
车牌识别综述阅读笔记
车牌识别综述阅读笔记
目前车牌识别所遇到的难点主要体现在三个方面,主要体现在:车牌倾斜,图像噪声,还有车牌模糊。
目前对车牌识别的方法大致可以分为三类,模板匹配,SVM,和深度学习的方法,其中,深度学习的方法用的更加广泛,深度学习上采用车牌识别的方法可分为直接检测算法和间接检测算法。对于车牌识别,有着不同的数据集,我们需要对不同公共数据集进行比较和说明,然后对针对不同的数据集,工作站,精度和时间进行比较,这样才能全面的衡量算法的优势和劣势,然后再对未来研究方向进行展望。
模板匹配:基于matlab+模板匹配的车牌识别
SVM:毕业设计 python opencv实现车牌识别 界面
深度学习方法基于u-net,cv2以及cnn的中文车牌定位,矫正和端到端识别软件
一、车牌识别技术的介绍
车牌识别是一项成熟但不完善的技术,在现阶段,车牌识别已经有很多产品出来了,比如说停车场车牌自动识别,这些大多数都是针对固定角度,目前针对复杂环境下的车牌识别,识别还有待提高,这些复杂环境主要是指:灯光条件,扭曲的车牌,还有泥土遮挡的车牌。车牌识别技术可以分类三个部分,车牌定位, 字符分割 ,车牌识别。由于字符分割在一定程度下会影响识别率,最近就有一些人提出免分割的车牌识别,将车牌识别分割成两个部分,车牌定位,车牌识别。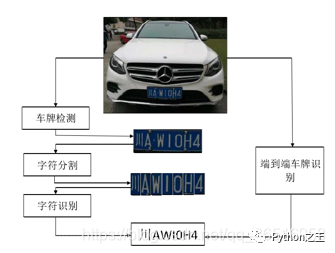
车牌识别的研究内容已经从传统的图像转向复杂的环境。主要的挑战分为三个方面
1:有挑战的数据集:比如说像Caltech car 还有English LP 数据集,图像比较简单,而像LP和UFPR-ALPR数据集,在一些图片中存在很多辆车,而且车辆位置不一定在图像的中间。
2:噪声污染,在现实生活中,往往会受到天气因素的影响,这些成像的图片的背景不再是间的的停车场,而是有可能有一些在斑马线上面来来往往的行人。
3:模糊图像:主要是产生在高速公路监控上面。由于车辆行驶速度快,所以摄像机有可能会拍摄到模糊的图片,比如说,在15971197的图片中,车辆可能只有533522,其中截取的图片可能只有123*96,相当于只占到了图片中的0.2%,在这样一个小尺寸的图片上检测会有一定的难度。
基于深度学习的车牌定位可分为直接定位和间接定位,直接定位把车牌识别当成一个目标检测模型,比如像SSD还有YOLO等等,只需要改变最后一层的卷积层就可以了,把它定成所需要识别的类别。基于一个车辆只有一个车牌的情形,间接定位首先定位到车牌的相关物体,然后再定位到车牌。定位到车牌之后,就需要对车牌进行字符分割,基于字符分割的方法有连接成分分析,投影分析,字符先验知识,字符轮廓等等 。在没有得到高精度分类器下面的分割结果,是很难得到准确的字符分类的,
二、车牌识别的难点
1.倾斜车牌(倾斜矫正)
车牌倾斜所带来的挑战,车牌倾斜分为垂直倾斜和水平倾斜,这些倾斜会导致字符变形,从而影响识别率,如果可以将物体的姿态和部分变形从纹理和形状中解脱出来,会有利于后面的预测,比如说车牌的矫正可以看作是仿射变换的过程。那么,如何找到这个变换矩阵也是一个难点所在。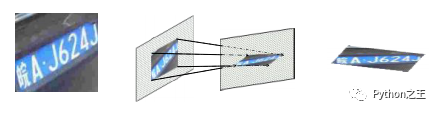
J提出了一种STN计算仿射变换矩阵。由于一个图像只需要6个参数矩阵就可以变换成任意的图像,比如旋转,缩小,放大等等,具体可以参考博客:STN:空间变换网络(Spatial Transformer Network)
2.图像噪声(图像去噪)
在自然环境下面,采集到的图片往往有很多噪声,下表是一些文献对噪声的处理方法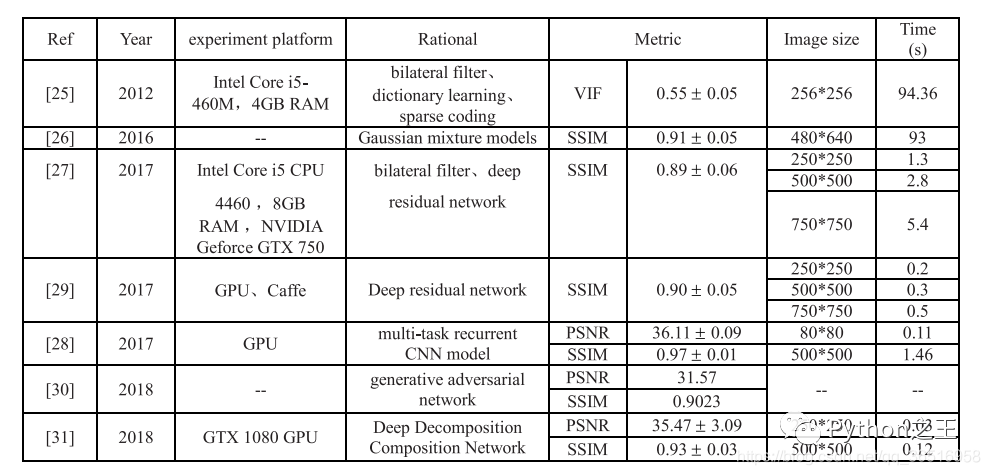
其中[25]和[26]因为不满足实时性要求,所以不可取,在表格中,SSIM为结构相似度指标,VIF为视觉信息保真度,PSNR为峰值信噪比。SSIM越高,说明去噪算法在图像结构上的效果越接近真实的标签值。VIF和SSIM的取值范围均为[0,1]。数值越大,越接近干净的图像。
[27]Fu等人使用了名为DerainNet的深层网络架构来从单一图像中去除雨痕。
