
行为识别综述
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
引言
行为识别是计算机视觉领域非常有挑战性的课题,因为其不仅仅要分析目标体的空间信息,还要分析时间维度上的信息。如何更好的提取出空间-时间特征是问题的关键。本文总结了近几年在这个领域的技术进展,涵盖范围从手动提取特征,到光流法,再到CNN和LSTM,一直到最近研究比较火的图神经网络。一开始是打算进行这方面的深入研究的,因此读了很多论文,做了综述,还投给了《有三AI》公众号(这是一个深度学习不错的公众号,喜欢的可以关注),后来考虑到自己是做深度学习加速方面的,还是做和这方面契合的更好一些。为什么将这篇综述放上来呢,一个是这周工作繁忙,先用它来顶一顶,另外通过这方面介绍也可以对深度学习的应用领域有一些了解。
1. 背景介绍
行为识别研究的是视频中目标的动作,比如判断一个人是在走路,跳跃还是挥手。在视频监督,视频推荐和人机交互中有重要的应用。近几十年来,随着神经网络的兴起,发展出了很多处理行为识别问题的方法。不同于目标识别,行为识别除了需要分析目标的空间依赖关系,还需要分析目标变化的历史信息。这就为行为识别的问题增加了难度。输入一系列连续的视频帧,机器首先面临的问题是如何将这一系列图像依据相关性进行分割,比如一个人可能先做了走路的动作,接下来又做了挥手,然后又跳跃。机器要判断这个人做了三个动作,并且分离出对应时间段的视频单独进行判断。其次机器要解决的问题是从一幅图像中分离出要分析的目标,比如一个视频中有一个人喝一个狗,需要分析人的行为而忽略狗的。最后是将一个人在一个时间段的行为进行特征提取,进行训练,对动作做判断。这些问题是一个机器需要面临的问题,当然在实际运用中,这些问题的解决可能会被统一解决,或者被人为的控制。接下来我们详细介绍以下内容:兴趣点提取,密集轨迹,光流和表观并举,3D卷积网络,循环神经网络(LSTM),图卷积网络(GCN)几种方法以及对应发展出来的方法。
2. 行为识别方法
2.1 时空关键点(space-time interest points)
提取时空关键点基于的主要思想是:视频图像中的关键点通常是在时空维度上发生强烈变化的数据,这些数据反应了目标运动的重要信息[1-3]。比如一个人挥舞手掌,手掌一定会在前后帧中发生最大移动,其周围图像数据发生变化最大。而这个人的身体其他部位却变化很小,数据几乎保持不变。如果能将这个变化数据提取出来,并且进一步分析其位置信息,那么可以用于区分其他动作。
时空关键点的提取方法是对空间关键点方法的扩展,描述一幅多尺度图像f(x,y)最普遍是使用高斯变换:

G为高斯函数,不同的方差会产生出不同分辨率的图像。Harris等就是在不同尺度图像上进行拉普拉斯变换:

U是图像的自相关矩阵,关键点的位置可以通过分析其特征值得到。Harris使用如下量来寻找关键点:

这个量的正数最大值即可以当做关键点。因为其反应了附近数据变化较大。
为什么这里要使用多尺度高斯函数来作为窗口?首先多尺度可以获得不同分辨率的图像,因为图像中的物体或者特征在不同分辨率下的敏感性不同,比如对于小的物体可能需要在较高分辨率下才能寻找到,而较大物体可以在较粗分辨率下寻找到,这样的效果更好。使用高斯函数来进行卷积是因为高斯函数和图像导数的卷积可以被转化为高斯导数和图像的卷积,节省了对图像求导操作。另外一个原因是使用高斯函数来进行图像滤波,之后再进行特征提取结果较好。

如果图像变成了视频,在原来空间维度上增加了时间维度,那么可以针对上述空间分辨率图像进行扩展:
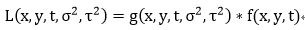
高斯函数增加了时间维度用于模糊时间维度上的图像,其为:

那么视频的自相关矩阵就变成了:
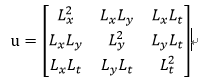
而寻找关键点的量扩展为:

这些关键点是位于一幅图像中的极值点,会随着尺度大小的不同发生变化。为了保证提取的特征在不同尺度下也有稳健的表达作用,通常也要求关键点在尺度方向上也是极值点。
现在解决了视频中关键点提取的问题,接下来就是如何来描述一系列视频图像,并且对不同动作的视频进行分类。描述图像方法有很多,比如HOG(histogram of gradient),SIFT(scale-invariant feature transform)等。这些方法本质上是将图像分割成很多小的cell,统计各个方向上的梯度值。论文就是采用了3D-SIFT来描述视频,即统计关键点时空周围的梯度直方图,形成特征描述子。然后对所有的特征描述子进行k-means聚类,划分类别,形成“word”。所有不同word就构成了一个vocabulary,每个视频就可以通过出现在这个vocabulary中词汇的数量来进行描述。最后训练一个SVM或者感知器的分类器来进行动作的最终判别。
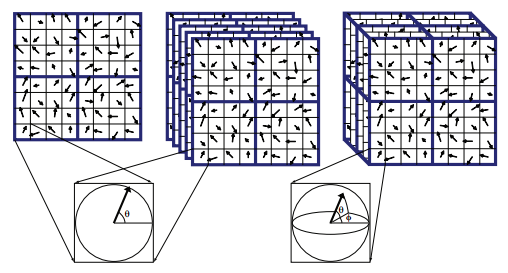
关键点的方法比较古老,这种方法忽略了很多视频细节,可能会丢失很多信息,泛化能力较弱。而且其将时间维度和空间维度进行等同处理,但是时间和空间的特征是不一样的。提取的时空关键点可能并不会很好的反应动作信息。
2.2 密集轨迹(dense-trajectories)
时空关键点是编码时空坐标中的视频信息,而轨迹法是追踪给定坐标图像沿时间的变化。Messing等[4]人就是通过KLT追踪3D Harris关键点来提取特征轨迹,用球坐标描述轨迹特征用于分类。Sun等[5]人则通过匹配前后两帧SIFT特征来追踪关键点,形成一系列轨迹描述。通过轨迹内和轨迹间的统计特征,可以描述一个具体动作。这些方法还是以关键点作为视频特征,很多有用的信息被过滤了。而将要介绍的dense-trajectories就是为了解决提取的信息稀疏问题而提出的[6]。
密集轨迹方法采样更多的图像信息,并且通过光流来追踪目标移动轨迹。采样密集能更好覆盖视频特征,而用光流可以提高追踪质量。
密集采样是对不同尺度下的图像都进行关键点提取,同时对图像自相关矩阵的特征值设置了一定阈值,通过阈值大小可以调节采样点的密集程度。阈值为:

