
从AlexNet到BERT:深度学习中那些最重要idea的最简单回顾
点击下方卡片,关注“新机器视觉”公众号
重磅干货,第一时间送达

来自 | 大数据文摘
编译 | 奥🌰vi丫、肉包、Andy
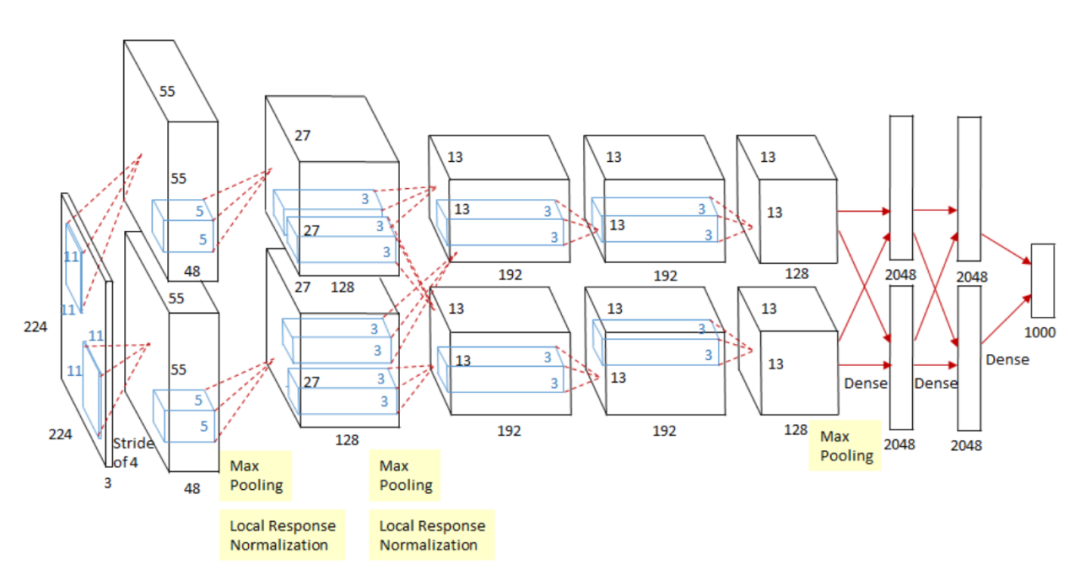
AlexNet 和 Dropout:AlexNet 直接打开了深度学习时代,奠定了之后 CV 里面 CNN 模型基本结构,Dropout 也不用说,都成了基本配置。
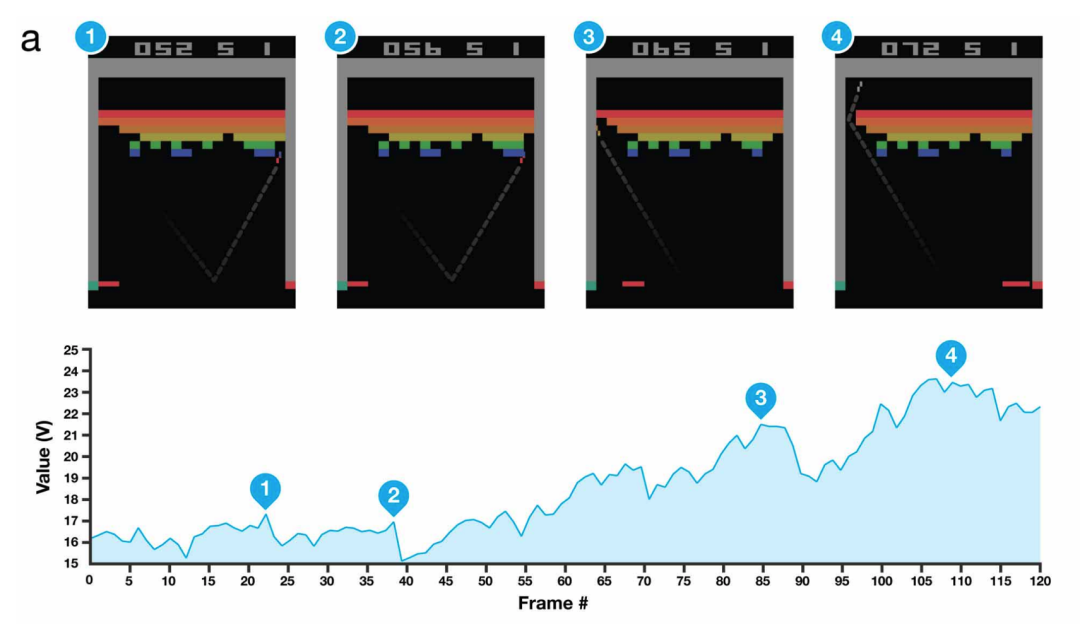
