
从AlexNet到BERT:深度学习中那些最重要的idea回顾
AlexNet 和 Dropout:AlexNet 直接打开了深度学习时代,奠定了之后 CV 里面 CNN 模型基本结构,Dropout 也不用说,都成了基本配置。
深度强化学习的Atari:深度强化学习的开山之作,DQN 之后也是打开了一条新路,大家开始在各种游戏上进行尝试。
Seq2Seq+Atten:这个在 NLP 领域的影响没得说,有段时间,甚至都在说任何 NLP 任务都能 Seq2Seq+Atten 来解决,而且这篇其实还为之后纯 Attention 的 Transformer 打下了基础。
Adam Optimizer:不多说,训练模型的心头好。
Generative Adversarial Networks (GANs):这个也是从14年开始几年里火得一塌糊涂,大家都在搞各种各样的 GAN,直到去年 StyleGAN 这种集大成模型出来,才算是差不多消停。引起各种争议的 Deepfake 是成果之一,最近都有看到人用它做假资料。
Residual Networks:和 Dropout,Adam 一样变成了基本配置,模型要深全靠它。
Transformers:纯 Attention 模型,直接给 NLP 里的 LSTM 给取代了,而且在其他领域也慢慢取得很好效果,同时也为之后 BERT 预训练模型打下基础。
BERT and 精调 NLP 模型:利用可扩展性非常强大的 Transformer,加上大量数据,加上一个简单的自监督训练目标,就能够获得非常强大的预训练模型,横扫各种任务。最近的一个是 GPT3,自从给出 API 后,网络上展现出了各种特别 fancy 的demo,简直了,各种自动补全。
深度学习是个瞬息万变的领域,海量的研究论文和想法可能会令人感觉有点跟不上。就算是经验丰富的研究人员,有时也会很懵圈,很难告诉公司PR真正的突破是哪些。
按照“时间是检验真理的唯一标准”,作者在这篇文章回顾了那些经受住时间考验的研究,它们或它们的改进已被反复用在各种研究和应用上,效果也有目共睹。
如果你想看完这篇文章之后就马上入门,那你就想多了。最好的方法是,搞明白和复现下面提到的经典论文,这可以给你打下非常好的基础,而且对你之后看懂最新研究和开展自己项目也会很有帮助。
