
目标检测算法YOLO-V2详解
❝上期我们一起学习了
❞YOLO-V1算法的框架原来和损失函数等知识,如下:
目标检测算法YOLO-V1算法详解
目标检测模型YOLO-V1损失函数详解
【文末领福利】
今天,我们一起学习下YOLO-V2跟YOLO-V1比起来都做了哪些改进?从速度优化和精确度优化的角度来看,主要有以下内容:
Darknet-19结构YOLO-v2结构高精度分类器 Anchor卷积维度聚类 直接位置预测 细粒度特征 多尺度训练 YOLO-v2性能
针对YOLO-V1准确率不高,容易漏检,对长宽比不常见物体效果差等问题,结合SSD的特点,提出了YOLO-V2算法。改算法从速度和精度上做了一些改进措施,我们一起看下都有哪些优化?微信公众号[智能算法]回复关键字“1002”,即可下载YOLOV2论文。
YOLO-V2速度优化
大多数检测网络依赖于VGG-16作为特征提取网络,VGG-16是一个强大而准确的分类网络,但是过于复杂。比如一张224x224的图片进行一次前向传播,其卷积层就需要多达306.9亿次浮点数运算。YOLO-V1使用使用的是基于GoogLeNet的自定制的网络,比VGG-16更快,一次前向传播需要85.2亿次运算,不过它的精度要略低于VGG-16。
在YOLO-V2中,使用的是Darknet-19的网络,该网络一次前向传播仅需要55.8亿次运算,我们先来看下Darknet-19模型的网络框架:
Darknet-19结构
Darknet-19顾名思义,有19个卷积层,如下图:
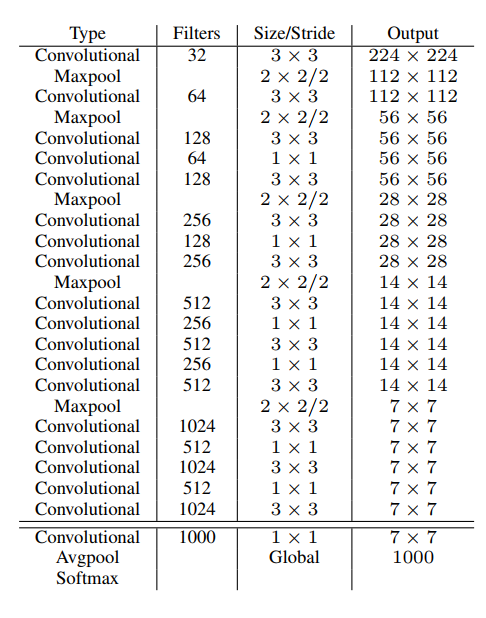
网络很简单,大致连接如下:
首先输入图像大小为 224x224x3,经过3x3x32的卷积层以及池化后得到112x112x32的特征图;接着经过 3x3x64的卷积层以及池化后得到56x56x64的特征图;接着依次经过 3x3x128,1x1x64,3x3x128的卷积层以及池化后得到28x28x128的特征图;接着依次 3x3x256,1x1x128,3x3x256的卷积层和最大化池化后得到14x14x256的特征图;接着依次经过 3x3x512,1x1x256,3x3x512,1x1x256,3x3x512和最大化池化后得到7x7x512的特征图;接着再一次通过 3x3x1024,1x1x512,3x3x1024,1x1x512,3x3x1024的卷积层后得到7x7x1024的特征图;最后经过一个 1x1x1000的卷积层,均值池化层得到1000个结果再经过softmax输出。
YOLO-v2结构
既然YOLO-V2的主框架是基于Darknet-19搭建的,我们来看下YOLO-V2的结构,如下图:
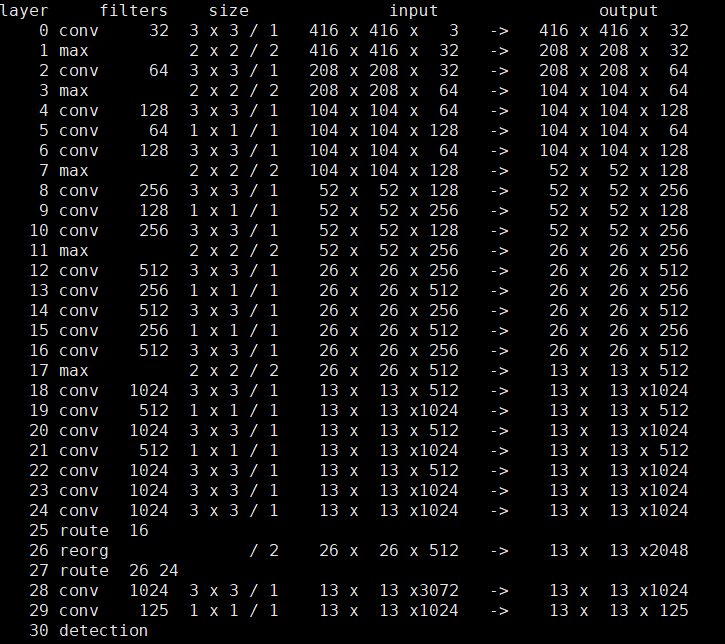
其中上图中的输入大小为416x416x3,其他的0-24层跟上面学的Darknet-19是一样的。我们来从第25层看一下后面的那几层啥意思:
第 25层的route 16的意思是将第16层中的数据取过来做第26层的处理。第 26层对第16层的数据做了一个reorganization的处理,将26x26x512的数据转化为13x13x2048的特征图;第 27层将第26层和24层的数据拿过来堆放到一起,给第28层处理;第 28层做了一个3x3x1024的卷积,将特征图大小变为13x13x1024;第 29层最终经过一个1x1x125的卷积层,将特征图变为13x13x125,最后得到检测结果。
