
目标检测算法YOLOv4详解
一句话总结:速度差不多的精度碾压,精度差不多的速度碾压!
YOLOv4是精度速度最优平衡, 各种调优手段是真香,本文主要从以下几个方面进行阐述:
YOLOv4介绍 YOLOv4框架原理 BackBone训练策略 BackBone推理策略 检测头训练策略 检测头推理策略
1.YOLOv4介绍
YOLOV4其实是一个结合了大量前人研究技术,加以组合并进行适当创新的算法,实现了速度和精度的完美平衡。可以说有许多技巧可以提高卷积神经网络(CNN)的准确性,但是某些技巧仅适合在某些模型上运行,或者仅在某些问题上运行,或者仅在小型数据集上运行;我们来码一码这篇文章里作者都用了哪些调优手段:加权残差连接(WRC),跨阶段部分连接(CSP),跨小批量标准化(CmBN),自对抗训练(SAT),Mish激活,马赛克数据增强,CmBN,DropBlock正则化,CIoU Loss等等。经过一系列的堆料,终于实现了目前最优的实验结果:43.5%的AP(在Tesla V100上,MS COCO数据集的实时速度约为65FPS)。
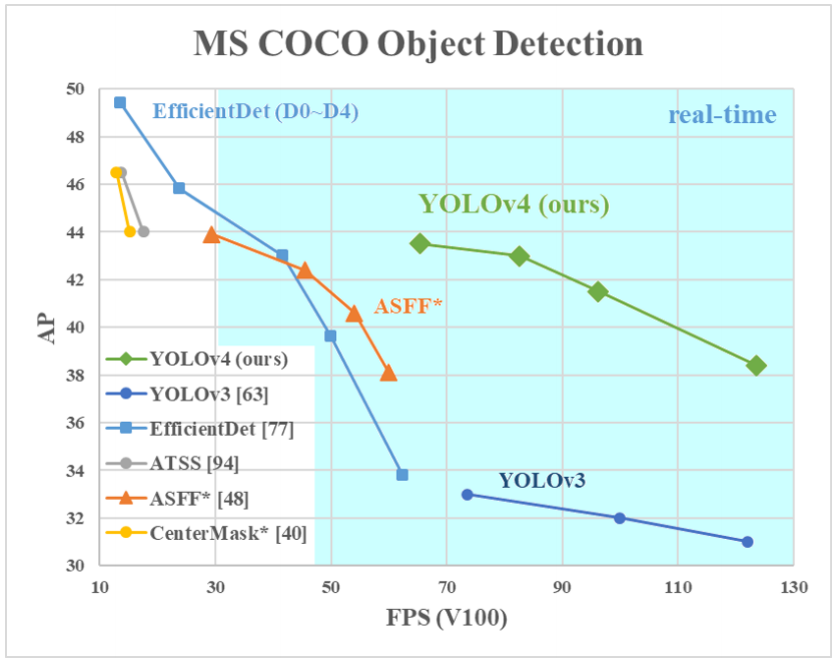
YOLOv4的贡献如下:
开发了一个高效、强大的目标检测模型。它使每个人都可以使用 1080 Ti或2080 TiGPU来训练一个超级快速和准确的目标探测器。验证了在检测器训练过程中,最先进的 Bag-of-Freebies和Bag-of-Specials的目标检测方法的影响。修改了最先进的方法,使其更有效,更适合于单 GPU训练,包括CBN、PAN、SAM等。
总之一句话:速度差不多的精度碾压;精度差不多的速度碾压。
YOLOV4论文: https://arxiv.org/pdf/2004.10934.pdf
YOLOV4代码: https://github.com/AlexeyAB/darknet
2.YOLOv4框架原理
我们主要从通用框架,CSPDarknet53,SPP结构,PAN结构和检测头YOLOv3出发,来一起学习了解下YOLOv4框架原理。
2.1 目标检测器通用框架
目前检测器通常可以分为以下几个部分,不管是two-stage还是one-stage都可以划分为如下结构,只不过各类目标检测算法设计改进侧重在不同位置:
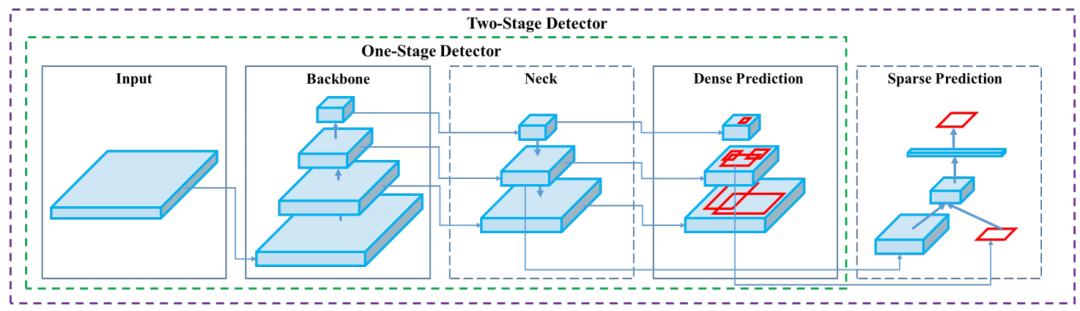
如上图,除了输入,一般one-stage的目标检测算法通常由提取特征的backbone,传输到检测网络的Neck部分和负责检测的Head部分。而two-stage的算法通常还包括空间预测部分。网络中常用的模块为:
Input: 图像,图像金字塔等 Backbone: VGG16,Resnet-50,ResNeXt-101,Darknet53,…… Neck: FPN,PANet,Bi-FPN,…… Head: Dense Prediction:RPN,YOLO,SSD,RetinaNet,FCOS,…… Head: Sparse Prediction:Faster RCNN,Fast RCNN,R-CNN,……
而作为one-stage的YOLO网络主要由三个主要组件组成:
Backbone -在不同图像细粒度上聚合并形成图像特征的卷积神经网络。 Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。 Head:对图像特征进行预测,生成边界框和并预测类别。
这里先直接上YOLOv4的整体原理图(来源网络)如下:
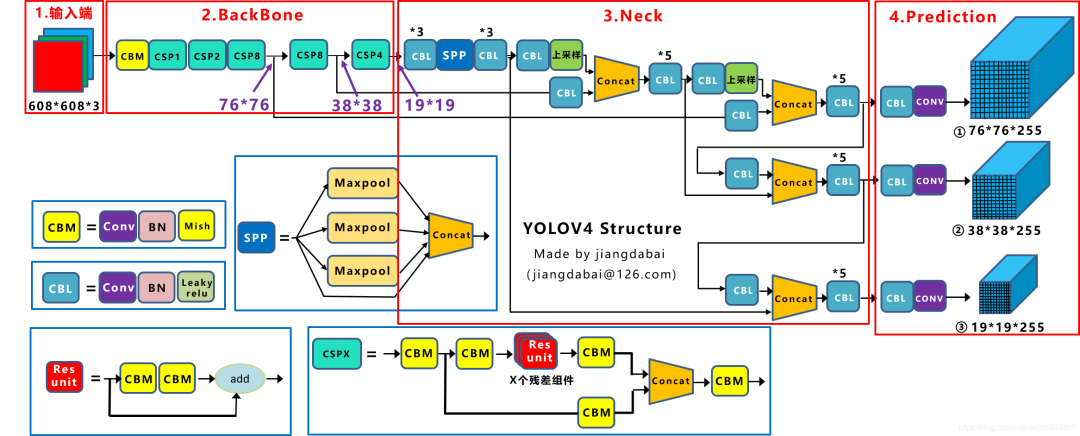
如上图,整体框架跟我们之前学的YOLOv3很是类似。这里先大致看下,接下来我们将逐步分析各个部分,首先,我们先看特征提取网络Backbone.