0.001是在试验中确定的,可以在保证有很好凸点的情况下,也能有合适的采样密度。
对轨迹的追踪是通过光流,计算图像光流速率(ut, vt),然后通过这个速率来描述图像运动轨迹:
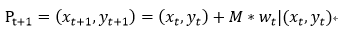
M是中值滤波器,用于平滑运动轨迹边界。得到的一系列点:
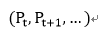
形成了一个轨迹。由于轨迹会随着时间漂移,可能会从初始位置移动到很远的地方。所以论文对轨迹追踪距离做了限制,首先将帧数限制在L内,而且轨迹空间范围限制在WXW范围,如果被追踪点不在这个范围,就重新采样进行追踪。这样可以保证轨迹的密度不会稀疏。
特征描述子论文选择选择了HOG,HOF(histogram of flow)以及MBH(motion boundary histogram)。其中MBH描述了光流梯度信息,反应了不同像素之间的相对运动。同时可以过滤掉由于摄像机移动造成的背景移动。
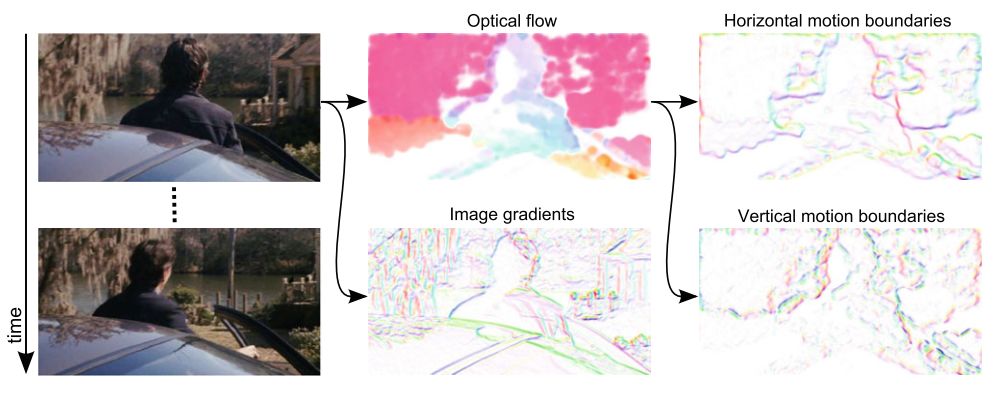
提取出HOG等信息后,接下来是采用相同办法来进行分类:首先对描述子聚类,形成word和vocabulary,然后对视频形成词汇描述,最后通过分类器完成动作识别。特征提取过程如下图:

2.3 表观和光流并举(two-stream)
随着深度神经网络在目标检测方面的广泛应用和取得的良好效果,人们也探索使用神经网络进行动作识别。视频自然的被分解为空间和时间两部分。空间以单幅图像的的形式表现出来,其携带着目标的形状,颜色等静态信息。而时间则通过多帧连续图像表现出来,反应了目标体的移动信息。这正是论文[7]的出发点,将对图像空间和时间信息分开处理,通过两个神经网络,最后利用SVM将这两部分关联起来,实现目标体的静态和动态的融合。
其中空间流神经网络针对静态图像进行特征提取,实际上是目标识别过程。因为动作和目标体相关,在确定动作类型之前首先需要知道判断的目标是什么。空间神经网络可以通过在imgNet等训练集上进行预训练,获得初始化网络参数。然后再进行后续的参数微调。
光流神经网络用于提取光流中的特征。多帧光流图像以并行多输入通道方式进入神经网络。通过多通道的融合来增强对光流变化信息的提取。光流的特征描述可以采用连续多帧光流,通过直接堆叠L帧光流图像,每帧有x和y方向的光流,生成两幅光流向量值图,这样就是2L幅图像,送入2L个通道。
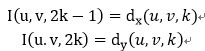
另外一种方法是沿着运动轨迹采样:
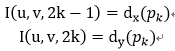
其中p1,p2,p3,…是沿着运动轨迹方向的点。

论文在UCF-101和HMDB-51数据集上进行了训练和测试,这两个数据集属于被标注的最大视频数据集。分别包含了101和51类动作。Two-stream方法在这两种测试集上最高获得了88%和59.4%的平均精度。