此外,按下面这样时间顺序浏览论文也很有用,可以帮你了解当前的技术从何而来,以及它们最初为何被发明出来。
简单来说,作者在这篇文章会总结出尽量少,但涵盖了理解现代深度学习研究所需的大部分基本知识的研究。
关于深度学习,一个特点就是其应用领域,包含了机器视觉、自然语言、语音和强化学习等。而这些领域都用着差不多的技术,比如:一个曾用深度学习搞计算机视觉的人,能很快就在NLP研究中取得成果。
即使特定的网络架构有些不同,但概念、方法和代码都是相通的。本文将介绍来自不同领域的一些研究,但进入正题前,需要声明一下:
这篇文章不是为下面提到的研究提供深入详解或代码示例,因为长篇复杂的论文其实很难被总结成一个简短的段落。相反,作者只会简要概述这些技术和相关历史背景,并提供其论文和实现链接。
如果你想学有所得,最好在不用现有代码库或高级库的情况下,从头开始用PyTorch复现一遍论文中的实验。
一些研究的选择可能有些随意。因为总会有些相似技术在相近时间内被发布出来,而本文目的也不是对其进行全面回顾,而是要向萌新介绍各个领域的各种研究。
例如,GAN可能有几百种变体,但无论你要研究哪种,GAN的基本概念都是不可不知的。

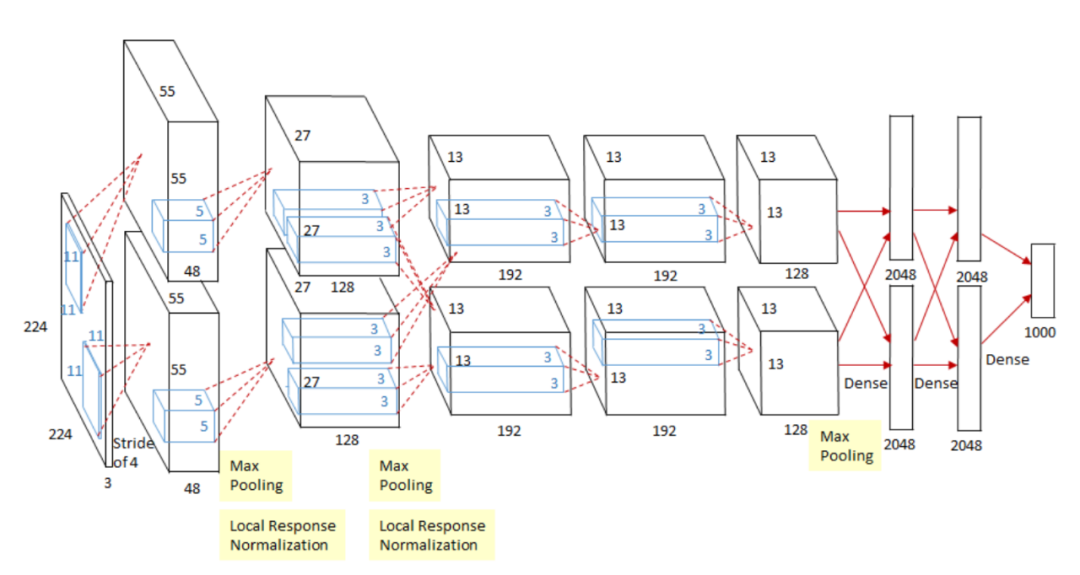
一般认为,是AlexNet开启了近年来深度学习和人工智能研究的大浪潮。而AlexNet其实就是个基于Yann LeCun早年提出的LeNet 的深度卷积网络。
独特之处在于,AlexNet通过结合GPU强大性能和其算法优越而获得了非常大的提升,远远超越之前对ImageNet数据集进行分类的其他方法。它也证明了神经网络的确是有效的!
AlexNet也是最早用Dropout[2]的算法之一,也是自此Dropout成为提高各种深度学习模型泛化能力的关键组件。
AlexNet架构是由卷积层,非线性ReLU和最大池化串成的一系列模块,而现在这些都已被大家接受,成为了标准机器视觉的网络结构了。
如今,由于像PyTorch这样的库已非常强大,跟最新一些架构相比,AlexNet实现已经非常简单了,现在用几行代码就能实现。
值得注意的是,AlexNet的许多实现都用的是它的一个变种,加入了这篇论文One weird trick for parallelizing convolutional neural networks中提到的一个技巧。
