
详解目标检测之Neck选择

极市导读
Neck是目标检测框架中承上启下的关键环节。它对Backbone提取到的重要特征,进行再加工及合理利用,有利于下一步head的具体任务学习。本文按照Neck的六种分类顺序对主流Neck进行阶段性总结。>>加入极市CV技术交流群,走在计算机视觉的最前沿
Neck是目标检测框架中承上启下的关键环节。它对Backbone提取到的重要特征,进行再加工及合理利用,有利于下一步head的具体任务学习,如分类、回归、keypoint、instance mask等常见的任务。本文将对主流Neck进行阶段性总结。
总体概要:
根据它们各自的论文创新点,大体上分为六种,这些方法当然可以同时属于多个类别。
上下采样:SSD (https://arxiv.org/abs/1512.02325) (ECCV 2016) STDN(https://openaccess.thecvf.com/content_cvpr_2018/html/Zhou_Scale-Transferrable_Object_Detection_CVPR_2018_paper.html) (CVPR 2018) 路径聚合:DSSD(https://arxiv.org/abs/1701.06659) (Arxiv 2017), FPN(https://openaccess.thecvf.com/content_cvpr_2017/html/Lin_Feature_Pyramid_Networks_CVPR_2017_paper.html) (CVPR 2017), PANet(https://openaccess.thecvf.com/content_cvpr_2018/html/Liu_Path_Aggregation_Network_CVPR_2018_paper.html) (CVPR 2018), Bi-FPN(https://openaccess.thecvf.com/content_CVPR_2020/html/Tan_EfficientDet_Scalable_and_Efficient_Object_Detection_CVPR_2020_paper.html) (CVPR 2020), NETNet(https://openaccess.thecvf.com/content_CVPR_2020/html/Li_NETNet_Neighbor_Erasing_and_Transferring_Network_for_Better_Single_Shot_CVPR_2020_paper.html) (CVPR 