X. Fu, J. Huang, X. Ding, Y. Liao, and J. Paisley, ‘‘Clearing the skies: A deep network architecture for single-image rain removal,’’ IEEE Trans. Image Process., vol. 26, no. 6, pp. 2944–2956, Jun. 2017
[28] Yang等人提出了一种利用深度联合雨点检测和去除单一图像的方法。
W. Yang, R. T. Tan, J. Feng, J. Liu, Z. Guo, and S. Yan, ‘‘Deep joint rain detection and removal from a single image,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 1685–1694.
[29] X. Fu, J. Huang, D. Zeng, Y. Huang, X. Ding, and J. Paisley, ‘‘Removing rain from single images via a deep detail network,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 1715–1723.
[30] R. Qian, R. T. Tan, W. Yang, J. Su, and J. Liu, ‘‘Attentive generative adversarial network for raindrop removal from a single image,’’ in Proc. IEEE/CVF Conf. Comput. Vis. Pattern Recognit., Jun. 2018, pp. 2482–2491.
[31] S. Li, W. Ren, J. Zhang, J. Yu, and X. Guo, ‘‘Fast single image rain removal via a deep omposition-composition network,’’ 2018, arXiv:1804.02688. [Online]. Available: https://arxiv.org/abs/1804.02688dec
3.模糊车牌(提高分辨率)
在目标检测领域,小目标的车牌识别是很难的,由于车牌在整幅图片中占比很小,所以很容易出现低分辨率和噪声,给我们的检测带来了一些困难。通过插值直接上采样可以作为低分辨率识别的一种可能的解决方案,但这对后续的字符识别是不利的,或者通过学习小目标在多个尺度上的表示来检测小目标是很耗时的。因此,有必要寻找一种有效提高小目标车牌分辨率的方法。
Li等人使用[32]感知GAN进行内部提升,从小物体到“超分辨”物体的表现,实现与大型物体相似的特征更具鉴别性的检测,由于GANS训练很困难、Tolstikhin等人[33]研究了cascade的使用生成模型来解决模型缺失的训练问题。Radford等人[34]和Salimans等人[35]的目的是使计数器生成网络更稳定、更容易微调。Singh等人[36]提出了一种名为DirectCapsNet的双定向胶囊网络,用于识别非常低分辨率的图像。其中文献[47]在限速90km/h的道路上拍摄数据集,利用盲反卷积算法反求模糊图像的清晰图像,字符错误率从23%降低到9%,提高了2.5倍。处理时间约0.5秒,在实时性上有一定差距。生成对抗网络也可以提高小目标识别的准确性,但由于网络的复杂性,训练起来比较困难,因此如何结合生成对抗网络进行端到端识别还需要进一步研究
[32] J. Li, X. Liang, Y. Wei, T. Xu, J. Feng, and S. Yan, ‘‘Perceptual generative adversarial networks for small object detection,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 1951–1959.
