
图像生成王者不是GAN?扩散模型最近有点火:靠加入类别条件,效果...
点击上方“迈微AI研习社”,选择“星标★”公众号
重磅干货,第一时间送达
OpenAI刚刚推出的年末新作GLIDE,又让扩散模型小火了一把。
这个基于扩散模型的文本图像生成大模型参数规模更小,但生成的图像质量却更高。
于是,依旧是OpenAI出品,论文标题就直接号称“在图像生成上打败GAN”的ADM-G模型也重新进入了大众眼中:

光看Papers with Code上基于ImageNet数据集的图像生成模型榜单,从64 x 64到512 x 512分辨率都由这一模型占据榜首:
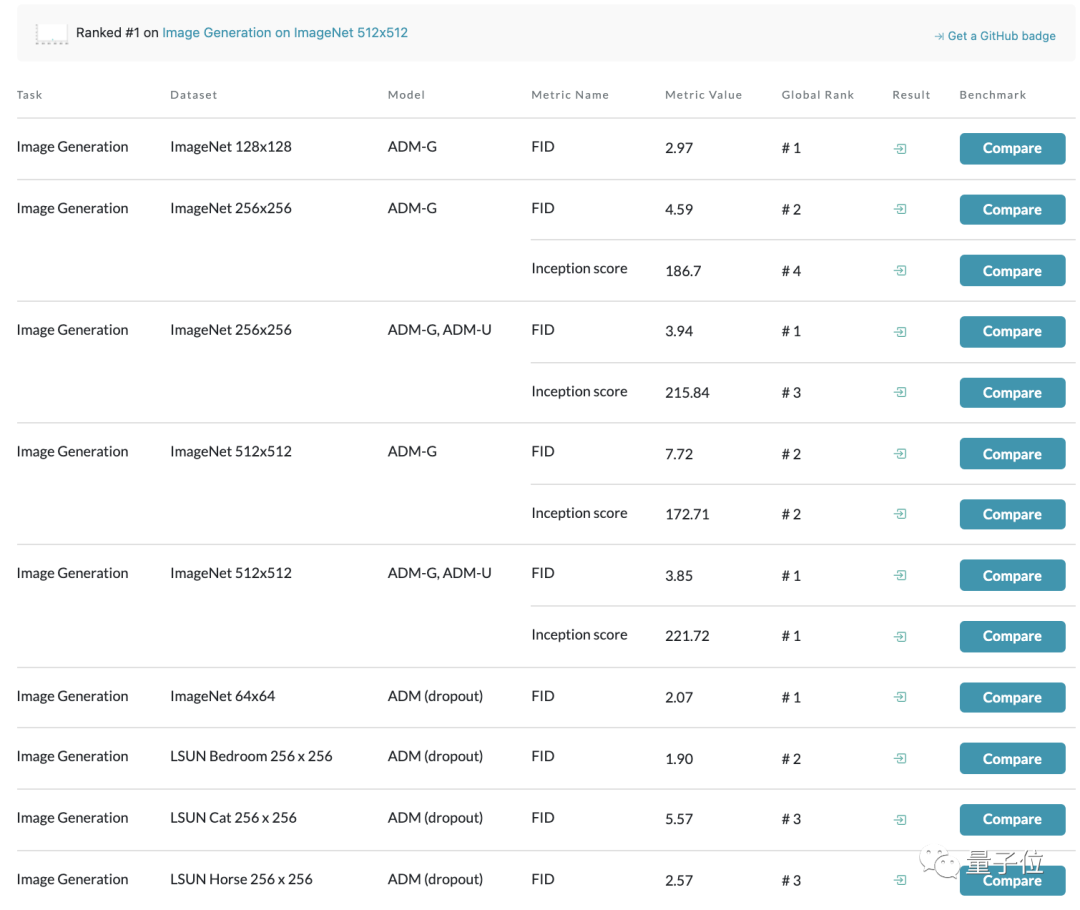
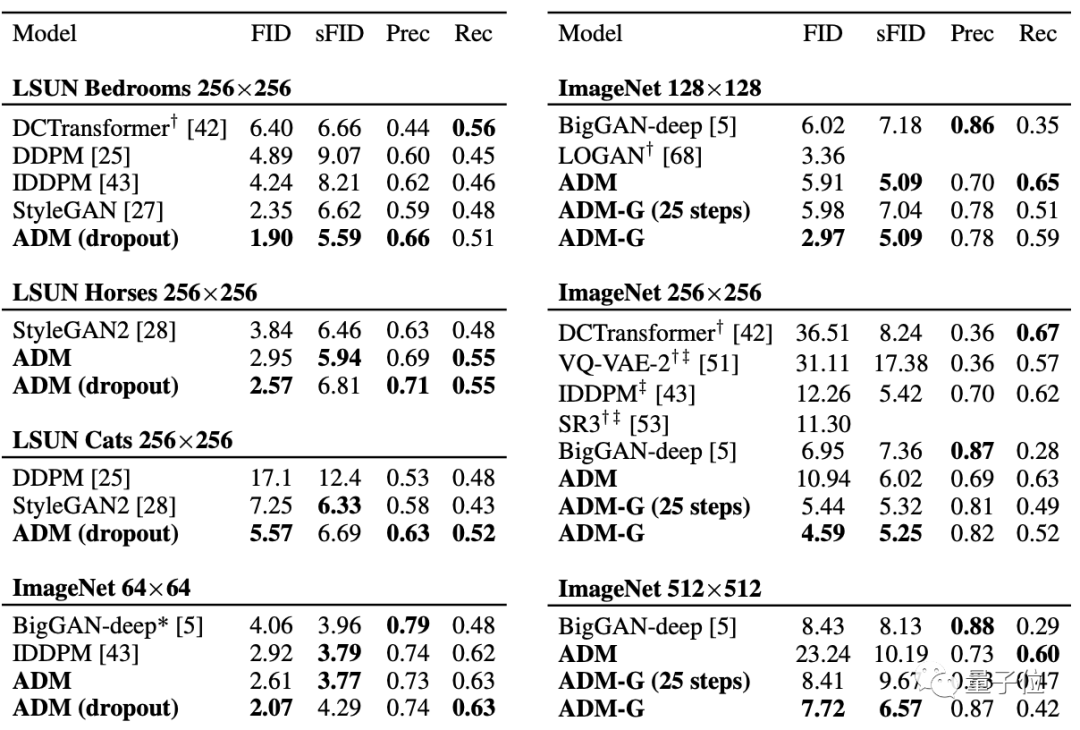
对比曾号称史上最强图像生成器的BigGAN-deep也不落下风,甚至还能在LSUN和ImageNet 64 × 64的图像生成效果上达到SOTA。
有网友对此感叹:前几年图像生成领域一直由GAN主导,现在看来,似乎要变成扩散模型了。

加入类别条件的扩散模型
我们先来看看扩散模型的定义。
这是一种新的图像生成的方法,其名字中的“扩散”本质上是一个迭代过程。
具体到推理中,就是从一幅完全由噪声构成的图像开始,通过预测每个步骤滤除的噪声,迭代去噪得到一个高质量的样本,然后再逐步添加更多的细节。