2.2 CSPDarknet53
我们前面知道在YOLOv3中,特征提取网络使用的是Darknet53,而在YOLOv4中,对Darknet53做了一点改进,借鉴了CSPNet,CSPNet全称是Cross Stage Partial Networks,也就是跨阶段局部网络。CSPNet解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题,将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量和FLOPS数值,既保证了推理速度和准确率,又减小了模型尺寸。如下图:
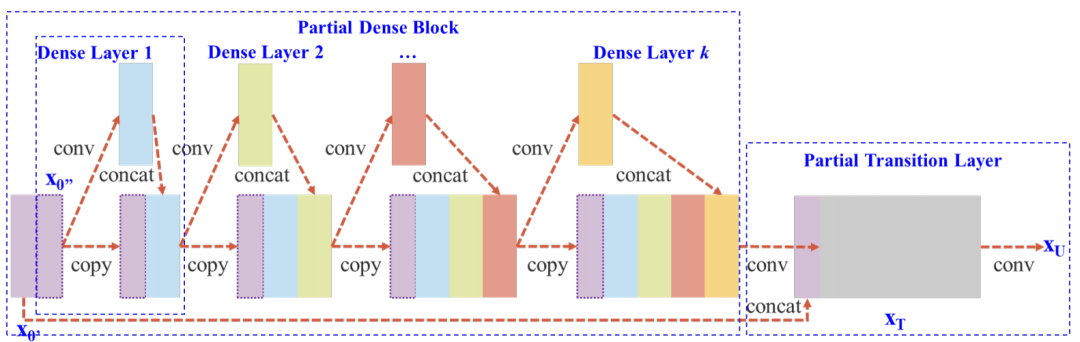
CSPNet实际上是基于Densnet的思想,复制基础层的特征映射图,通过dense block发送副本到下一个阶段,从而将基础层的特征映射图分离出来。这样可以有效缓解梯度消失问题(通过非常深的网络很难去反推丢失信号) ,支持特征传播,鼓励网络重用特征,从而减少网络参数数量。CSPNet思想可以和ResNet、ResNeXt和DenseNet结合,目前主要有CSPResNext50 和CSPDarknet53两种改造Backbone网络。
考虑到几方面的平衡:输入网络分辨率/卷积层数量/参数数量/输出维度。一个模型的分类效果好不见得其检测效果就好,想要检测效果好需要以下几点:
更大的网络输入分辨率——用于检测小目标 更深的网络层——能够覆盖更大面积的感受野 更多的参数——更好的检测同一图像内不同size的目标
这样最终的CSPDarknet53结构就如下图:
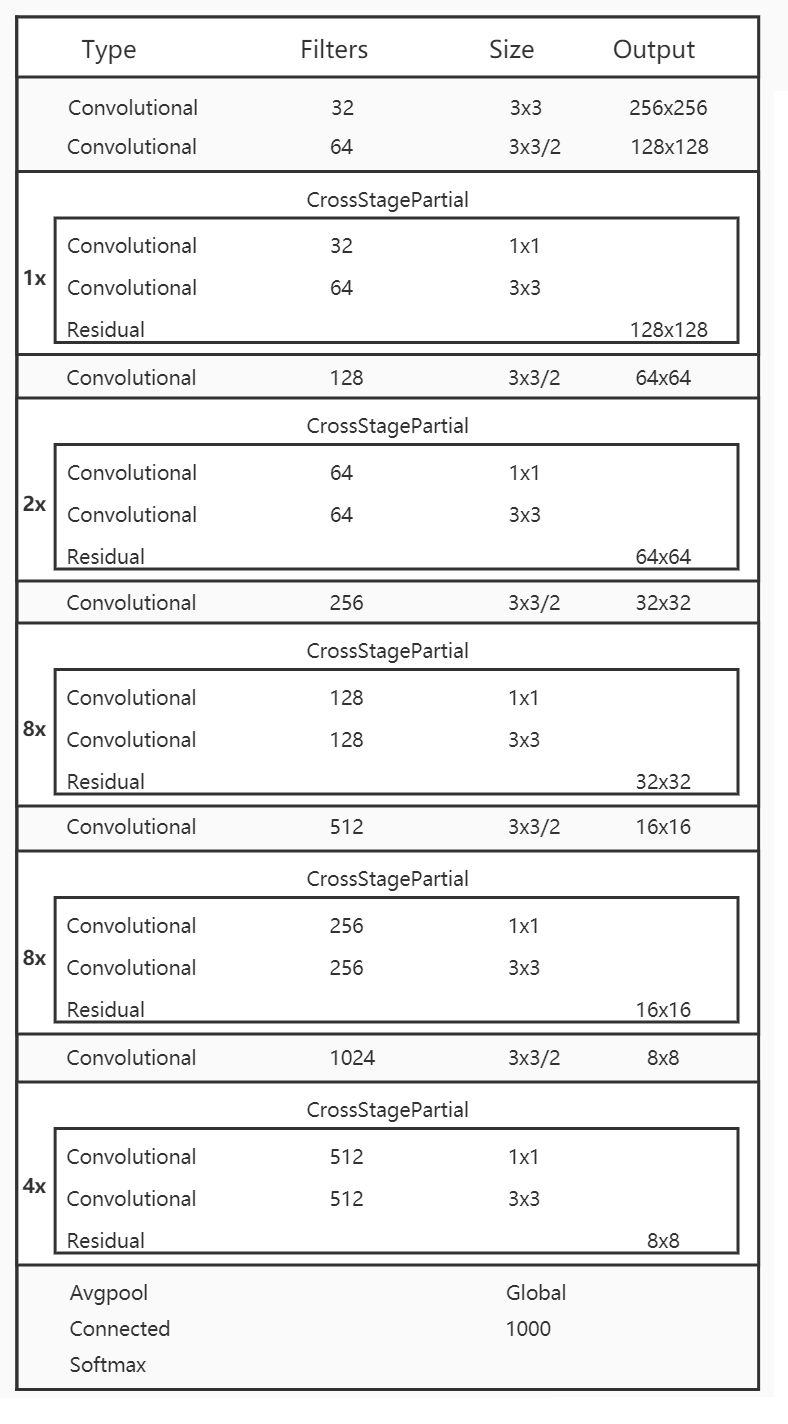
CSPNet论文: https://arxiv.org/pdf/1911.11929v1.pdf
为了增大感受野,作者还使用了SPP-block,使用PANet代替FPN进行参数聚合以适用于不同level的目标检测。
2.3 SPP结构
SPP-Net结构我们之前也有学过,SPP-Net全称Spatial Pyramid Pooling Networks,当时主要是用来解决不同尺寸的特征图如何进入全连接层的,直接看下图,下图中对任意尺寸的特征图直接进行固定尺寸的池化,来得到固定数量的特征。
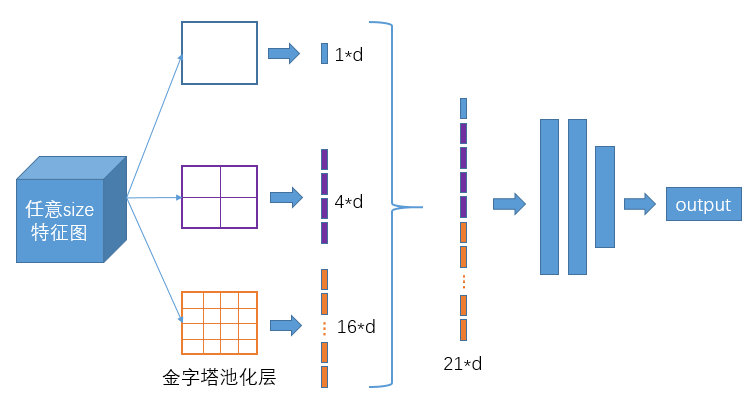