[33] I. O. Tolstikhin, S. Gelly, O. Bousquet, C.-J. Simon-Gabriel, and B. Schölkopf, ‘‘AdaGAN: Boosting generative models,’’ in Proc. Adv. Neural Inf. Process. Syst., 2017, pp. 5424–5433. [34] A. Radford, L. Metz, and S. Chintala, ‘‘Unsupervised representation learning with deep convolutional generative adversarial networks,’’ 2016, arXiv:1511.06434v2. [Online]. Available: https://arxiv. org/abs/1511.06434
[35] T. Salimans, I. Goodfellow, W. Zaremba, V. Cheung, A. Radford, X. Chen, and X. Chen, ‘‘Improved techniques for training GANs,’’ Proc. Adv. Neural Inf. Process. Syst., 2016, pp. 2234–2242.
[36]M. Singh, S. Nagpal, R. Singh, and M. Vatsa, ‘‘Dual directed capsule network for very low resolution image recognition,’’ in Proc. IEEE/CVF Int. Conf. Comput. Vis. (ICCV), Oct. 2019, pp. 340–349.
[47]P. Svoboda, M. Hradis, L. Marsik, and P. Zemcik, ‘‘CNN for license plate motion deblurring,’’ in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2016, pp. 3832–3836
三、车牌定位
车牌定位就是提取输入图片的一部分区域。这部分区域的内容是汉字+字母+数字,传统的车牌定位算法根据直观的特征可以分为四类:基于文本的检测、基于颜色的检测、基于字符的检测和连接分量的检测。这些直观的特征容易受到环境的影响,而深度学习可以通过像素信息提取出更深层的特征。定位算法分为直接定位和间接定位两种。直接定位指的是回归网络直接预测车牌的坐标,以及长度和宽度,而间接定位指间接获取车牌的信息通过其他指标,很容易找到车辆,例如,检测汽车或汽车的尾灯首先然后计算板坐标。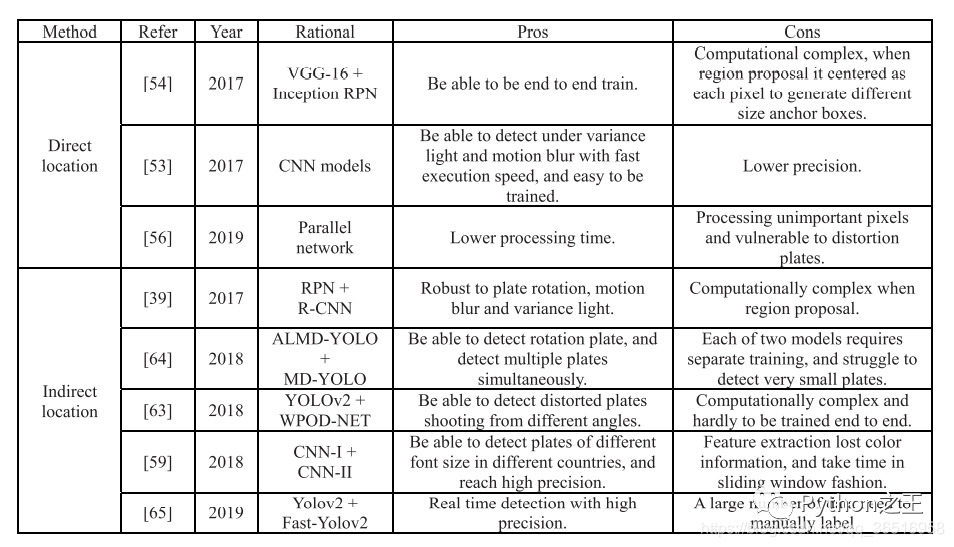
1)直接检测
直接检测车牌就是输入一张图片直接得到车牌图片的高宽和位置信息。训练的时候,采用欧氏距离等损失函数计算参数梯度,直接检测可以节约时间成本,但不如间接检测准确。
Kurpiel等[53]将输入图像分割成120像素宽180像素高的子区域,形成重叠的网格。然后将每个子区域发送给9层的CNN,得到一个置信值,输出值为[0,1]。车牌中心越向外移动,得分越低,由1降为0。最后,结合所有图像子区域的输出值来估计车牌的位置,使车牌中心更接近得分最高的左或右子区域。其检测准确率达到0.87,召回率为0.83,处理时间为0.23秒。
Li等人[54]提出了一种端到端训练的统一深度神经网络(网络结构和Faster RCNN相似),用于同时定位和识别车牌。在定位到车牌后,使用RNNs+CTC进行免分割的车牌识别。
Xiang等人[56]提出了一种用于复杂场景车牌检测的高效轻量化全卷积网络, 这个网络由两个平行的分支组成。前景分支将图像采样到原图像的1/8,背景分支的主要部分用密集块[57]构建,每个块包含一系列相连的卷积层。采用带stride 2的3 3卷积,而不是在每个块中对子样本特征映射进行池化处理,在不影响精度的前提下降低了计算成本.
