近年来,知识蒸馏被证明是一种有效的模型压缩方法。这种方法可以使轻量级的学生模型从较大的教师模型中获取知识。然而,以往的提取检测方法对不同检测框架的泛化能力较弱,十分依赖于GT,忽略了实例间有价值的关系信息。今天我们介绍一篇用于目标检测的通用实例蒸馏的论文。该论文已被CVPR 2021收录,论文提出了一种新的基于区分性实例的提取方法,即一般实例提取(GID)。该方法包含了通用实例选择模块(GISM),充分利用了基于特征、基于关系和基于响应的知识进行提取。

论文:General Instance Distillation for Object Detection链接:https://arxiv.org/abs/2103.02340
01
知识蒸馏
1.1 知识蒸馏
知识蒸馏,可以将一个网络的知识转移到另一个网络,两个网络可以是同构或者异构。做法是先训练一个teacher网络,然后使用这个teacher网络的输出和数据的真实标签去训练student网络。知识蒸馏,可以用来将网络从大网络转化成一个小网络,并保留接近于大网络的性能;也可以将多个网络的学到的知识转移到一个网络中,使得单个网络的性能接近emsemble的结果。
1.2 目标检测的知识蒸馏
当前,大多数蒸馏方法主要设计用于多类分类问题。由于在检测任务中正例和负例的比例极不平衡,因此直接将分类专用蒸馏方法直接迁移到检测模型的效果较差。一些专为检测任务设计的蒸馏框架可解决此问题,例如通过以RPN采样的一定比例提取正例和负例来解决该问题,以及进一步建议仅提炼GT。