
Full Stack Deep Learning:解构深度学习项目落地过程的各个方面

极市导读
倘若你想了解深度学习项目的落地过程,这门来自Berkeley的课程 Full Stack Deep Learning 将非常适合你。它介绍了团队组织、框架工具、数据管理、测试上线等多个方面的内容,并提供了大量进阶学习资源。
最近看了这个非常不错的来自Berkeley的课程Full Stack Deep Learning,介绍了实际深度学习项目落地过程中的各个方面,包括项目设定、团队组织、框架工具、数据管理、开发调优实践、测试与生产上线等。
这方面其它的经典包括Google的两篇paper:Hidden Technical Debt in Machine Learning Systems和The ML Test Score,Rules of Machine Learning,Andrew Ng的Machine Learning Yearning,Martin Fowler的CD4ML,以及Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow,Building Machine Learning Powered Applications,Building Machine Learning Pipelines 等优秀书籍。
下面是这个课程的一些简单笔记。
Setting up Machine Learning Projects
Overview
Pieter Abbeel说,深度学习更像是一门艺术,而不是科学。虽然目前深度学习很多方面缺乏坚实的理论支撑,但并不妨碍在各个业务领域深度学习的应用蓬勃发展。所以在探究深度学习理论原理的同时,我们同样可以在工程化的方向探索算法应用如何借鉴软件工程的思想,使得其应用落地有迹可循,逐渐形成一系列的规范和最佳实践。
算法项目很多还是没有脱离研究性质,有数据表明,85%的AI项目会失败。有各种可能原因:
技术可行性:基于数据统计学习构建的模型,在实际使用中有很多限制。 项目范围:对于AI技术有过高的期望,容易导致项目需求设定方面失去控制,最终难以达成。 目标定义:对于是否成功交付的定义不明确,或者定义的目标与实际业务没有很好的挂钩。 从实验室到生产环境:机器学习建模过程偏研究性质,没有为实际业务落地做足够的准备。 组织变革:在技术和产品层面外,对于流程,组织都有一定要求,执行推进难度较大。
Lifecycle
整个机器学习的项目基本流程大家应该都很熟悉,值得注意的是这个流程并不是线性关系,会反复迭代跳转。所以遇到问题时不要把自己的思维局限在当前这个点上,要把目光放到整个项目流程上来寻找机会点。
计划立项:明确需求和目标,项目资源的准备,项目排期等
数据收集:数据系统和流程的梳理,训练数据的收集,数据质量监控
建模与调优:构建baseline模型,尝试使用SoTA模型,debug模型并迭代优化
测试与部署:内部/小范围试点,添加各类测试,监控,部署上线,应用推广
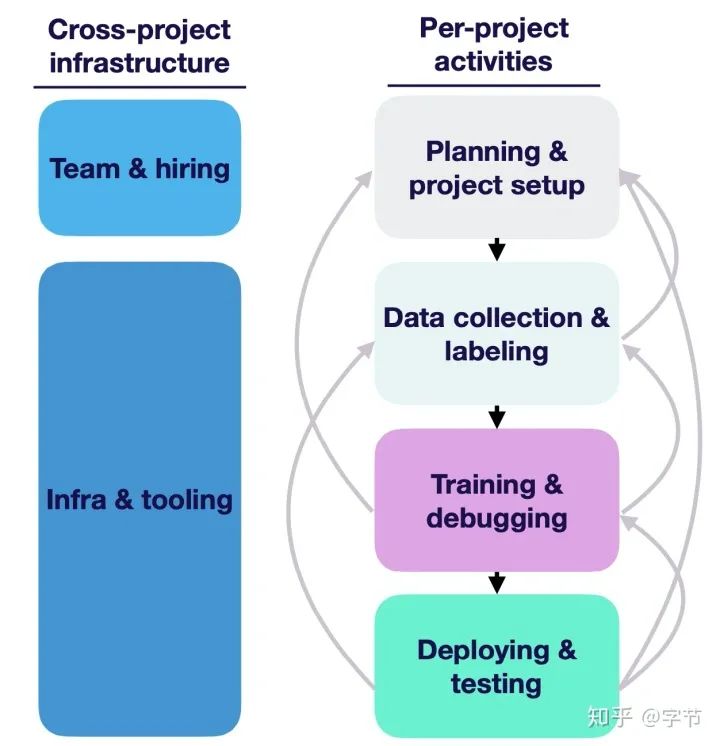
另外还有跨项目的基础架构,包括团队和组织,支持框架和工具(后续会介绍)。
Prioritizing
考虑项目影响力和可行性两个维度。
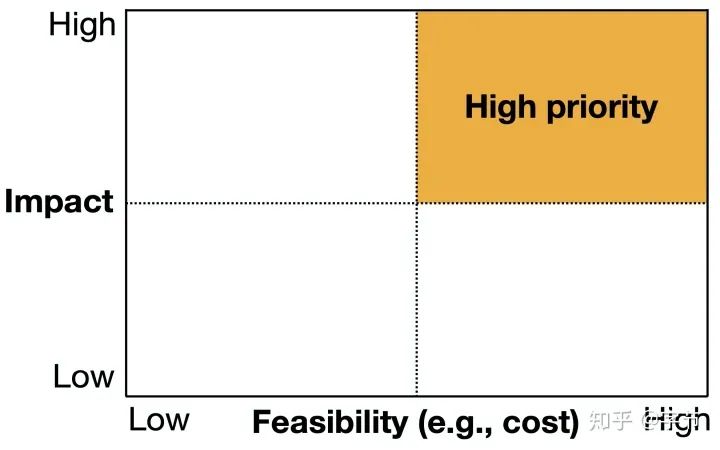
项目影响力方面,参考《AI极简经济学》及Karpathy的一些观点:
可行性:
问题的难度,是否有成熟的技术和方案,对算力需求等。可以从输出复杂度,可靠性需求和泛化需求等方面来评估。 准确率的需求,模型给出错误预测的代价有多高,预测准确率对系统可用性影响有多大。准确率越高,需要投入的调优精力会越大,例如对rare case数据的需求。 数据的可用性,获取数据的难度,数据量的需求,数据标签是否容易获得。一般也是可行性方面最大的障碍。
Archetypes
在公司的各种业务场景中,如何找到适合使用机器学习来提效的机会点并构建原型尝试呢?有如下几种模式可以参考:
现有流程的效果提升,例如从规则推荐,到模型推荐系统
模型是否能提升目前的效果 效果提升是否产生业务价值 是否能形成“数据飞轮” 人工流程的增强智能辅助,例如Email的自动补全功能
智能系统需要达到什么程度才对人有帮助? 需要多少数据量达到这个智能程度? 人工流程的自动化,例如自动驾驶,智能客服
系统可接受的失败率如何? 如何保证系统的失败率不会超过界限? 训练数据是否能容易获得?