[53] F. Delmar Kurpiel, R. Minetto, and B. T. Nassu, ‘‘Convolutional neural networks for license plate detection in images,’’ in Proc. IEEE Int. Conf. Image Process. (ICIP), Sep. 2017, pp. 3395–3399.
[54] H. Li, P. Wang, and C. Shen, ‘‘Towards End-to-End car license plates detection and recognition with deep neural networks,’’ 2017, arXiv:1709.08828. [Online]. Available: http://arxiv.org/abs/1709.08828
[56] H. Xiang, Y. Zhao, Y. Yuan, G. Zhang, and X. Hu, ‘‘Lightweight fully convolutional network for license plate detection,’’ Optik, vol. 178, pp. 1185–1194, Feb. 2019.
[57] G. Huang, Z. Liu, L. Van Der Maaten, and K. Q. Weinberger, ‘‘Densely connected convolutional networks,’’ in Proc. IEEE Conf. Comput. Vis. Pattern Recognit. (CVPR), Jul. 2017, pp. 2261–2269
2)间接定位
在大多数情况下,直接定位算法的精度低于间接定位算法,而且,大多数文献使用YOLO等版本进行车牌检测,间接检测算法由两种不同的网络组成,可以接受一定程度的光变化、畸变和模糊。
一些研究者利用车牌与车体之间的先验知识,如后灯与车牌[58]的位置关系,将问题转化为更容易检测的目标。Li等人[59]采用级联框架读取车牌,首先检测字符区域,然后提取车牌图片。该检测模型的准确率达到97%左右,召回率达到95%以上。Dong等人[39]使用由快速区域建议网络和R-CNN网络组成的级联结构提取车牌,首先,一个轻量级的RPN网络[17]以下采样图像作为输入,生成候选车牌。然后,采样器从原始高分辨率图像中提取感兴趣区域(region of interest, roi)。提取的小块输入R-CNN网络对候选车牌进行分类,回归车牌的四角。该车牌检测器比faster R-CNN速度快1.5倍,体积小57倍,准确率达到96%以上。Silva等人[62]使用YOLOv2网络检测车辆,不做任何修改和细化,只是将网络作为一个黑盒,在PASCAL-VOC数据集上合并cars和buses这两类,忽略其他类。根据YOLO、SSD和STN的见解,WPOD-NET被提出用于检测各种不同扭曲的车牌,并回归仿射变换的系数,将扭曲的车牌解扭曲为类似正面视图的矩形。Xie等[63]受到YOLO框架的启发,提出了一种基于cnn的MDYOLO方法来实现多向车牌检测。与YOLO类似,每个输入图像被划分为规则的7 7个网格单元,使用车牌中心所在的单元检测车牌,并预测每个单元的2个边框和一个置信度分数。与YOLO不同的是,MD-YOLO引入角度信息,引导模型回归并确定给定车牌图像的旋转角度。提出了角偏差惩罚因子(ADPF)来近似预测值与标签值的交点比例。为了识别负旋转角值,激活函数选择了泄漏函数和恒等函数,而不是ReLU函数。考虑到车牌通常很小,在实施MDYOLO之前,我们使用了一个前置CNN注意模型ALMDYOLO。该检测模型在GPU GTX980上的处理时间为5ms,准确率达到99%以上。Laroca等人[64]通过评估和优化不同的Yolo模型,并进行各种修改,实现了该系统,旨在在每个阶段实现最佳的速度/精度权衡。车牌检测阶段,考虑到车牌可能只占很小的部分图片,和其他文本块像交通标志可能会混淆牌照,相同的检测过程采用[62],首次检测到的车辆,然后检测牌照。该系统在8个不同的数据集上平均查准率为98.37%,平均查全率为99.92%
[58]M. R. Asif, Q. Chun, S. Hussain, M. S. Fareed, and S. Khan, ‘‘Multinational vehicle license plate detection in complex backgrounds,’’ J. Vis. Commun. Image Represent., vol. 46, pp. 176–186, Jul. 2017
[59]H. Li, P. Wang, M. You, and C. Shen, ‘‘Reading car license plates using deep neural networks,’’ Image Vis. Comput., vol. 72, pp. 14–23, Apr. 2018.
