD在各种检测器、数据集和广泛的任务(如实例分割)上获得了不错的结果。例如,在MS-COCO数据集中,LGD在2倍单尺度训练下使用ResNet-50将视网膜神经网络从36.2%提高到39.0%mAP(+2.8%)。在2倍多尺度训练(46.1%)下,对于更强大的检测器,如带有ResNeXt-101 DCN v2的FCOS,LGD达到47.9%(+1.8%)。对于CrowdHuman数据集中的pedes-trian检测,LGD将mMR提高了2.3%,从而提高了R-CNN与ResNet-50的速度。与经典的基于教师的方法FGFI相比,LGD不仅在不需要预先训练的教师的情况下表现更好。虽然所有的提取或正则化方法都不会影响学生的推理速度,但由于先决条件的预训练和提取过程,它们仍然可能训练效率低下。成本分为预训练成本、总体成本和特定模型的成本(除学生学习之外的总体成本,也是所有方法的固有成本)。在8个Tesla V100 GPU上运行下,研究人员发现提出的方法在总体成本和方法特定成本上分别节省了34%(23.5小时对35.5小时)和51%(11.4小时对23.4小时)。事实上,FGFI或其他基于教师的知识蒸馏可能会有更强的教师开发能力,表现优于文中提出的知识蒸馏方法,但这可能会带来更高的训练负担。与FGFI类似,LabelEnc正则化引入了两阶段训练范式,尽管没有预先训练过的教师,但对于LabelEnc,新方法节省了1小时,并且以一步式方式进行训练。并且LabelEnc消耗了3.8G额外的gpu内存,除了固有检测器的内存,新方法只消耗了2.5G (相对节省34%),但性能更好。
参考资料:
https://arxiv.org/pdf/2109.11496.pdf




 下载APP
下载APP