但是,需要精心设计正例与负例之间的比例,并且仅蒸馏与GT相关的区域可能会忽略背景中潜在的信息区域。而且,当前的检测蒸馏方法不能同时在多个检测框架中很好地工作,例如两阶段anchor-free的方法。因此,作者希望为各种检测框架设计一种通用的蒸馏方法,以便在不考虑正例或负例影响的情况下,尽可能有效地利用尽可能多的知识。
02
目标检测的通用实例蒸馏
先前的工作,提出目标对象附近的特征区域具有相当多的信息,这对于知识的提炼是有用的。然而,作者发现,不仅对象附近的特征区域,甚至来自背景区域的区分块都具有有意义的知识。基于此发现,作者设计了通用实例选择模块(GISM)该模块利用教师模型和学生模型的预测来选择要蒸馏的关键实例。此外,为了更好地利用教师模型提供的信息,作者提取并利用了基于特征,基于关系和基于响应的知识进行蒸馏。下图是目标检测通用实例蒸馏的框架:
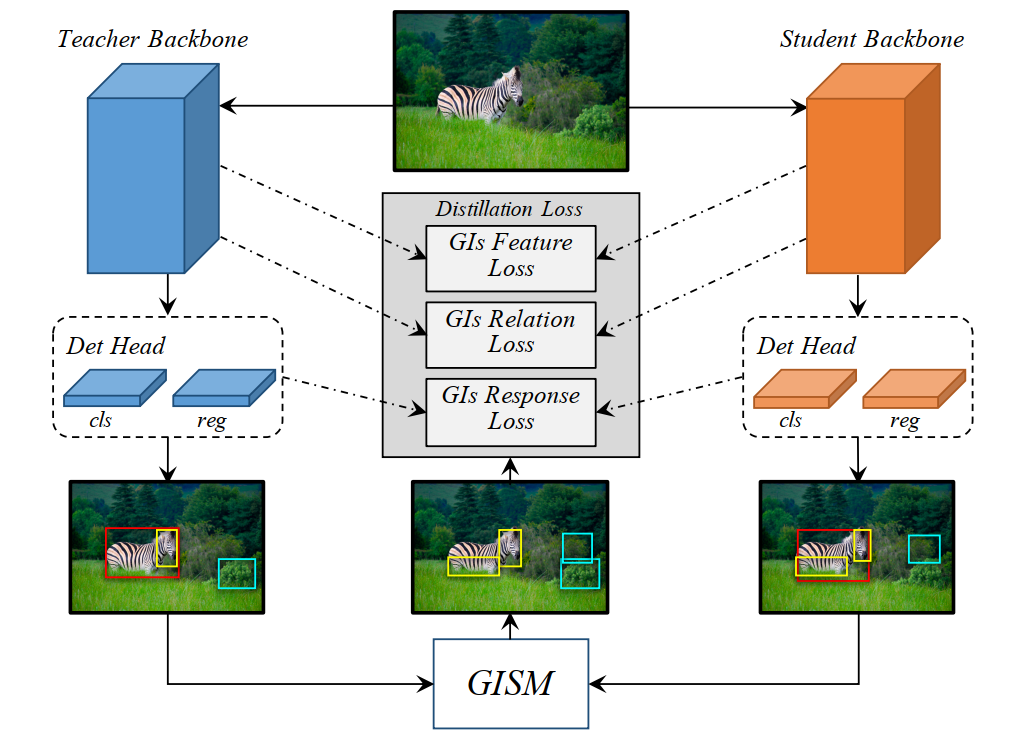
2.1 选择通用实例
GISM(General Instance Selection Module) 利用教师模型和学生模型的预测来选择要蒸馏的关键实例。首先量化教师模型预测实例和学生模型预测实例的差异,然后选择可区分的实例进行蒸馏,因此作者提出了两个指标评估两个模型预测实例的差异:GI Score 和GI Box。这两个参数都是在每个训练步骤中动态计算的。作者将分类得分的L1距离计算为GI Score,选择得分更高的框作为GI box。