
深度学习之Focus层
1
深度学习有哪些下采样的方式?
YOLOv5中提到了一种Focus层,高大上的名称背后感觉就是特殊的下采样而已。不过原理逻辑虽然简单,但也体现了作者的创造力,不然小编咋就没想到呢~~~
提到下采样,在这里小编列举一下深度学习中都接触过哪些下采样方式:
最早接触到的应该是池化操作,如下图所示:
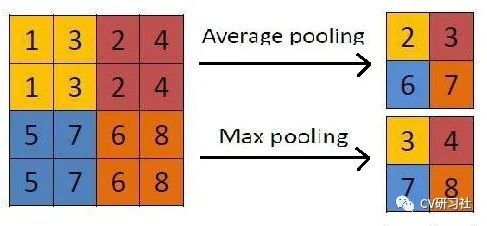
包括平均池化和最大池化两种,平均池化有种平滑滤波的味道,通过求取滑窗内的元素平均值作为当前特征点,根据滑窗的尺寸控制下采样的力度,尺寸越大采样率越高,但是边缘信息损失越大。最大池化类似锐化滤波,突出滑窗内的细节点。但是不论哪种池化操作,都是以牺牲部分信息为代价,换取数据量的减少。
步长大于1的卷积也可以实现池化功能,如下图所示:
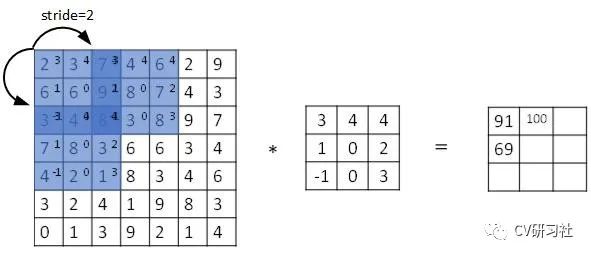
卷积操作可以获得图像像素之间的特征相关性,采用步长大于1的跳跃可以实现数据降维,但是跳跃采样造成的相邻像素点特征丢失是否会影响最终效果。
池化作为一种强先验操作人为设定了降采样规则,而卷积层是通过参数自己学习出降采样算子,具体对比可以参考这篇文章:Striving for simplicity: The All Convolutional Net.
2
下采样在神经网络中的作用?
下采样在神经网络中主要是为了减少参数量达到降维的作用,同时还能增加局部感受野。
但是下采样的过程不可避免的伴随信息丢失,尤其是在分割任务要经历下采样编码和上采样解码的过程,那么如何在不损失数据信息的情况下,增大深层特征图的感受野呢?
18年的时候出了个空洞卷积的玩意,如下图所示,根据打洞的间距把卷积核进行膨胀,在没有增加参数量的情况下,增大了感受野,从某种角度来看也算是一种局部下采样的过程。
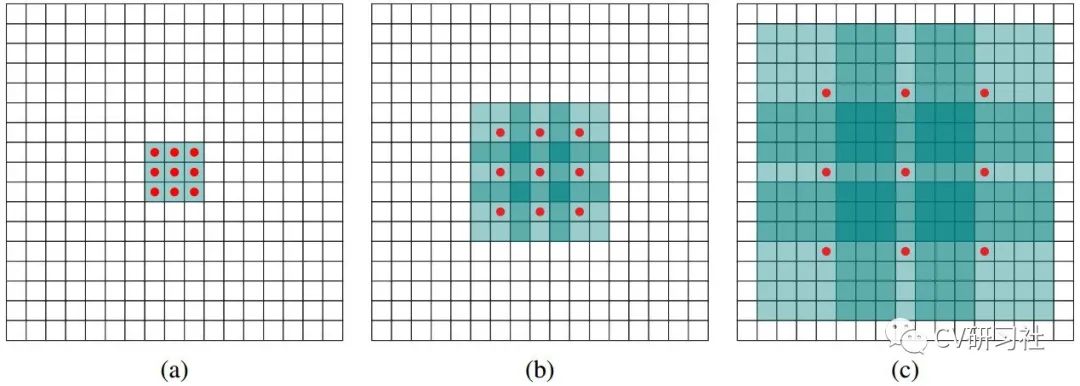
图a,b,c均是3×3尺寸卷积核,图(a)的空洞为0,每个核算子之间紧挨着没有间隔,等价于普通的卷积,每次运算学习9个参数,感受野即3×3;图(b)的空洞为1,同样学习9个参数,但是每个算子之间空一格,感受野即7×7;图(c)的空洞为3,仍然学习9个参数,但是每个算子之间空三格,感受野即15×15。
如何计算空洞卷积的感受野呢?
