
【机器学习】机器学习项目流程
项目来源:
这是一个机器学习的完整流程,附代码非常全,几乎适合任何监督学习的分类问题,本文提供代码和数据下载。
作者:WillKoehrsen
翻译:DeqianBai(https://github.com/DeqianBai)
这是2018年夏天,一位美国数据科学家在申请工作时的“作业”,完整的英文版作业在:
https://github.com/WillKoehrsen/machine-learning-project-walkthrough/blob/master/hw_assignment.pdf
项目目标:
使用提供的建筑能源数据开发一个模型,该模型可以预测建筑物的能源之星得分, 然后解释结果以找到最能预测得分的变量。
项目介绍:
这是一个受监督的回归机器学习任务:给定一组包含目标(在本例中为分数)的数据,我们希望训练一个可以学习将特征(也称为解释变量)映射到目标的模型。
受监督问题:我们可以知道数据的特征和目标,我们的目标是训练可以学习两者之间映射关系的模型。 回归问题:Energy Star Score是一个连续变量。
在训练中,我们希望模型能够学习特征和分数之间的关系,因此我们给出了特征和答案。然后,为了测试模型的学习效果,我们在一个从未见过答案的测试集上进行评估
我们在拿到一个机器学习问题之后,要做的第一件事就是制作出我们的机器学习项目清单。下面给出了一个可供参考的机器学习项目清单,它应该适用于大多数机器学习项目,虽然确切的实现细节可能有所不同,但机器学习项目的一般结构保持相对稳定:
数据清理和格式化
探索性数据分析
特征工程和特征选择
基于性能指标比较几种机器学习模型
对最佳模型执行超参数调整
在测试集上评估最佳模型
解释模型结果
得出结论
提前设置机器学习管道结构让我们看到每一步是如何流入另一步的。但是,机器学习管道是一个迭代过程,因此我们并不总是以线性方式遵循这些步骤。我们可能会根据管道下游的结果重新审视上一步。例如,
虽然我们可以在构建任何模型之前执行特征选择,但我们可以使用建模结果返回并选择一组不同的特征。 或者,建模可能会出现意想不到的结果,这意味着我们希望从另一个角度探索我们的数据。 一般来说,你必须完成一步才能继续下一步,但不要觉得一旦你第一次完成一步,你就不能回头做出改进!你可以在任何时候返回前面的步骤并作出相应的修改。
