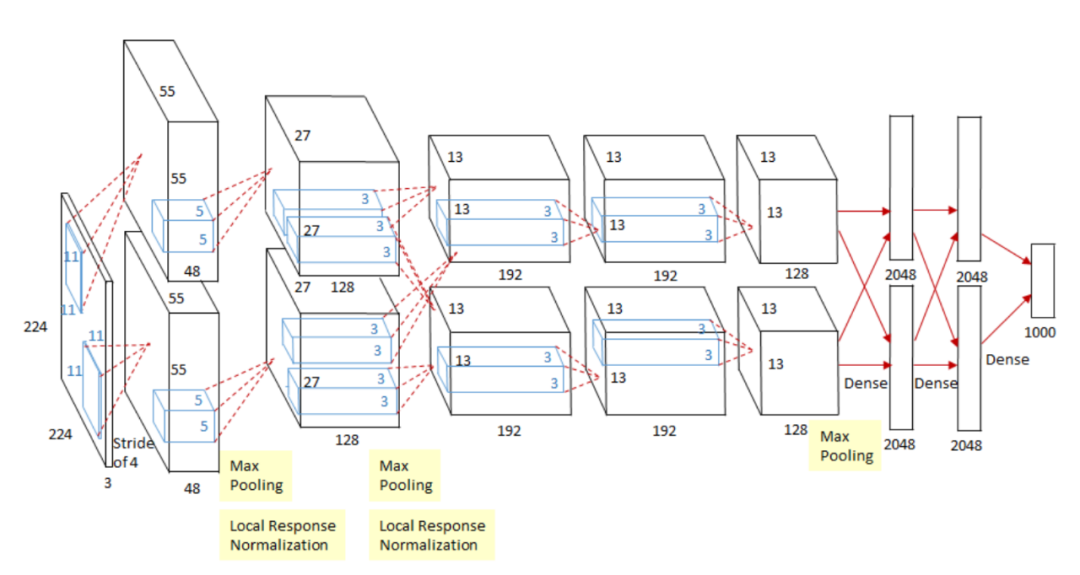
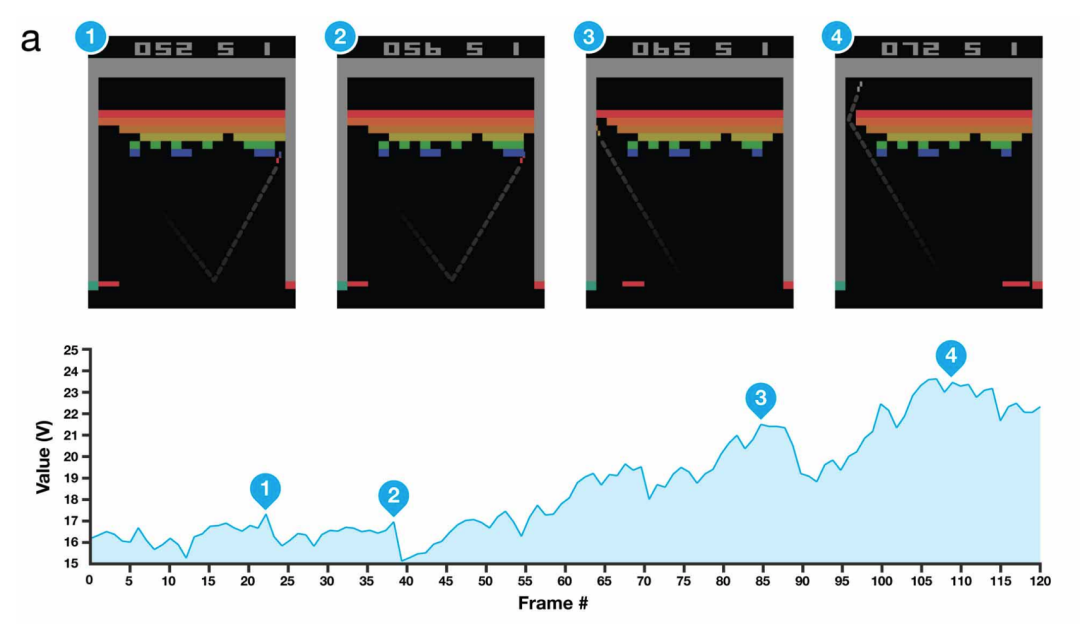
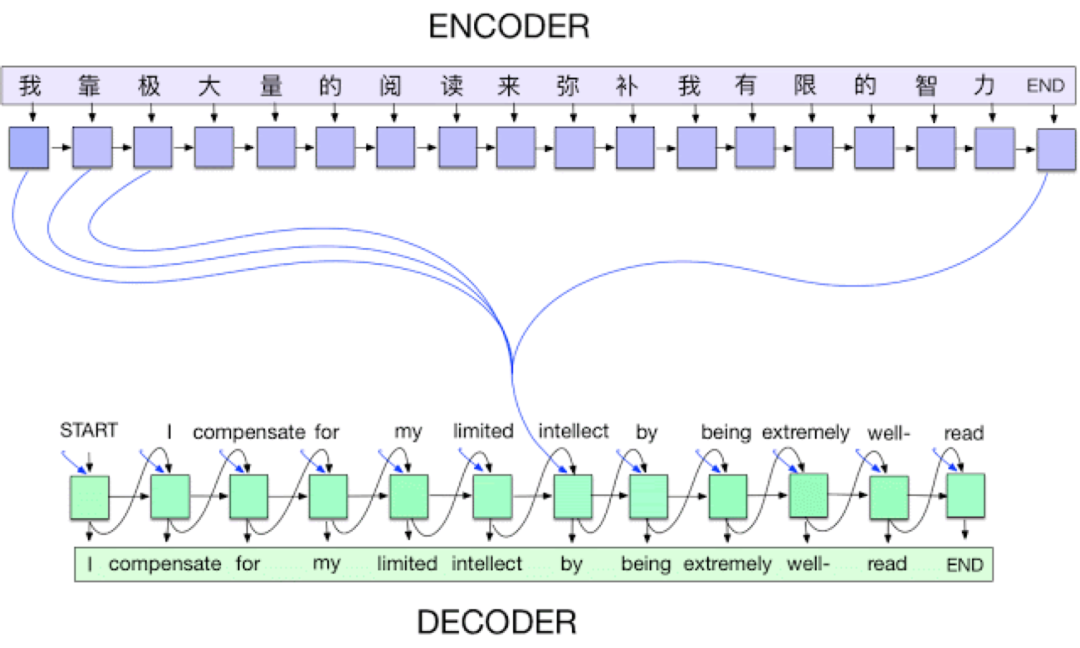
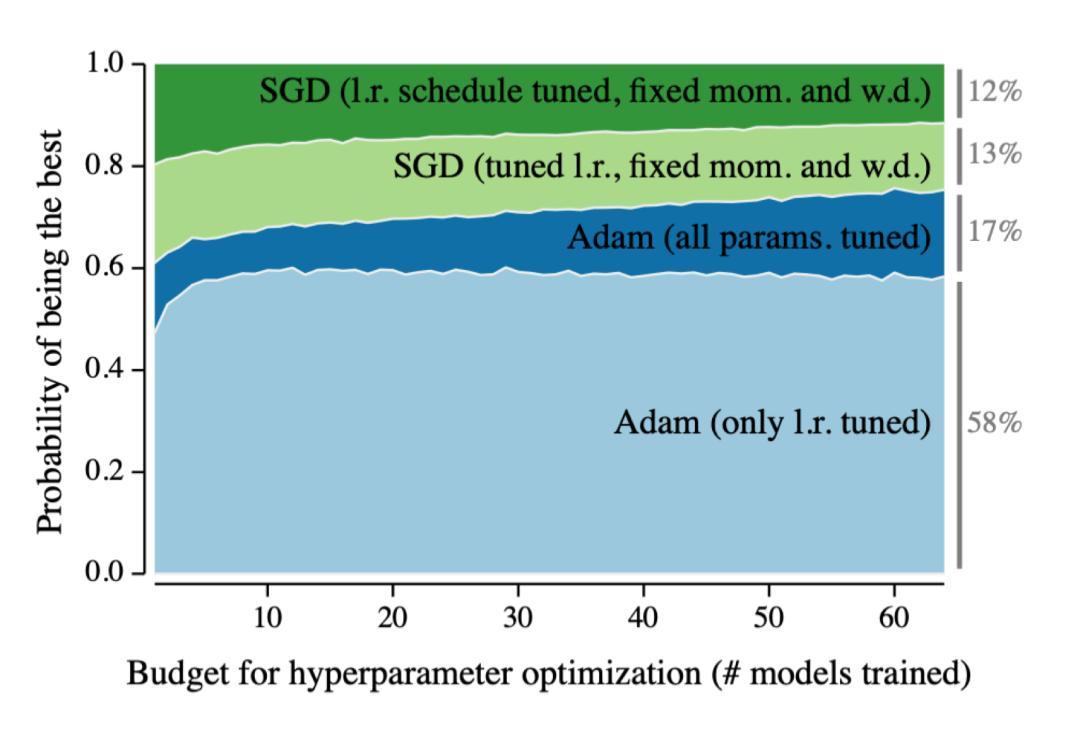
Alex Krizhevsky, Ilya Sutskever, Geoffrey E Hinton (2012)
Advances in Neural Information Processing Systems 25
[http://papers.nips.cc/paper/4824-imagenet-classification-with-deep-convolutional-neural-networks.pdf] [Semantic Scholar] [Google Scholar]
[2] Improving neural networks by preventing co-adaptation of feature detectors
Geoffrey E. Hinton, Nitish Srivastava, Alex Krizhevsky, Ilya Sutskever, Ruslan R. Salakhutdinov (2012)
arXiv:1207.0580 \[cs\]
[http://arxiv.org/abs/1207.0580] [Semantic Scholar] [Google Scholar]
[3] Neural Machine Translation by Jointly Learning to Align and Translate
Dzmitry Bahdanau, Kyunghyun Cho, Yoshua Bengio (2016)
arXiv:1409.0473 \[cs, stat\]
[http://arxiv.org/abs/1409.0473] [Semantic Scholar] [Google Scholar]
[4] Sequence to Sequence Learning with Neural Networks
Ilya Sutskever, Oriol Vinyals, Quoc V. Le (2014)
arXiv:1409.3215 \[cs\]
[http://arxiv.org/abs/1409.3215] [Semantic Scholar] [Google Scholar]
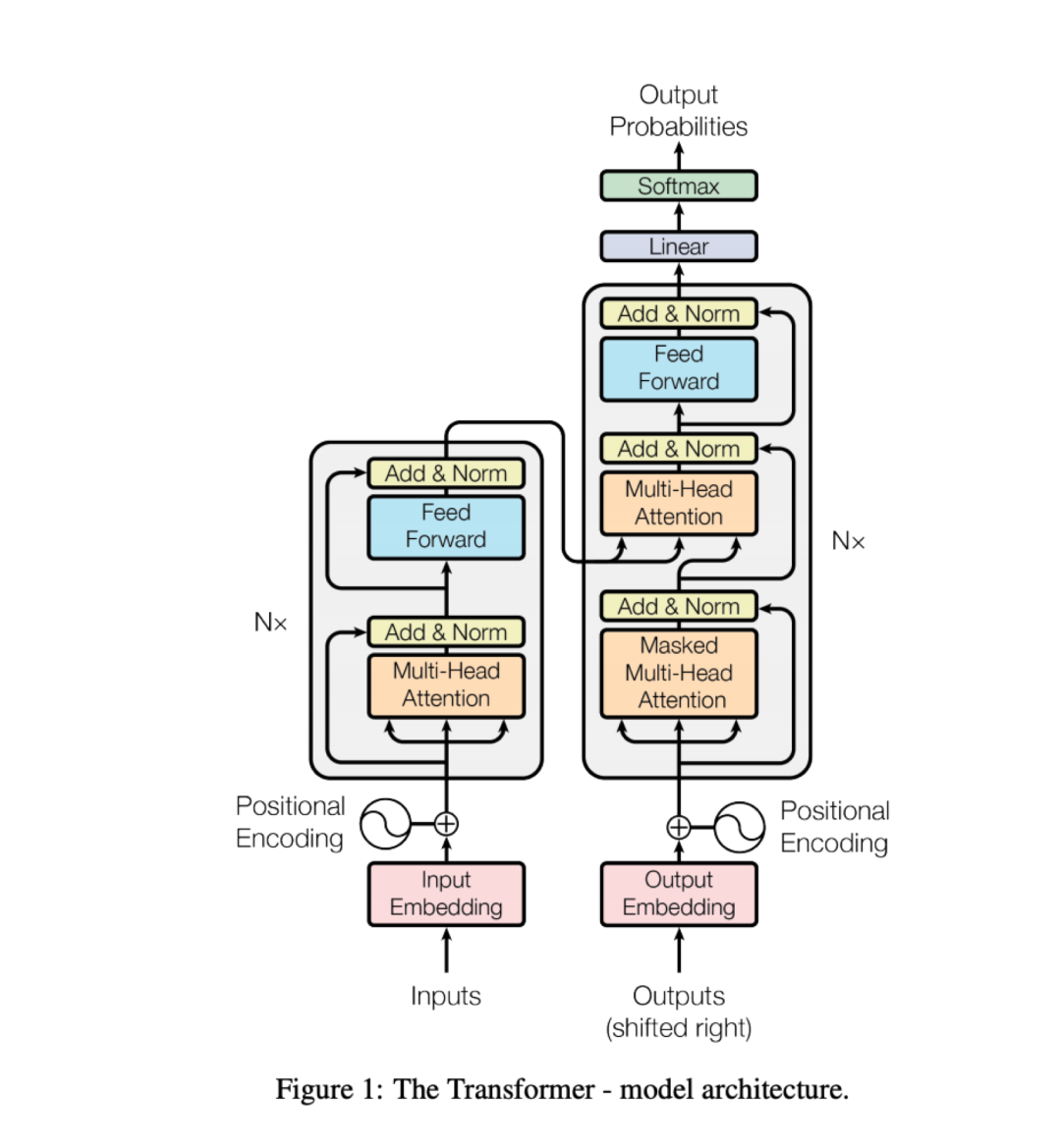