2020) NAS搜索:NAS-FPN(https://openaccess.thecvf.com/content_CVPR_2019/html/Ghiasi_NAS-FPN_Learning_Scalable_Feature_Pyramid_Architecture_for_Object_Detection_CVPR_2019_paper.html) (CVPR 2019) 加权聚合:ASFF(https://arxiv.org/abs/1911.09516) (Arxiv 2019), Bi-FPN 非线性聚合:Feature Reconfiguration(https://openaccess.thecvf.com/content_ECCV_2018/html/Tao_Kong_Deep_Feature_Pyramid_ECCV_2018_paper.html) (ECCV2018, TIP 2019) 无限堆叠:i-FPN(https://arxiv.org/abs/2012.13563) (Arxiv 2020)
上下采样
该方法的特点是不具有特征层聚合性的操作,如SSD,直接在多级特征图后接head。
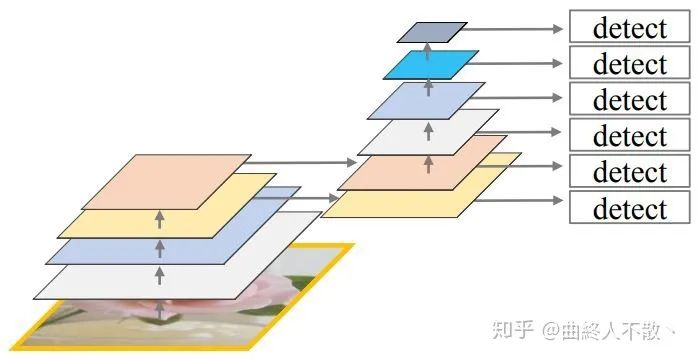
STDN是基于SSD的模型,其思想是构造法。由于STDN使用了DenseNet作为主干,因此后面的特征图在尺寸上是相同的,所以需要构造出各种大小的特征图来检测不同大小的物体。中间尺寸特征图直接使用,大尺寸特征图以尺寸变换层上采样获得,小尺寸特征图以池化获得。
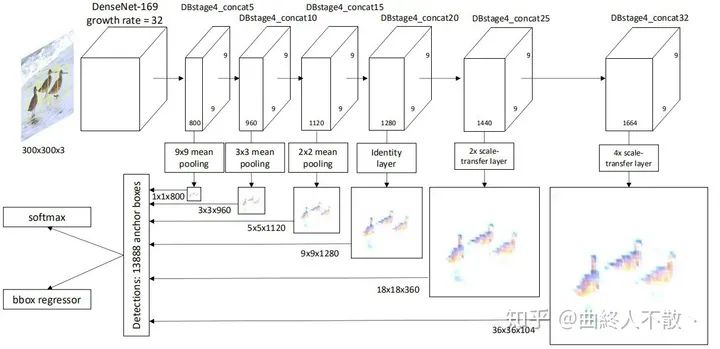
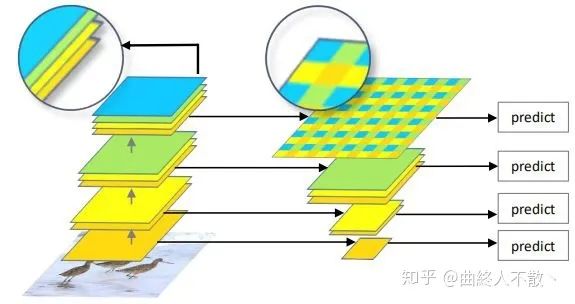
路径聚合
该方法基于一个最基本的观察:深层特征图尺寸小,经过层层卷积下采样使得小物体的信息严重丢失,所以深层不利于小物体检测,就将小物体检测交给浅层来做。这也是为什么SSD需要多级head的原因。
然而光是这样还不够,由于深层特征图具有非常丰富的语义信息,那么最好把深层特征再往浅层传,以增加浅层语义信息。于是乎就诞生了最为人所熟知的FPN。在如何上采样方面,FPN使用最邻近上采样,当然还有使用反卷积的DSSD。
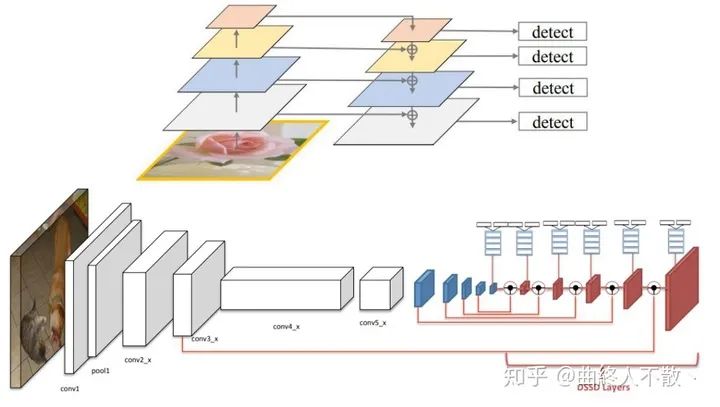
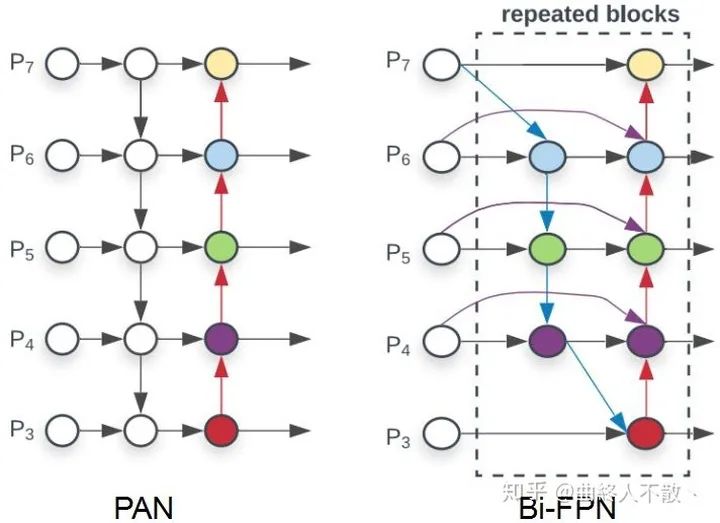
这类方法的共性就是反复利用各种上下采样、拼接、点和或点积,来设计聚合策略。可改进的点还包括加上Deformable Conv、Attention、门控机制、跨FPN level的label assignment等,都已有文章。