代码部分
代码部分较长,仅贴代码的目录,完整代码在文末提供下载。
1. 数据清理和格式化
1.1 加载并检查数据 1.2 数据类型和缺失值 1.2.1 将数据转换为正确的类型 1.3 处理缺失值
2. 探索性数据分析
2.1 单变量图 2.2 去除异常值 2.3 寻找关系 2.4 特征与目标之间的相关性 2.5 双变量图(Two-Variable Plots) 2.5.1 Pairs Plot
3. 特征工程和特征选择
3.1 特征工程 3.2 特征选择(去除共线特征) 3.3 划分训练集和测试集 3.4 建立Baseline 小结
4. 基于性能指标比较几种机器学习模型
4.1 输入缺失值 4.2 特征缩放 4.3 需要评估的模型
5. 对最佳模型执行超参数调整
5.1 超参数 5.2 使用随机搜索和交叉验证进行超参数调整
6. 在测试集上评估最佳模型
7. 解释模型结果
7.1 特征重要性 7.2 使用特征重要性进行特征选择 7.3 本地可解释的与模型无关的解释 7.4 检查单个决策树
8. 得出结论
8.1 得出结论 记录发现
代码截图

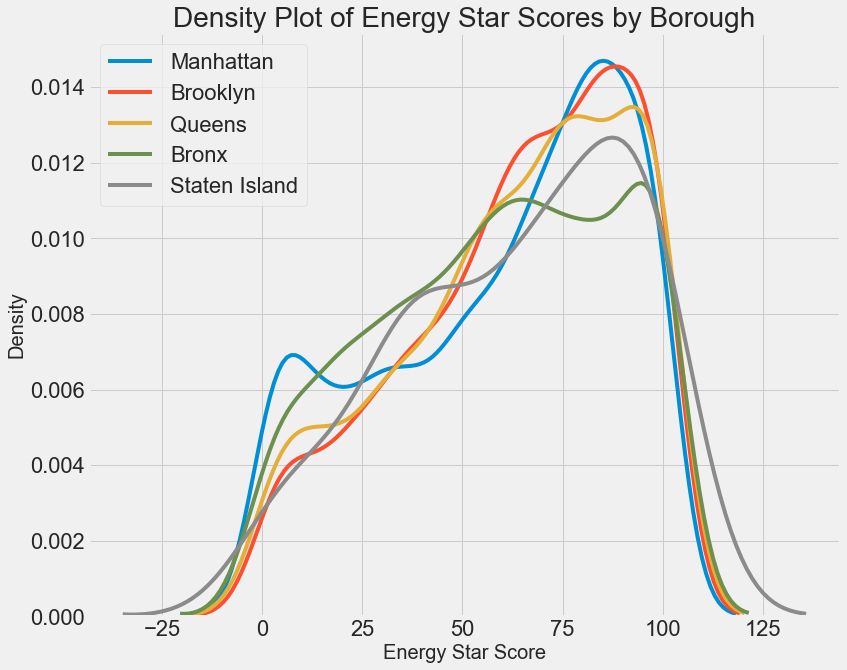
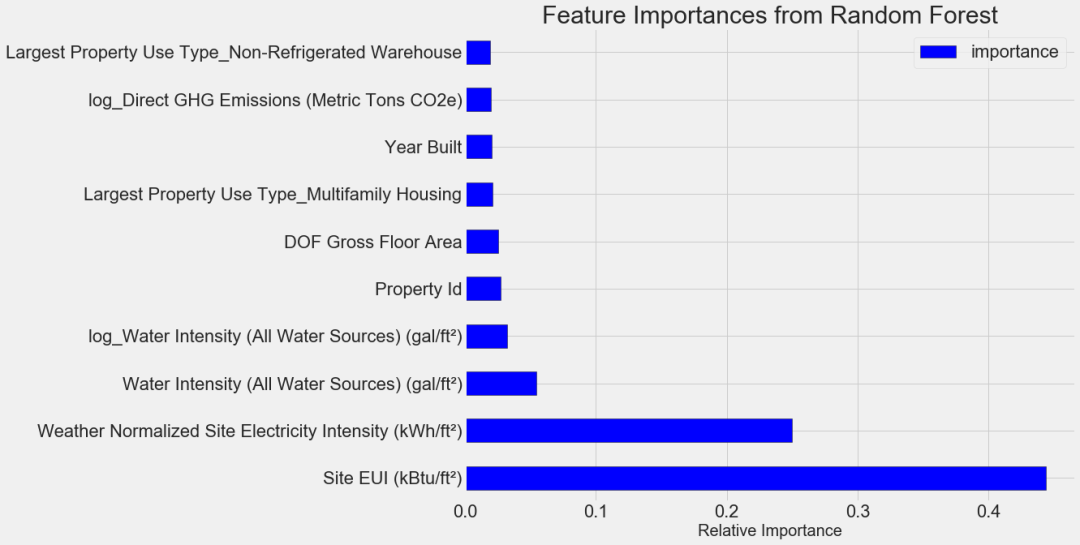
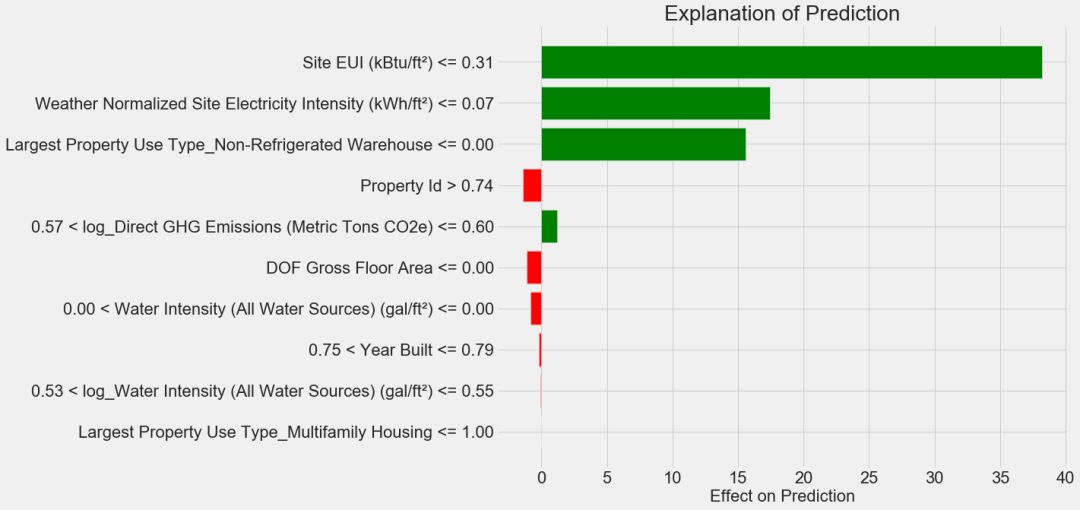
参考
[1] https://github.com/WillKoehrsen/machine-learning-project-walkthrough
[2] https://github.com/DeqianBai/Your-first-machine-learning-Project---End-to-End-in-Python
[3] DeqianBai(https://github.com/DeqianBai)
总结
本文是一个完整的监督学习的机器学习流程,包含:
数据清理,探索性数据分析,特征工程和选择等常见问题的解决办法 随机搜索,网格搜索,交叉验证等方法寻找最优超参数 可视化决策树 对完整的机器学习项目流程建立一个宏观的了解
代码非常完整,可以在平时的机器学习项目中拿来用,只需要改少量代码即可。
推荐阅读
如有收获,欢迎三连