[5] Attention Is All You Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin (2017)
arXiv:1706.03762 \[cs\]
[http://arxiv.org/abs/1706.03762] [Semantic Scholar] [Google Scholar]
[6] Generative Adversarial Networks
Ian J. Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio (2014)
arXiv:1406.2661 \[cs, stat\]
[http://arxiv.org/abs/1406.2661] [Semantic Scholar] [Google Scholar]
[7] Playing Atari with Deep Reinforcement Learning
Volodymyr Mnih, Koray Kavukcuoglu, David Silver, Alex Graves, Ioannis Antonoglou, Daan Wierstra, Martin Riedmiller (2013)
arXiv:1312.5602 \[cs\]
[http://arxiv.org/abs/1312.5602] [Semantic Scholar] [Google Scholar]
[8] The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks
Jonathan Frankle, Michael Carbin (2019)
arXiv:1803.03635 \[cs\]
[http://arxiv.org/abs/1803.03635] [Semantic Scholar] [Google Scholar]
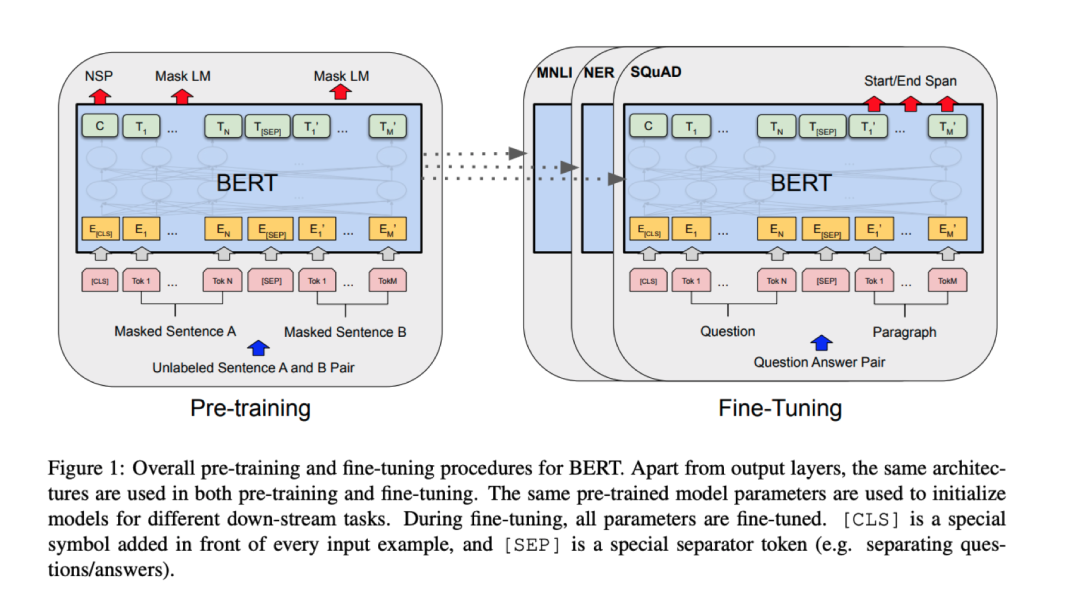
[9] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova (2019)
arXiv:1810.04805 \[cs\]
[http://arxiv.org/abs/1810.04805] [Semantic Scholar] [Google Scholar]
[10] Language Models are Unsupervised Multitask Learners
Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, Ilya Sutskever
[Semantic Scholar] [Google Scholar]