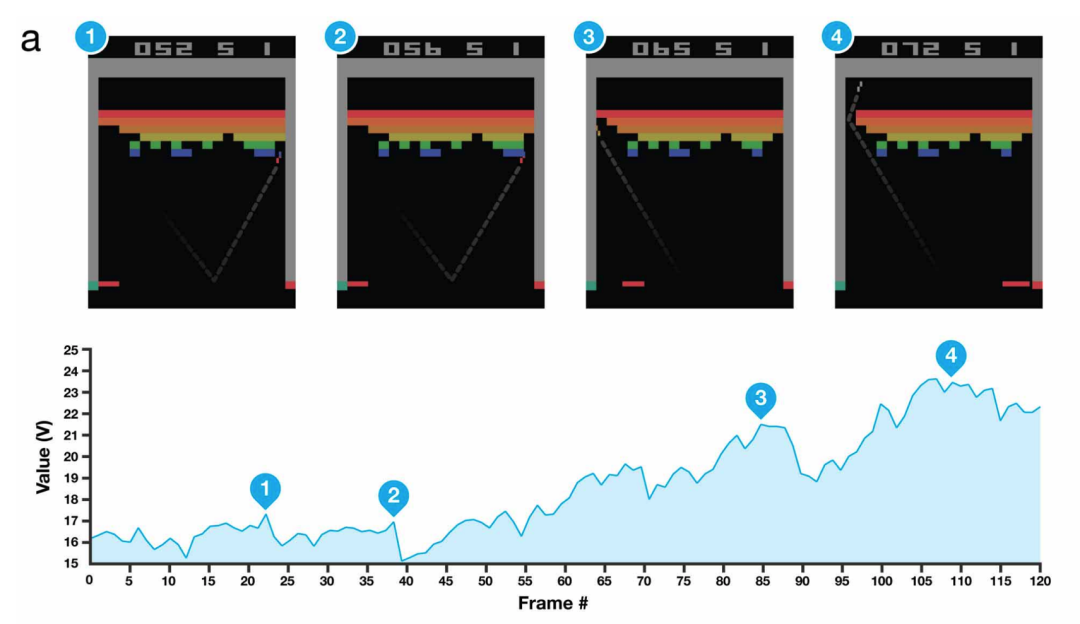
其中,强化学习与监督学习(如图像分类)的不同之处在于,强化学习的智能体必须在一段时间步(如一盘游戏)中学习最大化奖励总和,而不仅仅是预测标签。
由于其智能体是能直接与环境交互的,而且每个行动都会影响下一个行动,因此,训练其数据并不是独立同分布的。
这也使得许多强化学习模型的训练很不稳定,但这个问题可以用经验重播(experience replay)等技术来解决。
尽管没有明显的算法创新,但这项研究巧妙结合了各种现有技术,比如在GPU上训练卷积神经网络和经验重播,以及一些数据处理技巧,从而取得了超出大家预期令人印象深刻的结果。
这也让人们更有信心去扩展深度强化学习技术,以解决更复杂的任务,比如:围棋,多塔2,星际争霸2等。
而且从这篇论文后,Atari游戏也变成了强化学习研究的测试标准。最初的方法尽管超过了人类的表现,但只能在7种游戏取得这样的表现。
而之后几年,这些想法被不断拓展,在越来越多的游戏中击败人类。直到最近,技术才攻克了全部57款游戏并超过了所有人类水平,其中的《蒙特祖玛的复仇》以其需要长期规划著称,被认为是最难攻克的游戏之一。
https://pytorch.org/tutorials/intermediate/seq2seq_translation_tutorial.html
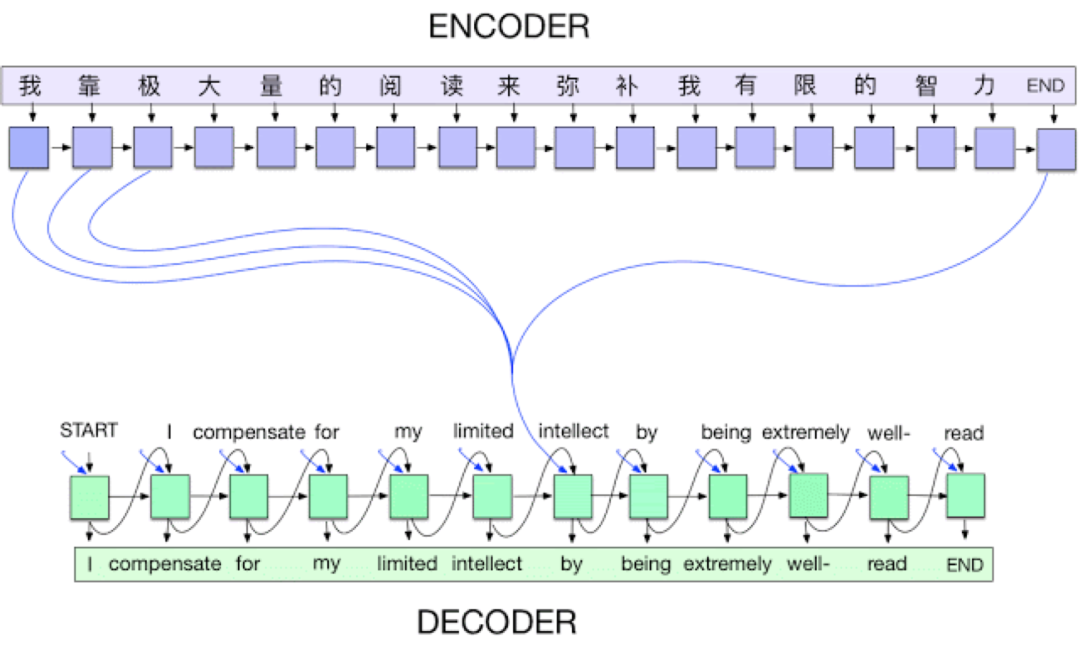
深度学习中很多最让人印象深刻的结果都是和视觉相关的任务,而且由卷积神经网络驱动。
尽管NLP领域有通过用LSTM以及编码器-解码器架构在语言模型和翻译上并取得一些成功,但直到注意力机制的出现,该领域才取得真正令人瞩目的成就。
在处理语言时,每个token(可以是一个字符,单词或介于两者之间)都会被喂入一个循环网络(如LSTM)中,该网络会存储先前处理过的输入。
换句话说,这就像一个时间序列的句子,每个token代表一个时间步。而这些循环模型在处理序列时很容易“忘记”较早的输入,因此很难处理长距离依赖关系。
由于其中梯度要通过很多时间步来传播,这会导致梯度爆炸和梯度消失等问题,所以用梯度下降来优化循环模型也变得困难。