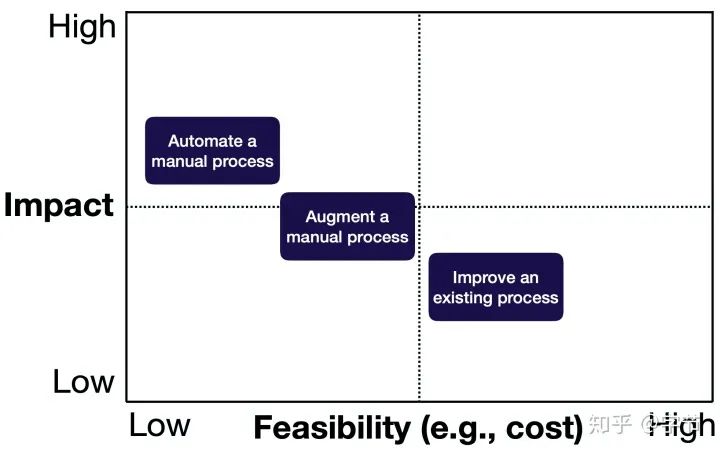
已有流程的提升项目,需要提升impact,比如思考整个流程的优化能否提升数据流的效率,不断在这个任务上提升效果。而带来的更多数据,有机会给下游业务的优化提升构建更好的基础。
人工流程的增强辅助,可以通过更好的产品设计以提升整体的可行性,尽早发布good enough的版本,获取用户反馈。比如友好的交互方式,让用户自己决定是否采纳,对于模型的精度需求会有所降低。
人工流程的自动化需要提升可行性,一方面是引入human-in-the-loop的思想,另一方面,控制项目scope适用范围等。自动驾驶方面有很多这类例子,例如需要人工关注的自动驾驶,或者在特定环境中达到无需人类干预的状态。
Metrics
对于算法来说,有一个唯一的可量化的优化指标是非常重要的。但现实业务场景中的需求往往有多个优化目标,需要一些方法来综合这些指标由模型来进行优化。
简单的指标加权平均。 把对模型输出敏感度不高,或者较容易达到预期的指标,设置为threshold形式。 根据实际业务来设计更复杂的优化指标,例如M5 competition里的复杂多层级指标的加权。
需要不时的评估你的metrics,达成情况,与实际业务的联系程度等,并根据实际情况来做出调整。
Baselines
模型基线的选择很重要,可以帮助评估项目可行性和目标设置。一般有两种构建baseline的方式:
外部基线:业务需求,公开研究的成果等 内部基线:使用规则或简单模型,目前业务中的人工水平
Infrastructure and Tooling
Overview
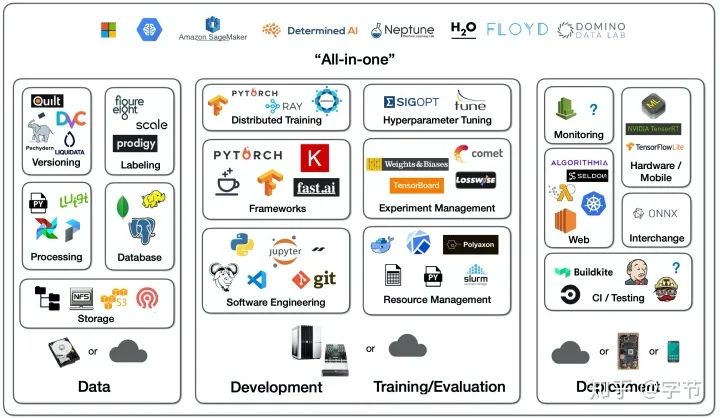
算法应用的理想状态是,提供更多数据,然后系统自动训练提升模型效果。但实际上需要引入的系统组件和工具非常多,需要把各个环节的infra基础打好,后续才有可能实现更高效率的一体化自动化系统。
Software Engineering
语言选择,基本没有异议,Python。
IDE支持,VS Code和PyCharm都不错,个人更喜欢后者。两者都支持远程执行和debug,很实用的功能。
Linters and Type Hints,Python还是挺需要各类代码检查和类型提示的支持的,可以预防很多问题,提升开发效率。
Jupyter Notebook,比较适合探索开发。Netflix把整个数据科学流程构建在notebook之上,做了很复杂的二次开发,作者觉得不值得。我个人一般也是notebook的draft后续会在IDE中重新组织编写。Notebook原生的一些缺点有,难以版本管理,缺乏IDE支持,难以测试,执行顺序混乱,长时间运行任务支持差等。
Streamlit,一个快速构建data app的工具,个人没有用过。
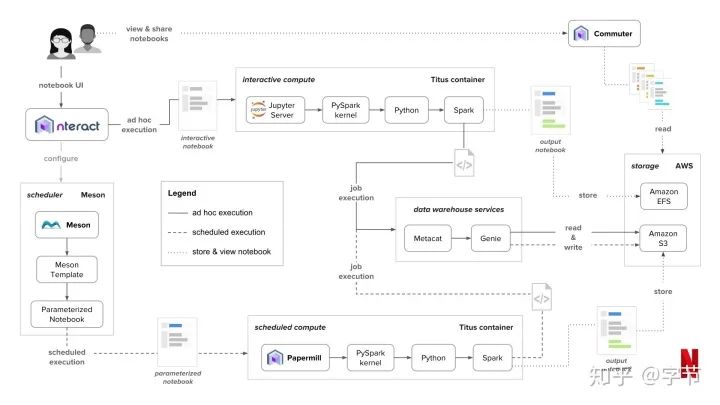
Computing and GPUs
深度学习领域有很多进展都得益于强大的计算能力,当然除了“暴力美学”,如何利用少量资源来达到同样的效果也是非常值得投入研究的。
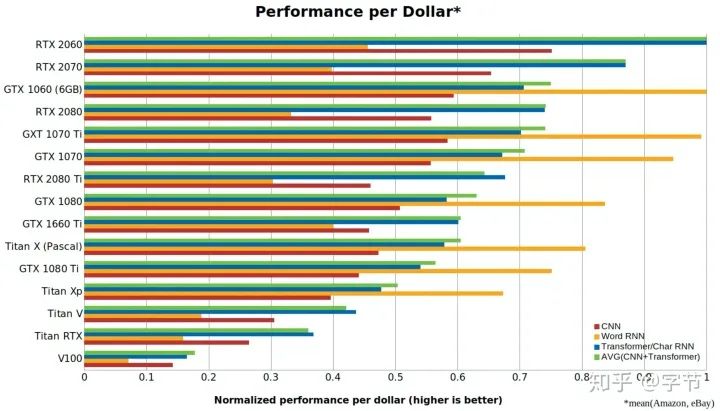