[11] Language Models are Few-Shot Learners
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin, Scott Gray, Benjamin Chess, Jack Clark, Christopher Berner, Sam McCandlish, Alec Radford, Ilya Sutskever, Dario Amodei (2020)
arXiv:2005.14165 \[cs\]
[http://arxiv.org/abs/2005.14165] [Semantic Scholar] [Google Scholar]
[12] Adam: A Method for Stochastic Optimization
Diederik P. Kingma, Jimmy Ba (2017)
arXiv:1412.6980 \[cs\]
[http://arxiv.org/abs/1412.6980] [Semantic Scholar] [Google Scholar]
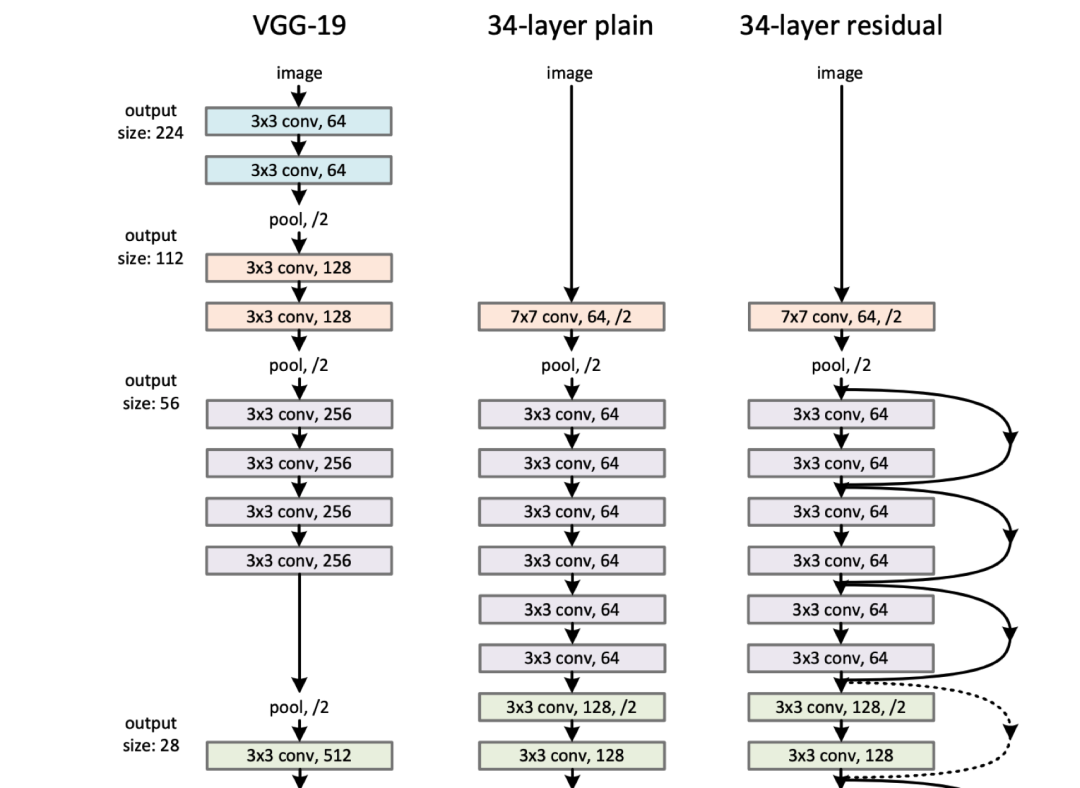
[13] Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun (2015)
arXiv:1512.03385 \[cs\]
[http://arxiv.org/abs/1512.03385] [Semantic Scholar] [Google Scholar]
[14] One weird trick for parallelizing convolutional neural networks
Alex Krizhevsky (2014)
arXiv:1404.5997 \[cs\]
[http://arxiv.org/abs/1404.5997] [Semantic Scholar] [Google Scholar]
[15] Self-Improving Reactive Agents Based on Reinforcement Learning, Planning and Teaching
Long-Ji Lin (1992)
Machine Language
[https://doi.org/10.1007/BF00992699] [Semantic Scholar] [Google Scholar]
[16] Long Short-Term Memory
Sepp Hochreiter, Jürgen Schmidhuber (1997)
Neural Computation