而引入注意力机制有助于缓解该问题,通过直接连接,它为网络提供了一种自适应的能“回顾”较早时间步的方法。这些连接使网络可以决定在生成特定输出时,重要的输入有哪些。
简单用翻译来举例子:当生成一个输出词时,通常有一个或多个特定的输入单词被注意力机制选中,作为输出参考。
神经网络一般是通过用优化器最小化损失函数来进行训练的,而优化器的作用则是搞明白怎么调节网络参数使其能学习到指定目标。
大部分优化器都是基于随机梯度下降法(SGD)(https://ruder.io/optimizing-gradient-descent/)来改进。
但要指出的是,很多优化器本身还包含可调参数,如学习率。所以,为特定问题找到正确的设置,不光能减少训练时间,而且还能找到更好的损失函数局部最优,这往往也能使模型获得更好结果。
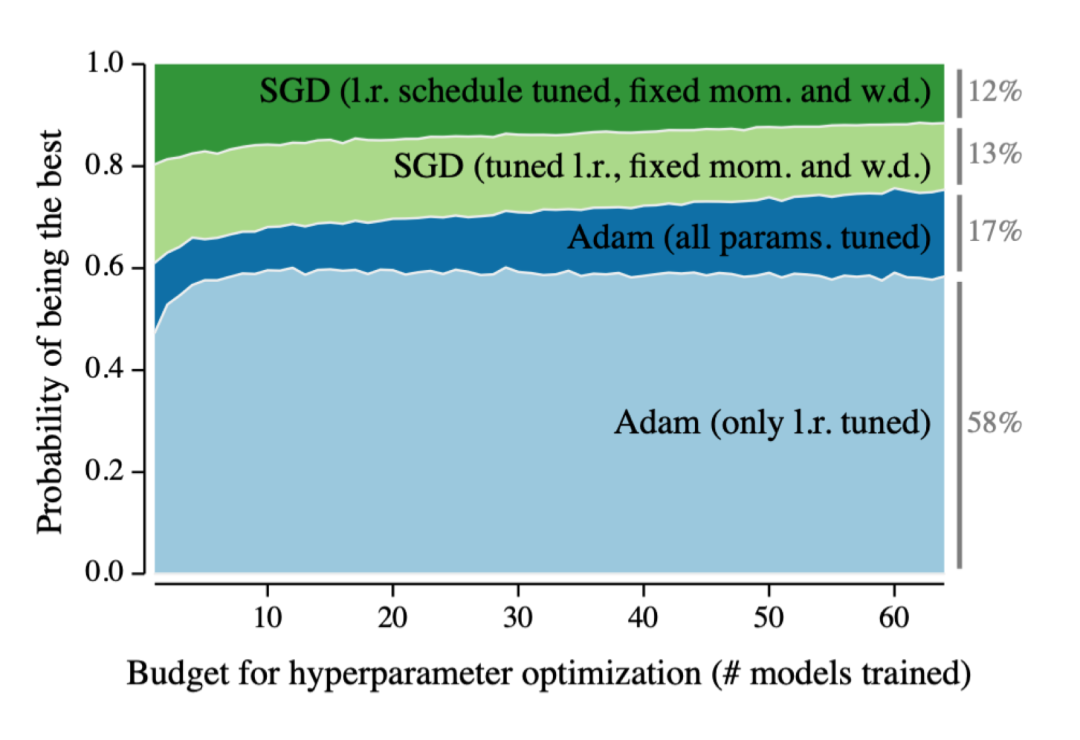
之前,财大气粗的研究室通常要跑特烧钱的超参搜索,来弄出一套给SGD用的学习率调节方案。虽然它能超过之前最好的表现,但往往也意味着要花大量的钱来调节优化器。
这些细节在论文里一般不会提的,所以那些没有相同预算来调优化器的贫穷研究员们,就总会被较差的结果卡住,还没办法。
而Adam给这些研究员带了福音,它能通过梯度的一阶和二阶矩来自动调整学习率。而且实验结果证明其非常可靠,对超参的选择也不太敏感。
换句话说,Adam拿来就能用,不用像其它优化器那样要进行大量调参。尽管调优后的SGD可能获得更好的结果,但Adam却使研究变得更容易了。
因为一旦出现问题时,你就知道应该不太可能是调参引起的问题。

GAN的基本思想是同时训练两个网络,生成器和判别器。生成器的目标是产生能欺骗判别器的样本,而判别器经过训练,则要分辨真实图像和生成图像。
随着训练进行,判别器将变得更善于识别假图片,而生成器也将变得更善于欺骗判别器,产生更逼真的样本,这就是对抗网络之为对抗所在。刚开始的GAN产生的还是模糊低分辨率的图像,而且训练起来相当不稳定。
但随着技术进步,类似于DCGAN[17]、Wasserstein GAN[25]、CycleGAN[26]、StyleGAN(v2)[27]等变体和改进都能产生更高分辨率的逼真图像和视频。
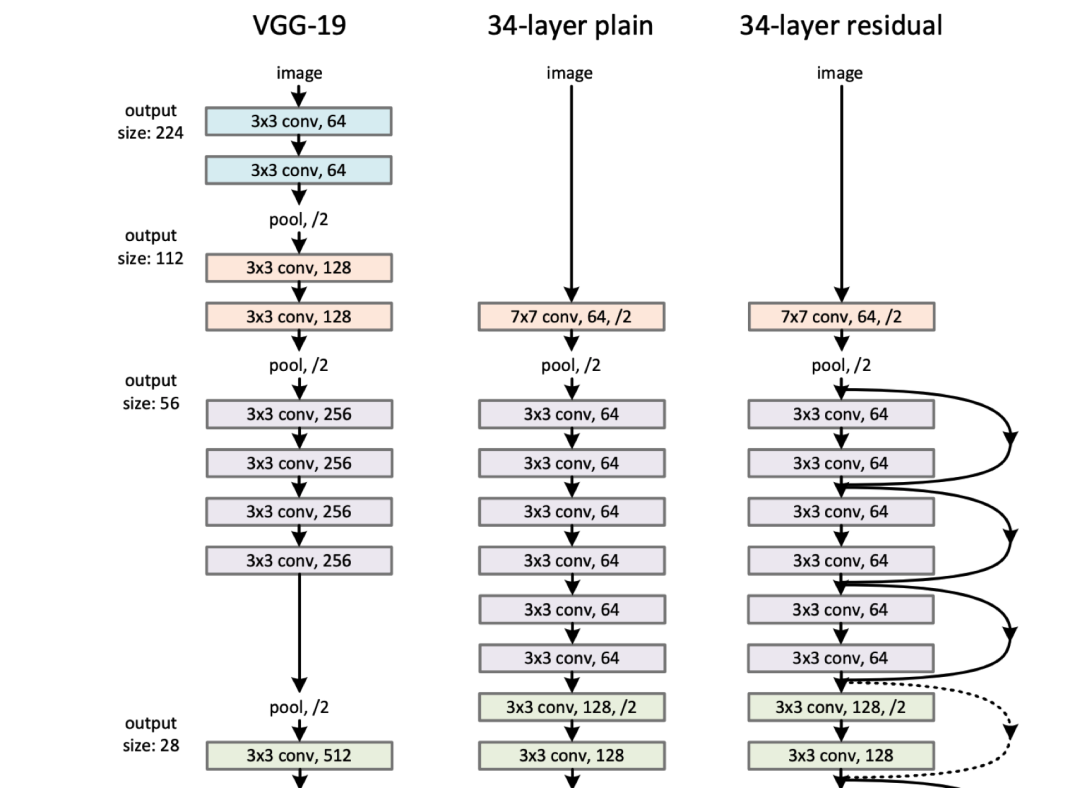