到这里应该有一些疑问,什么是reorganization处理?以及为什么最后是13x13x125的尺寸?这里简单的说下reorganization处理,reorganization处理就是硬性的对数据进行重组,比如将一个2x2的矩阵重组成1x4,重组前后元素总个数不变,但是尺寸变化。上面的就是对26x26x512的数据进行了重组为13x13x2048大小。那么最后的尺寸为什么是13x13x125,这个下面再讲好理解些。框架上大致优化就这些,我们接着看以下精确度上如何优化。
YOLO-V2精确度优化
为了得到更好的精确度,YOLO-V2主要做从这几方面做了优化:高精度分类器,Anchor卷积,维度聚类,直接位置预测,细粒度特征,多尺度训练。我们一个一个看:
高精度分类器
在YOLO-V1中,网络训练的分辨率是224x224,检测的时候将分辨率提升到448x448。而YOLO-V2直接修改了预训练分类网络的分辨率为448x448,在ImageNet数据集上训练10个周期(10 epochs)。这个过程让网络有足够的时间去适应高分辨率的输入,然后再fine tune检测网络,mAP获得了4%的提升。
Anchor卷积
在YOLO-V1中使用全连接层进行bounding box预测,这会丢失较多的空间信息,导致定位不准。YOLO-V2借鉴了Faster RCNN中anchor的思想,我们知道Faster RCNN中的anchor就是在卷积特征图上进行滑窗采样,每个中心预测9个不同大小和比例的anchor。
总的来说YOLO-V2移除了全连接层(以获得更多的空间信息)使用anchor boxes去预测bounding boxes。并且YOLO-V2中的anchor box可以同时预测类别和坐标。具体做法如下:
跟 YOLO-V1比起来,去掉最后的池化层,确保输出的卷积特征图有更高的分辨率。缩减网络,让图片的输入分辨率为 416x416,目的是让后面产生的卷积特征图宽高都为奇数,这样就可以产生一个center cell。因为大物体通常占据了图像的中间位置,可以只用一个中心的cell来预测这些物体的位置,否则就要用中间的4个cell来进行预测,这个技巧可稍稍提升效率。使用卷积层降采样( factor=32),使得输入卷积网络的416x416的图片最终得到13x13的卷积特征图(416/32=13)。由 anchor box同时预测类别和坐标。因为YOLO-V1是由每个cell来负责预测类别的,每个cell对应的两个bounding box负责预测坐标。YOLO-V2中不再让类别的预测与每个cell绑定一起,而是全部都放到anchor box中去预测。
加入了anchor之后,我们来计算下,假设每个cell预测9个anchor,那么总计会有13x13x9=1521个boxes,而之前的网络仅仅预测了7x7x2=98个boxes。具体每个网格对应的输出维度如下图:
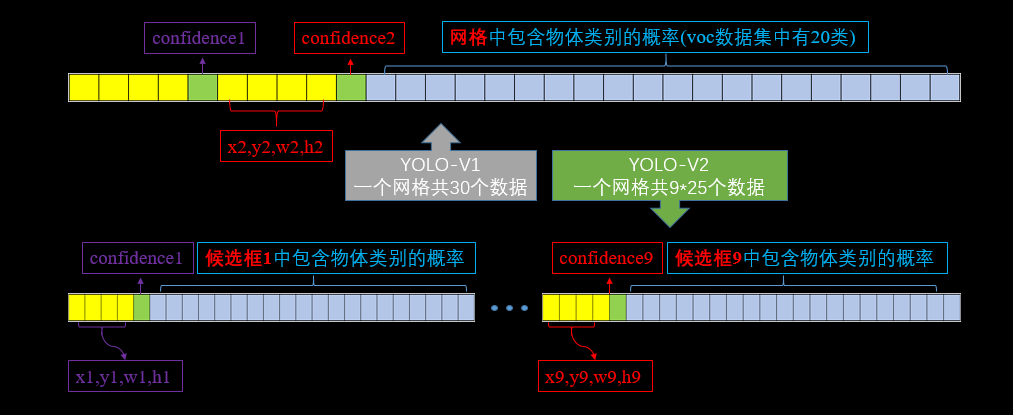