如上图,以3个尺寸的池化为例,对特征图进行一个最大值池化,即一张特征图得取其最大值,得到1*d(d是特征图的维度)个特征;对特征图进行网格划分为2x2的网格,然后对每个网格进行最大值池化,那么得到4*d个特征;同样,对特征图进行网格划分为4x4个网格,对每个网格进行最大值池化,得到16*d个特征。
接着将每个池化得到的特征合起来即得到固定长度的特征个数(特征图的维度是固定的),接着就可以输入到全连接层中进行训练网络了。用到这里是为了增加感受野。
2.4 PAN结构
YOLOv4使用PANet(Path Aggregation Network)代替FPN进行参数聚合以适用于不同level的目标检测, PANet论文中融合的时候使用的方法是Addition,YOLOv4算法将融合的方法由加法改为Concatenation。如下图:
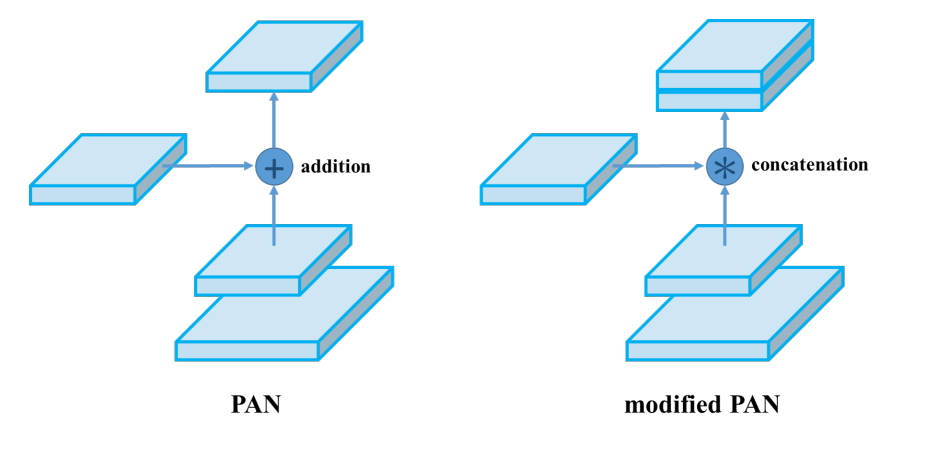
是一种特征图融合方式。
2.5 检测头YOLOv3
对于检测头部分,YOLOv4继续采用YOLOv3算法的检测头,不再赘述。
3.BackBone训练策略
这里我们主要从数据增强,DropBlock正则化,类标签平滑方面来学习下BackBone训练策略。
3.1 数据增强
CutMix
YOLOv4选择用CutMix的增强方式,CutMix的处理方式也比较简单,同样也是对一对图片做操作,简单讲就是随机生成一个裁剪框Box,裁剪掉A图的相应位置,然后用B图片相应位置的ROI放到A图中被裁剪的区域形成新的样本,ground truth标签会根据patch的面积按比例进行调整,比如0.6像狗,0.4像猫,计算损失时同样采用加权求和的方式进行求解。这里借CutMix的地方顺带说下几种类似的增强方式: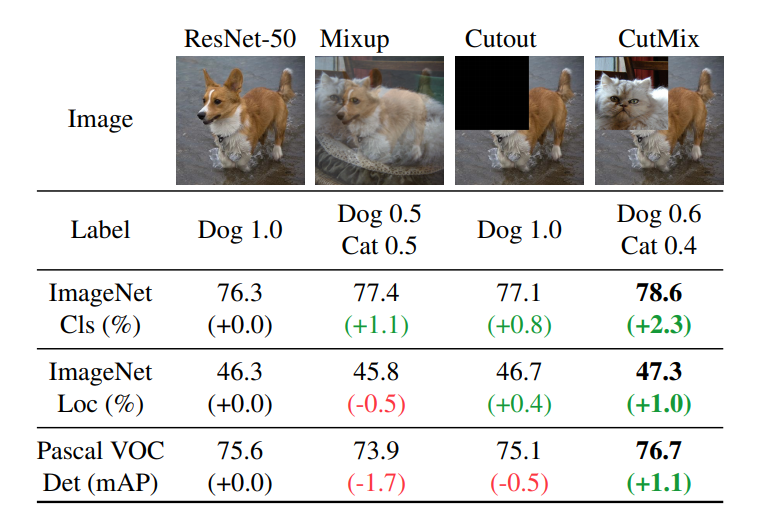 上图是
上图是CutMix论文中作者对几种增强方式做的对比,结果显而易见,CutMix的增强方式在三个数据集上的表现都是最优的。其中Mixup是直接求和两张图,如同附身,鬼影一样,模型很难学到准确的特征图响应分布。Cutout是直接去除图像的一个区域,这迫使模型在进行分类时不能对特定的特征过于自信。然而,图像的一部分充满了无用的信息,这是一种浪费。在CutMix中,将图像的一部分剪切并粘贴到另一个图像上,使得模型更容易区分异类。
CutMix论文: https://arxiv.org/pdf/1905.04899v2.pdf
Mosaic