研究者们在AlexNet的基础上,又发明了基于卷积神经网络的性能更好的架构,如VGGNet[28]、Inception[29]等。
而ResNet则是这一系列进展中的最重要的突破所在。时至今日,ResNet变体已被用作各种任务的基准模型架构,也被用于更复杂架构的基础。
RseNet之所以特别,除了其在ILSVRC 2015分类挑战赛中获得冠军外,更在于其相比于其他网络架构的深度。
论文中提到的网络最深的有1000层,尽管在基准任务上比101和152层的略差些,但仍然表现出色。因为梯度消失问题,训练这样一个深度的网络其实是非常具有挑战的,序列模型也有同样的问题。
在此之前,很少有研究者认为训练如此深的网络还能有这么稳定的结果。
ResNet使用捷径连接的方式来帮助梯度传递。一种理解是,ResNet仅需要学习从一层到另一层的“差分”,这比学习一个完全转换要简单些。
此外,ResNet中的残差连接算是Highway Networks[30]的一种特殊情况,而Highway Networks 又受到了LSTM里门控机制的启发。
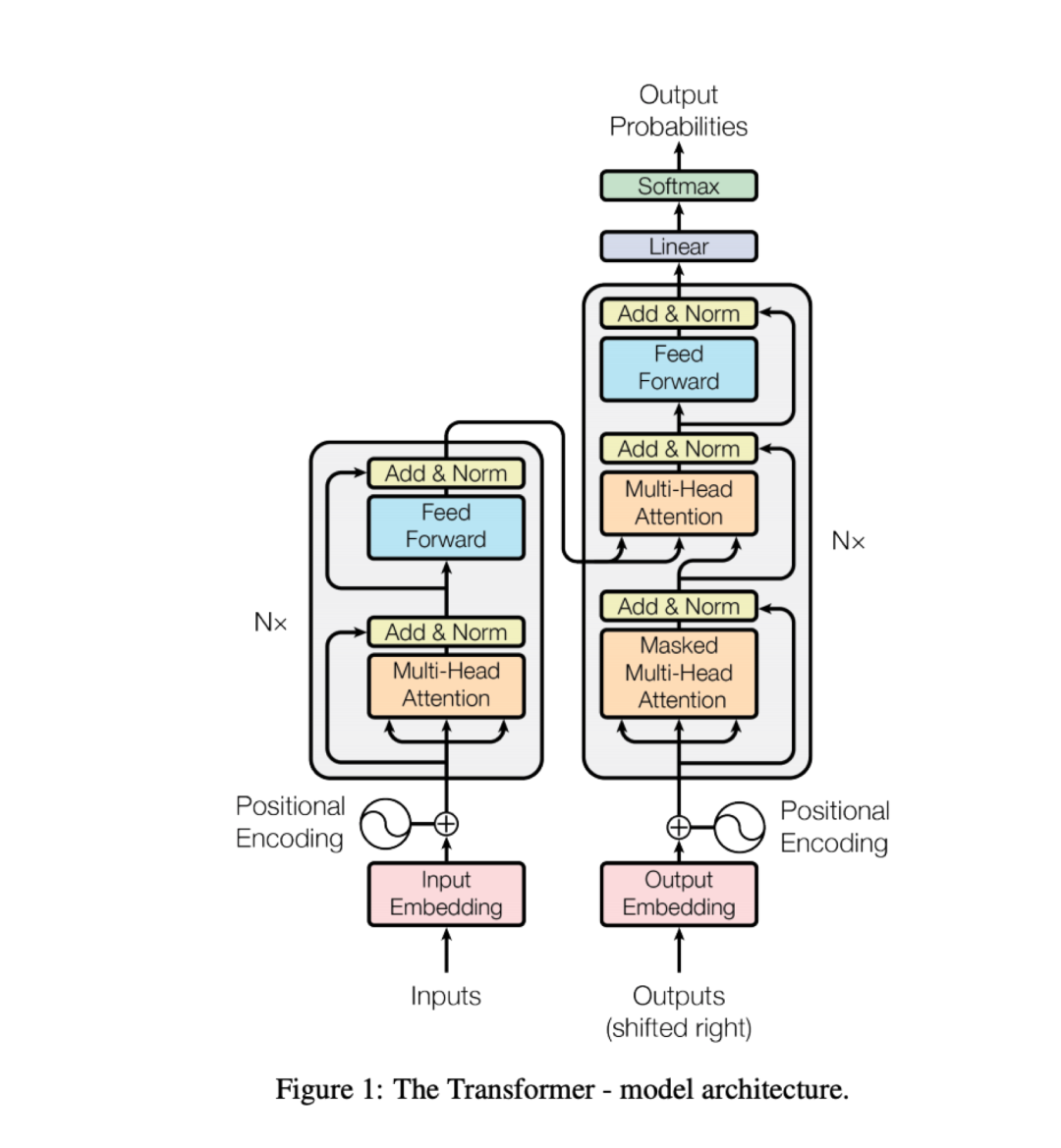
Transformer – 模型架构
Seq2Seq+Atten模型(前面已经介绍过了)性能很好,但由于它的递归特性,导致需要按时序计算。所以很难并行,一次只能处理一步,而每一步又取决于前一个。
这也使得它很难用在长序列数据上,即使有注意力机制,仍然难以对复杂的长距离依赖关系进行建模,而且其大部分工作还是在递归层里实现的。
Transformers直接解决了这些问题,丢掉了递归部分,取而代之的是多个前馈的自注意力层,并行处理所有输入,并在输入与输出之间找到相对较短(容易用梯度下降优化)的路径。
这使得它的训练速度非常快,易于扩展,并且能够处理更多的数据。为了加入输入位置信息(在递归模型中是隐式的),Transformers还用了位置编码。
要了解有关Transformer工作原理的更多信息,建议阅读这个图解博客。
如果仅仅只是说Transformers比几乎所有人预期的表现都要好,那简直就是对它的侮辱。
因为在接下来的几年里,它不光表现更好,而且还直接干掉了RNN,成为了绝大多数NLP和其他序列任务标准架构,甚至还用在了机器视觉上。
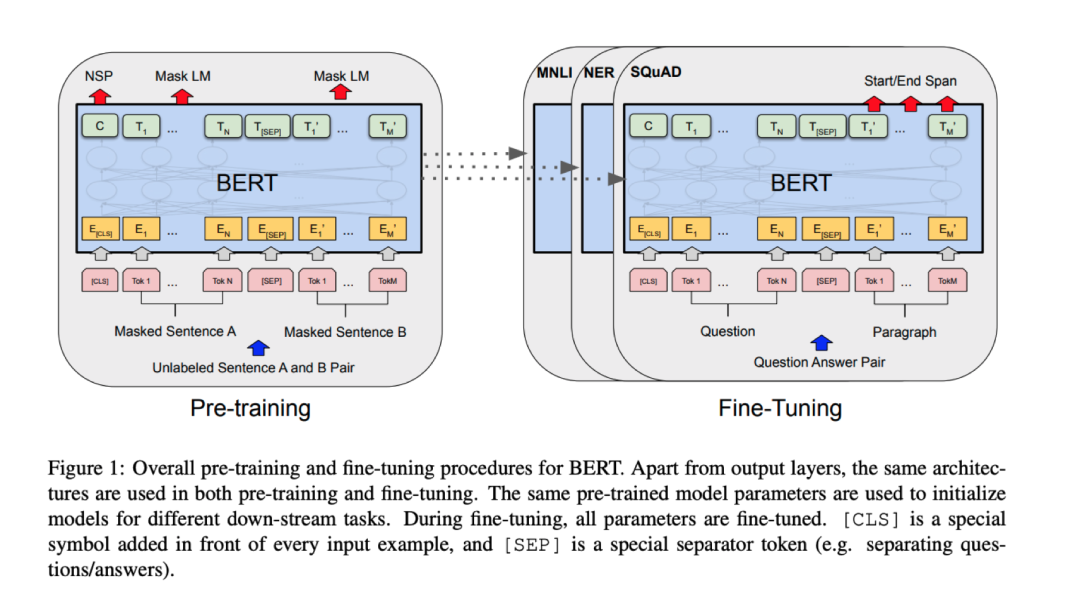