[https://doi.org/10.1162/neco.1997.9.8.1735] [Semantic Scholar] [Google Scholar]
[17] Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
Alec Radford, Luke Metz, Soumith Chintala (2016)
arXiv:1511.06434 \[cs\]
[http://arxiv.org/abs/1511.06434] [Semantic Scholar] [Google Scholar]
[18] Mastering the game of Go with deep neural networks and tree search
David Silver, Aja Huang, Chris J. Maddison, Arthur Guez, Laurent Sifre, George Driessche, Julian Schrittwieser, Ioannis Antonoglou, Veda Panneershelvam, Marc Lanctot, Sander Dieleman, Dominik Grewe, John Nham, Nal Kalchbrenner, Ilya Sutskever, Timothy Lillicrap, Madeleine Leach, Koray Kavukcuoglu, Thore Graepel, Demis Hassabis (2016)
Nature
[https://www.nature.com/articles/nature16961] [Semantic Scholar] [Google Scholar]
[19] Convolutional Sequence to Sequence Learning
Jonas Gehring, Michael Auli, David Grangier, Denis Yarats, Yann N. Dauphin (2017)
arXiv:1705.03122 \[cs\]
[http://arxiv.org/abs/1705.03122] [Semantic Scholar] [Google Scholar]
[20] WaveNet: A Generative Model for Raw Audio
Aaron van den Oord, Sander Dieleman, Heiga Zen, Karen Simonyan, Oriol Vinyals, Alex Graves, Nal Kalchbrenner, Andrew Senior, Koray Kavukcuoglu (2016)
