
深度学习中的那些Trade-off
点击上方“程序员大白”,选择“星标”公众号
重磅干货,第一时间送达


极市导读
在深度学习中我们往往想要追求精度、内存、通信和计算四个指标都满足,但现实总是让人做出取舍,本文介绍了五个业内常见的trade-off做法。
鱼与熊掌不可兼得,深度学习领域中的几个指标也相同。
主要的指标有如下四个:
(1)精度:自然精度是一个模型最根本的衡量指标,如果一个模型精度不高,再快,再绿色环保也无济于事。基本上所有刷榜的工作都是用其他所有指标换精度:比如用更深的网络就是用memory和computation换精度。然而到了实际应用中,尤其是部署侧,工程师越来越多的用一些方法适当的减少精度从而换取更小的内存占用或者运算时间
(2)内存:Out Of Memory Error恐怕是炼丹师最常见的情况了。内存(或者说可以高效访问的存储空间)的尺寸是有限的,如果网络训练需要的内存太大了,可能程序直接就报错了,即使不报错,也需要把内存中的数据做个取舍,一部分存到相对较慢的存储介质中(比如host memory)
(3) 通信:随着网络规模越来越大,分布式训练已经是state-of-the-art的网络模型必不可少的部分(你见过谁用单卡在ImageNet训练ResNet50?),在大规模分布式系统,通信带宽比较低,相比于computation或者memory load/sotre,network communication会慢很多,如果可以降低通信量,那么整个网络的训练时间就会有大幅减少:这样研究员就不会借口调参,实际上把模型往服务器上一扔自己就跑出去浪了。(资本家狂喜)

(4)计算:虽然我们用的是计算机,但实际上恐怕只有很少的时间用于计算(computation)了,因为大多数时间都在等待数据的读取或者网络通信,不过即便如此,对于一些计算密集型的神经网络结构(比如BERT,几乎都是矩阵乘法),制约我们的往往是设备的计算能力(FLOPS),即每秒钟可以处理多少浮点计算。
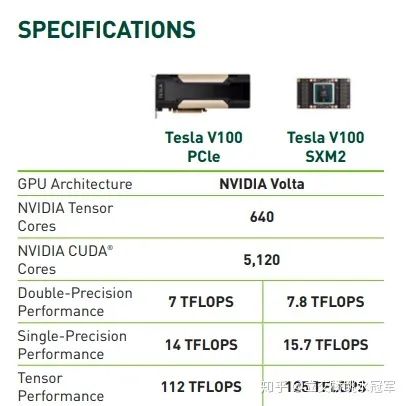
计算能力是重要指标,即使多数情况用不满
无疑同时将以上四点做好是我们追求的,但现实往往很残酷,需要我们做很多取舍。今天就在这儿介绍一些业内常见的trade-off
(1)计算换内存
很多时候内存是最重要的:计算慢了我们多等一等就行了,内存爆了就彻底训练不了了。在神经网络训练中,内存的占用大头往往是activation,即神经网络每层的输出。我们在训练的时候需要把这些输出(activation)记录下来,因为我们反向传播的时候需要用这些activation计算梯度。
一个很直观的想法就是:我们干脆把一堆activation扔掉,到时候需要他们的时候再算一遍。这就是checkpoint机制的想法。虽然这个想法很简单,但是对于一个特定的神经网络,究竟扔掉/保留哪些activation一直没有定论,有兴趣的同学可以看一下我之前写的另一篇文章了解这个专题:
立交桥跳水冠军:DNN显存优化的终点?Checkmate论文总结
https://zhuanlan.zhihu.com/p/299861314
(2)通信换内存
随着BERT,GPT的发展,研究员发现一件更尴尬的事情:内存不够了,但这次不仅仅是装不下activation,甚至光是参数(parame)和参数对应的optimizer都装不下了。那之前说的checkpoint就不管用了(人家只负责省activation)。
这时候有些读者会有想法:那如果我一张卡装不下,就两张卡来呗。恭喜你!你的想法和世界上最顶尖的程序员一样!这种做法可以被称为Model Parallel,即每个分布式节点存储不同的参数,feed一样的数据。目前Model Parallel有两种,粗略来说可以分成intra-layer拆分和inter-layer拆分:
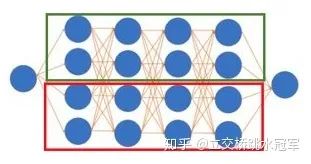
intra-layer拆分,多见于NLP模型
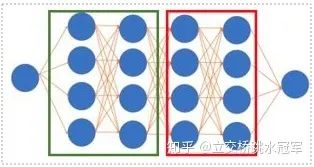
inter-layer拆分,多见于CV模型
上面的例子可能比较抽象,我们来结合下面的两个具体工作说一下这两种model-parallel:
首先是intra-layer的拆分:
我们知道神经网络是一层一层的,每层可能是一个卷积,一个Pool,或者BN什么的。如果我们对一层进行了拆分,那么就是intra-layer的。下面这张图摘自英伟达的Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism(https://arxiv.org/abs/1909.08053),描述了如何把两个很大的矩阵乘法拆开到两个节点上来算

本来矩阵乘法是 和 (忽略激活层什么的)。我们知道矩阵乘法有很好的性质:我们可以把矩阵乘法变成分块矩阵乘法。因此我们可以把上面的矩阵乘法变成
和
因此如果我们让第一个节点计算 ,第二个节点计算 ,最后再累加两个人的结果,不就好了?这样的好处就是第一个节点只需要存储A1和B1,第二个只需要A2和B2,相当于节省了一半的空间(和一个节点存储A和B相比)
inter-layer拆分:和intra-layer不同,我们只做网络层之间的切分。这种切分方式更符合直觉。上面的例子来自PipeDream(https://arxiv.org/abs/1806.03377、PipeDream: Fast and Efficient Pipeline Parallel DNN Training)。假设我们有5层的神经网络,有四个节点可以用,那我们可以让第一个节点算第一层,第二个节点算第二层,第三个节点算第三层,第四个节点算最后两层。这样我们很直接的就把网络拆开了,不管第1-5层的具体操作是卷积,BN还是什么,都可以这么搞

