
【深度学习】深度学习之解构基础网络结构
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

引言
在现实生活中,图像和视频等非结构化的数据已经司空见惯,而且数量庞大;如何对这些数据进行分析获取价值,是机器视觉(CV)所关注的焦点。其中,图像分类是机器视觉中最常见的任务之一,有着非常广泛的应用场景,也是其他任务的基石。

在深度学习出现之前,传统图像分类基本可以分两个步骤:
(1)人为的提取特征(底层特征如颜色,纹理,边缘形状等,中间特征如LBP,SIFT, SURF等)
(2)这些特征作为传统分类器(如SVM)的输入进行分类。而深度学习之后,通过卷积神经网络来自动提取特征,后面接全连接层来分类,是一个端到端的过程。
如何有效的提取特征,前辈们进行了广泛的探索,从1998年LeCun的LeNet-5成功应用到手写字母识别任务中,到2012年Alex的AlexNet开启了深度学习大门,再到何凯明的ResNet等等。这些探索也奠定了深度学习的今天一统江山的地位。
本文和大家梳理分享一下大师们的探索成果,即经典的基础网络(backbone)以及关键思想,附带实现过程。

LetNet-5和AlexNet
LeCun在1998年提出手写字符识别网络LeNet-5,包括2个卷积层、2个pooling和3个全连接层,并且可以通过反向传播算法进行训练,已经具有当前深度学习的雏形了,是一个卷积神经网络(convolution Neural Network)。
卷积操作具有局部感受野,共享权重的特定,大大降低了参数量, 且一定程度具有尺度不变性。卷积操作很符合人类视觉的特点,人类识别图像,并不需要看全幅图,即使图像缩小后,也不影响判断。 但是LeNet-5并没有得到太多的关注,主要原因应该是算力跟不上。
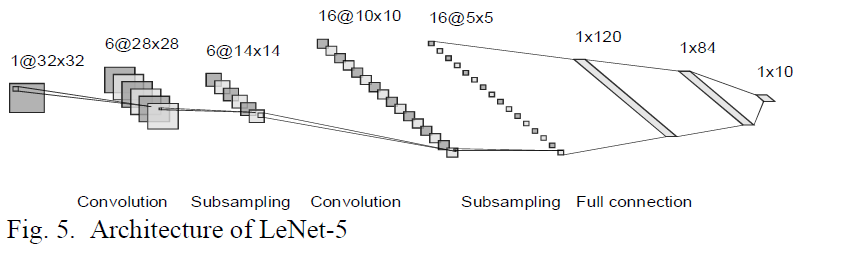
import torchfrom torch import nnimport torch.nn.functional as Fclass LeNet5(nn.Module):def __init__(self):super(LeNet5, self).__init__()self.conv1 = nn.Conv2d(1, 6, 5)self.conv2 = nn.Conv2d(6, 16, 5)self.max_pool_1 = nn.MaxPool2d(2)self.max_pool_2 = nn.MaxPool2d(2)self.fc1 = nn.Linear(16*5*5, 120)self.fc2 = nn.Linear(120, 84)self.fc3 = nn.Linear(84, 10)def forward(self, x):x = self.max_pool_1(F.relu(self.conv1(x)))x = self.max_pool_2(F.relu(self.conv2(x)))x = x.view(-1, 16*5*5)x = self.fc1(x)x = self.fc2(x)x = self.fc3(x)return xinput1 = torch.rand([1,1,32,32])lenet = LeNet5()print(lenet)output = lenet(input1)print(output.shape)
LeNet5((conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1))(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1))(max_pool_1): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(max_pool_2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(fc1): Linear(in_features=400, out_features=120, bias=True)(fc2): Linear(in_features=120, out_features=84, bias=True)(fc3): Linear(in_features=84, out_features=10, bias=True))torch.Size([1, 10])
而到了2012年AlexNet取得历史性的突破,结构上包括5个卷积层和3个全连接层,更重要的是利用GPU进行加速。
AlexNet中采用了几个关键技术:
RELU激活函数:降低了梯度消失的问题,使得训练更深的卷积层变成可能,现在也是广泛使用
dropout层:随机去除一些神经元节点,相当于正则,避免过拟合,提高模型的泛化能力。现在一般用在全连接层中间
LRN:一种正则操作,现在基本上不用了, 不做详细介绍
max pooling 代替 average pooling
采用数据增强操作:这个也是训练十分重要的操作,后面部分会重点分享
有趣的是,当时算力不足,为了加快训练AlexNet采用两路卷积,并共享部分的feature map。这个是后来也成为一个方向group convolution。
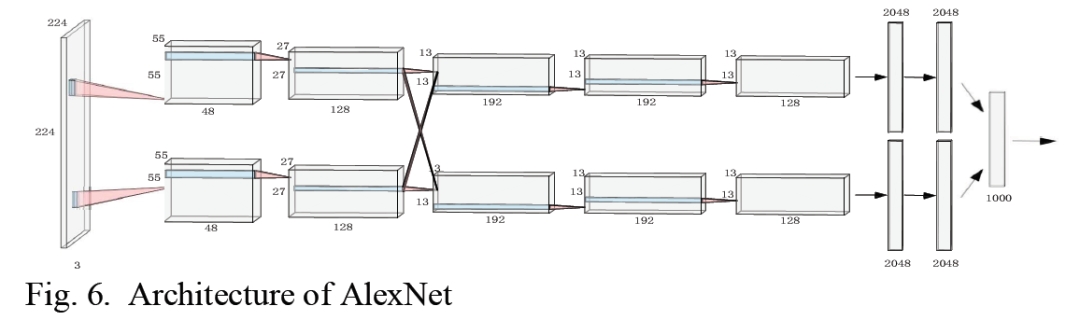
import torchfrom torch import nnimport torch.nn.functional as Fclass AlexNet(nn.Module):def __init__(self):super(AlexNet, self).__init__()self.conv1 = nn.Sequential(nn.Conv2d(3, 96, kernel_size=11, stride=4, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2))self.conv2 = nn.Sequential(nn.Conv2d(96, 256, kernel_size=5, stride=1, padding=2),nn.ReLU(),nn.MaxPool2d(kernel_size=3,stride=2))self.conv3 = nn.Sequential(nn.Conv2d(256, 384, kernel_size=3, padding=1),nn.ReLU())self.conv4 = nn.Sequential(nn.Conv2d(384, 384, kernel_size=3, padding=1),nn.ReLU())self.conv5 = nn.Sequential(nn.Conv2d(384, 256, kernel_size=3, padding=1),nn.ReLU(),nn.MaxPool2d(2))self.fc1 = nn.Linear(256*6*6, 4096)self.fc2 = nn.Linear(4096, 4096)self.fc3 = nn.Linear(4096, 1000)passdef forward(self, x):x = self.conv1(x)x = self.conv2(x)x = self.conv3(x)x = self.conv4(x)x = self.conv5(x)x = x.view(x.size(0), -1)x = self.fc1(x)x = self.fc2(x)x = self.fc3(x)return xinput1 = torch.rand([1, 3, 224, 224])alex_net = AlexNet()print(alex_net)output = alex_net(input1)print(output.shape)
AlexNet((conv1): Sequential((0): Conv2d(3, 96, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2))(1): ReLU()(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False))(conv2): Sequential((0): Conv2d(96, 256, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))(1): ReLU()(2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False))(conv3): Sequential((0): Conv2d(256, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU())(conv4): Sequential((0): Conv2d(384, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU())(conv5): Sequential((0): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU()(2): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(fc1): Linear(in_features=9216, out_features=4096, bias=True)(fc2): Linear(in_features=4096, out_features=4096, bias=True)(fc3): Linear(in_features=4096, out_features=1000, bias=True))torch.Size([1, 1000])
VGG
VGG是牛津大学的Visual Geometry Group提出经典网络结构。VGGNet在AlexNet基础上探索了更深的网络结构的可行性,比较著名的是VGG-16和VGG-19。
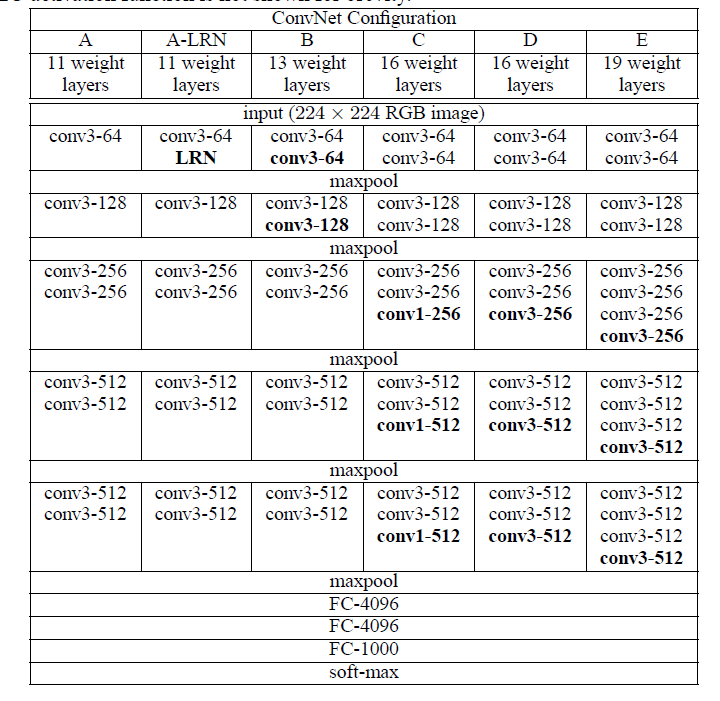
从结构可知,VGG除了用更多的卷积层,其他的亮点:
更小的kernel size:用3x3的kernel代替5x5的kernel
Multi-scale training: (1)不同尺寸输入256或者384;(2)在[256, 512]随机选取一个尺度作为输入
import torchfrom torch import nndef make_layers(cfg):layers = []in_channels = 3for v in cfg:if v == 'M':layers += [nn.MaxPool2d(kernel_size=2, stride=2)]else:v = int(v)conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)layers += [conv2d, nn.ReLU(inplace=True)]in_channels = vreturn nn.Sequential(*layers)class VGG16(nn.Module):def __init__(self, features, num_classes=1000):super(VGG16, self).__init__()self.features = featuresself.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(True),nn.Dropout(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return xcfg = [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M']input1 = torch.rand([1, 3, 224, 224])vgg16 = VGG16(features=make_layers(cfg))print(vgg16)output = vgg16(input1)print(output.shape)