Two-stream的方法中光流卷积网络使用了2L个输入通道,来对应2L幅提取到的光流数据,计算量很大。Wang等[8]人对光流特征做了二次加工,减少了卷积网络的输入通道。他们的工作可以用于3D动作识别,通过从RGB-D(RGB图像和深度图像)数据中提取出场景流数据(scene-flow),场景流包括了光流和相对于摄像机方向的运动场,其描述了目标体在整个3D空间的运动。用(u,v,w)描述场景流运动场,u和v为光流运动场,w为图像相对于摄像机垂直方向的运动。通过场景流可以恢复3D物体的运动:
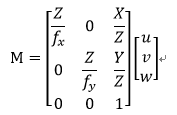
其中fx,fy为摄像机焦距,X,Y,Z为物体的空间坐标。对场景流的计算是一个变分问题,即最小化图像强度变化和深度图像变化的绝对微分,同时还增加了正则项用于平滑图像变化,即最小化场景流的方向导数。

其中r,a,b都是调节系数。获得了(u,v,w),实际上对于每两帧图像或者深度图之间就形成了三路不同map(Xu, Xv, Xw)。
接下来作者将场景流经过一定处理映射到动作图像(action map),映射的方法不尽相同。这些方法具有怎样的效果需要通过实验来判定。方法有以下几种:
1) SFAM-D
两帧场景流图像绝对差值之和:

这种表达反映了不同图像能量差值的累计分布。
2) SFAM-S

这种表达用于获得行为的最大运动幅度。
3) SFAM-RP
这个方法的出发点是动作是有时间顺序的,用一个变量来表示出视频随时间变化的顺序信息。那么就可以用于动作识别。所以其首先将多帧场景流map平均化:
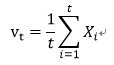
平均化的目的有两个:一个是将场景流和时间变量t关联起来了,另外一个可以减小视频中噪声的影响,稳定性好。然后找出一个量可以描述出一系列不同时间的vt的顺序:
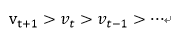
然后用这个量来作为连续多帧场景流的特征。排序方法可以利用SVM,其目标函数和约束条件为:

这样就可以将连续多帧场景流Xi映射到一个描述帧顺序的变量u了。
4) SFAM-AMRP
以上三种场景流是独立处理的,为了将三者联系起来,用均方来表示出一个量:
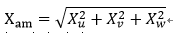
然后再运用SFAM-RP的方法映射到一个顺序变量。
5) SFAM-CTKRP
三种场景流图像的关系不经过人为设置,而是通过一个卷积网络来学习。将重新学习到的(Y1, Y2, Y3)作为新的map,再通过RP方法得到顺序量。

然后将以上提取的特征通过卷积网络,来对动作分类。同时作者也尝试了multi-score融合方法,即将两种以上特征通过多个不同训练出来的网络,最后将每个网络的输出结果统一考虑。
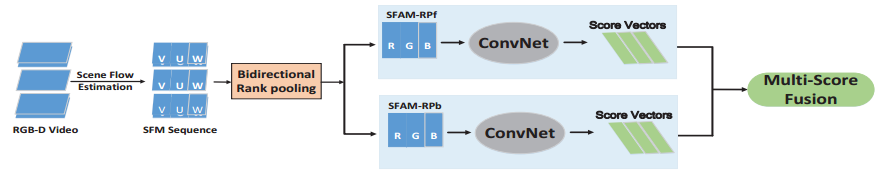
2.4 3D卷积网络(C3D)
3D卷积顾名思义就是在时间和空间维度上进行卷积运算[9],3D卷积和pooling可以保留时间上的信息。2D卷积只是在空间维度上进行运算,图像的时间信息会丢失。而3D卷积核pooling输出的是三维数据,其中包含了时间序列上的信息和特征。
作者尝试了几种不同的3D卷积核的深度:1,3,5,7,发现3x3x3大小卷积有更好的表现。由于3D卷积运算量很大,论文减小了网络深度和宽度,使用了8层卷积,5层pooling,2层全连接和1层softmax层。

作者通过解卷积方式研究了3D网络的学习过程,发现在前几帧图像中,网络主要寻找图像中的突出目标,然后就聚焦于目标并追踪它的运动轨迹。

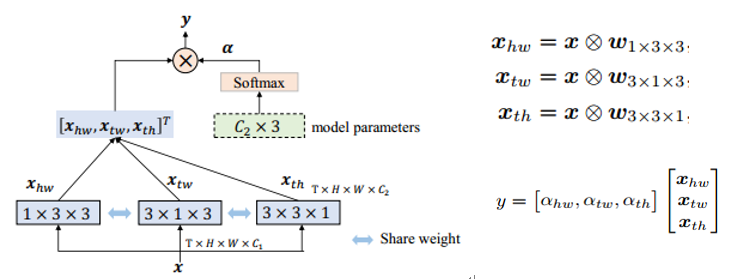
由于C3D权重参数的巨量以及运算的低效,Li等[10]人提出了一种2D网络可以联合时间-空间信息。给定了一个3D视频张量,通过不同观察角度将其展平为2D图像。下图显示了从三种不同角度观察运动员跳跃的画面。H-W角度是正常看到的运动员画面,显示了目标的的空间特征。通过时间角度看(比如T-W,T-H),我们可以了解视频的动态信息。虽然单从T-W和T-H角度看,我们很难直接看出和动作相关的信息。但是这些角度上包含了视频随时间变化的信息,通过在这上面运用2D卷积,理论上可以找到相关特征。