预训练指训练一个模型来执行某个任务,之后用学到的参数来作为初始化参数来学习一个相关任务。
这个其实很直观,一个已经学会分类猫或狗图像的模型,应该已经学会了一些关于图像和毛茸茸动物的基础知识。
当这个模型被微调用来对狐狸进行分类时,可以预计它比一个从头开始学习的模型更好。同样,一个学会了预测句子中下一个词的模型,应该已经学会了一些关于人类语言模型的知识。
那么它的参数对于相关任务(如翻译或情感分析)也会是一个很好的初始化。
预训练和微调已经在计算机视觉和NLP领域取得了成功,虽然在计算机视觉中其早已成为标准,但如何在NLP领域更好的发挥作用似乎还有些挑战。大多数最佳结果仍然出自完全监督模型。
随着ELMo [34], ULMFiT [35]等方法出现,NLP研究者终于也能开始做预训练的工作了(之前词向量其实也算),特别是对Transformer的应用,更是产生了一系列如 GPT和BERT的方法。
BERT算是预训练比较新的成果,很多人认为它开创了NLP研究新纪元。它没有像大多数预训练模型一样,训练预测下一个单词,而是预测句子中被掩盖(故意删除)的单词,以及两个句子是否相邻。
注意,这些任务不需要标注数据,它可以在任何文本上进行训练,而且可以是一大堆文本! 于是预训练好的模型,就能学会了一些语言的一般属性,之后就可以进行微调了,用来解决监督任务,如问答或情感预测。
BERT在各种任务中的表现都非常好,出来就屠榜。而像HuggingFace这样的公司也坐上浪头,让用于NLP任务的微调BERT模型变得容易下载和使用。
之后,BERT又被XLNet[31]和RoBERTa[32]以及ALBERT[33]等新模型不断传颂,现在基本上整个领域人都知道了。
纵观整个深度学习的历史,最明显的趋势或许就是 Sutton 说的 the bitter lesson(苦痛的一课)。如里面说的,能够利用更好并行(更多数据)并且有更多模型参数的算法,能一次又一次地战胜一些所谓 "更聪明的技术"。
这种趋势似乎到2020年还在持续,OpenAI的GPT-3模型,一个拥有1750亿参数的庞大语言模型,尽管其训练目标和架构都很简单,但却表现出了意想不到的泛化性(各种效果非常好的demo)。