[39] M. Dong, D. He, C. Luo, D. Liu, and W. Zeng, ‘‘A CNN-based approach for automatic license plate recognition in the wild,’’ in Proc. Brit. Mach. Vis. Conf., 2017, pp. 1–12
[62]S. M. Silva and C. R. Jung, ‘‘License plate detection and recognition in
unconstrained scenarios,’’ in Proc. Eur. Conf. Comput. Vis., Sep. 2018,
pp. 593–609.
[63] L. Xie, T. Ahmad, L. Jin, Y. Liu, and S. Zhang, ‘‘A new CNN-based method for multi-directional car license plate detection,’’ IEEE Trans. Intell. Transp. Syst., vol. 19, no. 2, pp. 507–517, Feb. 2018.
[64] R. Laroca, L. A. Zanlorensi, G. R. Gonçalves, E. Todt, W. R. Schwartz, and D. Menotti, ‘‘An efficient and layout-independent automatic license plate recognition system based on the YOLO detector,’’ 2019, arXiv:1909.01754. [Online]. Available: https://arxiv.org/abs/1909.01754
四、车牌识别
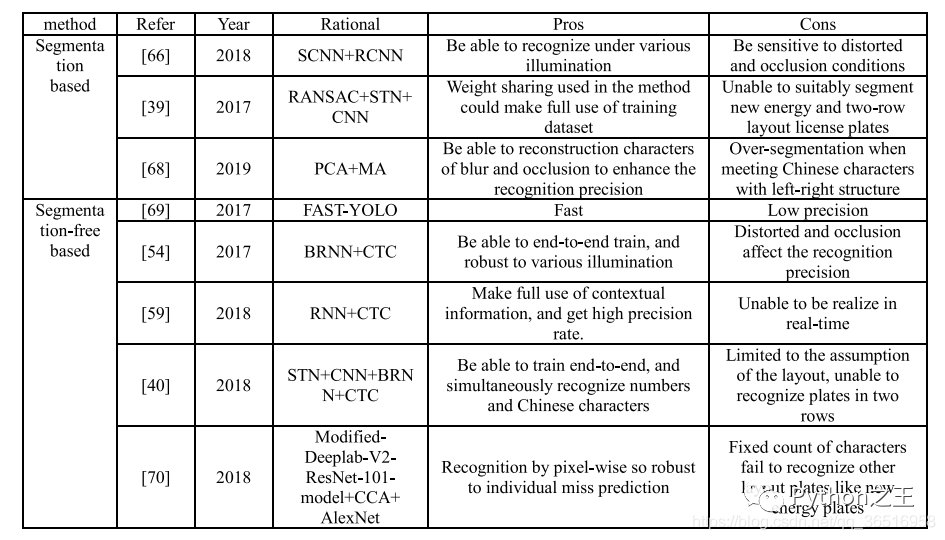
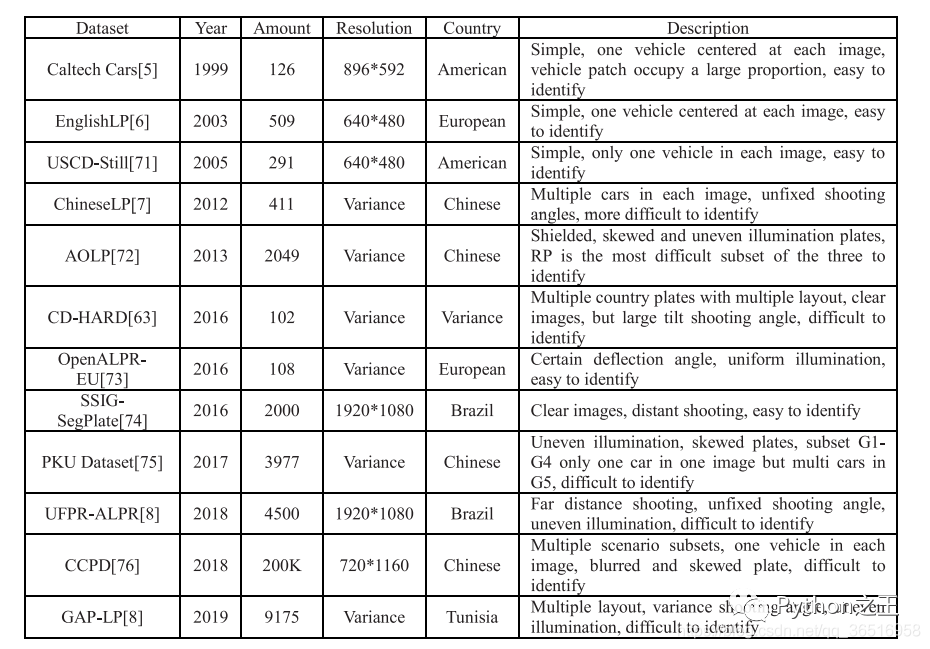
这张表比较了现有公共车牌数据集的数量和分辨率,并描述了遮挡和模糊等其他情况。其中,CD-HARD是从汽车数据集中挑选出来的具有挑战性的图像。此外,常见的目标检测数据集如PASAL-VOC、ImageNet和COCO也包含了一些车辆类,但由于这些数据集不是专用的车牌数据集,所以在表中没有进行比较。像SSIG这样的数据集,大量使用了车辆的前视图,没有大角度偏转的居中图像,在大多数算法中都可以达到较高的精度。但是AOLP等数据集包含大量的车牌图像,如光照不均匀、倾斜等,会增加识别的难度。