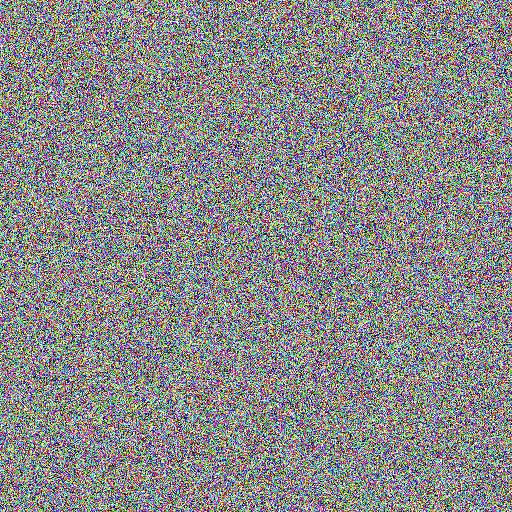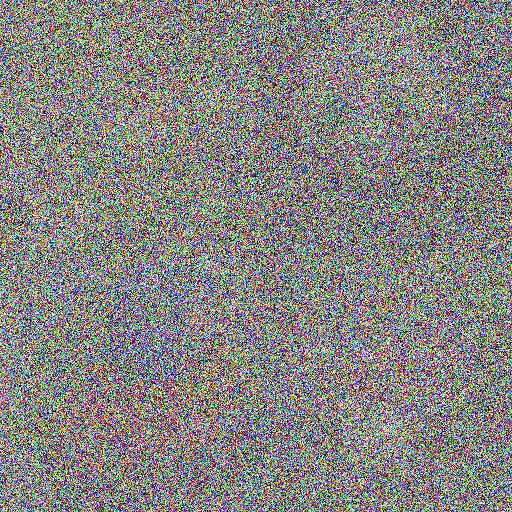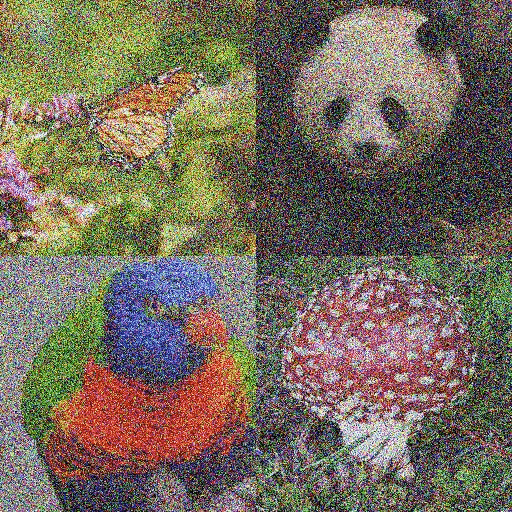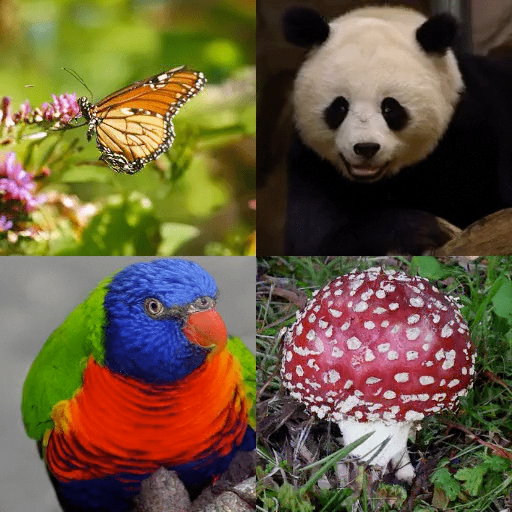
而OpenAI的这个ADM-G模型,则是在此基础上向图像生成任务中加入了类别条件,形成了一种独特的消融扩散模型。
研究人员分别从以下几个方面做了改进:
基本架构
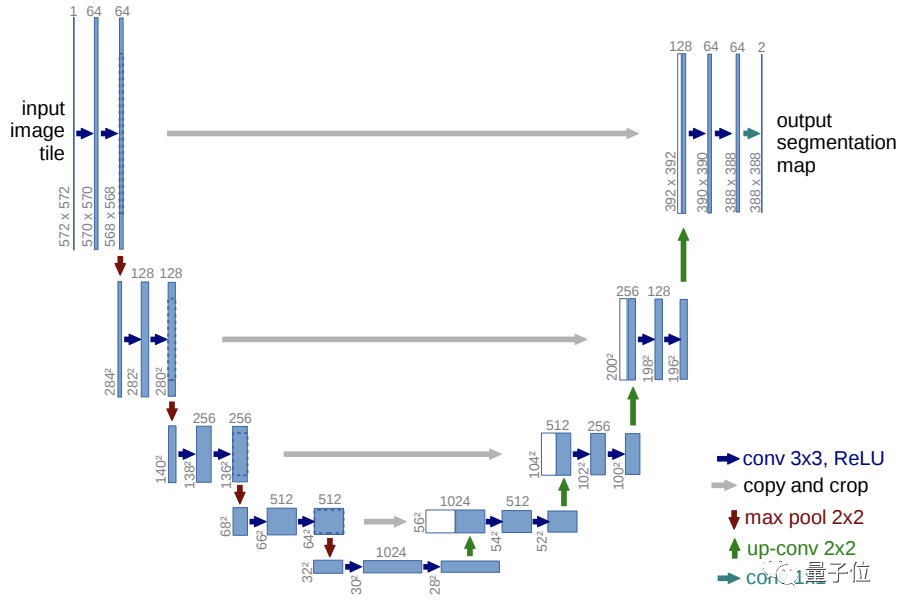
基于UNet结构做了五点改进:
在保持模型大小不变的前提下,增加深度与宽度
增加注意头(Attention Head)数量
在32×32、16×16和8×8的分辨率下都使用注意力机制
使用BigGAN残差块对激活函数进行上采样和下采样
将残差连接(Residual Connections)缩小为原来的1/根号2
类别引导(Classifier Guidance)
在噪声逐步转换到信号的过程中,研究人员引入了一个预先训练好的分类网络。
它能够为中间生成图像预测并得到一个标签,也就是可以对生成的图片进行分类。
之后,再基于分类分数和目标类别之间的交叉熵损失计算梯度,用梯度引导下一步的生成采样。