深度强化学习的Atari:深度强化学习的开山之作,DQN 之后也是打开了一条新路,大家开始在各种游戏上进行尝试。
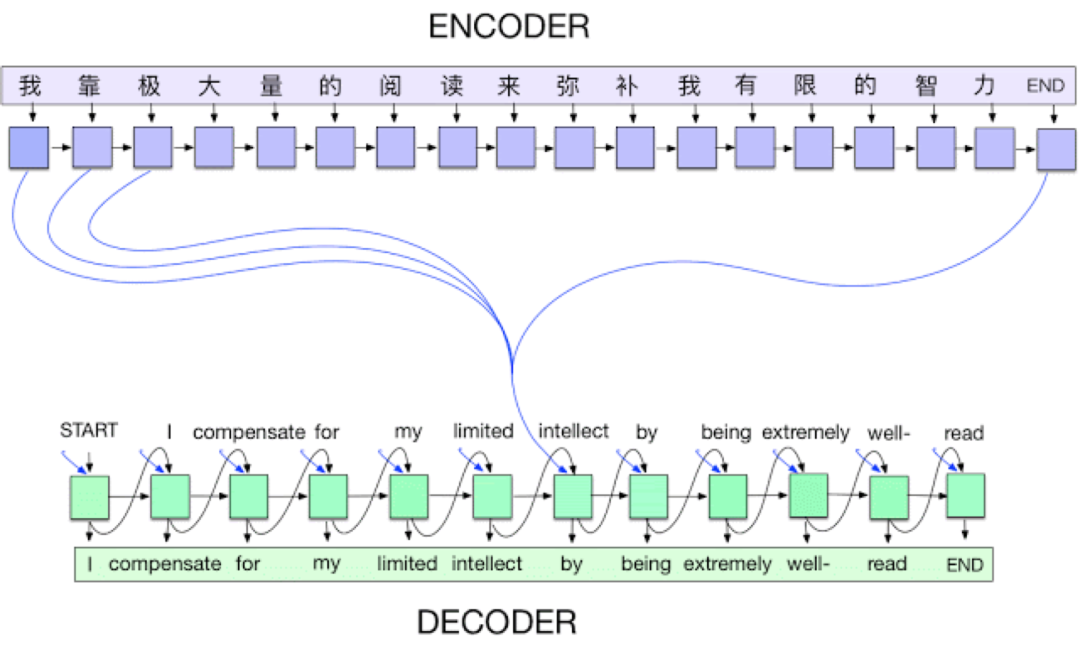
Seq2Seq+Atten:这个在 NLP 领域的影响没得说,有段时间,甚至都在说任何 NLP 任务都能 Seq2Seq+Atten 来解决,而且这篇其实还为之后纯 Attention 的 Transformer 打下了基础。
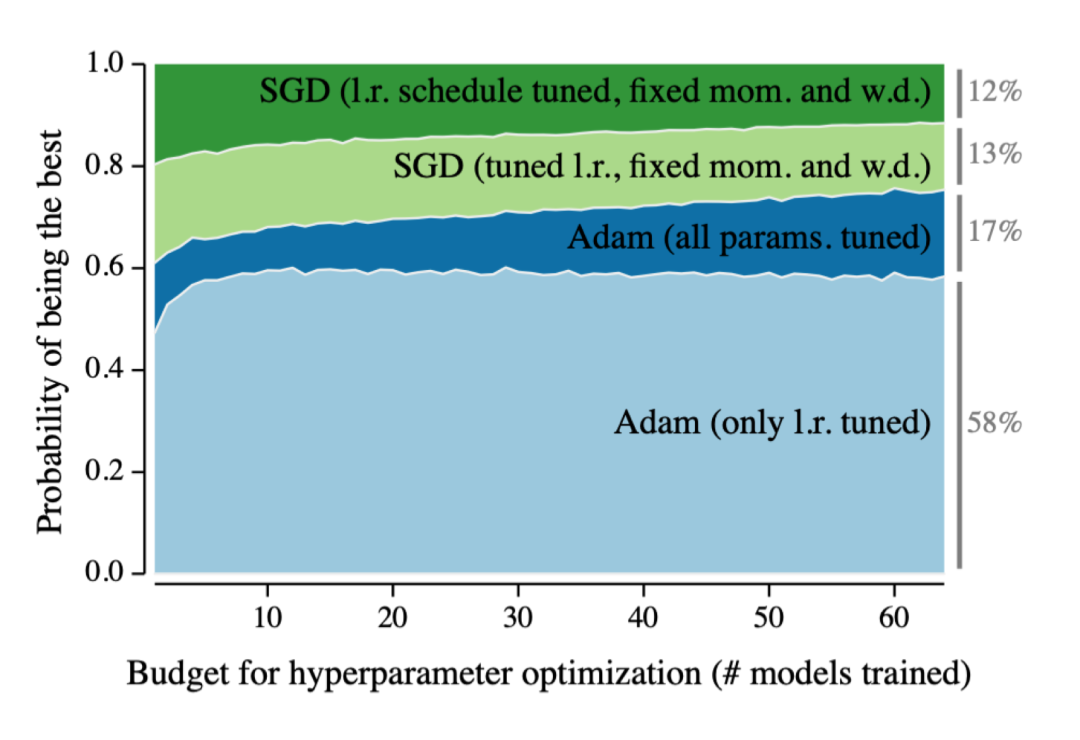