1)基于分割的车牌识别
首先来说,分割的方法有:连接成分分析,投影分析,字符的先验知识,字符轮廓及其组合。
Liu等[65]采用连通成分分析与项目分析相结合的方法进行分割。设计了两种简单、循环的cnn用于字符识别,分别是SCNN和RCNN,一种用于汉字识别,另一种用于数字和字母识别。在2189幅图像中,分割率为96.58%,识别率为98.09%。
Dong等人[39]提出了一种由并行空间变换网络和共享权重识别器组成的创新结构。将校正后的车牌输入7个并行的无监督STNs[24]中,每个STNs都进行隐式字符分割。最后,由7个识别器分别对每个片段进行识别,第一个识别器分别对汉字进行训练,其余6个识别器共享权重。对于权值共享识别器,将其先验概率与识别子网络估计的似然概率相乘得到得分,其中第二个字符的阿拉伯数字数字的先验概率为0。最终模型的识别准确率为89.05%。
kare等人[66]提出了一个新的概念,称为部分字符重构,摘要针对主成分分析(PCA)和长轴分析(MA)可以在没有完整字符形状的情况下估计字符成分方向的问题,提出了一种基于角度信息的字符分割方法,如果PCA和MA给出的角度几乎相同并且都接近90度,则该分量被认为是一个完整的特征。如果两个轴之间的差值超过26度,并且给出的值几乎为0,那么该组件就被认为是分割不足。否则,该组成部分被认为是一个过度细分的情况。对于分割不足或过分割的字符,使用了迭代收缩或迭代扩展算法,该模型的分割率为82.6%,识别精度为87.3%。
[65]Y. Liu, H. Huang, J. Cao, and T. Huang, ‘‘Convolutional neural networksbased intelligent recognition of chinese license plates,’’ Soft Comput., vol. 22, no. 7, pp. 2403–2419, Apr. 2018.
[39]M. Dong, D. He, C. Luo, D. Liu, and W. Zeng, ‘‘A CNN-based approach for automatic license plate recognition in the wild,’’ in Proc. Brit. Mach. Vis. Conf., 2017, pp. 1–12.