VGG16((features): Sequential((0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(1): ReLU(inplace=True)(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(3): ReLU(inplace=True)(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(6): ReLU(inplace=True)(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(8): ReLU(inplace=True)(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(11): ReLU(inplace=True)(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(13): ReLU(inplace=True)(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(15): ReLU(inplace=True)(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(18): ReLU(inplace=True)(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(20): ReLU(inplace=True)(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(22): ReLU(inplace=True)(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(25): ReLU(inplace=True)(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(27): ReLU(inplace=True)(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))(29): ReLU(inplace=True)(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False))(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))(classifier): Sequential((0): Linear(in_features=25088, out_features=4096, bias=True)(1): ReLU(inplace=True)(2): Dropout(p=0.5, inplace=False)(3): Linear(in_features=4096, out_features=4096, bias=True)(4): ReLU(inplace=True)(5): Dropout(p=0.5, inplace=False)(6): Linear(in_features=4096, out_features=1000, bias=True)))torch.Size([1, 1000])
VGG卷积层能够有效地提取特征,在超分(如perceptual loss,GAN),风格转换等任务中都有重要的应用。
GoogLeNet
GoogleNet系列有4个版本Inception v1/v2/v3/v4,GoogleNet的重要思想是在宽度上探索经典的深度学习网络。
Inception v1利用不用的卷积核来提取不同感受野的特征,同时1x1的卷积核降低参数量和计算量。
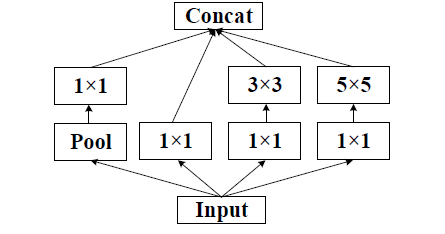
Inception v2 在网络中加入了Batch-Normalization(BN),使得损失空间更加平滑,能够训练更有泛化的模型以及可以在高learning rate开始训练。 同时,一个5x5的卷积可以用两个3x3的卷积表示,同时为了降低参数量,v2指出一个nxn的卷积可以拆分成一个1xn和nx1的卷积,这种替换在每个分支的最后一个3x3进行操作。
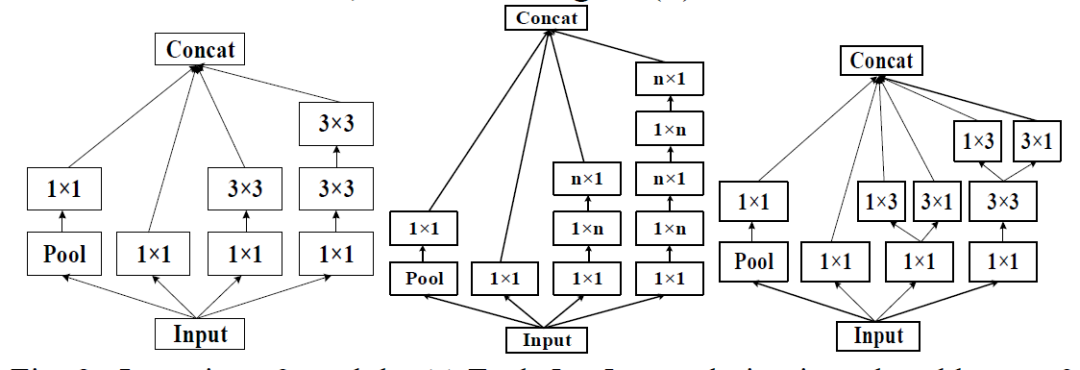
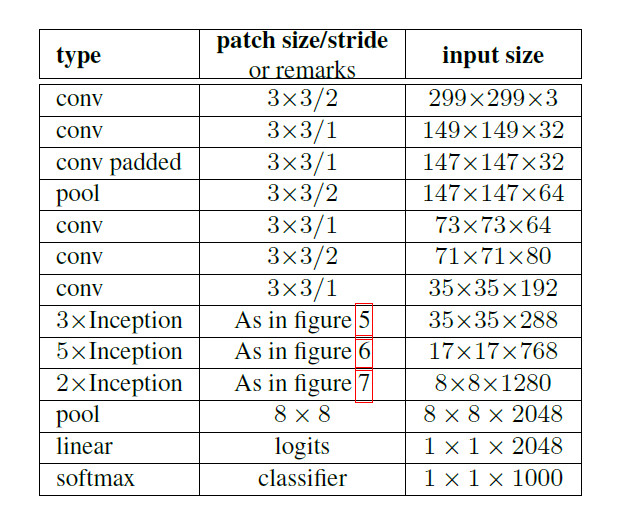
网络基本结构如下(figure5/6/7 依次为上图的左中右:
from collections import namedtupleimport warningsimport torchfrom torch import nn, Tensorimport torch.nn.functional as Ffrom typing import Callable, Any, Optional, Tuple, ListInceptionOutputs = namedtuple('InceptionOutputs', ['logits', 'aux_logits'])InceptionOutputs.__annotations__ = {'logits': Tensor, 'aux_logits': [Tensor]}# Script annotations failed with _GoogleNetOutputs = namedtuple ...# _InceptionOutputs set here for backwards compat_InceptionOutputs = InceptionOutputsclass Inception3(nn.Module):def __init__(self,num_classes: int = 1000,aux_logits: bool = False,transform_input: bool = False,inception_blocks = None,init_weights = None) -> None:super(Inception3, self).__init__()if inception_blocks is None:inception_blocks = [BasicConv2d, InceptionA, InceptionB, InceptionC,InceptionD, InceptionE, InceptionAux]assert len(inception_blocks) == 7conv_block = inception_blocks[0]inception_a = inception_blocks[1]inception_b = inception_blocks[2]inception_c = inception_blocks[3]inception_d = inception_blocks[4]inception_e = inception_blocks[5]inception_aux = inception_blocks[6]self.aux_logits = aux_logitsself.transform_input = transform_inputself.Conv2d_1a_3x3 = conv_block(3, 32, kernel_size=3, stride=2)self.Conv2d_2a_3x3 = conv_block(32, 32, kernel_size=3)self.Conv2d_2b_3x3 = conv_block(32, 64, kernel_size=3, padding=1)self.maxpool1 = nn.MaxPool2d(kernel_size=3, stride=2)self.Conv2d_3b_1x1 = conv_block(64, 80, kernel_size=1)self.Conv2d_4a_3x3 = conv_block(80, 192, kernel_size=3)self.maxpool2 = nn.MaxPool2d(kernel_size=3, stride=2)self.Mixed_5b = inception_a(192, pool_features=32)self.Mixed_5c = inception_a(256, pool_features=64)self.Mixed_5d = inception_a(288, pool_features=64)self.Mixed_6a = inception_b(288)self.Mixed_6b = inception_c(768, channels_7x7=128)self.Mixed_6c = inception_c(768, channels_7x7=160)self.Mixed_6d = inception_c(768, channels_7x7=160)self.Mixed_6e = inception_c(768, channels_7x7=192)self.AuxLogits = Noneif aux_logits:self.AuxLogits = inception_aux(768, num_classes)self.Mixed_7a = inception_d(768)self.Mixed_7b = inception_e(1280)self.Mixed_7c = inception_e(2048)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.dropout = nn.Dropout()self.fc = nn.Linear(2048, num_classes)def _transform_input(self, x: Tensor) -> Tensor:if self.transform_input:x_ch0 = torch.unsqueeze(x[:, 0], 1) * (0.229 / 0.5) + (0.485 - 0.5) / 0.5x_ch1 = torch.unsqueeze(x[:, 1], 1) * (0.224 / 0.5) + (0.456 - 0.5) / 0.5x_ch2 = torch.unsqueeze(x[:, 2], 1) * (0.225 / 0.5) + (0.406 - 0.5) / 0.5x = torch.cat((x_ch0, x_ch1, x_ch2), 1)return xdef _forward(self, x: Tensor):# N x 3 x 299 x 299x = self.Conv2d_1a_3x3(x)# N x 32 x 149 x 149x = self.Conv2d_2a_3x3(x)# N x 32 x 147 x 147x = self.Conv2d_2b_3x3(x)# N x 64 x 147 x 147x = self.maxpool1(x)# N x 64 x 73 x 73x = self.Conv2d_3b_1x1(x)# N x 80 x 73 x 73x = self.Conv2d_4a_3x3(x)# N x 192 x 71 x 71x = self.maxpool2(x)# N x 192 x 35 x 35x = self.Mixed_5b(x)# N x 256 x 35 x 35x = self.Mixed_5c(x)# N x 288 x 35 x 35x = self.Mixed_5d(x)# N x 288 x 35 x 35x = self.Mixed_6a(x)# N x 768 x 17 x 17x = self.Mixed_6b(x)# N x 768 x 17 x 17x = self.Mixed_6c(x)# N x 768 x 17 x 17x = self.Mixed_6d(x)# N x 768 x 17 x 17x = self.Mixed_6e(x)# N x 768 x 17 x 17aux = Noneif self.AuxLogits is not None:if self.training:aux = self.AuxLogits(x)# N x 768 x 17 x 17x = self.Mixed_7a(x)# N x 1280 x 8 x 8x = self.Mixed_7b(x)# N x 2048 x 8 x 8x = self.Mixed_7c(x)# N x 2048 x 8 x 8# Adaptive average poolingx = self.avgpool(x)# N x 2048 x 1 x 1x = self.dropout(x)# N x 2048 x 1 x 1x = torch.flatten(x, 1)# N x 2048x = self.fc(x)# N x 1000 (num_classes)return x, auxdef eager_outputs(self, x: Tensor, aux: Optional[Tensor]) -> InceptionOutputs:if self.training and self.aux_logits:return InceptionOutputs(x, aux)else:return x # type: ignore[return-value]def forward(self, x: Tensor) -> InceptionOutputs:x = self._transform_input(x)x, aux = self._forward(x)aux_defined = self.training and self.aux_logitsif torch.jit.is_scripting():if not aux_defined:warnings.warn("Scripted Inception3 always returns Inception3 Tuple")return InceptionOutputs(x, aux)else:return self.eager_outputs(x, aux)class InceptionA(nn.Module):def __init__(self,in_channels: int,pool_features: int,conv_block = None) -> None:super(InceptionA, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch1x1 = conv_block(in_channels, 64, kernel_size=1)self.branch5x5_1 = conv_block(in_channels, 48, kernel_size=1)self.branch5x5_2 = conv_block(48, 64, kernel_size=5, padding=2)self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, padding=1)self.branch_pool = conv_block(in_channels, pool_features, kernel_size=1)def _forward(self, x: Tensor) -> List[Tensor]:branch1x1 = self.branch1x1(x)branch5x5 = self.branch5x5_1(x)branch5x5 = self.branch5x5_2(branch5x5)branch3x3dbl = self.branch3x3dbl_1(x)branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch5x5, branch3x3dbl, branch_pool]return outputsdef forward(self, x: Tensor) -> Tensor:outputs = self._forward(x)return torch.cat(outputs, 1)class InceptionB(nn.Module):def __init__(self,in_channels: int,conv_block = None) -> None:super(InceptionB, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch3x3 = conv_block(in_channels, 384, kernel_size=3, stride=2)self.branch3x3dbl_1 = conv_block(in_channels, 64, kernel_size=1)self.branch3x3dbl_2 = conv_block(64, 96, kernel_size=3, padding=1)self.branch3x3dbl_3 = conv_block(96, 96, kernel_size=3, stride=2)def _forward(self, x: Tensor) -> List[Tensor]:branch3x3 = self.branch3x3(x)branch3x3dbl = self.branch3x3dbl_1(x)branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)branch3x3dbl = self.branch3x3dbl_3(branch3x3dbl)branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)outputs = [branch3x3, branch3x3dbl, branch_pool]return outputsdef forward(self, x: Tensor) -> Tensor:outputs = self._forward(x)return torch.cat(outputs, 1)class InceptionC(nn.Module):def __init__(self,in_channels: int,channels_7x7: int,conv_block = None) -> None:super(InceptionC, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch1x1 = conv_block(in_channels, 192, kernel_size=1)c7 = channels_7x7self.branch7x7_1 = conv_block(in_channels, c7, kernel_size=1)self.branch7x7_2 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))self.branch7x7_3 = conv_block(c7, 192, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_1 = conv_block(in_channels, c7, kernel_size=1)self.branch7x7dbl_2 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_3 = conv_block(c7, c7, kernel_size=(1, 7), padding=(0, 3))self.branch7x7dbl_4 = conv_block(c7, c7, kernel_size=(7, 1), padding=(3, 0))self.branch7x7dbl_5 = conv_block(c7, 192, kernel_size=(1, 7), padding=(0, 3))self.branch_pool = conv_block(in_channels, 192, kernel_size=1)def _forward(self, x: Tensor) -> List[Tensor]:branch1x1 = self.branch1x1(x)branch7x7 = self.branch7x7_1(x)branch7x7 = self.branch7x7_2(branch7x7)branch7x7 = self.branch7x7_3(branch7x7)branch7x7dbl = self.branch7x7dbl_1(x)branch7x7dbl = self.branch7x7dbl_2(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_3(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_4(branch7x7dbl)branch7x7dbl = self.branch7x7dbl_5(branch7x7dbl)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch7x7, branch7x7dbl, branch_pool]return outputsdef forward(self, x: Tensor) -> Tensor:outputs = self._forward(x)return torch.cat(outputs, 1)class InceptionD(nn.Module):def __init__(self,in_channels: int,conv_block = None) -> None:super(InceptionD, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch3x3_1 = conv_block(in_channels, 192, kernel_size=1)self.branch3x3_2 = conv_block(192, 320, kernel_size=3, stride=2)self.branch7x7x3_1 = conv_block(in_channels, 192, kernel_size=1)self.branch7x7x3_2 = conv_block(192, 192, kernel_size=(1, 7), padding=(0, 3))self.branch7x7x3_3 = conv_block(192, 192, kernel_size=(7, 1), padding=(3, 0))self.branch7x7x3_4 = conv_block(192, 192, kernel_size=3, stride=2)def _forward(self, x: Tensor) -> List[Tensor]:branch3x3 = self.branch3x3_1(x)branch3x3 = self.branch3x3_2(branch3x3)branch7x7x3 = self.branch7x7x3_1(x)branch7x7x3 = self.branch7x7x3_2(branch7x7x3)branch7x7x3 = self.branch7x7x3_3(branch7x7x3)branch7x7x3 = self.branch7x7x3_4(branch7x7x3)branch_pool = F.max_pool2d(x, kernel_size=3, stride=2)outputs = [branch3x3, branch7x7x3, branch_pool]return outputsdef forward(self, x: Tensor) -> Tensor:outputs = self._forward(x)return torch.cat(outputs, 1)class InceptionE(nn.Module):def __init__(self,in_channels: int,conv_block = None) -> None:super(InceptionE, self).__init__()if conv_block is None:conv_block = BasicConv2dself.branch1x1 = conv_block(in_channels, 320, kernel_size=1)self.branch3x3_1 = conv_block(in_channels, 384, kernel_size=1)self.branch3x3_2a = conv_block(384, 384, kernel_size=(1, 3), padding=(0, 1))self.branch3x3_2b = conv_block(384, 384, kernel_size=(3, 1), padding=(1, 0))self.branch3x3dbl_1 = conv_block(in_channels, 448, kernel_size=1)self.branch3x3dbl_2 = conv_block(448, 384, kernel_size=3, padding=1)self.branch3x3dbl_3a = conv_block(384, 384, kernel_size=(1, 3), padding=(0, 1))self.branch3x3dbl_3b = conv_block(384, 384, kernel_size=(3, 1), padding=(1, 0))self.branch_pool = conv_block(in_channels, 192, kernel_size=1)def _forward(self, x: Tensor) -> List[Tensor]:branch1x1 = self.branch1x1(x)branch3x3 = self.branch3x3_1(x)branch3x3 = [self.branch3x3_2a(branch3x3),self.branch3x3_2b(branch3x3),]branch3x3 = torch.cat(branch3x3, 1)branch3x3dbl = self.branch3x3dbl_1(x)branch3x3dbl = self.branch3x3dbl_2(branch3x3dbl)branch3x3dbl = [self.branch3x3dbl_3a(branch3x3dbl),self.branch3x3dbl_3b(branch3x3dbl),]branch3x3dbl = torch.cat(branch3x3dbl, 1)branch_pool = F.avg_pool2d(x, kernel_size=3, stride=1, padding=1)branch_pool = self.branch_pool(branch_pool)outputs = [branch1x1, branch3x3, branch3x3dbl, branch_pool]return outputsdef forward(self, x: Tensor) -> Tensor:outputs = self._forward(x)return torch.cat(outputs, 1)class InceptionAux(nn.Module):def __init__(self,in_channels: int,num_classes: int,conv_block = None) -> None:super(InceptionAux, self).__init__()if conv_block is None:conv_block = BasicConv2dself.conv0 = conv_block(in_channels, 128, kernel_size=1)self.conv1 = conv_block(128, 768, kernel_size=5)self.conv1.stddev = 0.01 # type: ignore[assignment]self.fc = nn.Linear(768, num_classes)self.fc.stddev = 0.001 # type: ignore[assignment]def forward(self, x: Tensor) -> Tensor:# N x 768 x 17 x 17x = F.avg_pool2d(x, kernel_size=5, stride=3)# N x 768 x 5 x 5x = self.conv0(x)# N x 128 x 5 x 5x = self.conv1(x)# N x 768 x 1 x 1# Adaptive average poolingx = F.adaptive_avg_pool2d(x, (1, 1))# N x 768 x 1 x 1x = torch.flatten(x, 1)# N x 768x = self.fc(x)# N x 1000return xclass BasicConv2d(nn.Module):def __init__(self,in_channels: int,out_channels: int,**kwargs) -> None:super(BasicConv2d, self).__init__()self.conv = nn.Conv2d(in_channels, out_channels, bias=False, **kwargs)self.bn = nn.BatchNorm2d(out_channels, eps=0.001)def forward(self, x: Tensor) -> Tensor:x = self.conv(x)x = self.bn(x)return F.relu(x, inplace=True)inception3 = Inception3()input1 = torch.rand([1, 3, 299, 299])# print(resnet50)output = inception3(input1)print(output.shape)
ResNet
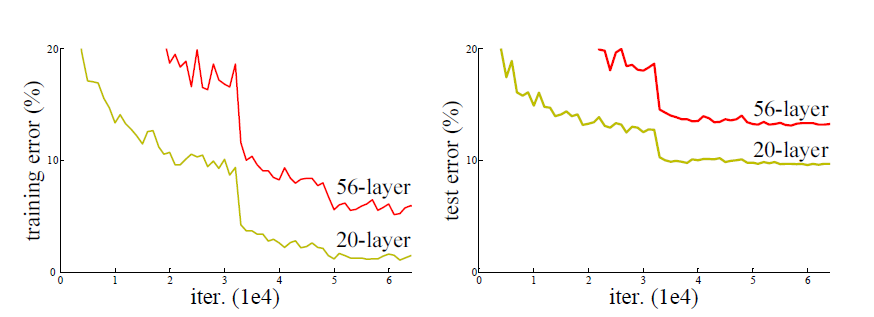
理论上,更深的深度神经网络能提取更多更复杂的特征,但是研究表明随着网络层数的增加,网络训练会变得越来越困难,伴随着出现梯度消失或者梯度爆炸的问题。如下图所示,网络层数从20层增加56层,训练误差和测试误差都显著增加。
Kaiming He在2016年提出了ResNet网络结构,赢得了ILSVRC2015的图像分类和目标检测的冠军,超过了Inception v3。ResNet基于残差学习(Residual Learning)的方式,每次学习只学习残差或者偏差的部分,然后通过shotcut connection的方式,将原始值和残差进行求和,研究表明这样可以在网络层数增加的时候有效的解决梯度消失的问题,因为shotcut connection的方式使得反向传播的参数变得很小,即使残差都没有学习到东西(权重为0),因为叠加求和的原因,理论上可以叠加无限多的层。而实际上残差是有学习到一些有效的特征表示,使得ResNet有着广泛的应用。
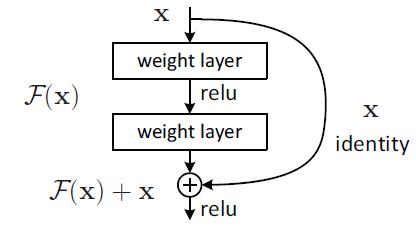
ResNet主要有两种shotcut connection方式;如下图所示,左边是两层结构由两个3x3的卷积层来学习残差信息;右边是三层结构,先通过1x1卷积进行降维,接着是3x3卷积提取特征,再通过1x1卷积升维后进行shotcut connection,这样可以有效降低参数量。
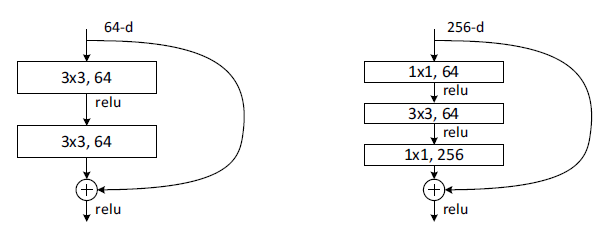
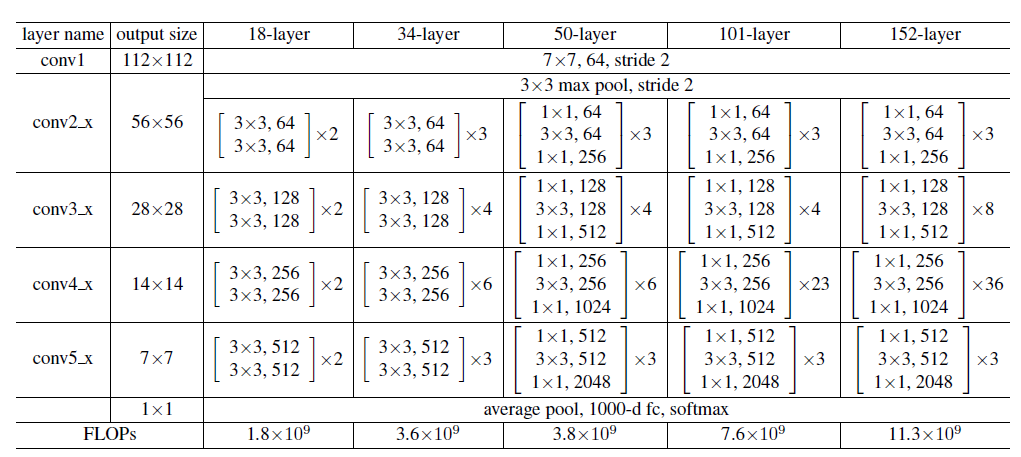
在两种shotcut connection基础上,共有18/34/50/101/152层经典的ResNet结构,如下表所示