这里给出一个常规的计算公式:
size=(dilate_rate-1) ×(kernel_size-1)+ kernel_size
3
YOLOv2之PassThrough层
上面我们聊了一些下采样的方法和优缺点,但是在目标检测网络中还有两种特殊的下采样,PassThrough首次出现在YOLOv2网络,将相邻的特征堆积在不同的通道中,目的是将大尺度特征图下采样后与小尺度特征图进行融合,从而增加小目标检测的精确度。如下图所示:
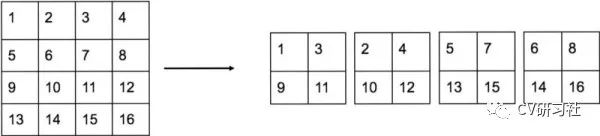
小编对这张图和Focus的图对比了半天,简直一模一样,暂时没发现这两个层有何区别?通过Tensorflow提供的API接口tf.space_to_depth测试了下Tensor的输出,确实是隔行采样再拼接的形式。有小伙伴知道差异的欢迎+v指导。
4
YOLOv5之Focus层
Focus层非常类似PassThrough层,同样是采用切片操作把高分辨率的图片/特征图拆分成多个低分辨率的图片/特征图,如下图所示:隔行采样+拼接
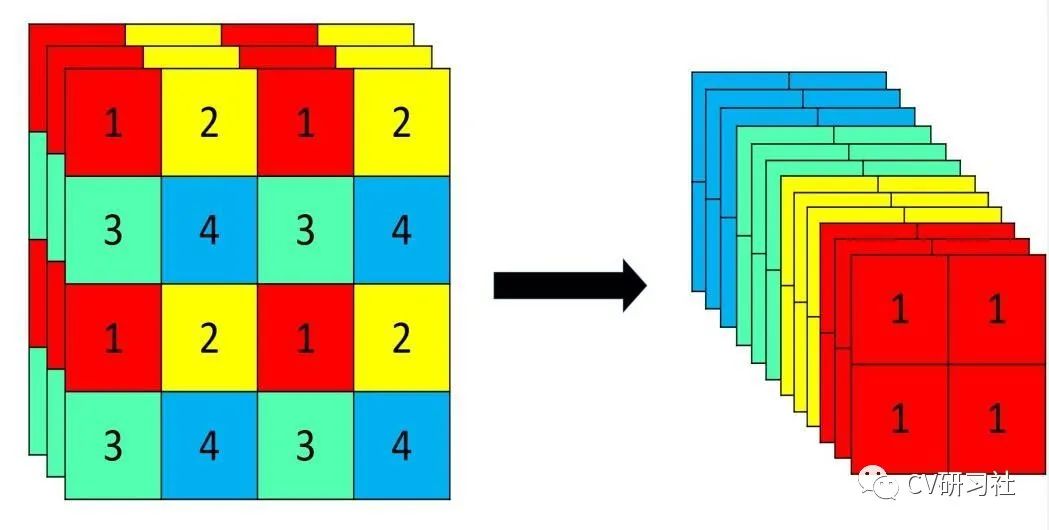
将4×4×3的Tensor通过间隔采样拆分成4份,在通道维度上进行拼接生成2×2×12的Tensor。Focus层将w-h平面上的信息转换到通道维度,再通过卷积的方式提取不同特征。采用这种方式可以减少下采样带来的信息损失。
小编觉得从细节的角度此方式确实比stride为2的卷积或者池化要精致,用在PC端建模可能有一些精度提升。但是如果用在工程上,考虑到大多数芯片厂商未必提供Focus层或者自定义接口,从部署的角度可以牺牲Focus带来的0.1%的提升更换成Conv或Pool层。
✄------------------------------------------------
感谢对我们的支持! 