具体的网络结构如下图,将一个3x3x3卷积核展开为三个2D卷积,这三个2D卷积是共享权重的。这三个2D卷积分别和打平的三幅map(H-W,T-H,T-W)进行卷积运算,得到了三个角度的张量结果,再通过一个向量运算将三个张量结果统一起来,得到一个输出y。
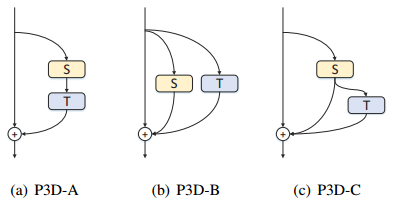
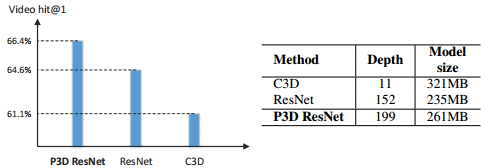
为了降低C3D巨大的权重数据和计算量,Qiu等[11]人则采取了将3D卷积分解成一个2D空间卷积(S:3x3x1)和1D时间卷积(T:1x1x3),然后以串联或者并联的方式将这两个卷积联系起来,并结合残差网络的特点,形成了伪3D(P3D)网络结构。根据1D和2D卷积的联系形式,有三种结构:S和T串联,并联,串联和并联并举。然后作者将这三种P3D模块替换resnet50中的残差网络单元,用于对视频的的识别。而为了增加网络的多样性,论文创建了自己的网络,同时用了这三种网络模块。获得了比单独一种网络模块要高的精确度,同时相比于C3D大大降低了模型大小。
2.5 LSTM
LSTM网络自身的记忆功能就适合处理长时依赖关系的输入信号,而视频正是在时间上变化的图像。因此有论文使用LSTM来提取视频特征。Srivastava等[12]人就采用了LSTM编码解码结构,LSTM编码器将一系列视频图像进行特征提取,生成对视频的描述。而LSTM解码器可以用于视频的预测或者恢复。LSTM的编码器输入可以使任何经过特征提取过的视频信息,比如卷积网络提取出的光流信息或者目标信息,然后在LSTM中进一步学习到时间相关特征。

在论文[13]中,通过CNN来提取图像的空间特征,接下来采用两种方法来得到时间相关特征。一种是对多帧图像的CNN结果使用pooling来融合,另外一种是将CNN输出作为LSTM输入,提取时间特征。论文中采用了5层LSTM,LSTM之后是sofmax,完成对图像的预测。
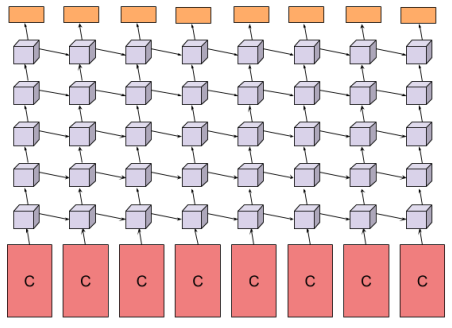
Baccouche等[14]人也在用了类似的方法,只不过他们并不是用CNN来提取特征。他们选择使用两种传统方法提取特征,一个是词袋(bag of words),通过对每幅图片用SIFT描述,然后通过聚类形成30个视频词汇,用于描述视频中的不同特征。然后每帧图片用词汇描述,这样就形成了连续多帧的词汇序列;另外一种是通过追踪两帧图像的SIFT点,获得两幅图片之间的仿射变换T,用T来作为视频描述符。
得到视频的连续描述符之后,再使用LSTM-RNN结构来进行预测。

2.6 图卷积网络(GCN)
最近,基于图的模型得到广泛关注,因为其在图结构数据上非常好的表达效果。图神经网络有两种结构,一种是图和RNN的结合,另外一种是图和CNN的结合(GCN)。GCN有两种类型,一种是空间GCN,另外一种是谱GCN。其中谱GCN是将图像数据转换到谱空间表达。为了在行为识别中应用GCN,首先需要对视频进行图表达。一张图可以表示为(Vt, et),其中vt是定点,et是边。可以利用姿态估测方法获得目标的关节坐标,然后将这些关节点作为图的点,并按照空间或者时间将这些点连接起来。一个结点的临近节点可以这样表示:

D是定义的节点距离。这样定义之后,就可以将每个节点以及它临近节点划分到同一个组。为这些节点标识后,就想当于一个张量了。那么就可以进行卷积运算了。图卷积通常就表示为:
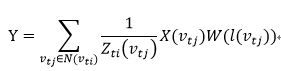
其中l(v_tj)是节点被标识的序号。X是图表示,W为权重。
论文[15]中提出了AGC-LSTM网络用于行为识别,其将图卷积和LSTM结合。网络整体上看是LSTM,也有输入门,记忆门和输出门等。只不过这些门的是进行的图卷积运算,处理的是图数据。同时将注意力机制引入到网络中,使得网络具备自动检测重要节点的能力。
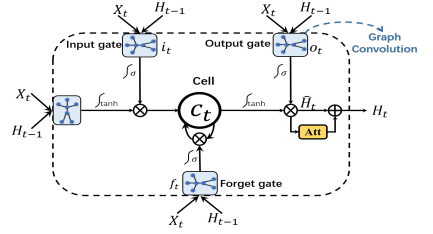
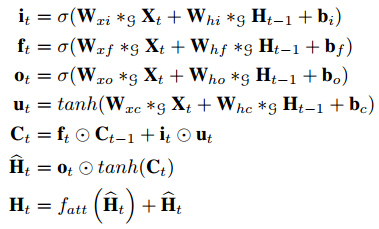
上图中g表示进行图卷积计算,fatt是注意力网络。由于Ht中包含了大量的空间和时间信息,对其应用注意力网络有效提高对有效节点的追踪。
总结
通过调研最近几年人们对行为识别的研究方法,其主要都集中于对特征的提取上。行为是发生在一定时空的事件,特征不仅仅具有空间性,也具有时间性。如何有效的描述出时间空间特征才是行为识别问题的关键。所以人们从不同角度出发,或者分别考虑时间和空间特点,然后融合(two-stream),或者同时进行计算(3D);特征的描述手段也各种各样,有的用图像2D上的算子(SIFT),有的用光流,有的用图。这些方法在视频背景较为简单的情况下获得了不错的精度,但是在背景较为复杂的视频中精度还很有限,所以这个领域还有很大研究空间。
文献
1. Paul Scovanner, S.A., Mubarak Shah, A 3-Dimensional SIFT Descriptor and its Application to Action Recognition. ECCV, 2007.
2. Manal Al Ghamdiy, L.Z.a.Y.G., Spatio-temporal SIFT and Its Application to Human Action Classification. ECCV, 2012.
3. Laptev, I., On space-time interest points. International Journal of Computer Vision, 2005.
4. Ross Messing, C.P., Henry Kautz, Activity Recognition Using the Velocity Histories of Tracked Key Points. IEEE international conference on computer vision, 2009.
5. Ju Sun, X.W., Shuicheng Yan, Loong-Fah Cheong, Tat-Seng Chua, Jintao Li, Hierarchical Spatio-Temporal Context Modeling for Action Recognition. IEEE international conference on multimedia and expo, 2009.
6. Heng Wang, A.K., Cordelia Schmid, Cheng-Lin Liu, Dense Trajectories and Motion Boundary Descriptors for Action Recognition. International Journal of Computer Vision, 2013.
7. Karen Simonyan, A.Z., Two-Stream Convolutional Networks for Action Recognition in Videos. CVPR, 2014.
8. Pichao Wang, W.L., Zhimin Gao, Yuyao Zhang, Chang Tang and Philip Ogunbona, Scene Flow to Action Map A New Representation for RGB-D Based Action Recognition With Convolutional Neural Networks. CVPR, 2017.
9. Du Tran, L.B., Rob Fergus, Lorenzo Torresani, Manohar Paluri, Learning Spatiotemporal Features with 3D Convolutional Networks. CVPR, 2015.
10. Pu, C.L.Q.Z.D.X.S., Collaborative Spatiotemporal Feature Learning for Video Action Recognition. ICCV, 2019.
11. Zhaofan Qiu, T.Y., and Tao Mei, Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. ICCV, 2017.
12. Nitish Srivastava, E.M., Ruslan Salakhutdinov, Unsupervised Learning of Video Representations using LSTMs. ICML, 2015.
13. Joe Yue-Hei Ng, M.H., Sudheendra Vijayanarasimhan, Oriol Vinyals, Rajat Monga, George Toderici, Beyond Short Snippets Deep Networksfor Video Classification. CVPR, 2015.
14. Moez Baccouche, F.M., Christian Wolf, Christophe Garcia and Atilla Baskurt, Action Classification in Soccer Videos with Long Short-Term Memory Recurrent Neural Networks. ICANN, 2010.
15. Chenyang Si, W.C., Wei Wang, Liang Wang, Tieniu Tan, An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognition. CVPR, 2019.
本文仅做学术分享,如有侵权,请联系删文。
—THE END—
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达
引言