Adam Optimizer:不多说,训练模型的心头好。
Generative Adversarial Networks (GANs):这个也是从14年开始几年里火得一塌糊涂,大家都在搞各种各样的 GAN,直到去年 StyleGAN 这种集大成模型出来,才算是差不多消停。引起各种争议的 Deepfake 是成果之一,最近都有看到人用它做假资料。
Residual Networks:和 Dropout,Adam 一样变成了基本配置,模型要深全靠它。
Transformers:纯 Attention 模型,直接给 NLP 里的 LSTM 给取代了,而且在其他领域也慢慢取得很好效果,同时也为之后 BERT 预训练模型打下基础。
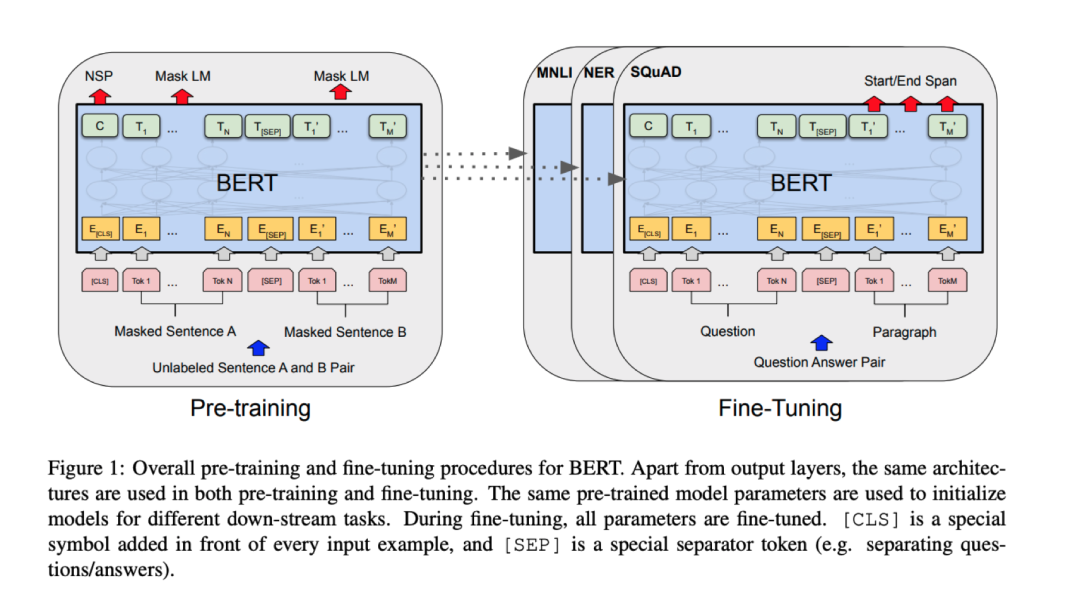
BERT and 精调 NLP 模型:利用可扩展性非常强大的 Transformer,加上大量数据,加上一个简单的自监督训练目标,就能够获得非常强大的预训练模型,横扫各种任务。最近的一个是 GPT3,自从给出 API 后,网络上展现出了各种特别 fancy 的demo,简直了,各种自动补全。