import torchfrom torch import nnimport torch.nn.functional as Ffrom torchsummary import summaryclass BasicBlock(nn.Module):expansion = 1def __init__(self, in_channels=64, out_channels=64, stride=1, is_down=False):super(BasicBlock, self).__init__()self.conv1_3x3 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1)self.bn1 = nn.BatchNorm2d(out_channels)self.relu1 = nn.ReLU(inplace=True)self.conv2_3x3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(out_channels)self.relu2 = nn.ReLU(inplace=True)self.is_down = is_downself.downsample_conv = nn.Sequential(nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=2),nn.BatchNorm2d(out_channels))def forward(self, x):identity = xout = self.conv1_3x3(x)out = self.bn1(out)out = self.relu1(out)out = self.conv2_3x3(out)out = self.bn2(out)# 看conv1 有没有下采样 stride=2,利用1x1进行大小对齐if self.is_down:identity = self.downsample_conv(x)out += identityout = self.relu2(out)return outclass Bottleneck(nn.Module):expansion = 4def __init__(self, in_channels, out_channels=64, stride=1, is_down=False):super(Bottleneck, self).__init__()expansion_channels = out_channels*self.expansion# print(expansion_channels)self.in_channels = in_channelsself.out_channels = out_channelsself.conv1_1x1 = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride)self.bn1 = nn.BatchNorm2d(out_channels)self.relu1 = nn.ReLU(inplace=True)self.conv2_3x3 = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1)self.bn2 = nn.BatchNorm2d(out_channels)self.relu2 = nn.ReLU(inplace=True)self.conv3_1x1 = nn.Conv2d(out_channels, expansion_channels, kernel_size=1, stride=1)self.bn3 = nn.BatchNorm2d(expansion_channels)self.relu3 = nn.ReLU(inplace=True)self.is_down = is_downself.downsample_conv = nn.Sequential(nn.Conv2d(in_channels, expansion_channels, kernel_size=1, stride=stride),nn.BatchNorm2d(expansion_channels))def forward(self, x):identity = xout = self.conv1_1x1(x)out = self.bn1(out)out = self.relu1(out)out = self.conv2_3x3(out)out = self.bn2(out)out = self.relu2(out)out = self.conv3_1x1(out)out = self.bn3(out)# 看conv1 有没有下采样 stride=2,利用1x1进行大小对齐if self.is_down | (self.in_channels == self.out_channels):identity = self.downsample_conv(x)out += identityout = self.relu3(out)return outclass ResNet(nn.Module):def __init__(self, layers, block, num_classes):super(ResNet, self).__init__()self.in_channels = 64self.conv1 = nn.Conv2d(3, self.in_channels, kernel_size=7, stride=2, padding=3,bias=False)self.bn = nn.BatchNorm2d(self.in_channels)self.relu = nn.ReLU(inplace=True)self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)layer_in_channels = [i * block.expansion for i in [64, 128, 256, 512]]self.layer1 = self._make_layers(block, layers[0], self.in_channels, 64, stride=1, is_down=False)self.layer2 = self._make_layers(block, layers[1], layer_in_channels[0], 128, stride=2, is_down=True)self.layer3 = self._make_layers(block, layers[2], layer_in_channels[1], 256, stride=2, is_down=True)self.layer4 = self._make_layers(block, layers[3], layer_in_channels[2], 512, stride=2, is_down=True)self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.fc = nn.Linear(layer_in_channels[3], num_classes)def _make_layers(self, block, blocks, in_channels, out_channels, stride, is_down):layers = []layers.append(block(in_channels, out_channels, stride=stride, is_down=is_down))for i in range(1, blocks):layers.append(block(out_channels*block.expansion, out_channels, stride=1, is_down=False))return nn.Sequential(*layers)def forward(self, x):print(x.shape)x = self.conv1(x)x = self.bn(x)x = self.relu(x)print(x.shape)x = self.maxpool(x)print(x.shape)x = self.layer1(x)print(x.shape)x = self.layer2(x)print(x.shape)x = self.layer3(x)print(x.shape)x = self.layer4(x)print(x.shape)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.fc(x)return x
layers = [3, 4, 6, 3]resnet50 = ResNet(layers, block=Bottleneck, num_classes=1000)input1 = torch.rand([1, 3, 224, 224])# print(resnet50)output = resnet50(input1)print(output.shape)layers = [3, 4, 6, 3]resnet34 = ResNet(layers, block=BasicBlock, num_classes=1000)input1 = torch.rand([1, 3, 224, 224])# print(resnet34)output = resnet34(input1)print(output.shape)
值得一提的是,ResNet论文中提到的warmup训练方法也在后面广泛应用,即在初始用小的学习率进行学习,稳定之后再从高的学习率学习。
DenseNet
在ResNet开宗立派之后,ResNet相关的思想遍地开花。CVPR 2017 best paper的DenseNet立足于更密集的连接和更多特征重用,达到更好的性能。
研究表明随着CNN网络层数的增加,网络输入的信息在经过多个卷积层之后,有多少有效的信息留下来。DenseNet认为ResNet通过shotcut connection方式保留输入信息,DenseNet扩大了这种连接,使得连接更加密集。
如下图所示,x1输入为x0,而x2输入为x1和x0,x3的输入为x2,x1和x0,即后面卷积的输入是前面所有层,这样一个L层的就有L*(L+1)/2个连接,而ResNet只有L个连接。与ResNet不同的是,DenseNet不是通过相加的方式来利用连接过来的特征,而是采用concat的方式拼接所有连接的特征来重用特征,以获得更好的性能。由于是concat的导致特征数增大,DenseNet采用1x1卷积对特征数进行调整即Transition Layer,并进行下采样。


DenseNet典型的有121/169/201/264层结构,如下表所示
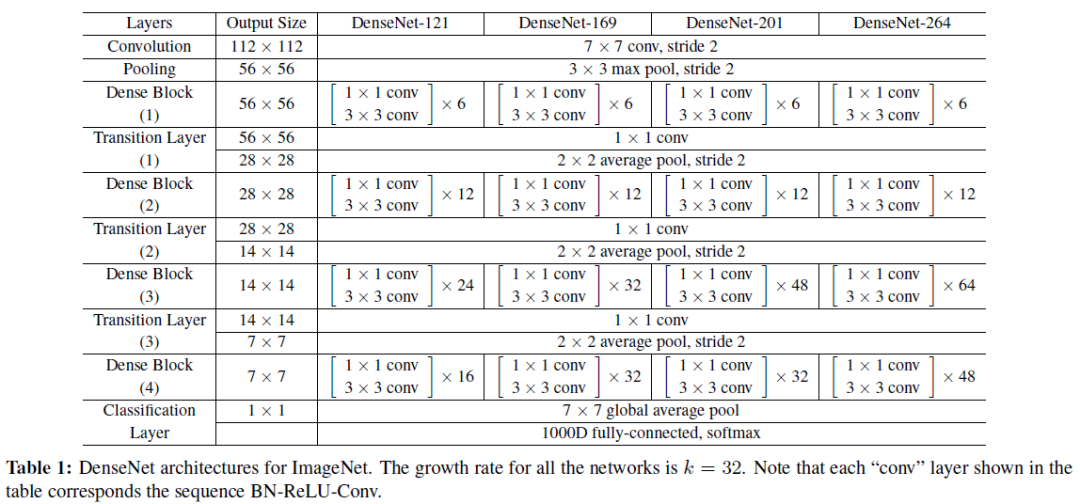
Growth rate决定了多少新信息(特征)传递到下一个卷积操作。
import torchfrom torch import nnimport torch.nn.functional as Ffrom collections import OrderedDictfrom torchsummary import summaryclass _DenseLayer(nn.Module):def __init__(self, num_input_features, bn_size, growth_rate):super(_DenseLayer, self).__init__()self.bn1 = nn.BatchNorm2d(num_input_features)self.relu1 = nn.ReLU(inplace=True)self.conv1 = nn.Conv2d(in_channels=num_input_features, out_channels=bn_size*growth_rate, kernel_size=1, stride=1)self.bn2 = nn.BatchNorm2d(bn_size*growth_rate)self.relu2 = nn.ReLU(inplace=True)self.conv2 = nn.Conv2d(in_channels=bn_size*growth_rate, out_channels=growth_rate, kernel_size=3, stride=1, padding=1)def forward(self, inputs):concat_inputs = torch.cat(inputs, 1)x = self.bn1(concat_inputs)x = self.relu1(x)x = self.conv1(x)x = self.bn2(x)x = self.relu2(x)new_features = self.conv2(x)return new_featuresclass _DenseBlock(nn.ModuleDict):def __init__(self, num_layers, num_input_features, bn_size, growth_rate):super(_DenseBlock, self).