行为识别是计算机视觉领域非常有挑战性的课题,因为其不仅仅要分析目标体的空间信息,还要分析时间维度上的信息。如何更好的提取出空间-时间特征是问题的关键。本文总结了近几年在这个领域的技术进展,涵盖范围从手动提取特征,到光流法,再到CNN和LSTM,一直到最近研究比较火的图神经网络。一开始是打算进行这方面的深入研究的,因此读了很多论文,做了综述,还投给了《有三AI》公众号(这是一个深度学习不错的公众号,喜欢的可以关注),后来考虑到自己是做深度学习加速方面的,还是做和这方面契合的更好一些。为什么将这篇综述放上来呢,一个是这周工作繁忙,先用它来顶一顶,另外通过这方面介绍也可以对深度学习的应用领域有一些了解。
1. 背景介绍
行为识别研究的是视频中目标的动作,比如判断一个人是在走路,跳跃还是挥手。在视频监督,视频推荐和人机交互中有重要的应用。近几十年来,随着神经网络的兴起,发展出了很多处理行为识别问题的方法。不同于目标识别,行为识别除了需要分析目标的空间依赖关系,还需要分析目标变化的历史信息。这就为行为识别的问题增加了难度。输入一系列连续的视频帧,机器首先面临的问题是如何将这一系列图像依据相关性进行分割,比如一个人可能先做了走路的动作,接下来又做了挥手,然后又跳跃。机器要判断这个人做了三个动作,并且分离出对应时间段的视频单独进行判断。其次机器要解决的问题是从一幅图像中分离出要分析的目标,比如一个视频中有一个人喝一个狗,需要分析人的行为而忽略狗的。最后是将一个人在一个时间段的行为进行特征提取,进行训练,对动作做判断。这些问题是一个机器需要面临的问题,当然在实际运用中,这些问题的解决可能会被统一解决,或者被人为的控制。接下来我们详细介绍以下内容:兴趣点提取,密集轨迹,光流和表观并举,3D卷积网络,循环神经网络(LSTM),图卷积网络(GCN)几种方法以及对应发展出来的方法。
2. 行为识别方法
2.1 时空关键点(space-time interest points)
提取时空关键点基于的主要思想是:视频图像中的关键点通常是在时空维度上发生强烈变化的数据,这些数据反应了目标运动的重要信息[1-3]。比如一个人挥舞手掌,手掌一定会在前后帧中发生最大移动,其周围图像数据发生变化最大。而这个人的身体其他部位却变化很小,数据几乎保持不变。如果能将这个变化数据提取出来,并且进一步分析其位置信息,那么可以用于区分其他动作。
时空关键点的提取方法是对空间关键点方法的扩展,描述一幅多尺度图像f(x,y)最普遍是使用高斯变换:
G为高斯函数,不同的方差会产生出不同分辨率的图像。Harris等就是在不同尺度图像上进行拉普拉斯变换:
U是图像的自相关矩阵,关键点的位置可以通过分析其特征值得到。Harris使用如下量来寻找关键点:
这个量的正数最大值即可以当做关键点。因为其反应了附近数据变化较大。
为什么这里要使用多尺度高斯函数来作为窗口?首先多尺度可以获得不同分辨率的图像,因为图像中的物体或者特征在不同分辨率下的敏感性不同,比如对于小的物体可能需要在较高分辨率下才能寻找到,而较大物体可以在较粗分辨率下寻找到,这样的效果更好。使用高斯函数来进行卷积是因为高斯函数和图像导数的卷积可以被转化为高斯导数和图像的卷积,节省了对图像求导操作。另外一个原因是使用高斯函数来进行图像滤波,之后再进行特征提取结果较好。
如果图像变成了视频,在原来空间维度上增加了时间维度,那么可以针对上述空间分辨率图像进行扩展:
高斯函数增加了时间维度用于模糊时间维度上的图像,其为:
那么视频的自相关矩阵就变成了:
而寻找关键点的量扩展为:
这些关键点是位于一幅图像中的极值点,会随着尺度大小的不同发生变化。为了保证提取的特征在不同尺度下也有稳健的表达作用,通常也要求关键点在尺度方向上也是极值点。
现在解决了视频中关键点提取的问题,接下来就是如何来描述一系列视频图像,并且对不同动作的视频进行分类。描述图像方法有很多,比如HOG(histogram of gradient),SIFT(scale-invariant feature transform)等。这些方法本质上是将图像分割成很多小的cell,统计各个方向上的梯度值。论文就是采用了3D-SIFT来描述视频,即统计关键点时空周围的梯度直方图,形成特征描述子。然后对所有的特征描述子进行k-means聚类,划分类别,形成“word”。所有不同word就构成了一个vocabulary,每个视频就可以通过出现在这个vocabulary中词汇的数量来进行描述。最后训练一个SVM或者感知器的分类器来进行动作的最终判别。
关键点的方法比较古老,这种方法忽略了很多视频细节,可能会丢失很多信息,泛化能力较弱。而且其将时间维度和空间维度进行等同处理,但是时间和空间的特征是不一样的。提取的时空关键点可能并不会很好的反应动作信息。
2.2 密集轨迹(dense-trajectories)
时空关键点是编码时空坐标中的视频信息,而轨迹法是追踪给定坐标图像沿时间的变化。Messing等[4]人就是通过KLT追踪3D Harris关键点来提取特征轨迹,用球坐标描述轨迹特征用于分类。Sun等[5]人则通过匹配前后两帧SIFT特征来追踪关键点,形成一系列轨迹描述。通过轨迹内和轨迹间的统计特征,可以描述一个具体动作。这些方法还是以关键点作为视频特征,很多有用的信息被过滤了。而将要介绍的dense-trajectories就是为了解决提取的信息稀疏问题而提出的[6]。
密集轨迹方法采样更多的图像信息,并且通过光流来追踪目标移动轨迹。采样密集能更好覆盖视频特征,而用光流可以提高追踪质量。
密集采样是对不同尺度下的图像都进行关键点提取,同时对图像自相关矩阵的特征值设置了一定阈值,通过阈值大小可以调节采样点的密集程度。阈值为:
0.001是在试验中确定的,可以在保证有很好凸点的情况下,也能有合适的采样密度。
对轨迹的追踪是通过光流,计算图像光流速率(ut, vt),然后通过这个速率来描述图像运动轨迹:
M是中值滤波器,用于平滑运动轨迹边界。得到的一系列点:
形成了一个轨迹。由于轨迹会随着时间漂移,可能会从初始位置移动到很远的地方。所以论文对轨迹追踪距离做了限制,首先将帧数限制在L内,而且轨迹空间范围限制在WXW范围,如果被追踪点不在这个范围,就重新采样进行追踪。这样可以保证轨迹的密度不会稀疏。
特征描述子论文选择选择了HOG,HOF(histogram of flow)以及MBH(motion boundary histogram)。其中MBH描述了光流梯度信息,反应了不同像素之间的相对运动。同时可以过滤掉由于摄像机移动造成的背景移动。
提取出HOG等信息后,接下来是采用相同办法来进行分类:首先对描述子聚类,形成word和vocabulary,然后对视频形成词汇描述,最后通过分类器完成动作识别。特征提取过程如下图:
2.3 表观和光流并举(two-stream)
随着深度神经网络在目标检测方面的广泛应用和取得的良好效果,人们也探索使用神经网络进行动作识别。视频自然的被分解为空间和时间两部分。空间以单幅图像的的形式表现出来,其携带着目标的形状,颜色等静态信息。而时间则通过多帧连续图像表现出来,反应了目标体的移动信息。这正是论文[7]的出发点,将对图像空间和时间信息分开处理,通过两个神经网络,最后利用SVM将这两部分关联起来,实现目标体的静态和动态的融合。
