
目标检测模型YOLO-V1损失函数详解
❝上期我们一起学习了
❞YOLOV1算法的原理框架,如下:
目标检测算法YOLO-V1算法详解
今天我们深入一步,一起学习下关于YOLO-V1算法的损失函数和优缺点。
YOLO-V1损失函数
从上期我们知道,YOLO-V1算法最后输出的检测结果为7x7x30的形式,其中30个值分别包括两个候选框的位置和有无包含物体的置信度以及网格中包含20个物体类别的概率。那么YOLO的损失就包括三部分:位置误差,confidence误差,分类误差。
损失函数的设计目标就是让坐标(x,y,w,h),confidence,classification这个三个方面达到很好的平衡。YOLO-V1算法中简单的全部采用了sum-squared error loss来做这件事,如下图:
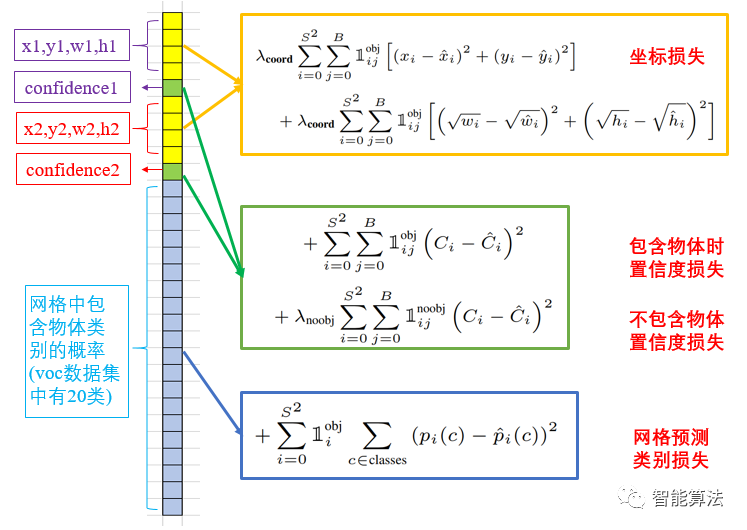
在上图中,我们也能清晰的看出来,整个算法的损失是由预测框的坐标误差,有无包含物体的置信度误差以及网格预测类别的误差三部分组成,三部分的损失都使用了均方误差的方式来实现。
我们知道,如果8维的localization error,两个置信度error和20维的classification error同等重要显然是不合理的;还有如果一个网格中没有object(一幅图中这种网格很多),那么就会将这些网格中的box的confidence push到0,相比于较少的有object的网格,这种做法是overpowering的,这会导致网络不稳定甚至发散。这里算法中用了权重系数来进行平衡,对于不同的损失用不同的权重,我们来逐个看:
位置损失
从上图可以看出,坐标损失也分为两部分,坐标中心误差和位置宽高的误差,其中表示第i个网格中的第j个预测框是否负责obj这个物体的预测,只有当某个box predictor对某个ground truth box负责的时候,才会对box的coordinate error进行惩罚,而对哪个ground truth box负责就看其预测值和ground truth box的IoU是不是在那个网格的所有box中最大。
我们可以看到,对于中心点的损失直接用了均方误差,但是对于宽高为什么用了平方根呢?这里是这样的,我们先来看下图: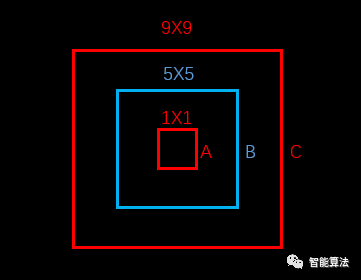 上图中,蓝色为
上图中,蓝色为bounding box,红色框为真实标注,如果W和h没有平方根的话,那么bounding box跟两个真实标注的位置loss是相同的。但是从面积看来B框是A框的25倍,C框是B框的81/25倍。B框跟A框的大小偏差更大,所以不应该有相同的loss。
如果W和h加上平方根,那么B对A的位置loss约为3.06,B对C的位置loss约为1.17,B对A的位置loss的值更大,这更加符合我们的实际判断。所以,算法对位置损失中的宽高损失加上了平方根。
而公式中的为位置损失的权重系数,在pascal VOC训练中取5。
置信度损失
这里分成了两部分,一部分是包含物体时置信度的损失,一个是不包含物体时置信度的值。置信度的定义,我们上期学习过,这里结合置信度损失再看一下:
其中前一项表示有无人工标记的物体落入网格内,如果有,则为1,否则为0.第二项代表bounding box和真实标记的box之间的IoU。值越大则box越接近真实位置。confidence是针对bounding box的,由于每个网格有两个bounding box,所以每个网格会有两个confidence与之相对应。
从损失函数上看,当网格i中的第j个预测框包含物体的时候,用上面的置信度损失,而不包含物体的时候,用下面的损失函数。对没有object的box的confidence loss,赋予小的loss weight,记为在pascal VOC训练中取0.5。有object的box的confidence loss和类别的loss的loss weight正常取1。
类别损失
类别损失这里也用了均方误差,实际上,感觉这里用交叉熵更好一些。其中表示有无object的中心点落到网格i中,如果网格中包含有物体object的中心的话,那么就负责预测该object的概率。
总体来说,对于不同的任务重要程度不同,所以也应该给与不同的loss weight:
每个网格两个预测框坐标比较重要,给这些损失赋予更大的 loss weight,在pascal VOC中取值为5.对没有 object的box的confidence loss,赋予较小的loss weight,在pascal VOC训练中取0.5.对有 object的box的confidence loss和类别的loss weight正常取值为1.
YOLO-V1的缺点
由于YOLOV1的框架设计,该网络存在以下缺点:
每个网格只对应两个 bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果较差。原始图片只划分为 7x7的网格,当两个物体靠的很近时,效果比较差。最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到)。 对于图片中比较小的物体,效果比较差。这其实是所有目标检测算法的通病。
好了,至此,我们这两期学习了YOLO-V1的结构框架和损失函数。下期我们将一起学习YOLO-V2的框架,看看YOLO-V2对YOLO-V1做了哪些改进。
♥转发在看也是一种支持♥