下图说明了生成GI(通用实例)的过程: 1、教师模型和学生模型预测图片中实例的Cls Score 和 Reg Box 2、根据两个模型预测结果计算实例的差异:GI Score(L1距离) 和GI Box(得分高的框) 3、GI Score和GI Box经过NMS反复选择具有最高GI分数的实例,然后删除与所选区域具有高度重叠的所有较低GI分数的实例。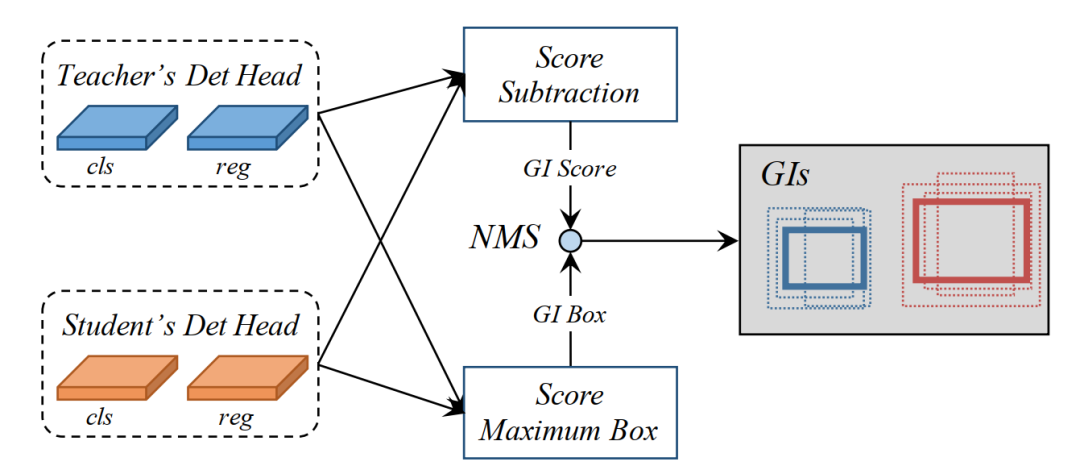
基于特征知识的蒸馏,作者根据GISM选择的每个GI Box的大小,从匹配的FPN层裁剪特征以进行蒸馏,并且采用ROI Align算法将提取的GI特征调整为相同大小,最后执行蒸馏,对每个目标进行同等处理,具体操作如下图(a)所示。基于特征的蒸馏损失如下: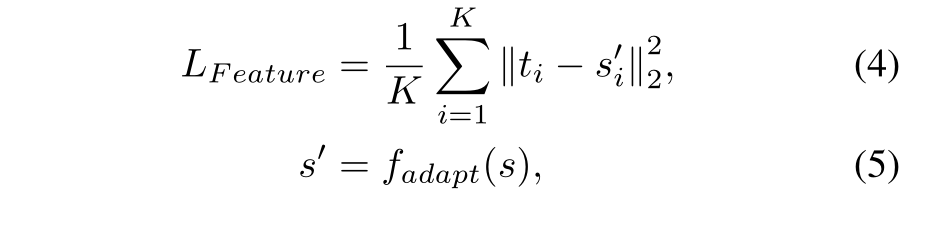
其中 K 是指GISM选择的GI Box的个数,ti 和 si 分别代表根据GISM选择的第i个GI Box 在教师模型和学生模型的FPN层中裁剪的特征,fadapt()是线性适应函数,为了让学生模型特征si与教师模型特征ti的尺寸相同。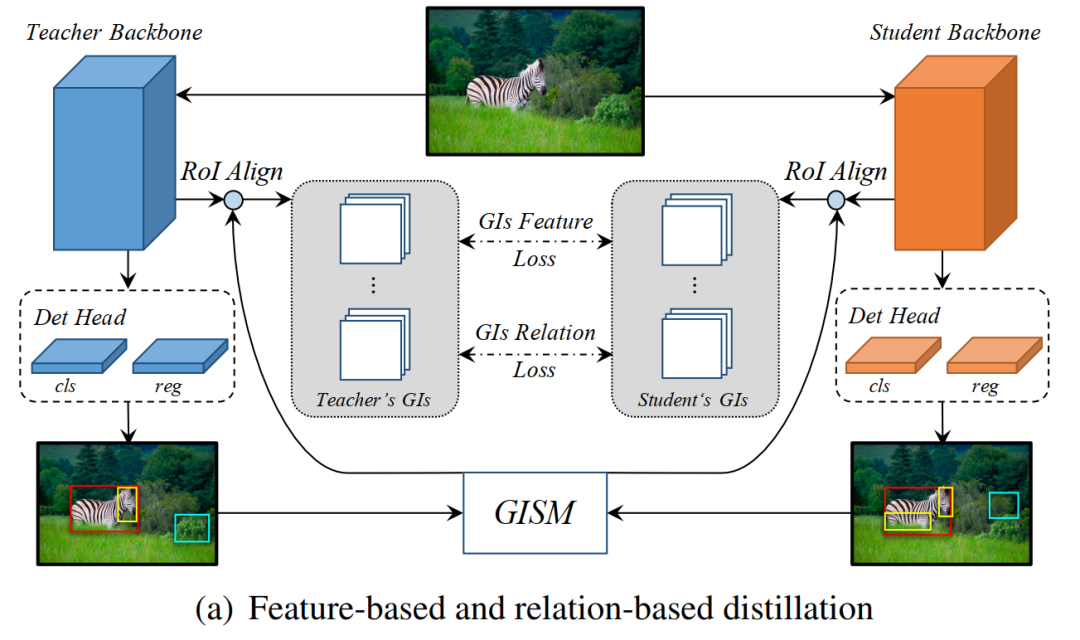