比较特殊的还有一种名为NETNet (CVPR 2020)的方法,其认为上述路径聚合方案无论怎么设计,对于预测小物体而言,大物体的特征一直存在,因为高层语义信息被传了下来,再加上其本身浅层自带的大物体特征,这对小物体来说会是一种干扰,如下图所示。

因此需要人为地进行干预,为浅层消除大物体特征。
思路也很简单,随着下采样的进行,小物体特征会丢失,那么深层必然已经都是大物体的特征。此时对深层上采样,得到的还是大物体特征,再把原来的浅层减去经过上采样的深层,于是浅层就不再有了大物体的特征。那么小物体的特征将被突出化。

同样的,被消除的大物体特征也可以进一步被传输到合适的层,以增强大物体的检测。
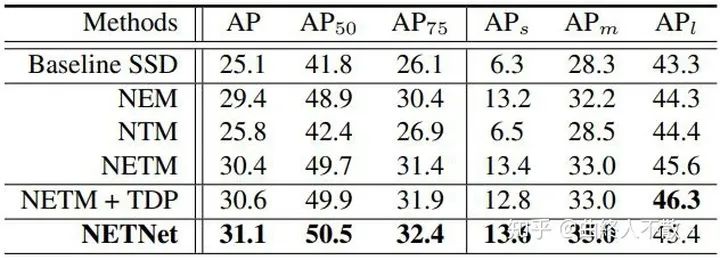
对小物体确实改进比较显著,值得一试。
NAS搜索
即利用神经网络搜索方法来搜索合适的聚合路径,但是搜索的时间成本极高,且数学可解释性低。最新的研究已表明,人工设计的路径聚合在精度上亦可超过NAS搜索出来的结构 (大力出奇迹)。
加权聚合
顾名思义,简单的聚合对所有参与的特征层都是一视同仁的,而实际上,这些来自不同层级的特征图对于单个物体而言,必然只有某一个是最适合检测它的。因此对聚合进行加权就显得尤为重要。
ASFF引入了可参与训练的加权因子来体现不同层级特征图的重要性。
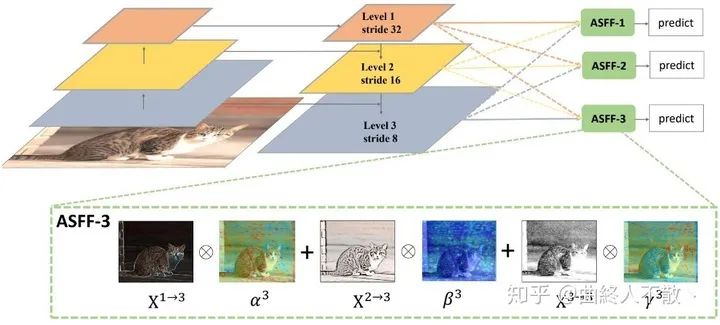
加权公式为 ,其中加权因子 求和为1,即对所参与的特征图先调整到同样尺寸,然后对每个像素点进行加权。
Bi-FPN也有类似的操作,区别在于其简单地使用标量进行加权, ,并且在限制加权因子求和为1方面,使用快速归一化,而非费时的Softmax操作。
非线性聚合
以上这些方法,都可以视为线性聚合操作。首先,让我们用一些简单符号来描述一下聚合过程。
给定特征金字塔的不同层特征图 ,SSD会从某个层开始,选择 层后接head.
接下来以FPN为例,最高层 聚合后仍然是它本身,所以 . 接下来是第二高层 ,它等于原来的 与新的 按照一定的方式进行聚合。最后完整的聚合可以表达为如下的过程:
这里的 以及 都是特定的线性操作,比如不带有激活函数的卷积, 卷积,双线性插值上采样,最邻近上采样,反卷积等。
因此FPN以及其他的路径聚合法,都可视为是线性聚合。于是在《Deep Feature Pyramid Reconfiguration for Object Detection》一文中,作者建立了一种非线性聚合法。
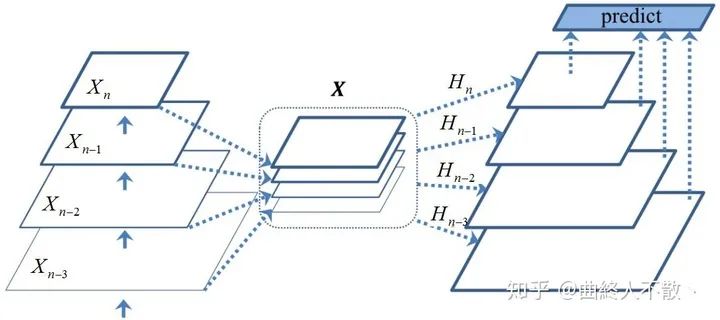
先把所有的层级特征图放在一起,然后学习多个非线性映射 .