Yolov4的Mosaic数据增强是参考CutMix数据增强,理论上类似。区别在于Mosaic是一种将4张训练图像合并成一张进行训练的数据增强方法(而不是CutMix中的2张)。这增强了对正常背景(context)之外的对象的检测,丰富检测物体的背景。此外,每个小批包含一个大的变化图像(4倍),因此,减少了估计均值和方差的时需要大mini-batch的要求,降低了训练成本。如下图:
3.2 DropBlock正则化
正则化技术有助于避免数据科学专业人员面临的最常见的问题,即过拟合。对于正则化,已经提出了几种方法,如L1和L2正则化、Dropout、Early Stopping和数据增强。这里YOLOv4用了DropBlock正则化的方法。
DropBlock方法的引入是为了克服Dropout随机丢弃特征的主要缺点,Dropout被证明是全连接网络的有效策略,但在特征空间相关的卷积层中效果不佳。DropBlock技术在称为块的相邻相关区域中丢弃特征。这样既可以实现生成更简单模型的目的,又可以在每次训练迭代中引入学习部分网络权值的概念,对权值矩阵进行补偿,从而减少过拟合。如下图:
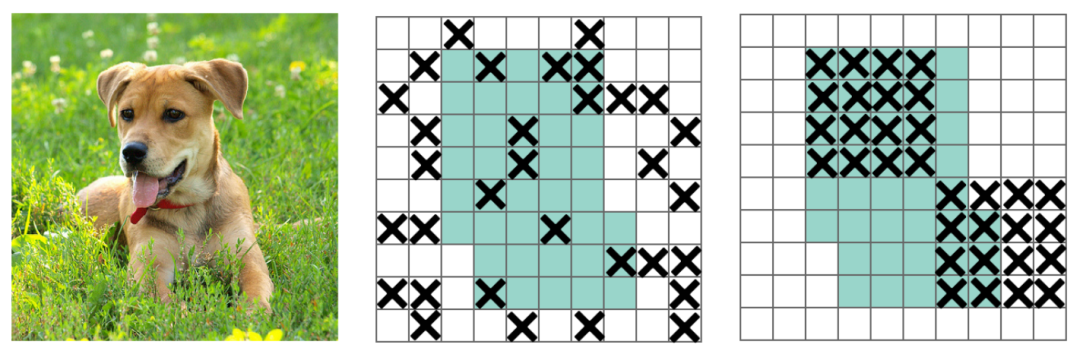
DropBlock论文中作者最终在ImageNet分类任务上,使用Resnet-50结构,将精度提升1.6%个点,在COCO检测任务上,精度提升1.6%个点。
DropBlock论文: https://arxiv.org/pdf/1810.12890.pdf
3.3 类标签平滑
对于分类问题,特别是多分类问题,常常把向量转换成one-hot-vector,而one-hot带来的问题:
对于损失函数,我们需要用预测概率去拟合真实概率,而拟合one-hot的真实概率函数会带来两个问题:
无法保证模型的泛化能力,容易造成过拟合; 全概率和 0概率鼓励所属类别和其他类别之间的差距尽可能加大,而由梯度有界可知,这种情况很难适应。会造成模型过于相信预测的类别。
对预测有100%的信心可能表明模型是在记忆数据,而不是在学习。标签平滑调整预测的目标上限为一个较低的值,比如0.9。它将使用这个值而不是1.0来计算损失。这个概念缓解了过度拟合。说白了,这个平滑就是一定程度缩小label中min和max的差距,label平滑可以减小过拟合。所以,适当调整label,让两端的极值往中间凑凑,可以增加泛化性能。
4.BackBone推理策略
这里主要从Mish激活函数,MiWRC策略方面进行阐述BackBone推理策略。
4.1 Mish激活函数
对激活函数的研究一直没有停止过,ReLU还是统治着深度学习的激活函数,不过,这种情况有可能会被Mish改变。Mish是另一个与ReLU和Swish非常相似的激活函数。正如论文所宣称的那样,Mish可以在不同数据集的许多深度网络中胜过它们。公式如下:
Mish是一个平滑的曲线,平滑的激活函数允许更好的信息深入神经网络,从而得到更好的准确性和泛化;在负值的时候并不是完全截断,允许比较小的负梯度流入。实验中,随着层深的增加,ReLU激活函数精度迅速下降,而Mish激活函数在训练稳定性、平均准确率(1%-2.8%)、峰值准确率(1.2% - 3.6%)等方面都有全面的提高。如下图:
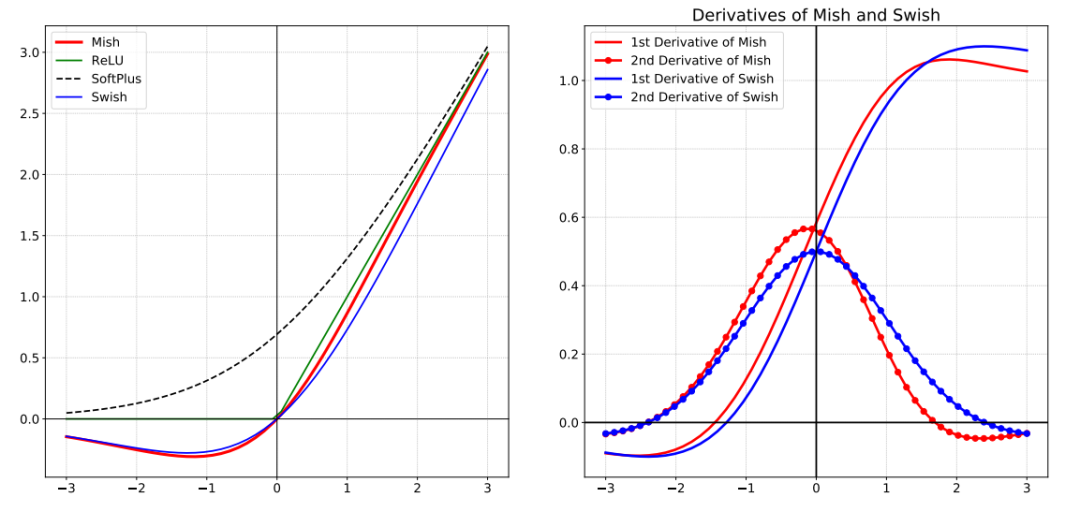
Mish论文: https://arxiv.org/pdf/1908.08681.pdf
4.2 MiWRC策略
MiWRC是Multi-input weighted residual connections的简称, 在BiFPN中,提出了用MiWRC来执行标尺度级重加权,添加不同尺度的特征映射。我们已经讨论了FPN和PAN作为例子。下面的图(d)显示了另一种被称为BiFPN的neck设计,根据BiFPN的论文,该设计具有更好的准确性和效率权衡。
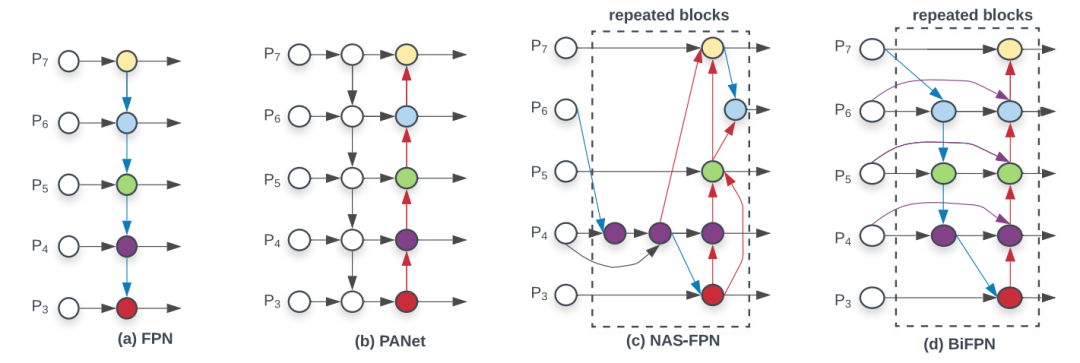
上图中 (a)FPN引入自顶向下的路径,将多尺度特征从3级融合到7级(P3-P7);(b)PANET在FPN之上增加一个额外的自下而上的路径;(c)NAS-FPN使用神经网络搜索找到一个不规则的特征拓扑网络,然后重复应用同一块拓扑结构;(d)是这里的BiFPN,具有更好的准确性和效率权衡。将该neck放到整个整个网络的连接中如下图:
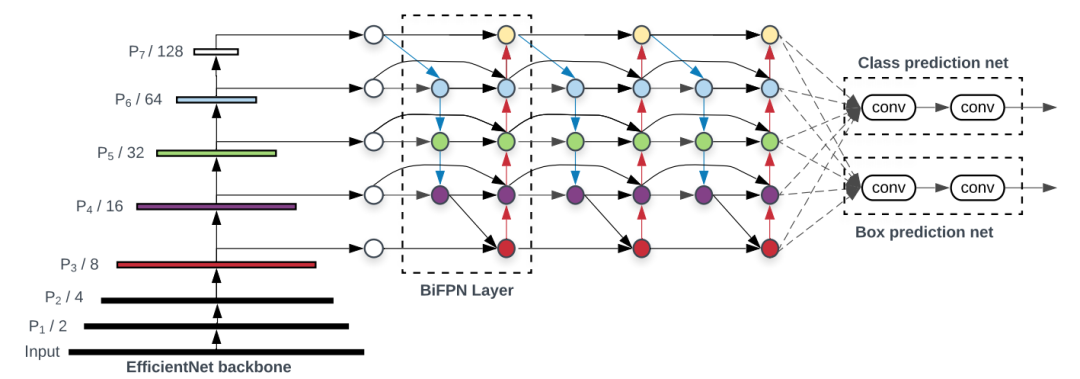
上图采用EfficientNet作为骨干网络,BiFPN作为特征网络,共享class/box预测网络。 基于不同的资源约束,BiFPN层和类/盒网层都被重复多次。
BiFPN论文: https://arxiv.org/pdf/1911.09070.pdf
5.检测头训练策略
前面介绍BackBone训练策略的时候,以及学习过DropBlock正则化,Mosaic数据增强的方法了,这两种方法在检测头训练的过程中也有用到这里不在赘述。我们一起看下检测头训练中采用的其他策略。
5.1 CIoU-loss
损失函数给出了如何调整权重以降低loss。所以在我们做出错误预测的情况下,我们期望它能给我们指明前进的方向。但如果使用IoU,考虑两个预测都不与ground truth重叠,那么IoU损失函数不能告诉哪一个是更好的,或者哪个更接近ground truth。这里顺带看下常用的几种loss的形式,如下:
经典IoU loss:
IoU算法是使用最广泛的算法,大部分的检测算法都是使用的这个算法。
GIoU:Generalized IoU
GIoU考虑到,当检测框和真实框没有出现重叠的时候IoU的loss都是一样的,因此GIoU就加入了C检测框(C检测框是包含了检测框和真实框的最小矩形框),这样就可以解决检测框和真实框没有重叠的问题。但是当检测框和真实框之间出现包含的现象的时候GIoU就和IoU loss是同样的效果了。
其中,C是指能包含predict box和Ground Truth box的最小box。
DIoU:Distance IoU
DIoU考虑到GIoU的缺点,也是增加了C检测框,将真实框和预测框都包含了进来,但是DIoU计算的不是框之间的交并,而是计算的每个检测框之间的欧氏距离,这样就可以解决GIoU包含出现的问题。
其中是指predict box和GT box中心点的距离的平方,而是指刚好能包含predict box和GT box的最小box的对角线长度平方。
CIoU:Complete IoU
CIoU就是在DIoU的基础上增加了检测框尺度的loss,增加了长和宽的loss,这样预测框就会更加的符合真实框。
实际上,CIOU只是在DIOU基础上增加了一项。
其中:
5.2 CmBN策略
BN就是仅仅利用当前迭代时刻信息进行norm,而CBN在计算当前时刻统计量时候会考虑前k个时刻统计量,从而实现扩大batch size操作。同时作者指出CBN操作不会引入比较大的内存开销,训练速度不会影响很多,但是训练时候会慢一些,比GN还慢。
CmBN是CBN的改进版本,其把大batch内部的4个mini batch当做一个整体,对外隔离。CBN在第t时刻,也会考虑前3个时刻的统计量进行汇合,而CmBN操作不会,不再滑动cross,其仅仅在mini batch内部进行汇合操作,保持BN一个batch更新一次可训练参数。
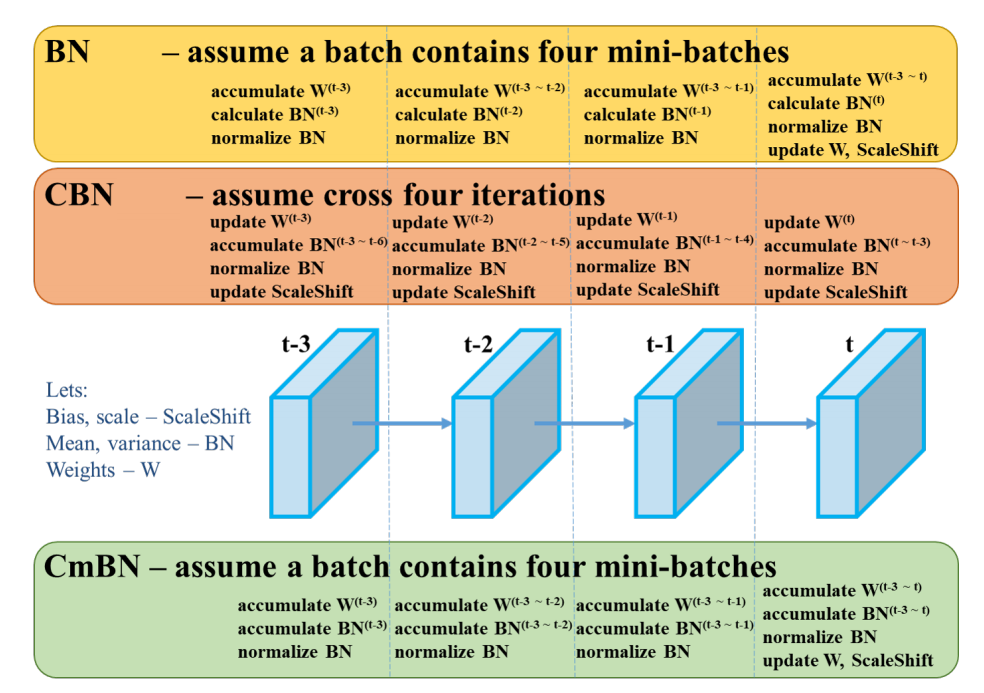
BN:无论每个batch被分割为多少个mini batch,其算法就是在每个mini batch前向传播后统计当前的BN数据(即每个神经元的期望和方差)并进行Nomalization,BN数据与其他mini batch的数据无关。CBN:每次iteration中的BN数据是其之前n次数据和当前数据的和(对非当前batch统计的数据进行了补偿再参与计算),用该累加值对当前的batch进行Nomalization。