arXiv:1609.03499 \[cs\]
[http://arxiv.org/abs/1609.03499] [Semantic Scholar] [Google Scholar]
[21] The Arcade Learning Environment: An Evaluation Platform for General Agents
Marc G. Bellemare, Yavar Naddaf, Joel Veness, Michael Bowling (2013)
Journal of Artificial Intelligence Research
[http://arxiv.org/abs/1207.4708] [Semantic Scholar] [Google Scholar]
[22] First return then explore
Adrien Ecoffet, Joost Huizinga, Joel Lehman, Kenneth O. Stanley, Jeff Clune (2020)
arXiv:2004.12919 \[cs\]
[http://arxiv.org/abs/2004.12919] [Semantic Scholar] [Google Scholar]
[23] Agent57: Outperforming the Atari Human Benchmark
Adrià Puigdomènech Badia, Bilal Piot, Steven Kapturowski, Pablo Sprechmann, Alex Vitvitskyi, Daniel Guo, Charles Blundell (2020)
arXiv:2003.13350 \[cs, stat\]
[http://arxiv.org/abs/2003.13350] [Semantic Scholar] [Google Scholar]
[24] Optimizer Benchmarking Needs to Account for Hyperparameter Tuning
Prabhu Teja Sivaprasad, Florian Mai, Thijs Vogels, Martin Jaggi, François Fleuret (2020)
arXiv:1910.11758 \[cs, stat\]
[http://arxiv.org/abs/1910.11758] [Semantic Scholar] [Google Scholar]
[25] Wasserstein GAN
Martin Arjovsky, Soumith Chintala, Léon Bottou (2017)