但这么拆有一个问题,就是每台机器之间都存在数据依赖:当你发现第1,2,3节点在悠闲地打王者,第四节点在苦逼的干活,你就上去质问他们你们为啥在划水?他们表示很无辜:我在等第四节点把结果算完,然后把梯度传给我啊

把每个节点工作的时间系统的记录下来,发现所有时刻都只有一个人在干活
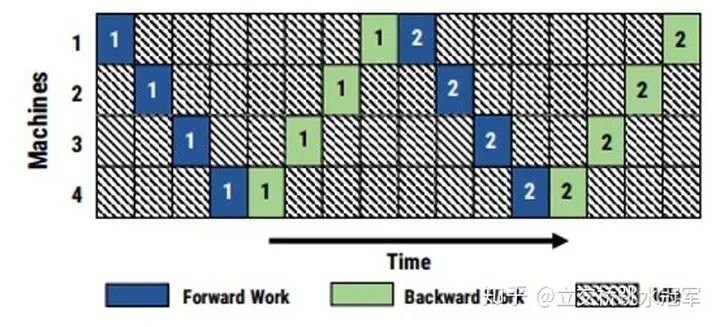
很自然的想法就是,如果每个人都处理不同的batch不就好了?但这样做可能会引发精度的问题。有兴趣的读者可以去看PipeDream的论文。
(3)计算换通信
虽然刚才介绍了模型并行,但目前主流的还是数据并行,即每张卡分到同样的parameter,每次接收不同的input,算完之后每个人把自己的local gradient做一次同步,得到global gradient来更新本地的参数(如下图所示)
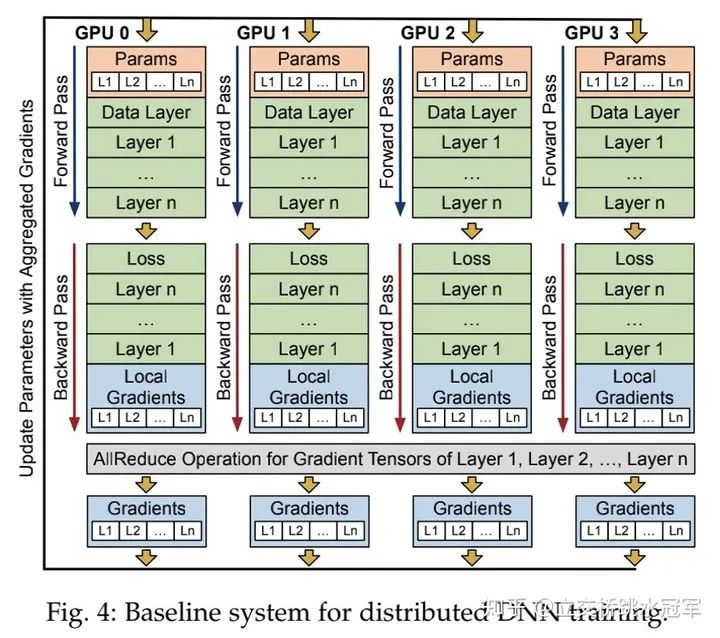
在这种情况下,我们的通信只发生在gradient allReduce的时刻(即图中最下面灰色的框)。虽然它只是训练过程的一部分,但因为随着分布式系统的增大,通信速度和计算、访存时间相比会越来越慢,因此这个allReduce操作逐渐成为了性能瓶颈。
为了打破这个瓶颈,有些研究员尝试压缩梯度:每次我们并不通信梯度本身,而是先把梯度做一个压缩,让他们的size变小,然后把压缩后的数据做一次传输,最后在本地解压缩这些数据,从而完成一次梯度的allReduce。其中做的比较好的就是TernGrad(TernGrad: Ternary Gradients to Reduce Communication in Distributed Deep Learning(https://arxiv.org/abs/1705.07878))。这个算法将原来一个N*float32这么大的梯度tensor压缩成了N*3这么大的tensor,再加一些可以忽略不计的meta-data。即用(-1,0,1)来表示原本float32的数值。
(4)显存换计算
这方面的例子我没想到太多,就想到诸如用3个3*3的卷积代替一个7*7的卷积:感受野不变,计算量减少,但是原本一个activation变成了三个,显存变大了。
(5)精度换计算/内存/通信
这种方法很“流氓”:深度学习模型最重要的就是精度,如果为了计算、内存和通信放弃了精度就很没道理。
不过得益于神经网络的超强鲁棒性,很多看似大胆的做法可以在显著降低计算,内存或通信的情况下只掉一点点精度。
这里简单介绍几种常见的做法:
量化/用低精度计算:显而易见,如果你用Float16代替Float32,那么运行速度,需要的内存,需要的带宽基本上都可以直接砍一半 稀疏通信:精度换通信的一种做法:我们每次对梯度做all reduce的时候并不需要传所有梯度,只需要选择一部分(比如数值比较大)的梯度传输就好了 神经网络的各种剪枝:比如把很小的weight直接删掉,毕竟对最终结果没啥影响
推荐阅读
关于程序员大白
程序员大白是一群哈工大,东北大学,西湖大学和上海交通大学的硕士博士运营维护的号,大家乐于分享高质量文章,喜欢总结知识,欢迎关注[程序员大白],大家一起学习进步!