GPU方面基本上也是没有悬念,选NVIDIA。具体购买建议方面,V100是目前server端最强大的选择。Consumer card其实性价比很高,如1080Ti, 2080Ti等。Kepler,Maxwell架构太老了,不建议选购。
云服务方面建议选购AWS或GCP,作者还黑了下Azure……另外Paperspace和Lambda Labs等也可以考虑。如果架构设计上允许,spot instance会便宜很多。
目前最划算的还是自己买GPU机器。从成本分析来看,5-10周的使用量以上,就是自建的成本更低了。云服务的优势主要在可扩展性,运维成本更低等。
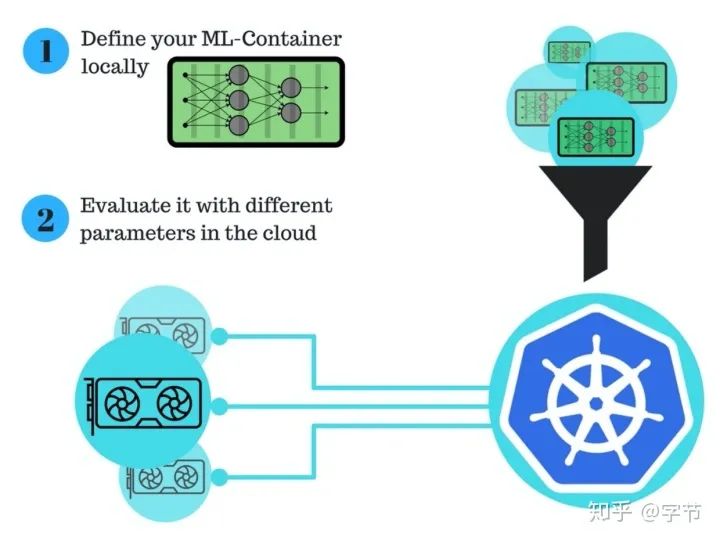
Resource Management
需求:多个用户,使用多台机器,来运行各自的workload。
最简单的解决方案,使用各类电子表格来登记管理。
用软件管理的方式,如SLURM Workload Mananger。
现在比较流行的方案,用Docker + Kubernetes来管理环境和集群资源。以及在此基础上提供更完善功能的Kubeflow,Polyaxon等。
Frameworks and Distributed Training
除非有特殊的理由,否则建议使用TensorFlow或PyTorch。这两者的很多功能特性也在逐渐趋于一致,例如TF 2.0里把eager execution设置为默认模式,使其更易于交互式开发。而PyTorch中也利用TorchScript增加对生产环境部署的支持度。另外fast.ai库也非常值得一试。目前研究领域PyTorch更火,工业界TensorFlow/Keras应用更多一些。
数据并行化是目前实践中更常用的做法。模型并行更加复杂,只有单模型无法在单卡上保存时才会考虑。尽可能利用更多RAM的GPU来避免这种情况。
分布式训练可以考虑的一些库:Ray,Horovod等。
Experiment Management
知乎上Deep Learning效率神器问题下,很多回答都提到实验管理方面的工具。
这里提到的一些工具:Spreadsheet,TensorBoard,Losswise,Comet.ml,Weights and Biases,MLflow。
Hyperparameter Tuning
前面AutoML的文章里有提到很多具体的原理和技术。
这里提到的一些工具:Hyperopt(Hyperas),SigOpt,Ray Tune,Weights and Biases。
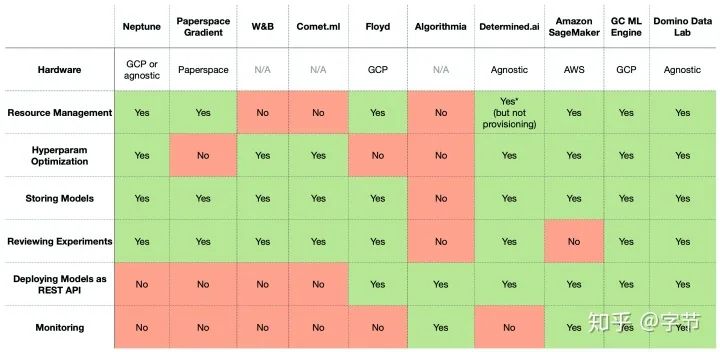
All-in-one Solutions
组合了上面提到的一系列的功能点的全功能软件平台,提供包括模型开发,分布式训练,实验记录,模型版本,模型发布,模型监控等功能的一站式服务。
举例:FBLearner Flow,Michelangelo,TFX,Amazon SageMaker,Neptune,FloydHub,Paperspace,Determined AI,Domino Data Lab(进入了Gartner DSML魔力四象限)。
Data Management
Overview