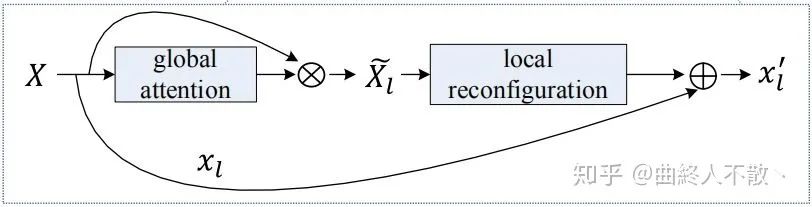
非线性映射的学习模仿SENet的方法,带有注意力的味道。
无限堆叠
EfficientDet通过重复堆叠多个Bi-FPN block来获得性能的提升。
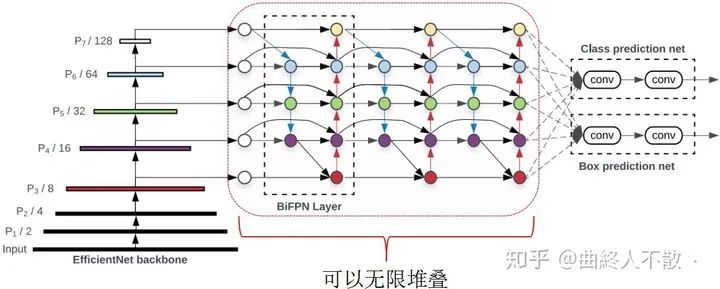
显然这样的操作会造成大量的计算开销与显存占用。
那么有没有更好的方法呢?当然有,比如权重共享,即只使用一个FPN block,backbone提取到的特征图会反复经过这个block,由于权重共享,显存占用很少,参数量也少,但是计算量仍然随着重复的次数而增加,因为每迭代一次,对该block的更新最终都需要增加一次反向传播。
但是上述过程有一个有趣的现象,就是当重复计算的次数趋于无穷多次时,这个FPN block的参数会收敛到一个固定点,即特征平衡态。那么如何利用有限次前向传播即可求解这样的网络参数固定点呢?就是《Deep Equilibrium Models》(曲終人不散丶)(NeurIPS 2019) 的厉害之处了。只要我们求得了该固定点,我们就直接得到了单个block重复前后向传播无数次的结果。
下面把最精华的部分提取出来描述:
给定一个FPN block的网络 , 是它的网络参数点,backbone提取到的多级特征 , 以及一系列初始化的特征金字塔 ,上标为0表示还没开始迭代。
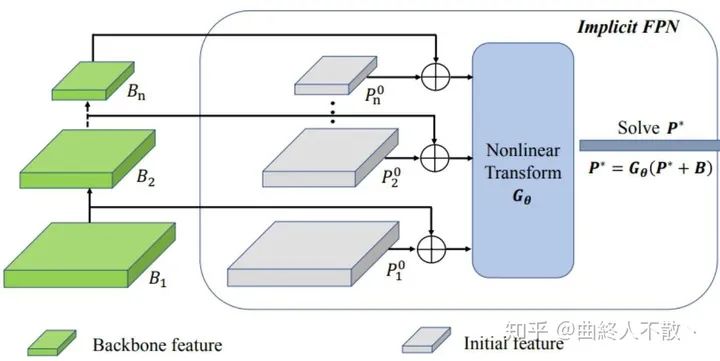
这个 的选择有多种,如FPN,PANet,Bi-FPN,Dense-FPN等,最终输出的也是多级特征金字塔,每一级后面接head. 由于权重共享,上述过程重复多次,那么第 次的输出就是
于是当重复无穷多次时,多级特征图收敛到固定值
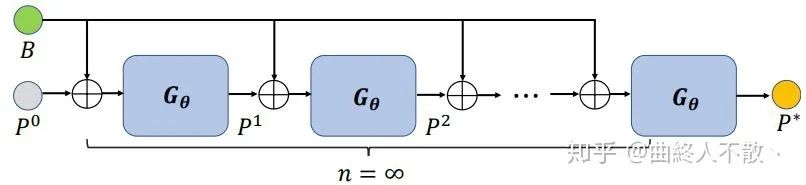
假如你选择迭代10次,就会得到10次多级特征图,依据链式求导法则,你就得更新10次这个block的网络参数 ,这是极为耗时的,且增加了内存开销,因为你需要存储中间的每一次输出。
现在事后诸葛亮一波,假如我已经迭代了1000次,可以认为此时的多级特征图已经是收敛到固定点了,误差很小。DEQ提出反向传播一次就够,即直接使用有关于这个固定点的雅克比的逆来反向传播。即利用它可以直接对一个还没开始迭代的block进行更新。
现在改写一下,把优化 改为优化 ,显然这个固定点就是这个方程的根,即 .
那么如何求这个固定点 ?你可以采用拟牛顿法,或者任何其他的求根法,通过多次迭代,得到满足给定误差以内的近似的 .
然后再使用 来反向传播,一次解决所有梯度回传。
i-FPN的思想就源于此,《Implicit Feature Pyramid Network for Object Detection》一文将其应用至目标检测的Neck中。作者以Dense-FPN为基础。
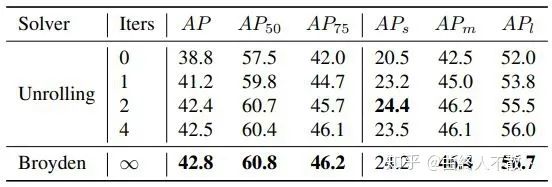
可以看到i-FPN相比较于迭代4次权重共享的block的方法来说,可以获得更好的性能。
就总结到这,如有错误,欢迎指正。
推荐阅读