__init__()for i in range(num_layers):layer = _DenseLayer(num_input_features + i * growth_rate, bn_size, growth_rate)self.add_module('denselayer%d' % (i + 1), layer)def forward(self, init_features):features = [init_features]for name, _layer in self.items():new_features = _layer(features)features.append(new_features)return torch.cat(features, 1)class _TransitionLayer(nn.Module):def __init__(self, num_input_features, num_output_featurns):super(_TransitionLayer, self).__init__()self.bn = nn.BatchNorm2d(num_input_features)self.relu = nn.ReLU(inplace=True)self.conv = nn.Conv2d(in_channels=num_input_features, out_channels=num_output_featurns, kernel_size=1, padding=1)self.avgpool = nn.AvgPool2d(kernel_size=2, stride=2)def forward(self, x):x = self.bn(x)x = self.relu(x)x = self.conv(x)x = self.avgpool(x)return xclass DenseNet(nn.Module):def __init__(self, in_channels, bn_size, growth_rate, block_config, num_classes=1000):super(DenseNet, self).__init__()self.features = nn.Sequential(OrderedDict([('conv0', nn.Conv2d(3, in_channels, kernel_size=7, stride=2, padding=3,bias=False)),('norm0', nn.BatchNorm2d(in_channels)),('relu0', nn.ReLU(inplace=True)),('pool0', nn.MaxPool2d(kernel_size=3, stride=2, padding=1)),]))num_input_features = in_channelsfor i, num_layers in enumerate(block_config):block = _DenseBlock(num_layers, num_input_features, bn_size, growth_rate)self.features.add_module('denseblock%d' % (i + 1), block)num_input_features = num_input_features + num_layers * growth_rateif i != len(block_config) - 1:transistion = _TransitionLayer(num_input_features, num_input_features // 2)self.features.add_module('transistion%d' % (i + 1), transistion)num_input_features = num_input_features // 2self.features.add_module('norm5', nn.BatchNorm2d(num_input_features))self.avgpool = nn.AdaptiveAvgPool2d((1, 1))self.classifier = nn.Linear(num_input_features, num_classes)def forward(self, x):print(x.shape)features = self.features(x)out = F.relu(features, inplace=True)out = self.avgpool(out)out = torch.flatten(out, 1)out = self.classifier(out)return outblock_config = [6, 12, 24, 16]growth_rate = 32in_channels = 64bn_size = 4densenet121 = DenseNet(in_channels, bn_size, growth_rate, block_config)input1 = torch.rand([1, 3, 224, 224])# print(densenet121)output = densenet121(input1)print(output.shape)# torch.Size([1, 1000]
EfficientNet
按直觉,更大的网络有更好的性能,同时也需要更大的计算量。EfficientNet将网络结构理解为分辨率,深度和宽度,更大的分辨率输入需要更深的网络增加感受野,同时需要更宽即更多的通道来获取更细致的特征。EfficientNet分析分辨率,深度,宽度和计算量之间的平衡。
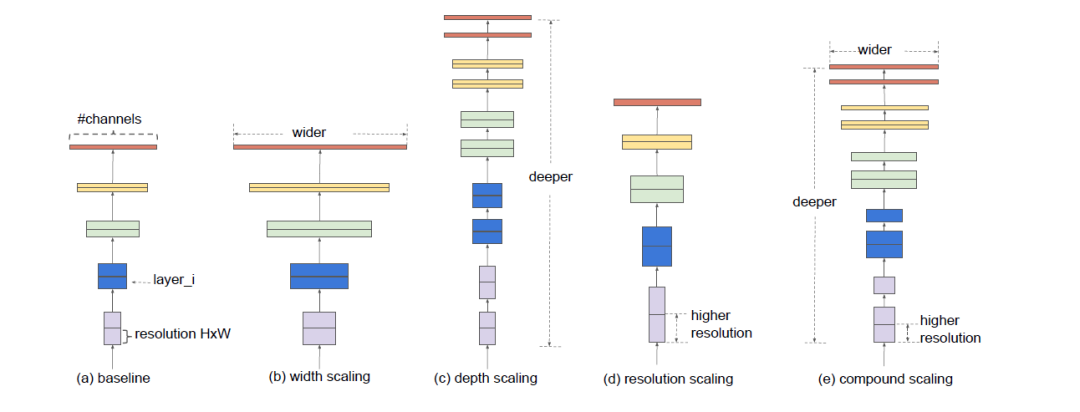
EfficientNet实验分析分辨率,深度,宽度的增加精度也会增加,但是在80%之后,再增加分辨率,深度,宽度,精度的收益就变得缓慢甚至消失,如下图所示。
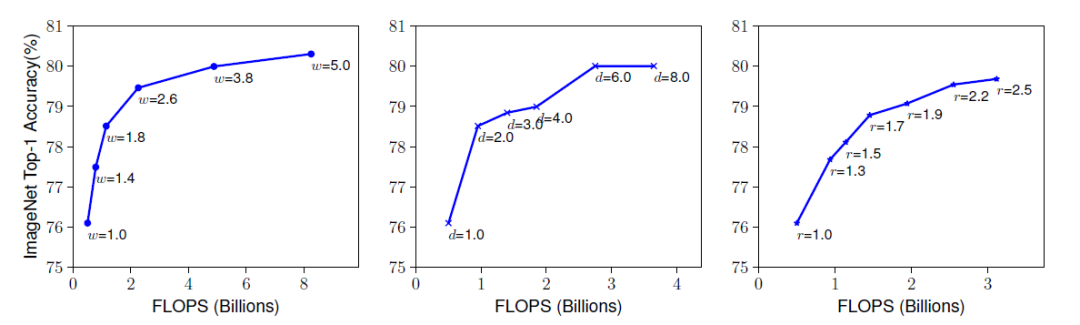
EfficientNet将分辨率,深度,宽度的变化集中到一个公共的参数(人为决定),决定有多少资源可用于分辨率,深度,宽度的增长,并约束其进行计算量(FLOPS)的增长,公式中为2,即模型增加到(公共的参数),运行FlOPS增加2的(公共的参数)指数倍。最佳的参数alpha,beta,gamma,通过网格搜索获得。
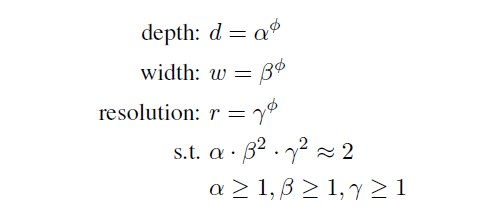
论文中先搜索基础模型EfficientNetB0的参数,设置公共参数为1,搜索最佳为alpha = 1.2; beta=1.1,gamma=1.15;在此基础上,固定alpha,beta,gamma,变化不同公共参数,得到不同的分辨率,深度,宽度,生成EfficientNetB1-B7。
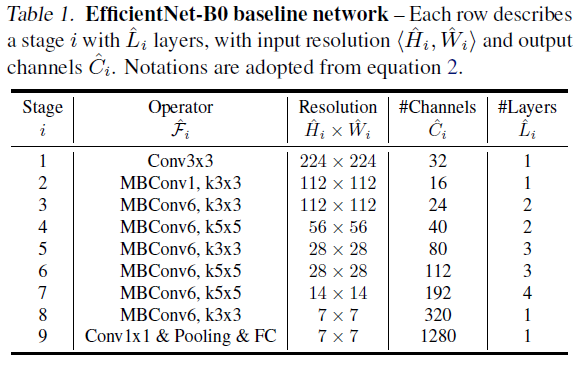
而EfficientNet的基础网络结构采用MobileNetv2中反向BottleNeck层即MBconv和SE注意力模块, 激活函数才有RELU6。结构如下EfficientNetB0,在此基础上,变更参数生成EfficientNetB1-B7。
import torchfrom torch import Tensorfrom torch import nnimport torch.nn.functional as Ffrom collections import OrderedDictfrom torchsummary import summaryimport torchvisionimport copyimport mathimport torchfrom torch import nn, Tensorfrom typing import Any, Callable, List, Optional, Sequencefrom functools import partial# from torchvision.ops import StochasticDepthdef _make_divisible(v: float, divisor: int, min_value= None) -> int:"""This function is taken from the original tf repo.It ensures that all layers have a channel number that is divisible by 8It can be seen here:https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py"""if min_value is None:min_value = divisornew_v = max(min_value, int(v + divisor / 2) // divisor * divisor)# Make sure that round down does not go down by more than 10%.if new_v < 0.9 * v:new_v += divisorreturn new_vclass ConvNormActivation(torch.nn.Sequential):"""Configurable block used for Convolution-Normalzation-Activation blocks.Args:in_channels (int): Number of channels in the input imageout_channels (int): Number of channels produced by the Convolution-Normalzation-Activation blockkernel_size: (int, optional): Size of the convolving kernel. Default: 3stride (int, optional): Stride of the convolution. Default: 1padding (int, tuple or str, optional): Padding added to all four sides of the input. Default: None, in wich case it will calculated as ``padding = (kernel_size - 1) // 2 * dilation``groups (int, optional): Number of blocked connections from input channels to output channels. Default: 1norm_layer (Callable[..., torch.nn.Module], optional): Norm layer that will be stacked on top of the convolutiuon layer. If ``None`` this layer wont be used. Default: ``torch.nn.BatchNorm2d``activation_layer (Callable[..., torch.nn.Module], optinal): Activation function which will be stacked on top of the normalization layer (if not None), otherwise on top of the conv layer. If ``None`` this layer wont be used. Default: ``torch.nn.ReLU``dilation (int): Spacing between kernel elements. Default: 1inplace (bool): Parameter for the activation layer, which can optionally do the operation in-place. Default ``True``"""def __init__(self,in_channels: int,out_channels: int,kernel_size: int = 3,stride: int = 1,padding: [int] = None,groups: int = 1,norm_layer = torch.nn.BatchNorm2d,activation_layer = torch.nn.ReLU,dilation: int = 1,inplace: bool = True,) -> None:if padding is None:padding = (kernel_size - 1) // 2 * dilationlayers = [torch.nn.Conv2d(in_channels,out_channels,kernel_size,stride,padding,dilation=dilation,groups=groups,bias=norm_layer is None,)]if norm_layer is not None:layers.append(norm_layer(out_channels))if activation_layer is not None:layers.append(activation_layer(inplace=inplace))super().__init__(*layers)self.out_channels = out_channelsclass SqueezeExcitation(torch.nn.Module):"""This block implements the Squeeze-and-Excitation block from https://arxiv.org/abs/1709.01507 (see Fig. 1).Parameters ``activation``, and ``scale_activation`` correspond to ``delta`` and ``sigma`` in in eq. 3.Args:input_channels (int): Number of channels in the input imagesqueeze_channels (int): Number of squeeze channelsactivation (Callable[..., torch.nn.Module], optional): ``delta`` activation. Default: ``torch.nn.ReLU``scale_activation (Callable[..., torch.nn.Module]): ``sigma`` activation. Default: ``torch.nn.Sigmoid``"""def __init__(self,input_channels: int,squeeze_channels: int,activation = torch.nn.ReLU,scale_activation = torch.nn.Sigmoid,) -> None:super().__init__()self.avgpool = torch.nn.AdaptiveAvgPool2d(1)self.fc1 = torch.nn.Conv2d(input_channels, squeeze_channels, 1)self.fc2 = torch.nn.Conv2d(squeeze_channels, input_channels, 1)self.activation = activation()self.scale_activation = scale_activation()def _scale(self, input: Tensor) -> Tensor:scale = self.avgpool(input)scale = self.fc1(scale)scale = self.activation(scale)scale = self.fc2(scale)return self.scale_activation(scale)def forward(self, input: Tensor) -> Tensor:scale = self._scale(input)return scale * inputclass MBConvConfig:# Stores information listed at Table 1 of the EfficientNet paperdef __init__(self,expand_ratio: float, kernel: int, stride: int,input_channels: int, out_channels: int, num_layers: int,width_mult: float, depth_mult: float) -> None:self.expand_ratio = expand_ratioself.kernel = kernelself.stride = strideself.input_channels = self.adjust_channels(input_channels, width_mult)self.out_channels = self.adjust_channels(out_channels, width_mult)self.num_layers = self.adjust_depth(num_layers, depth_mult)def __repr__(self) -> str:s = self.__class__.__name__ + '('s += 'expand_ratio={expand_ratio}'s += ', kernel={kernel}'s += ', stride={stride}'s += ', input_channels={input_channels}'s += ', out_channels={out_channels}'s += ', num_layers={num_layers}'s += ')'return s.format(**self.__dict__)@staticmethoddef adjust_channels(channels: int, width_mult: float, min_value: [int] = None) -> int:return _make_divisible(channels * width_mult, 8, min_value)@staticmethoddef adjust_depth(num_layers: int, depth_mult: float):return int(math.ceil(num_layers * depth_mult))class MBConv(nn.Module):def __init__(self, cnf: MBConvConfig,stochastic_depth_prob: float,norm_layer,se_layer = SqueezeExcitation) -> None:super().__init__()if not (1 <= cnf.stride <= 2):raise ValueError('illegal stride value')self.use_res_connect = cnf.stride == 1 and cnf.input_channels == cnf.out_channelslayers = []activation_layer = nn.ReLU6# expandexpanded_channels = cnf.adjust_channels(cnf.input_channels, cnf.expand_ratio)if expanded_channels != cnf.input_channels:layers.append(ConvNormActivation(cnf.input_channels, expanded_channels, kernel_size=1,norm_layer=norm_layer, activation_layer=activation_layer))# depthwiselayers.append(ConvNormActivation(expanded_channels, expanded_channels, kernel_size=cnf.kernel,stride=cnf.stride, groups=expanded_channels,norm_layer=norm_layer, activation_layer=activation_layer))# squeeze and excitationsqueeze_channels = max(1, cnf.input_channels // 4)layers.append(se_layer(expanded_channels, squeeze_channels, activation=partial(nn.ReLU6, inplace=True)))# projectlayers.append(ConvNormActivation(expanded_channels, cnf.out_channels, kernel_size=1, norm_layer=norm_layer,activation_layer=None))self.block = nn.Sequential(*layers)# self.stochastic_depth = StochasticDepth(stochastic_depth_prob, "row")self.out_channels = cnf.out_channelsdef forward(self, input: Tensor) -> Tensor:result = self.block(input)# if self.use_res_connect:# result = self.stochastic_depth(result)# result += inputreturn resultclass EfficientNet(nn.Module):def __init__(self,inverted_residual_setting,dropout: float,stochastic_depth_prob: float = 0.2,num_classes: int = 1000,block = None,norm_layer = None,**kwargs) -> None:"""EfficientNet main classArgs:inverted_residual_setting (List[MBConvConfig]): Network structuredropout (float): The droupout probabilitystochastic_depth_prob (float): The stochastic depth probabilitynum_classes (int): Number of classesblock (Optional[Callable[..., nn.Module]]): Module specifying inverted residual building block for mobilenetnorm_layer (Optional[Callable[..., nn.Module]]): Module specifying the normalization layer to use"""super().