其中空间流神经网络针对静态图像进行特征提取,实际上是目标识别过程。因为动作和目标体相关,在确定动作类型之前首先需要知道判断的目标是什么。空间神经网络可以通过在imgNet等训练集上进行预训练,获得初始化网络参数。然后再进行后续的参数微调。
光流神经网络用于提取光流中的特征。多帧光流图像以并行多输入通道方式进入神经网络。通过多通道的融合来增强对光流变化信息的提取。光流的特征描述可以采用连续多帧光流,通过直接堆叠L帧光流图像,每帧有x和y方向的光流,生成两幅光流向量值图,这样就是2L幅图像,送入2L个通道。
另外一种方法是沿着运动轨迹采样:
其中p1,p2,p3,…是沿着运动轨迹方向的点。
论文在UCF-101和HMDB-51数据集上进行了训练和测试,这两个数据集属于被标注的最大视频数据集。分别包含了101和51类动作。Two-stream方法在这两种测试集上最高获得了88%和59.4%的平均精度。
Two-stream的方法中光流卷积网络使用了2L个输入通道,来对应2L幅提取到的光流数据,计算量很大。Wang等[8]人对光流特征做了二次加工,减少了卷积网络的输入通道。他们的工作可以用于3D动作识别,通过从RGB-D(RGB图像和深度图像)数据中提取出场景流数据(scene-flow),场景流包括了光流和相对于摄像机方向的运动场,其描述了目标体在整个3D空间的运动。用(u,v,w)描述场景流运动场,u和v为光流运动场,w为图像相对于摄像机垂直方向的运动。通过场景流可以恢复3D物体的运动:
其中fx,fy为摄像机焦距,X,Y,Z为物体的空间坐标。对场景流的计算是一个变分问题,即最小化图像强度变化和深度图像变化的绝对微分,同时还增加了正则项用于平滑图像变化,即最小化场景流的方向导数。
其中r,a,b都是调节系数。获得了(u,v,w),实际上对于每两帧图像或者深度图之间就形成了三路不同map(Xu, Xv, Xw)。
接下来作者将场景流经过一定处理映射到动作图像(action map),映射的方法不尽相同。这些方法具有怎样的效果需要通过实验来判定。方法有以下几种:
1) SFAM-D
两帧场景流图像绝对差值之和:
这种表达反映了不同图像能量差值的累计分布。
2) SFAM-S
这种表达用于获得行为的最大运动幅度。
3) SFAM-RP
这个方法的出发点是动作是有时间顺序的,用一个变量来表示出视频随时间变化的顺序信息。那么就可以用于动作识别。所以其首先将多帧场景流map平均化:
平均化的目的有两个:一个是将场景流和时间变量t关联起来了,另外一个可以减小视频中噪声的影响,稳定性好。然后找出一个量可以描述出一系列不同时间的vt的顺序:
然后用这个量来作为连续多帧场景流的特征。排序方法可以利用SVM,其目标函数和约束条件为:
这样就可以将连续多帧场景流Xi映射到一个描述帧顺序的变量u了。
4) SFAM-AMRP
以上三种场景流是独立处理的,为了将三者联系起来,用均方来表示出一个量:
然后再运用SFAM-RP的方法映射到一个顺序变量。
5) SFAM-CTKRP
三种场景流图像的关系不经过人为设置,而是通过一个卷积网络来学习。将重新学习到的(Y1, Y2, Y3)作为新的map,再通过RP方法得到顺序量。
然后将以上提取的特征通过卷积网络,来对动作分类。同时作者也尝试了multi-score融合方法,即将两种以上特征通过多个不同训练出来的网络,最后将每个网络的输出结果统一考虑。
2.4 3D卷积网络(C3D)
3D卷积顾名思义就是在时间和空间维度上进行卷积运算[9],3D卷积和pooling可以保留时间上的信息。2D卷积只是在空间维度上进行运算,图像的时间信息会丢失。而3D卷积核pooling输出的是三维数据,其中包含了时间序列上的信息和特征。
作者尝试了几种不同的3D卷积核的深度:1,3,5,7,发现3x3x3大小卷积有更好的表现。由于3D卷积运算量很大,论文减小了网络深度和宽度,使用了8层卷积,5层pooling,2层全连接和1层softmax层。
作者通过解卷积方式研究了3D网络的学习过程,发现在前几帧图像中,网络主要寻找图像中的突出目标,然后就聚焦于目标并追踪它的运动轨迹。
由于C3D权重参数的巨量以及运算的低效,Li等[10]人提出了一种2D网络可以联合时间-空间信息。给定了一个3D视频张量,通过不同观察角度将其展平为2D图像。下图显示了从三种不同角度观察运动员跳跃的画面。H-W角度是正常看到的运动员画面,显示了目标的的空间特征。通过时间角度看(比如T-W,T-H),我们可以了解视频的动态信息。虽然单从T-W和T-H角度看,我们很难直接看出和动作相关的信息。但是这些角度上包含了视频随时间变化的信息,通过在这上面运用2D卷积,理论上可以找到相关特征。
具体的网络结构如下图,将一个3x3x3卷积核展开为三个2D卷积,这三个2D卷积是共享权重的。这三个2D卷积分别和打平的三幅map(H-W,T-H,T-W)进行卷积运算,得到了三个角度的张量结果,再通过一个向量运算将三个张量结果统一起来,得到一个输出y。
为了降低C3D巨大的权重数据和计算量,Qiu等[11]人则采取了将3D卷积分解成一个2D空间卷积(S:3x3x1)和1D时间卷积(T:1x1x3),然后以串联或者并联的方式将这两个卷积联系起来,并结合残差网络的特点,形成了伪3D(P3D)网络结构。根据1D和2D卷积的联系形式,有三种结构:S和T串联,并联,串联和并联并举。然后作者将这三种P3D模块替换resnet50中的残差网络单元,用于对视频的的识别。而为了增加网络的多样性,论文创建了自己的网络,同时用了这三种网络模块。获得了比单独一种网络模块要高的精确度,同时相比于C3D大大降低了模型大小。
2.5 LSTM
LSTM网络自身的记忆功能就适合处理长时依赖关系的输入信号,而视频正是在时间上变化的图像。因此有论文使用LSTM来提取视频特征。Srivastava等[12]人就采用了LSTM编码解码结构,LSTM编码器将一系列视频图像进行特征提取,生成对视频的描述。而LSTM解码器可以用于视频的预测或者恢复。LSTM的编码器输入可以使任何经过特征提取过的视频信息,比如卷积网络提取出的光流信息或者目标信息,然后在LSTM中进一步学习到时间相关特征。
在论文[13]中,通过CNN来提取图像的空间特征,接下来采用两种方法来得到时间相关特征。一种是对多帧图像的CNN结果使用pooling来融合,另外一种是将CNN输出作为LSTM输入,提取时间特征。论文中采用了5层LSTM,LSTM之后是sofmax,完成对图像的预测。
Baccouche等[14]人也在用了类似的方法,只不过他们并不是用CNN来提取特征。他们选择使用两种传统方法提取特征,一个是词袋(bag of words),通过对每幅图片用SIFT描述,然后通过聚类形成30个视频词汇,用于描述视频中的不同特征。然后每帧图片用词汇描述,这样就形成了连续多帧的词汇序列;另外一种是通过追踪两帧图像的SIFT点,获得两幅图片之间的仿射变换T,用T来作为视频描述符。
得到视频的连续描述符之后,再使用LSTM-RNN结构来进行预测。
2.6 图卷积网络(GCN)