[66] V. Khare, P. Shivakumara, C. S. Chan, T. Lu, L. K. Meng, H. H. Woon, and M. Blumenstein, ‘‘A novel character segmentation-reconstruction approach for license plate recognition,’’ Expert Syst. Appl., vol. 131, pp. 219–239, Oct. 2019
2)基于无分割的车牌识别
基于无分割的算法将车牌识别问题转化为字符序列标记问题,现阶段,无分割的车牌识别主要是通过RNN+CTC来进行实现。
Li等人[54]使用带有CTC损耗的双向RNNs (BRNN)来标记序列特征,在AOLP数据集上,平均识别率为91.83%,执行速度为400ms。
庄等[68]转移了YOLO-VOC网络进行车牌分割和字符识别,由于巴西车牌的特点,前3个字符是字母,后4个字符是数字,因此所有检测到的字符都由两个启发式规则过滤,该模型能够正确分割99%的字符,识别率为93%,在GPU上的执行时间仅为2.2ms。
Li等[59]在[54]文献的基础上,利用LSTM对递归神经网络(RNNs)进行训练,通过CNNs对整个车牌提取的序列特征进行识别。每个检测到的车牌都被转换为灰度图像,并调整到2494像素。一个24个24像素的子窗口,步长为1,以滑动窗口的方式分割填充图像。每个分割后的图像patch被送入36类CNN分类器中提取序列特征。将第四卷积层与第一全连通层连接成一个长度为5096的特征向量。然后利用主成分分析将特征维数降至256维,进行特征归一化处理。最后,设计CTC将预测的概率序列直接解码为输出标签,平均识别率约为92.47%。
Wang等[40]使用BRNN和CTC进行车牌识别,识别率为96.62%处理时间为17.53毫秒。首先,利用空间变压器网络(STN)对斜度和变形的车牌进行调整,车牌上有将统一的方向信息输入到改进的卷积神经网络(CNN)中提取序列特征,然后得到修正后的车牌,将这些不同卷积层的特征作为输入集成到BRNN中,最后用CTC实现序列标记。
Silva等人[69]提出了一种新的车牌识别系统,包括语义分割和字符计数,对输入图像进行简单投影预处理,使图像适合于语义分割
[54] H. Li, P. Wang, and C. Shen, ‘‘Towards End-to-End car license plates detection and recognition with deep neural networks,’’ 2017, arXiv:1709.08828. [Online]. Available: http://arxiv.org/abs/1709.08828
[68] J. Zhuang, S. Hou, Z. Wang, and Z.-J. Zha, ‘‘Towards human-level license plate recognition,’’ in Proc. Eur. Conf. Comput. Vis., Sep. 2018, pp. 314–329
[59] H. Li, P. Wang, M. You, and C. Shen, ‘‘Reading car license plates using deep neural networks,’’ Image Vis. Comput., vol. 72, pp. 14–23, Apr. 2018
[40] J. Wang, H. Huang, X. Qian, J. Cao, and Y. Dai, ‘‘Sequence recognition of chinese license plates,’’ Neurocomputing, vol. 317, pp. 149–158, Nov. 2018
[69] S. Montazzolli and C. Jung, ‘‘Real-time brazilian license plate detection and recognition using deep convolutional neural networks,’’ in Proc. 30th SIBGRAPI Conf. Graph., Patterns Images (SIBGRAPI), Oct. 2017, pp. 55–62.