有着同样趋势的还有contrastive self-supervised learning等方法,如SimCLR(https://arxiv.org/abs/2002.05709),它能更好的利用无标签数据。
随着模型变得越来越大,训练速度越来越快,也让能有效利用网上的大量无标注数据集,学习可迁移通用知识的技术正变得越来越有价值。
https://dennybritz.com/blog/deep-learning-most-important-ideas/
参考文献:
[1] ImageNet Classification with Deep Convolutional Neural Networks
Alex Krizhevsky, Ilya Sutskever, Geoffrey E Hinton (2012)
Advances in Neural Information Processing Systems 25
[http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf] [Semantic Scholar] [Google Scholar]
[2] Improving neural networks by preventing co-adaptation of feature detectors
Geoffrey E. Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, Ruslan R. Salakhutdinov (2012)
arXiv:1207.0580 \[cs\]
[http://arxiv.org/abs/1207.0580] [Semantic Scholar] [Google Scholar]
[3] Neural Machine Translation by Jointly Learning to Align and Translate
Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio (2016)
arXiv:1409.0473 \[cs, stat\]
[http://arxiv.org/abs/1409.0473] [Semantic Scholar] [Google Scholar]
[4] Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le (2014)
arXiv:1409.3215 \[cs\]
[http://arxiv.org/abs/1409.3215] [Semantic Scholar] [Google Scholar]
[5] Attention Is All You Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin (2017)
arXiv:1706.03762 \[cs\]
[http://arxiv.org/abs/1706.03762] [Semantic Scholar] [Google Scholar]
[6] Generative Adversarial Networks
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio (2014)
arXiv:1406.2661 \[cs, stat\]
[http://arxiv.org/abs/1406.2661] [Semantic Scholar] [Google Scholar]
[7] Playing Atari with Deep Reinforcement Learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller (2013)
arXiv:1312.5602 \[cs\]
[http://arxiv.org/abs/1312.5602] [Semantic Scholar] [Google Scholar]
[8] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle, Michael Carbin (2019)
arXiv:1803.03635 \[cs\]
[http://arxiv.org/abs/1803.03635] [Semantic Scholar] [Google Scholar]
[9] BERT: Pre-training of Deep Bi

2020-08-08
2020-08-07
2020-08-07
2020-08-05