arXiv:1701.07875 \[cs, stat\]
[http://arxiv.org/abs/1701.07875] [Semantic Scholar] [Google Scholar]
[26] Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros (2018)
arXiv:1703.10593 \[cs\]
[http://arxiv.org/abs/1703.10593] [Semantic Scholar] [Google Scholar]
[27] Analyzing and Improving the Image Quality of StyleGAN
Tero Karras, Samuli Laine, Miika Aittala, Janne Hellsten, Jaakko Lehtinen, Timo Aila (2020)
arXiv:1912.04958 \[cs, eess, stat\]
[http://arxiv.org/abs/1912.04958] [Semantic Scholar] [Google Scholar]
[28] Very Deep Convolutional Networks for Large-Scale Image Recognition
Karen Simonyan, Andrew Zisserman (2015)
arXiv:1409.1556 \[cs\]
[http://arxiv.org/abs/1409.1556] [Semantic Scholar] [Google Scholar]
[29] Going Deeper with Convolutions
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich (2014)
arXiv:1409.4842 \[cs\]
[http://arxiv.org/abs/1409.4842] [Semantic Scholar] [Google Scholar]
[30] Training Very Deep Networks
Rupesh K Srivastava, Klaus Greff, Jürgen Schmidhuber (2015)
Advances in Neural Information Processing Systems 28
[http://papers.nips.cc/paper/5850-training-very-deep-networks.pdf] [Semantic Scholar] [Google Scholar]