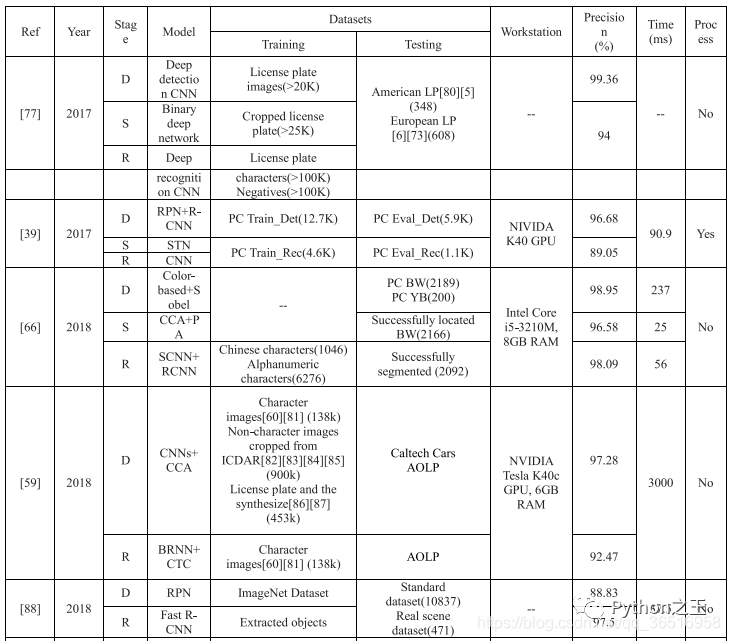
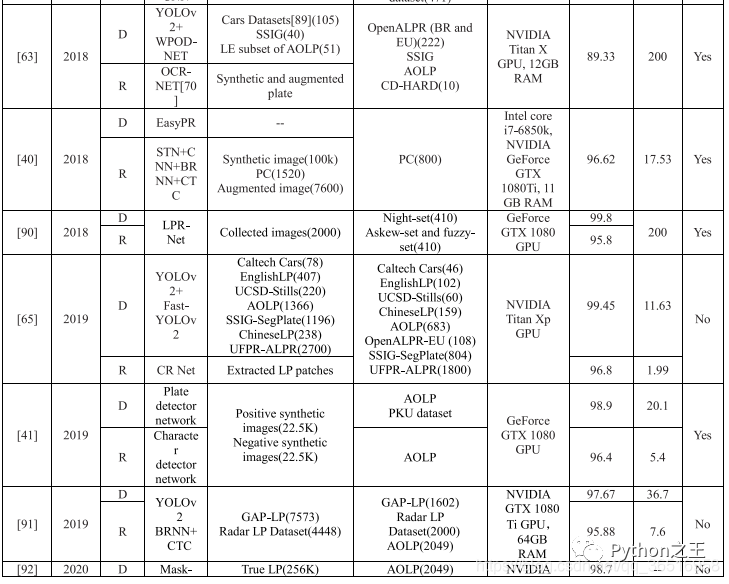
在表中,BW表示蓝色背景的白色字符车牌,YB表示黄色背景的黑色字符车牌。
在阶段列表中,D表示检测,S表示分割,R表示识别。在表中,也列出了各阶段的数据集、精度和处理时间。使用的图像数量列在数据集末尾的括号中,最后的处理是是否使用车牌校正、去噪、分辨率增强来提高识别精度。其中,只有LPR-Net[88]是统一的端到端模型,对于其他的算法,有6种算法采用了特殊的处理方法,大部分算法对车牌进行了校正,其中一种算法对图像进行去噪处理。与汉字和阿拉伯语相比,数字和字母有着更复杂的结构,他们更敏感,在现实场景中各种因素的影响,这些扭曲的变态和模糊字符也更难被肉眼识别的,所以调整和复原是需要的。
五、总结
从表6的数据可以看出,目前最先进的识别算法是[64]提出的基于YOLO的改进模型,对于多个国家的多个场景,识别准确率达到96.8%,而处理每幅图像只需要13.62ms。在今后车牌识别的研究工作中,可以从一下三个方面进行提升:
未来的算法可以结合图像去模糊和车牌校正或提高小目标的分辨率
客观评价,使用多套数据集进行算法测试,比如说,如第五张表所示,Caltech Cars只有126张,USCDStill只有291张,UFPR-ALPR最多为4500张。然而,太少的数据集不利于深度学习训练和测试评估。我们应该寻找一些像CCPD这样的数据集,里面包含了20万张图片。
现有的系统大多采用2 - 3个模型进行训练,即训练前需要收集相应的数据集并进行标记,测试前需要下载相应模型的矩阵参数,这无疑会给系统部署带来一定的人工成本和计算机存储成本。因此,迫切需要找到一个可以用统一模型进行端到端训练和测试的系统。
最后,在车牌识别方面,应该集中在解决复杂场景的三个方面,即车牌校正、去噪和高分辨率的表征,以及多元化的评价体系和建设一个统一的端到端训练和测试的模型。
本文来源
《Research on License Plate Recognition Algorithms Based on Deep Learning in Complex Environment》
下载地址
https://ieeexplore.ieee.org/document/9092977


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!