最近,基于图的模型得到广泛关注,因为其在图结构数据上非常好的表达效果。图神经网络有两种结构,一种是图和RNN的结合,另外一种是图和CNN的结合(GCN)。GCN有两种类型,一种是空间GCN,另外一种是谱GCN。其中谱GCN是将图像数据转换到谱空间表达。为了在行为识别中应用GCN,首先需要对视频进行图表达。一张图可以表示为(Vt, et),其中vt是定点,et是边。可以利用姿态估测方法获得目标的关节坐标,然后将这些关节点作为图的点,并按照空间或者时间将这些点连接起来。一个结点的临近节点可以这样表示:
D是定义的节点距离。这样定义之后,就可以将每个节点以及它临近节点划分到同一个组。为这些节点标识后,就想当于一个张量了。那么就可以进行卷积运算了。图卷积通常就表示为:
其中l(v_tj)是节点被标识的序号。X是图表示,W为权重。
论文[15]中提出了AGC-LSTM网络用于行为识别,其将图卷积和LSTM结合。网络整体上看是LSTM,也有输入门,记忆门和输出门等。只不过这些门的是进行的图卷积运算,处理的是图数据。同时将注意力机制引入到网络中,使得网络具备自动检测重要节点的能力。
上图中g表示进行图卷积计算,fatt是注意力网络。由于Ht中包含了大量的空间和时间信息,对其应用注意力网络有效提高对有效节点的追踪。
总结
通过调研最近几年人们对行为识别的研究方法,其主要都集中于对特征的提取上。行为是发生在一定时空的事件,特征不仅仅具有空间性,也具有时间性。如何有效的描述出时间空间特征才是行为识别问题的关键。所以人们从不同角度出发,或者分别考虑时间和空间特点,然后融合(two-stream),或者同时进行计算(3D);特征的描述手段也各种各样,有的用图像2D上的算子(SIFT),有的用光流,有的用图。这些方法在视频背景较为简单的情况下获得了不错的精度,但是在背景较为复杂的视频中精度还很有限,所以这个领域还有很大研究空间。
文献
1. Paul Scovanner, S.A., Mubarak Shah, A 3-Dimensional SIFT Descriptor and its Application to Action Recognition. ECCV, 2007.
2. Manal Al Ghamdiy, L.Z.a.Y.G., Spatio-temporal SIFT and Its Application to Human Action Classification. ECCV, 2012.
3. Laptev, I., On space-time interest points. International Journal of Computer Vision, 2005.
4. Ross Messing, C.P., Henry Kautz, Activity Recognition Using the Velocity Histories of Tracked Key Points. IEEE international conference on computer vision, 2009.
5. Ju Sun, X.W., Shuicheng Yan, Loong-Fah Cheong, Tat-Seng Chua, Jintao Li, Hierarchical Spatio-Temporal Context Modeling for Action Recognition. IEEE international conference on multimedia and expo, 2009.
6. Heng Wang, A.K., Cordelia Schmid, Cheng-Lin Liu, Dense Trajectories and Motion Boundary Descriptors for Action Recognition. International Journal of Computer Vision, 2013.
7. Karen Simonyan, A.Z., Two-Stream Convolutional Networks for Action Recognition in Videos. CVPR, 2014.
8. Pichao Wang, W.L., Zhimin Gao, Yuyao Zhang, Chang Tang and Philip Ogunbona, Scene Flow to Action Map A New Representation for RGB-D Based Action Recognition With Convolutional Neural Networks. CVPR, 2017.
9. Du Tran, L.B., Rob Fergus, Lorenzo Torresani, Manohar Paluri, Learning Spatiotemporal Features with 3D Convolutional Networks. CVPR, 2015.
10. Pu, C.L.Q.Z.D.X.S., Collaborative Spatiotemporal Feature Learning for Video Action Recognition. ICCV, 2019.
11. Zhaofan Qiu, T.Y., and Tao Mei, Learning Spatio-Temporal Representation with Pseudo-3D Residual Networks. ICCV, 2017.
12. Nitish Srivastava, E.M., Ruslan Salakhutdinov, Unsupervised Learning of Video Representations using LSTMs. ICML, 2015.
13. Joe Yue-Hei Ng, M.H., Sudheendra Vijayanarasimhan, Oriol Vinyals, Rajat Monga, George Toderici, Beyond Short Snippets Deep Networksfor Video Classification. CVPR, 2015.
14. Moez Baccouche, F.M., Christian Wolf, Christophe Garcia and Atilla Baskurt, Action Classification in Soccer Videos with Long Short-Term Memory Recurrent Neural Networks. ICANN, 2010.
15. Chenyang Si, W.C., Wei Wang, Liang Wang, Tieniu Tan, An Attention Enhanced Graph Convolutional LSTM Network for Skeleton-Based Action Recognition. CVPR, 2019.
本文仅做学术分享,如有侵权,请联系删文。