通过GISM选择的信息丰富的GI(通用实例),能够充分利用判别实例之间的相关性。当然,仅执行一对一的特征提炼当然不足以引入更多的知识。因此,为了挖掘GI背后的有价值的关系知识,作者进一步引入了基于关系的知识以进行提炼。在这里,我们使用欧式距离来度量实例的相关性,并使用L1距离来传递知识。如上图(a)所示,作者还利用GI之间的相关信息来从老师到学生中提取知识。损失表达式如下: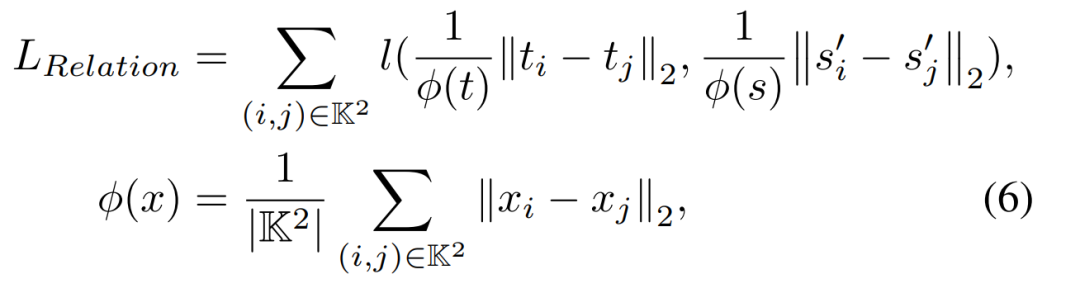
其中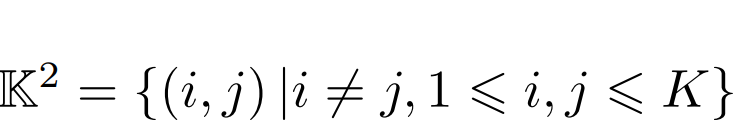 ,φ(·)是距离的归一化因子,l表示平滑的L1损失。
,φ(·)是距离的归一化因子,l表示平滑的L1损失。
知识蒸馏的性能提高主要归功于教师模型中基于响应的知识的正则化。但是,对检测头的整个输出进行蒸馏会影响学生模型的性能。这可能是由于检测任务的正负样本不平衡以及过多负样本引入的噪声导致。因此,作者基于选定的GI为分类分支和回归分支设计了 distillation mask,选定的GI首先通过GI分配生成msk。然后,将被屏蔽的分类和回归头进行提取,以利用基于响应的知识。其操作如下图(b)所示:1、首先基于GI计算distillation mask: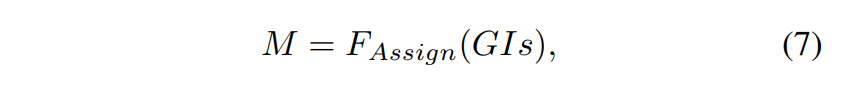
其中F是标签分配函数(由模型类别决定),输入是GI框,如果此输出像素与GI相匹配,则输出为1,否则为0。
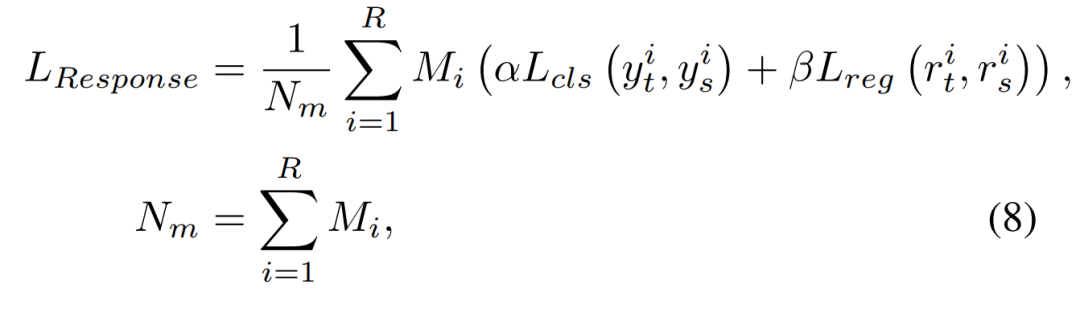