好处在于每个batch可以设置较小的size。CmBN:只在每个Batch内部使用CBN的方法,个人理解如果每个Batch被分割为一个mini batch,则其效果与BN一致;若分割为多个mini batch,则与CBN类似,只是把mini batch当作batch进行计算,其区别在于权重更新时间点不同,同一个batch内权重参数一样,因此计算不需要进行补偿。
5.3 自对抗训练(SAT)
SAT为一种新型数据增强方式。在第一阶段,神经网络改变原始图像而不是网络权值。通过这种方式,神经网络对其自身进行一种对抗式的攻击,改变原始图像,制造图像上没有目标的假象。在第二阶段,训练神经网络对修改后的图像进行正常的目标检测。
Self-Adversarial Training是在一定程度上抵抗对抗攻击的数据增强技术。CNN计算出Loss, 然后通过反向传播改变图片信息,形成图片上没有目标的假象,然后对修改后的图像进行正常的目标检测。需要注意的是在SAT的反向传播的过程中,是不需要改变网络权值的。
使用对抗生成可以改善学习的决策边界中的薄弱环节,提高模型的鲁棒性。因此这种数据增强方式被越来越多的对象检测框架运用。
5.4 消除网格敏感度
边界框b的计算方式为:
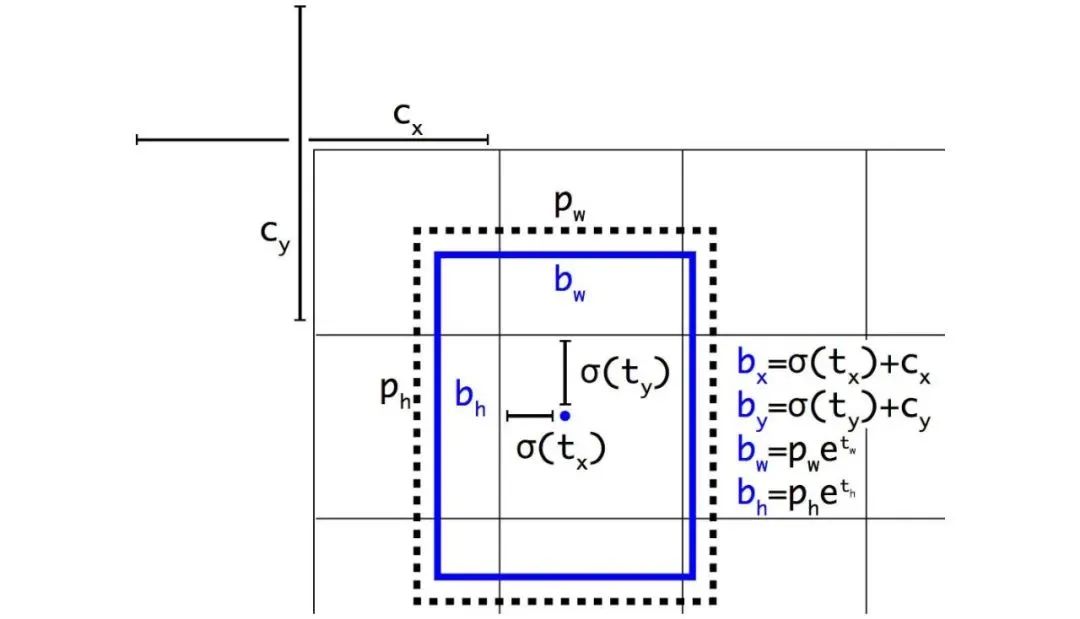
对于和的情况,我们需要分别具有很大的负值和正值。但我们可以将与一个比例因子(>1.0)相乘,从而更轻松地实现这一目标。
5.5 单目标使用多Anchor
如果 IoU(ground truth, anchor) > IoU threshold,则为单个基本真值使用多个锚点。(注:作者没有更多地说明该方法在 YOLOv4 中的作用。)
5.6 余弦模拟退火
余弦调度会根据一个余弦函数来调整学习率。首先,较大的学习率会以较慢的速度减小。然后在中途时,学习的减小速度会变快,最后学习率的减小速度又会变得很慢。
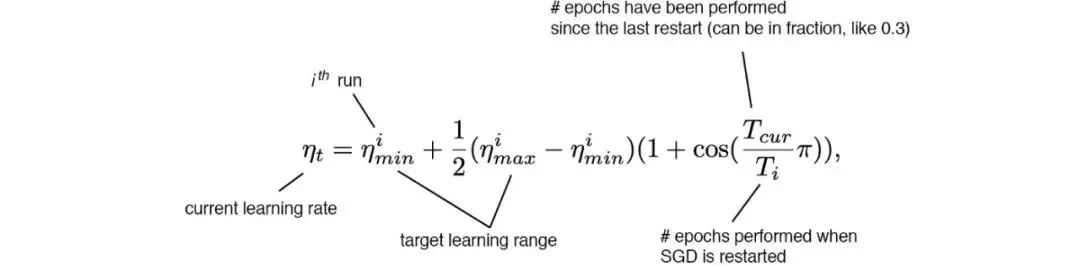
这张图展示了学习率衰减的方式(下图中还应用了学习率预热)及其对mAP的影响。可能看起来并不明显,这种新的调度方法的进展更为稳定,而不是在停滞一段时间后又取得进展。
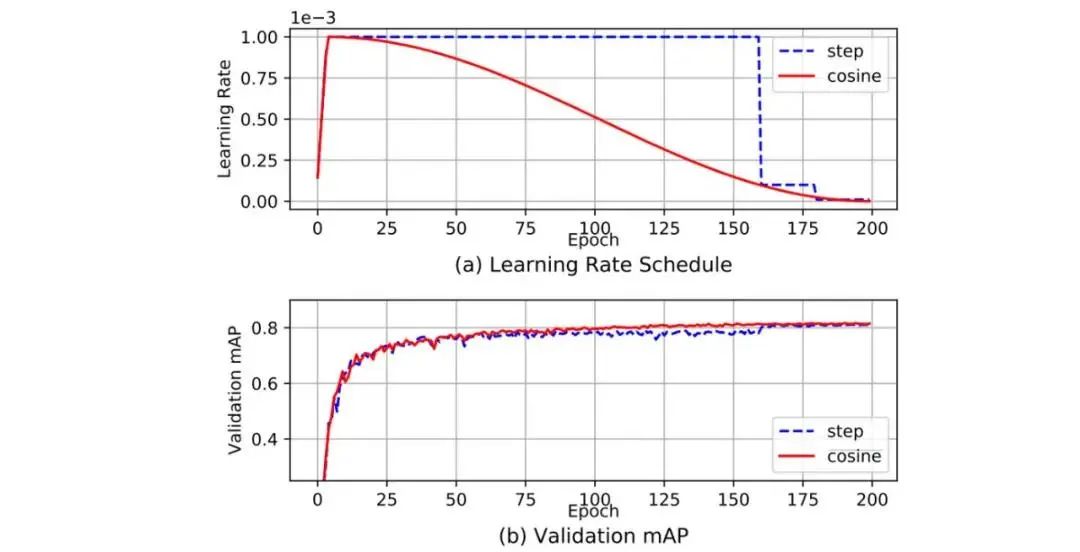
余弦模拟退火论文: https://arxiv.org/pdf/1608.03983.pdf
5.7 遗传算法优化超参
关于遗传算法的文章,我们之前也有学过:遗传算法如何模拟大自然的进化?