数据太重要了,为什么叫Data Scientist而不是Model Scientist是有原因的 :)
业界对这方面的重视也在快速提升,因为实际工作中对于数据方面能做的空间和回报都非常大。研究领域受到benchmark等因素影响,往往只能使用相对固定的数据集来做模型方面的工作。
Sources
大多数的深度学习应用都需要大量的训练数据。
可以使用公开数据集作为开始,然后通过产品构建起data flywheel。
半监督学习也是近期热门方向,可以减轻给数据打标的人工开销。
数据增强在CV领域是一个非常普遍应用的技术,其它领域的应用会困难些。对于表格数据,可以随机删除一些cell来形成更多的数据。自然语言处理方面也有一些类似尝试,例如替换近义词,改变词语顺序等。总体思路还是把一些领域知识通过变换,或者噪音的方式进行添加,使得模型更加稳定和通用。
生成数据,CV领域的应用比较多一些,比如可以在仿真场景中训练自动驾驶系统。
Labeling
数据打标方面,需要使用打标工具,制定相应规则来让打标人员来正确高效的进行数据标记。相比使用公司内部人力,crowdsourcing和外包是更常见的方式。其中比较关键的是需要先自己做一些打标工作,了解其中的复杂度,设计好规范和质量检查点。
打标服务公司:FigureEight,Scale.ai
打标软件举例:Hive,Prodigy等。除了用户交互的便利性,还可以使用active learning等技术来提高效率。
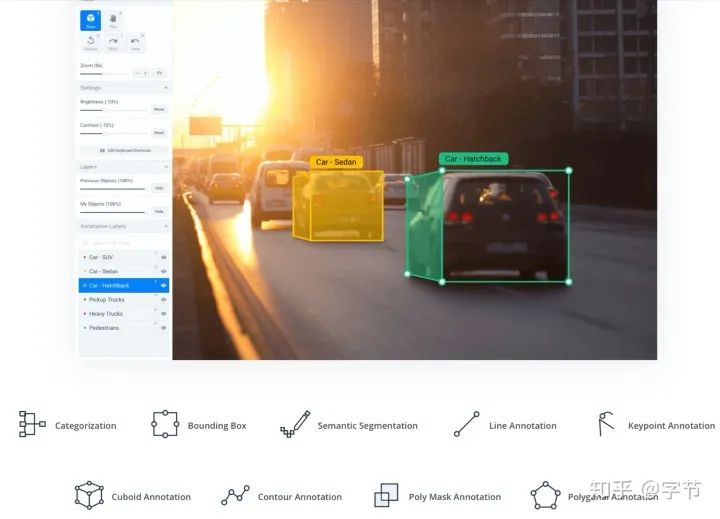
Storage
数据存储的各种形式:文件系统,对象存储,数据库,data lake等。
Binary data一般会以object store形式存储。
系统元数据以数据库形式存储较为常见。
非结构化的数据存储在data lake中,到使用时再进行后续处理。
训练时的数据读写一般会在文件系统中进行,提供了较为完整的POSIX API。
对于结构化数据的处理,SQL是最合适的方式。
Feature store在数据存储上一层进行了一些封装,在原始数据基础上做了transformation,后续在使用时可以直接进行调用。Uber,airbnb等实践了这个方案,而netflix反对这个想法,业界看起来还没有较为统一的认知。
Versioning
Level 0: 无版本管理。
Level 1: 用snapshot方式在训练时产生相应的版本。
Level 2: 使用assets和代码混合的方式进行版本管理。大致的做法就是把数据相关的元信息也在代码里进行管理。
Level 3: 使用专门的管理工具来做数据版本管理,例如DVC,Pachyderm,Quill,Dolt等。
另外Delta Lake也是一个值得关注的框架。
Processing
工作流的编排和运行。最简单的做法,使用makefile,但是有很多使用限制。在这方面使用最广泛的框架是Apache Airflow。其它有很多专注在数据科学领域的框架,例如MLflow,metaflow等,为算法实验,问题排查等提供了很多功能支持。
不要过度工程,使用简单的技术手段满足目前的需求,当碰到无法解决的复杂情况时再考虑引入其它工具框架。一旦引入框架,出现问题时不止要排查项目代码,还需要排查工具框架层面的问题 :)