来源:https://developers.google.com/machine-learning/gan/gan_structure
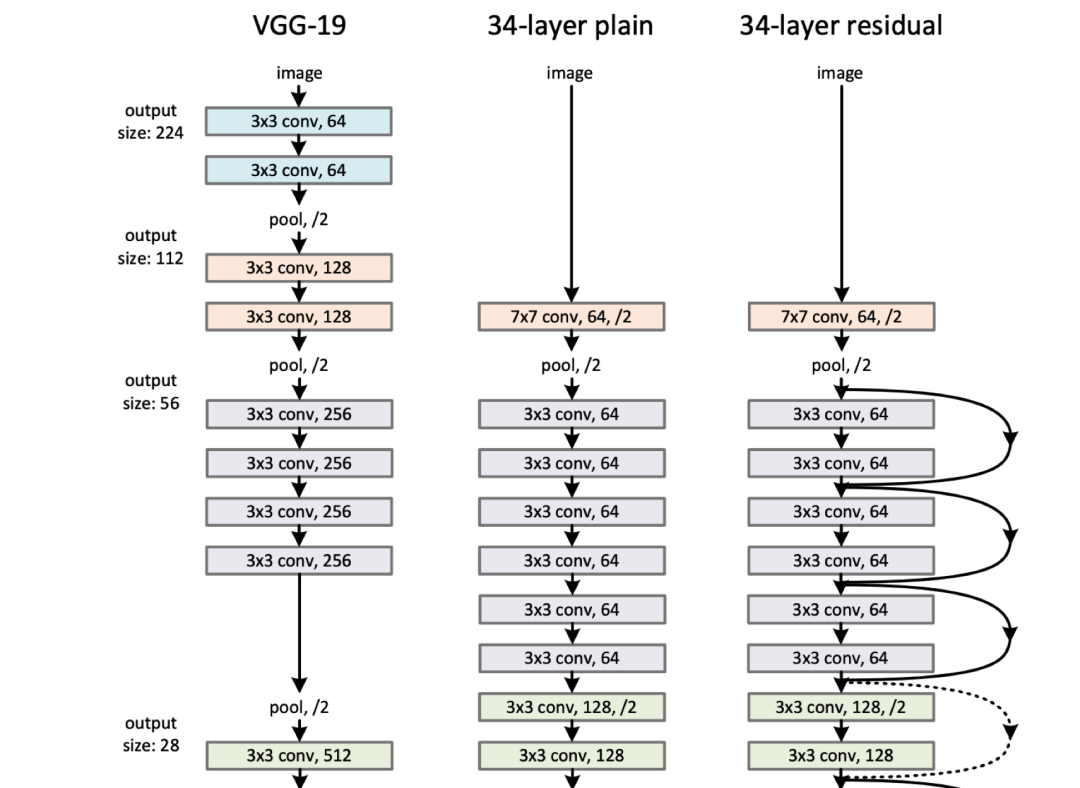
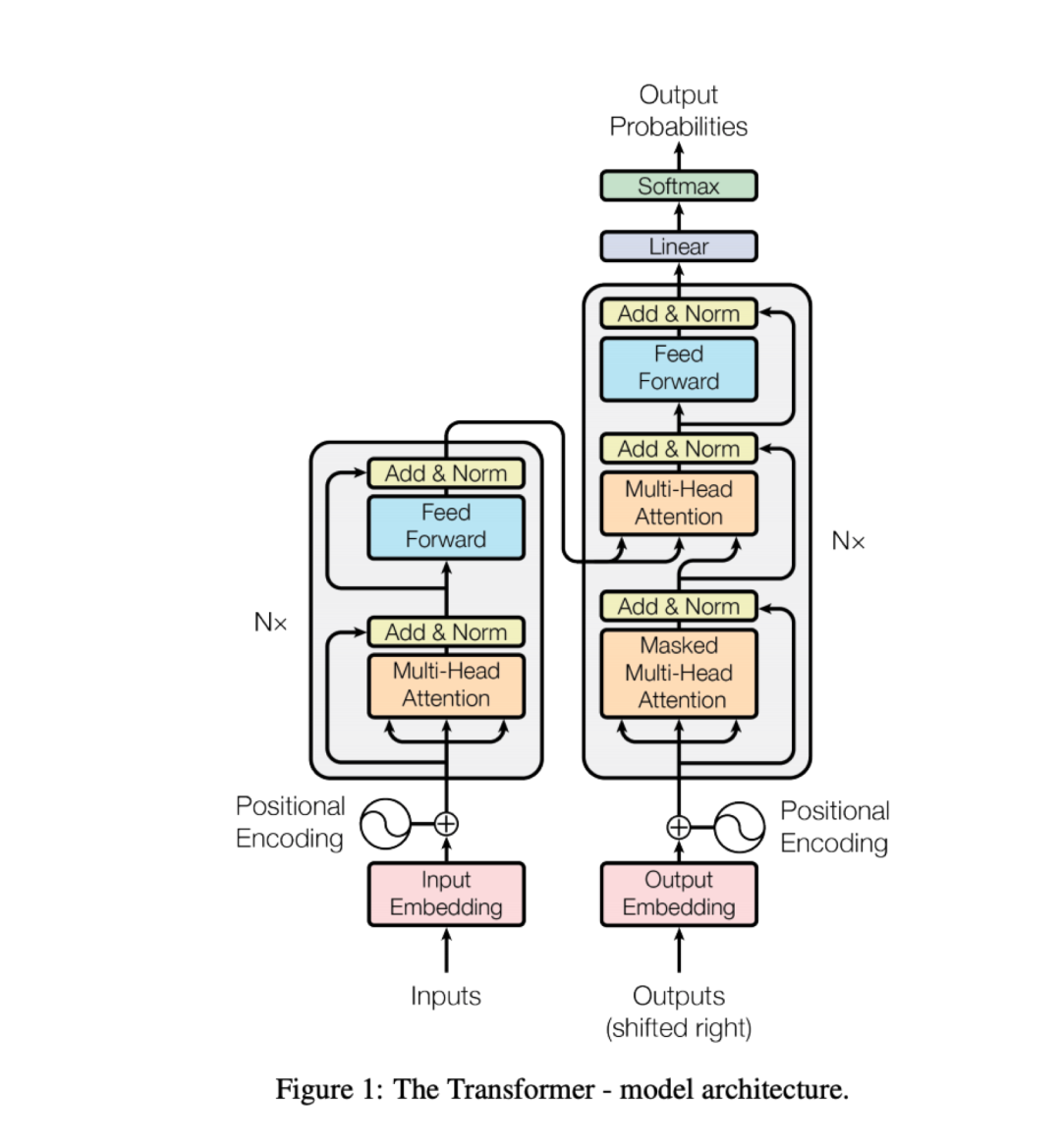
图1:Transformer – 模型架构
来源:https://arxiv.org/abs/1706.03762
本文仅做学术分享,如有侵权,请联系删文。