遗传算法论文: https://arxiv.org/pdf/2004.10934.pdf
5.8 随机形状训练
许多单阶段目标检测器是在固定的输入图像形状下训练的。为了提高泛化效果,我们可以对不同图像大小的模型进行训练。(在YOLO中进行多尺度训练)。
6.检测头推理策略
在检测头推理中除了用了上面讲的Mish, SPP, PAN技术外,还用了SAM和DIoU-NMS,如下:
6.1 SAM模块
注意力机制在DL设计中被广泛采用。在SAM中,最大值池化和平均池化分别用于输入feature map,创建两组feature map。结果被输入到一个卷积层,接着是一个Sigmoid函数来创建空间注意力。
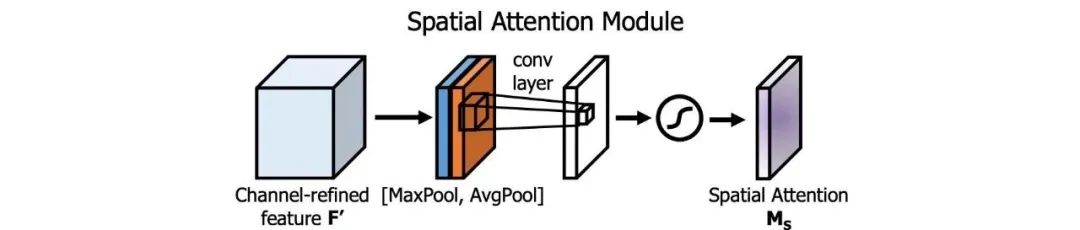
将空间注意掩模应用于输入特征,输出精细的特征图。
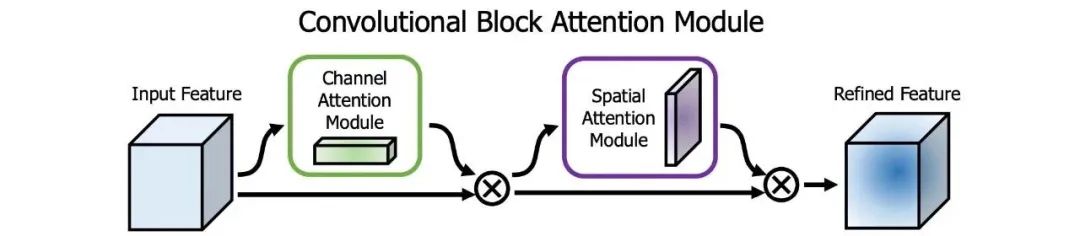
在YOLOv4中,使用修改后的SAM而不应用最大值池化和平均池化。
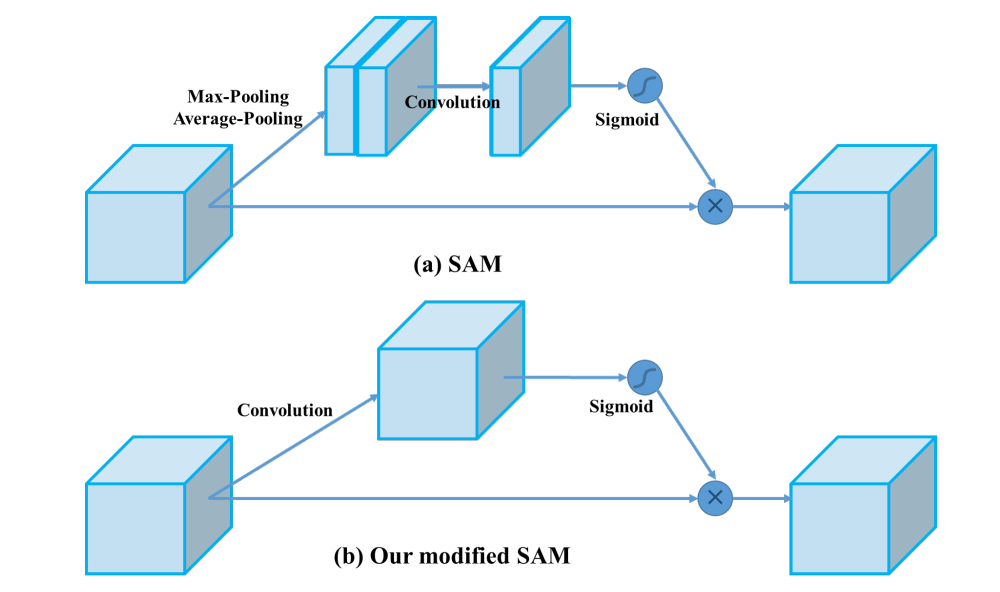
在YOLOv4中,FPN概念逐渐被实现/替换为经过修改的SPP、PAN和PAN。
6.2 DIoU-NMS
NMS过滤掉预测相同对象的其他边界框,并保留具有最高可信度的边界框。
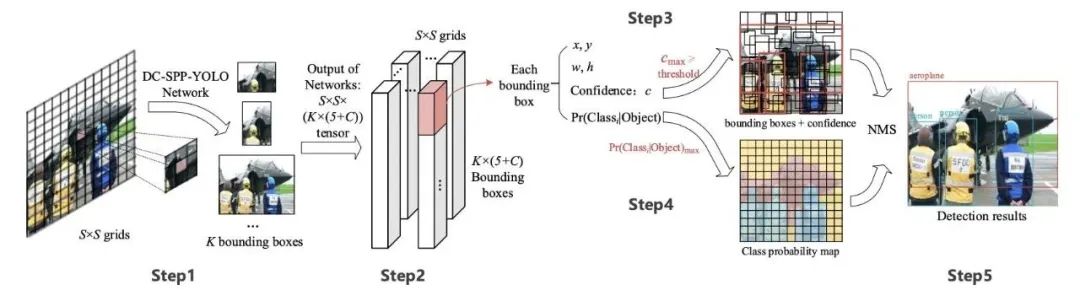
DIoU(前面讨论过的) 被用作非最大值抑制(NMS)的一个因素。该方法在抑制冗余框的同时,采用IoU和两个边界盒中心点之间的距离。这使得它在有遮挡的情况下更加健壮。
7.YOLOv4小结
为了提升准确度,可以针对训练过程进行一些优化,比如数据增强、类别不平衡、成本函数、软标注…… 这些改进不会影响推理速度,可被称为「Bag of freebies」。另外还有一些改进可称为「bag of specials」,仅需在推理时间方面做少许牺牲,就能获得优良的性能回报。这类改进包括增大感受野、使用注意力机制、集成跳过连接(skip-connection)或 FPN等特性、使用非极大值抑制等后处理方法。
本文从YOLOv4介绍,YOLOv4框架原理,BackBone训练策略,BackBone推理策略,检测头训练策略,检测头推理策略这几个大方面进行详细的阐述了YOLOv4中所用到的各种策略,希望对大家有所帮助。
♥点个赞再走呗♥