我们知道YOLO-V1输出7x7x30的检测结果,如上图,其中每个网格输出的30个数据包括两个候选框的位置,有无包含物体的置信度,以及网格中包含物体类别的20个概率值。YOLO-V2对此做了些改进,将物体类别的预测任务交给了候选框,而不再是网格担任了,那么假如是9个候选框,那么就会有9x25=225个数据的输出维度,其中25为每个候选框的位置,有无物体的置信度以及20个物体类别的概率值。这样的话,最后网络输出的检测结果就应该是13x13x225,但是上面网络框架中是125,是怎么回事儿呢?我们接着看。
维度聚类
在使用anchor时,Faster RCNN中anchor boxes的个数和宽高维度往往是手动精选的先验框(hand-picked priors),如果能够一开始就选择了更好的,更有代表性的先验boxes维度,那么网络就应该更容易学到精准的预测位置。YOLO-V2中利用K-means聚类方法,通过对数据集中的ground truth box做聚类,找到ground truth box的统计规律。以聚类个数k为anchor boxes个数,以k个聚类中心box的宽高为anchor box的宽高。
关于K-means,我们之前也有讲过如下:
基础聚类算法:K-means算法
但是,如果按照标准的k-means使用欧式距离函数,计算距离的时候,大boxes比小boxes产生更多的error。但是,我们真正想要的是产生好的IoU得分的boxes(与box大小无关),因此采用了如下距离度量方式:
假设有两个框,一个是3x5,一个框是5x5,那么欧式距离计算为:
IoU的计算如下,为了统计宽高聚类,这里默认中心点是重叠的:
这里,为了得到较好的聚类个数,算法里做了组测试,如下图,随着k的增大IoU也在增大,但是复杂度也在增加。

所以平衡复杂度和IoU之后,最终得到k值为5.可以从右边的聚类结果上看到5个聚类中心的宽高与手动精选的boxes是完全不同的,扁长的框较少,瘦高的框较多(黑丝框对应VOC2007数据集,紫色框对应COCO数据集)。 这样就能明白为什么上面网络框架中的输出为什么是13x13x125了,因为通过聚类选用了5个anchor。
直接位置预测
上面学习,我们知道这里用到了类似Faster RCNN中的anchor,但是使用anchor boxes有一个问题,就是会使得模型不稳定,尤其是早期迭代的时候。大部分的不稳定现象出现在预测box的中心坐标时,所以YOLO-V2没有用Faster RCNN的预测方式。
YOLO-V2位置预测,就是预测边界框中心点相对于对应cell左上角位置的相对偏移值,为了将边界框中心点约束在当前cell中,使用了sigmoid函数处理偏移值,这样预测的偏移值就在(0,1)范围内了(每个cell的尺度看作1)。
我们具体来看以下这个预测框是怎么产生的?
在网格特征图(13x13)的每个cell上预测5个anchor,每一个anchor预测5个值:,,,,。如果这个cell距离图像左上角的边距为(,),cell对应的先验框(anchor)的长和宽分别为(,),那么网格预测框为下图蓝框。如下图:

总的来说,虚线框为anchor box就是通过先验聚类方法产生的框,而蓝色的为调整后的预测框。算法通过使用维度聚类和直接位置预测这亮相anchor boxes的改进方法,将mAP提高了5%。接下来,我们继续看下还有哪些优化?