Machine Learning Teams
Overview
管理技术团队有很多挑战,对于机器学习组织,在技术团队困难的基础上还引入了更多的挑战:
机器学习的人才昂贵且稀缺 机器学习团队的角色更加多样化 机器学习项目往往难以制定明确的时间线,产出也有高度不确定性 机器学习领域变化迅速,且更容易积累技术债 作为新兴方向,领导层往往不理解机器学习的运作方式和特点
Roles
ML产品经理:制定任务优先级,推进项目进展 DevOps工程师:部署和运维线上系统 数据工程师:构建data pipeline,数据存储基础,相关监控等 机器学习工程师:训练和部署模型 机器学习研究员:更面向未来的算法技术调研和前沿探索 数据科学家:一个非常广义的职位,总体来说会更偏向算法,数据分析与业务连接部分
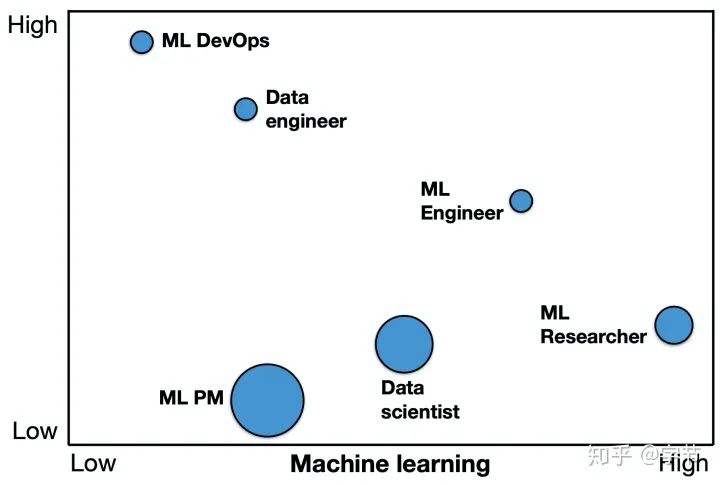
X轴是机器学习技术的需求,Y轴是计算机工程技术的需求,圆圈的大小表示沟通/技术协作能力的需求。
这个session的QA部分也有很多信息量。比如构建机器学习组织的时候,优先从哪种类型的角色开始。各个角色的职业发展等。
Team Structure
Ad-Hoc ML:没有专职的ML工程师,以ad-hoc的方式来做一些基础的机器学习应用,很多中小型公司的做法。主要的问题是ML项目缺乏支持,也比较难招聘和留住相关人才。 ML R&D:在研发部门中融入机器学习相关职能岗位,是更大一些的能源,制造,电信行业公司的做法。主要问题,数据难以获取,机器学习项目也很少实际上线产生价值,因此后续投入也比较少。 Embeded ML:在业务/产品部门中融入机器学习职能,大多数的软件科技类公司,金融服务公司的做法。主要问题是比较难吸引和培养出top级别的人才。另外软件工程的管理和发布节奏与机器学习项目的管理发布节奏容易有冲突。而且长周期的项目难以发展。 Independent ML:有独立的ML部门,直接汇报给CEO/CTO层级,有一些大型的金融服务公司会使用这种做法。这种做法的问题是与业务部门的交流合作会有一些gap,需要业务方认可和积极的合作,学习模型的使用方式,给出快速的反馈等。 ML-First:ML部门会专注于有挑战的,长周期投入的项目,而且在各个业务线也会有ML专家寻求算法快速落地,产生业务价值的机会,一般超大型的科技公司或者专注于机器学习领域的创业公司会采用这种方式。主要挑战是这个形式非常难达到,比如招聘足够的人才,公司文化的转变等。
Design choices:
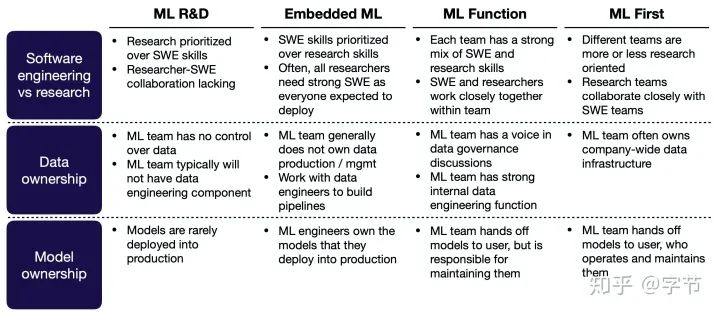
QA里有个彩蛋,想做ML方面的话,读数学博士还是计算机科学博士更好?讲师毫不犹豫的回答:计算机科学。
Managing Projects
机器学习项目的管理太难了。
事先无法评估问题的难度 项目进度往往是非线性的 Research和engineering之间的文化差异 管理层对机器学习的理解有限
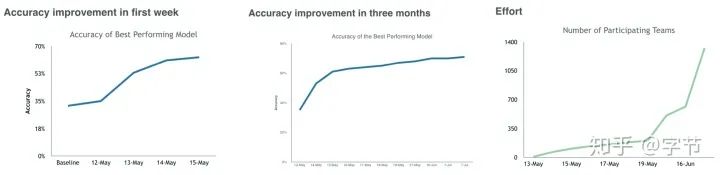
上图是一个kaggle比赛的例子,整个比赛中的效果提升大部分是在第一周达到的。
一些解决方案。使用概率性的方式来管理项目,令人震惊!