其中yt,ys分别来自教师模型和学生模型的分类头输出,rt,rs是回归头输出,Lcls和Lreg是分类和回归损失函数,与蒸馏模型的损失函数相同。对于两级检测器,为了简化起见,作者提取RPN的输出。
2.5 Overall loss function作者端到端地训练了学生模型,提取学生模型的总损失如下: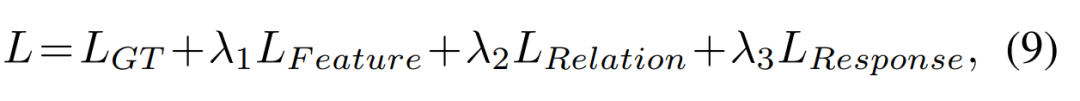
03
实验结果
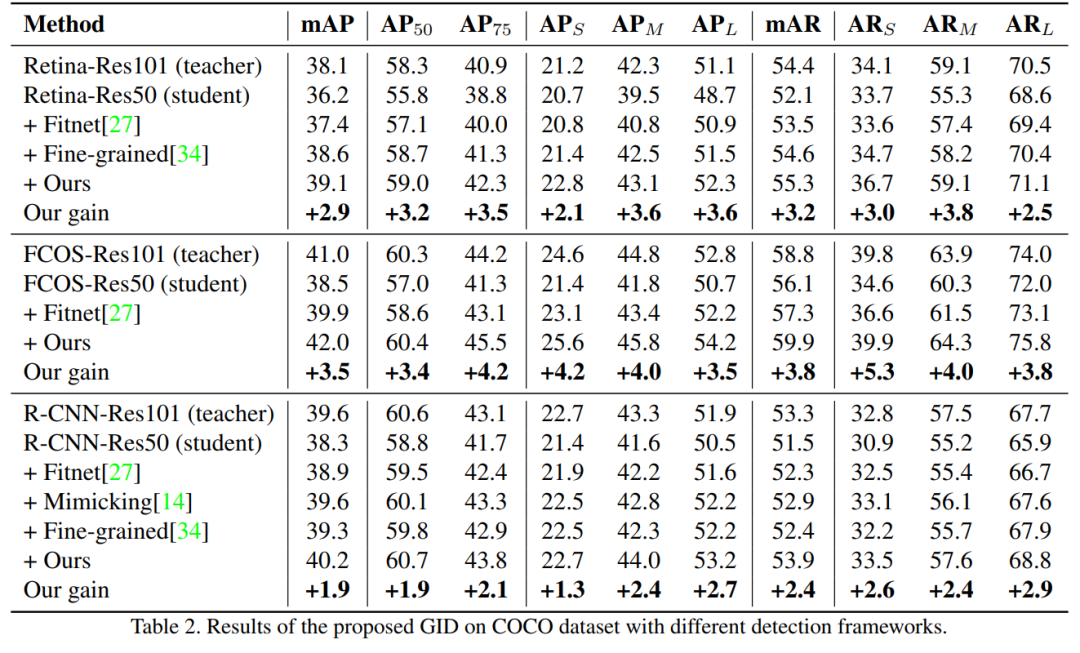
作者经过实验证明,在各种检测框架下,GID可显著的提高学生模型的AP,甚至优于老师。具体来说,在Reconet上使用ResNet-50的RetinaNet在COCO数据集上具有GID的mAP达到了39.1%,比基线的36.2%超出了2.9%,甚至比具有38.1%的AP的基于ResNet-101的教师模型更好。
04
总结
作者提出了通用实例提纯(GID)框架,该框架可自适应地选择教师和学生之间最有区别的实例进行提纯。此外,提取基于特征,基于关系和基于响应的知识以进行蒸馏。GID的方法有效地提高了现代检测框架的性能,并适用于各种检测框架。
✄------------------------------------------------
看到这里了,说明您也喜欢这篇文章,您可以点击「分享」与朋友们交流,点击「在看」使我们的新文章及时出现在您的订阅列表中,或顺手「点赞」给我们一个支持,让我们做的更好哦。
欢迎微信搜索并关注「目标检测与深度学习」,不被垃圾信息干扰,只分享有价值知识!