[31] XLNet: Generalized Autoregressive Pretraining for Language Understanding
Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le (2020)
arXiv:1906.08237 \[cs\]
[http://arxiv.org/abs/1906.08237] [Semantic Scholar] [Google Scholar]
[32] RoBERTa: A Robustly Optimized BERT Pretraining Approach
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, Veselin Stoyanov (2019)
arXiv:1907.11692 \[cs\]
[http://arxiv.org/abs/1907.11692] [Semantic Scholar] [Google Scholar]
[33] ALBERT: A Lite BERT for Self-supervised Learning of Language Representations
Zhenzhong Lan, Mingda Chen, Sebastian Goodman, Kevin Gimpel, Piyush Sharma, Radu Soricut (2020)
arXiv:1909.11942 \[cs\]
[http://arxiv.org/abs/1909.11942] [Semantic Scholar] [Google Scholar]
[34] Deep contextualized word representations
Matthew E. Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, Luke Zettlemoyer (2018)
arXiv:1802.05365 \[cs\]
[http://arxiv.org/abs/1802.05365] [Semantic Scholar] [Google Scholar]
[35] Universal Language Model Fine-tuning for Text Classification
Jeremy Howard, Sebastian Ruder (2018)
arXiv:1801.06146 \[cs, stat\]
[http://arxiv.org/abs/1801.06146] [Semantic Scholar] [Google Scholar]