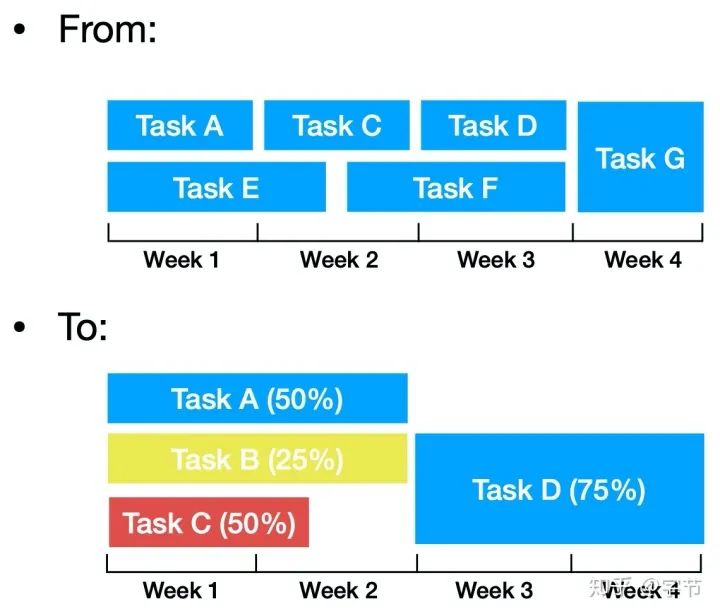
需要在项目过程中尝试多组方案,每组方案预估成功概率,根据进展及时调整。 评估组员产出时,根据他们的输入,例如做了哪些尝试,得出什么结论。而不是直接用最终结果来评估。 先快速构建起end-to-end的pipeline,再不断迭代。Rules of ML中也强调了这点。 对于管理层,需要对他们进行机器学习项目不确定性的教育。
Hiring
作为manager,需要明确招聘目标的画像,必需的技能点等。建议招聘对机器学习有兴趣的软件工程师。
里面还提到了不少招聘,建联渠道,如何吸引ML人才等,例如:
明确公司的愿景和产品的潜在影响力 在工具链和基础设施方面加大投入提升工作便捷度 构建学习型组织氛围 利用高人才密度来吸引更多的人才
另外对于招聘面试流程,以及求职方面的指导,session中也给出了一些建议,可供参考。
Training and Debugging
Overview
模型开发优化的过程中,80-90%的时间会花在debugging和tuning上,只有10-20%的时间在做implementation。
模型结果的复现很有难度,包括确保实现没有bug,超参的选择,数据的构建,模型是否适合对应的数据集等挑战。
总体策略:
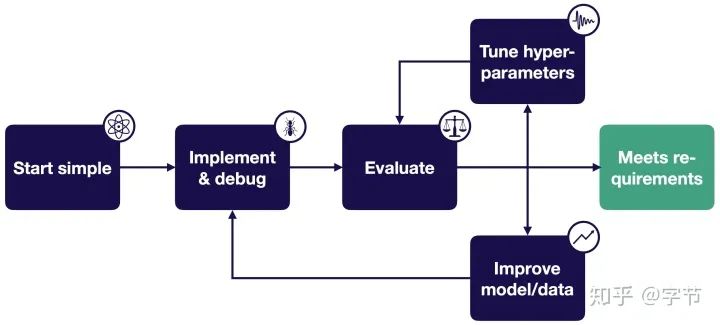
Start Simple
选择从简单的网络结构开始
图像问题:LeNet/ResNet 序列问题:LSTM/temporal convs 其它问题:fully-connected with one hidden layer 选择常见的默认超参
优化器:adam with lr 3e-4 激活函数:ReLU for MLP and conv nets,tanh for LSTM 参数初始化:He init for ReLU,Glorot for tanh 先不添加regularization和normalization 添加input normalization
简化问题
用少量数据/仿真数据来实验 使用固定数量的类别,input size等设置
Debug
5个最常见的bug:
tensor shape错误 输入的预处理不正确 Loss function的输入错误 没有设置正确的train mode 数值处理问题导致出现inf/NaN,例如不正确的exp使用, divide by zero等
实现模型的3个建议:
从一个轻量级的实现开始,一般少于200行代码 使用成熟库中的默认实现,例如Keras中的自带方法 后续再实现复杂的数据pipeline
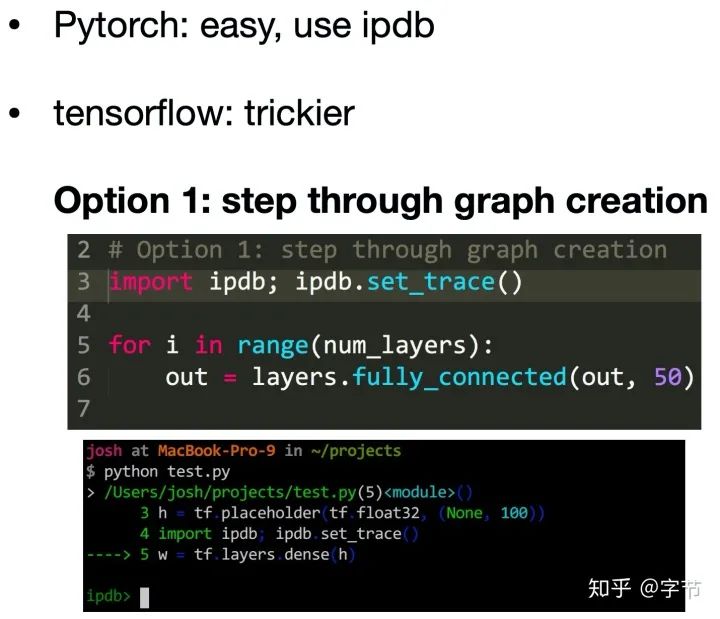
开发中的第一步,让模型跑起来:
Shape mismatch或casting之类的问题,可以用ipdb, tfdb等方法来做断点调试 Out-of-memory问题,可以逐个排除消耗内存较大的操作来定位 其它问题,Google/StackOverflow驱动开发……
第二步,在一个batch上过拟合:
Error不降反升,可能有地方符号用反了 Error爆炸,一般是数值处理问题,也可能是learning rate太大 Error震荡,先降低learning rate,再看看是不是label跟数据没对上,或者错误的augmentation Error保持在一个中间状态不下降,可以尝试提高learning rate,移除regularization。后续还可以检查一下loss function的实现,以及数据pipeline的正确性