细粒度特征
我们前面学过SSD通过不同Scale的Feature Map来预测Box,实现多尺度,如下:
目标检测算法SSD结构详解
而YOLO-V2则采用了另一种思路:通过添加一个passthrough layer,来获取之前的26x26x512的特征图特征,也就是前面框架图中的第25步。对于26x26x512的特征图,经过重组之后变成了13x13x2048个新的特征图(特征图大小降低4倍,而channels增加4倍),这样就可以与后面的13x13x1024特征图连接在一起形成13x13x3072大小的特征图,然后再在此特征图的基础上卷积做预测。如下图:
YOLO-V2算法使用经过扩展后的特征图,利用了之前层的特征,使得模型的性能获得了1%的提升。
多尺度训练
原始的YOLO网络使用固定的448x448的图片作为输入,加入anchor boxes后输入变成了416x416,由于网络只用到了卷积层和池化层,就可以进行动态调整,检测任意大小的图片。为了让YOLO-V2对不同尺寸图片具有鲁棒性,在训练的时候也考虑到了这一点。
不同于固定网络输入图片尺寸的方法,没经过10批训练(10 batches)就会随机选择新的图片尺寸。网络使用的降采样参数为32,于是使用32的倍数{320,352,...,608},最小尺寸为320x320,最大尺寸为608x608。调整网络到相应维度然后继续训练。这样只需要调整最后一个卷积层的大小即可,如下图:
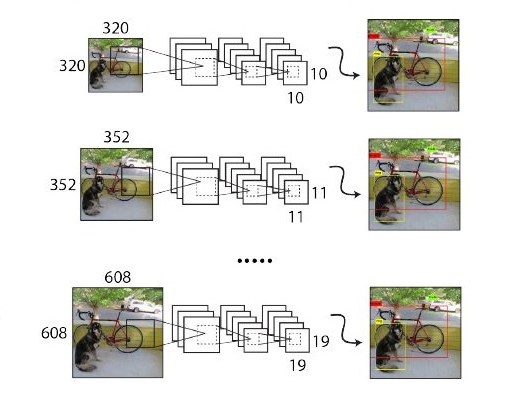
这种机制使得网络可以更好地预测不同尺寸的图片,同一个网格可以进行不同分辨率的检测任务,在小尺寸图片上YOLO-V2运行更快,在速度和精度上达到了平衡。
YOLOV2性能
对于YOLO-V2的性能,直接看下YOLOV2和其他常见的框架在pascal voc2007数据集上测试结果性能比对表,如下表:
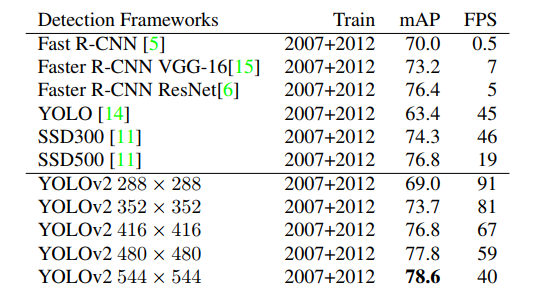
首先可以看到随着训练尺寸的尺寸变大,YOLOv2算法的mAP是逐渐上升的,FPS相应的逐渐下降。在554x554尺寸上的训练mAP达到78.6,从下面的性能分布图图中也可以看到YOLOV2算法的性能相对来说是挺不错的。
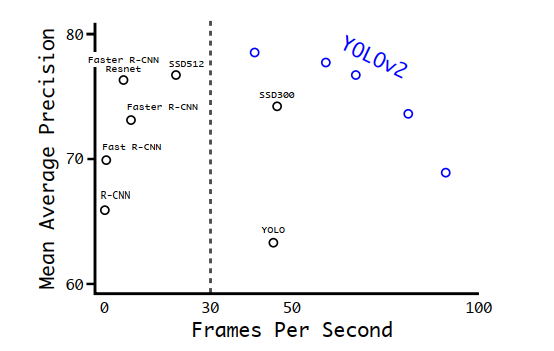
其中YOLOv2的五个蓝色圈圈代表上面表中的五个不同尺寸的结果。
好了,至此,我们从Darknet-19结构,YOLO-v2结构,高精度分类器,Anchor卷积,维度聚类,直接位置预测,细粒度特征,多尺度训练以及性能方面一起学习了YOLO-V2相比与YOLO-V1做了哪些改进。下一期,我们将一起学习YOLO-V3的算法框架。
添加作者微信,备注“2020nn”领取:2020最新版《神经网络与深度学习》中文版及课件。
♥转发在看也是一种支持♥