__init__()if not inverted_residual_setting:raise ValueError("The inverted_residual_setting should not be empty")elif not (isinstance(inverted_residual_setting, Sequence) andall([isinstance(s, MBConvConfig) for s in inverted_residual_setting])):raise TypeError("The inverted_residual_setting should be List[MBConvConfig]")if block is None:block = MBConvif norm_layer is None:norm_layer = nn.BatchNorm2dlayers = []# building first layerfirstconv_output_channels = inverted_residual_setting[0].input_channelslayers.append(ConvNormActivation(3, firstconv_output_channels, kernel_size=3, stride=2, norm_layer=norm_layer,activation_layer=nn.ReLU6))# building inverted residual blockstotal_stage_blocks = sum([cnf.num_layers for cnf in inverted_residual_setting])stage_block_id = 0for cnf in inverted_residual_setting:stage = []for _ in range(cnf.num_layers):# copy to avoid modifications. shallow copy is enoughblock_cnf = copy.copy(cnf)# overwrite info if not the first conv in the stageif stage:block_cnf.input_channels = block_cnf.out_channelsblock_cnf.stride = 1# adjust stochastic depth probability based on the depth of the stage blocksd_prob = stochastic_depth_prob * float(stage_block_id) / total_stage_blocksstage.append(block(block_cnf, sd_prob, norm_layer))stage_block_id += 1layers.append(nn.Sequential(*stage))# building last several layerslastconv_input_channels = inverted_residual_setting[-1].out_channelslastconv_output_channels = 4 * lastconv_input_channelslayers.append(ConvNormActivation(lastconv_input_channels, lastconv_output_channels, kernel_size=1,norm_layer=norm_layer, activation_layer= nn.ReLU6))self.features = nn.Sequential(*layers)self.avgpool = nn.AdaptiveAvgPool2d(1)self.classifier = nn.Sequential(nn.Dropout(p=dropout, inplace=True),nn.Linear(lastconv_output_channels, num_classes),)for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:nn.init.zeros_(m.bias)elif isinstance(m, (nn.BatchNorm2d, nn.GroupNorm)):nn.init.ones_(m.weight)nn.init.zeros_(m.bias)elif isinstance(m, nn.Linear):init_range = 1.0 / math.sqrt(m.out_features)nn.init.uniform_(m.weight, -init_range, init_range)nn.init.zeros_(m.bias)def _forward_impl(self, x: Tensor) -> Tensor:x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return xdef forward(self, x: Tensor) -> Tensor:return self._forward_impl(x)def _efficientnet_conf(width_mult: float, depth_mult: float, **kwargs):bneck_conf = partial(MBConvConfig, width_mult=width_mult, depth_mult=depth_mult)inverted_residual_setting = [bneck_conf(1, 3, 1, 32, 16, 1),bneck_conf(6, 3, 2, 16, 24, 2),bneck_conf(6, 5, 2, 24, 40, 2),bneck_conf(6, 3, 2, 40, 80, 3),bneck_conf(6, 5, 1, 80, 112, 3),bneck_conf(6, 5, 2, 112, 192, 4),bneck_conf(6, 3, 1, 192, 320, 1),]return inverted_residual_settingdef _efficientnet_model(arch: str,inverted_residual_setting,dropout: float,**kwargs) -> EfficientNet:model = EfficientNet(inverted_residual_setting, dropout, **kwargs)return modelinverted_residual_setting = _efficientnet_conf(width_mult=1.0, depth_mult=1.0)efficientnet_b0 = _efficientnet_model("efficientnet_b0", inverted_residual_setting, 0.2)input1 = torch.rand([1, 3, 224, 224])# print(densenet121)output = efficientnet_b0(input1)print(output.shape)inverted_residual_setting = _efficientnet_conf(width_mult=1.0, depth_mult=1.1)efficientnet_b1 = _efficientnet_model("efficientnet_b1", inverted_residual_setting, 0.2)input1 = torch.rand([1, 3, 224, 224])# print(densenet121)output = efficientnet_b1(input1)print(output.shape)
总结
本文梳理的卷积神经网络发展至今经典的网络结构和关键实现,希望对你有帮助,总结如下:
LeNet5: CNN开山之作,卷积层+pooling层
AlexNet:历史性的突破,引领深度学习普及,Relu
VGG: 特征提取神器
googleNet Inception系列: 综合多个卷积核多个感受野,探索模型更wider
ResNet:里程碑式研究,使得深度学习更deeper成为可能,主要结构是残差学习
DenseNet:探索信息在深层卷积层的传递方式,采用更密集的连接和特征concat重用
EfficientNet:考虑高性能CNN模型在深度,宽度和分辨率上的综合表现。
参考资料
Gradient-based learning applied to document recognition (Letnet-5)
mageNet Classification with Deep Convolutional Neural Networks (AlexNet)
Very Deep Convolutional Networks for Large-Scale Image Recognition (VGG)
Going deeper with convolutions (Inception v1)
Rethinking the inception architecture for computer vision(Inception v2/v3)
Inception-v4, inception-resnet and the impact of residual connections on learning (Inception-v4)
Deep Residual Learning for Image Recognition (ResNet)
Densely Connected Convolutional Networks (DenseNet)
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks (EfficientNet)
注:
本文版权归DataFountain和作者本人所有,转载需授权。
本文仅代表作者个人观点。如有不同看法,欢迎留言反馈/讨论。
—End—
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~