第三步,与已知结果比较:
例如与一个官方模型实现进行比较,把相同的数据集用到你实现的模型上 也可以尝试与非官方实现比较,不过很多github上的实现都有bug,要注意 或者直接与论文中提到的准确率比较 最后,可以与简单的baseline比较,包括规则,简单模型等
Slides中有更多细节,感觉总结的挺好。
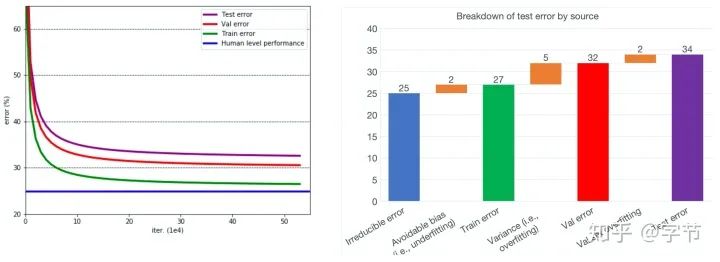
Evaluate
使用经典的bias variance decomposition来对模型进行评估。
Improve
解决under-fitting问题
增加模型复杂度 降低regularization Error analysis 使用更复杂的架构 超参调优 添加特征
解决over-fitting问题
增加训练数据 添加normalization(当前比regularization更流行) 数据增强 增强regularization Error analysis 使用更复杂的架构 超参调优 Early-stopping 特征选择 减少模型参数
解决distribution shift问题
分析test-validation error,进而收集/生成更多训练数据 使用domain adaptation技术
Error analysis的时候,需要对各类错误的优先级进行评估排序,这部分跟《Machine Learning Yearning》里内容类似。
最后,可以考虑rebalance数据集。例如validation集上的表现明显比test集好,可能需要考虑重新选择一下validation/test集。
QA中提到,调优RL算法的时候,random seed也应该视为超参中的一部分 :)
Tune
不同的参数对模型效果的敏感度不同:
低敏感度:optimizer,batch size,non-linearity 中敏感度:参数初始化,模型深度,layer parameters,regularization 高敏感度:learning rate,learning rate schedule,loss function,layer size
参数优化的方法:手动调参,grid search,random search,coarse-to-fine search,贝叶斯优化等。
Testing and Deployment
Project Structure
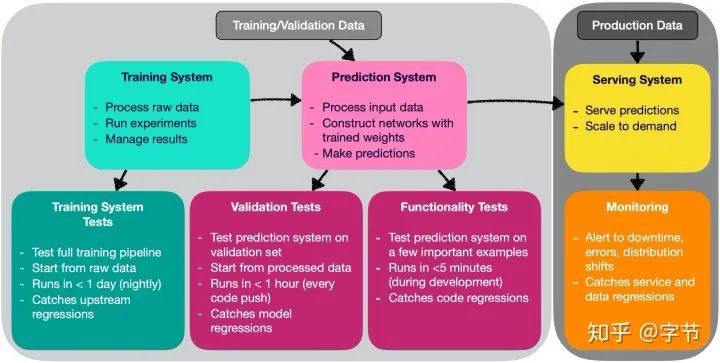
给出了项目结构中不同类型的测试,与传统的测试金字塔里的分类很不一样。
ML Test Score
我的专栏文章中之前也写过这两篇经典的论文,最近几年好像也没有见到新的相关文章出来。
CI/Testing
单元测试,集成测试,持续集成的一些基本概念,与软件工程中基本一致。CD4ML中有更详细的阐述。
一些工具介绍:CircleCI,Travis CI,Jenkins,Buildkite等。
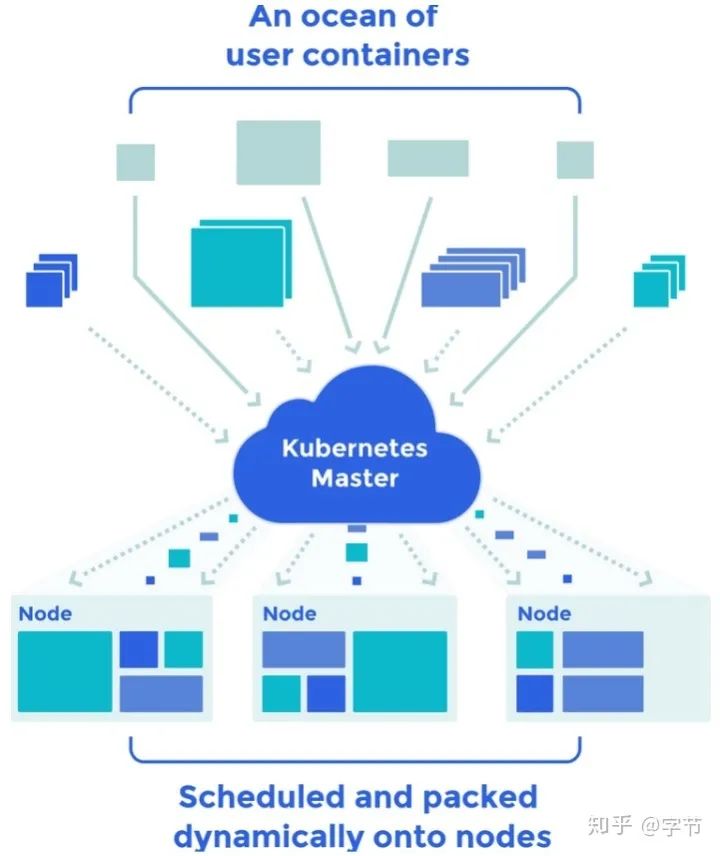
Docker
简单介绍了Docker的使用场景,原理,使用方式等。后面简单提了下容器编排相关的工具,如kubernetes等。
有经验的同学可以直接跳过。
Web Deployment
一般模型预测会以RESTful API的方式对外进行服务。几种部署方式:
在虚拟机上部署,通过添加intance来scale 在container上部署,通过k8s之类的编排软件来scale 通过serverless的方式部署(AWS Lambda,Google Cloud Functions,Azure Functions),自动扩展,自带负载均衡,监控等服务 通过模型服务来部署(TF Serving,Model Server for MXNet,Clipper,Seldon或其它SaaS服务)
如果使用CPU inference,一般会使用Docker部署或者serverless形式。
如果使用GPU inference,TF Serving,Ray Serve之类的模型服务中提供adaptive batching等功能会很有用。
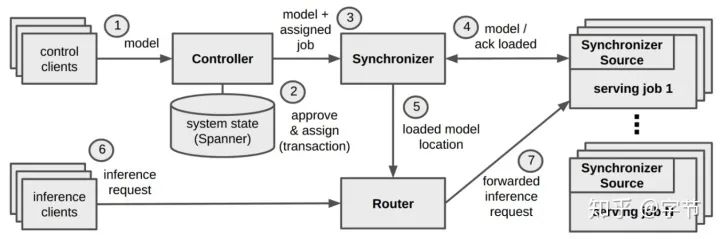
Monitoring
这一节同样参考《The ML Test Score》。
Serving systems, training pipelines, and input data,这几块都需要监控。出问题时发出alarm,并记录下来方便后续调查调优。 所有可以被日志记录的内容,都可以被监控,所以当你设计info/warning/error log时,同时考虑下是否要触发监控告警机制。 数据分布监控方面的现成服务或方案比较少。 除了技术层面的监控,对于业务,终端用户的监控同样非常重要。 Closing the Flywheel,一个需要思考的点。
Hardware/Mobile
在mobile上部署模型会遇到计算资源受限的问题,一般解决方法:减小模型大小(类似MobileNet),quantizing weights,知识蒸馏(例如DistillBERT)等。
一些工具框架介绍:TensorFlow Lite,PyTorch Mobile,CoreML,MLKit,FritzAI等。ONNX可以作为中间层,再部署到各种硬件平台上。对于嵌入式系统,最好的解决方案是NVIDIA for Embeded。
Research Areas
Pieter Abbeel介绍了few-shot learning,RL,imitation learning,domain randomization,NAS,unsupervised learning等几个方面的话题,主要还是集中在他比较擅长的强化学习和机器人应用领域。不过没看出跟课程主题之间的特别关系,可能主要是扩展一下大家的视野,尤其是有些问题通过了解学术领域的解决思路,SoTA水平等,对于解决工业界的问题也有一定借鉴意义。另一方面是建立起两者之间的连接,让工业界的同学也大致了解如何follow学术界的一些研究思路和最新进展,给出了一些参考建议。
Labs
一共有8个lab,感兴趣的同学可以跟着一起深入了解实践一下。
Guest Lectures
Where to go next
提供了非常多的学习资源。学完一个,todo list上 又加了10个有没有。
资源链接:https://course.fullstackdeeplearning.com/course-content/where-to-go-next
推荐阅读
深度学习准「研究僧」预习资料:图灵奖得主Yann LeCun《深度学习(Pytorch)》春季课程 一份来自贾扬清的AI青年修炼指南:不存在算法工程师,调参侠没有市场 追根溯源,算法岗面试「完整脉络」梳理:手推公式、通用问题、常见算法