缩放分类梯度(Scaling Classifier Gradients)
按超参数缩放分类网络梯度,以此来控制生成图像的多样性和精度。
比如像这样,左边是1.0规模大小的分类网络,右边是10.0大小的分类网络,可以看到,右边的生成图像明显类别更加一致:

也就是说,分类网络梯度越高,类别就越一致,精度也越高,而同时多样性也会变小。
生成领域的新热点
目前,这一模型在GitHub上已有近千标星:

而与GAN比起来,扩散模型生成的图像还更多样、更复杂。
基于同样的训练数据集时,扩散模型可以生成拥有全景、局部特写、不同角度的图像:
 △左:BigGAN-deep 右:ADM
△左:BigGAN-deep 右:ADM
其实,自2020年谷歌发表DDPM后,扩散模型就逐渐成为了生成领域的一个新热点,
除了文章中提到的OpenAI的两篇论文之外,还有Semantic Guidence Diffusion、Classifier-Free Diffusion Guidence等多个基于扩散模型设计的生成模型。
扩散模型接下来还会在视觉任务上有哪些新的应用呢,我们来年再看。
论文链接:
https://arxiv.org/abs/2105.05233
开源链接:
https://github.com/openai/guided-diffusion
参考链接:
[1]https://www.casualganpapers.com/guided_diffusion_langevin_dynamics_classifier_guidance/Guided-Diffusion-explained.html
[2]https://www.reddit.com/r/MachineLearning/comments/rq1cnm/d_diffusion_models_beat_gans_on_image_synthesis/
更多细节可参考论文原文,更多精彩内容请关注迈微AI研习社,每天晚上七点不见不散!
© THE END
投稿或寻求报道微信:MaiweiE_com
GitHub中文开源项目《计算机视觉实战演练:算法与应用》,“免费”“全面“”前沿”,以实战为主,编写详细的文档、可在线运行的notebook和源代码。
项目地址 https://github.com/Charmve/computer-vision-in-action
项目主页 https://charmve.github.io/L0CV-web/
推荐阅读
(更多“抠图”最新成果)
微信号: MaiweiE_com
GitHub: @Charmve
CSDN、知乎: @Charmve
投稿: yidazhang1@gmail.com
主页: github.com/Charmve
如果觉得有用,就请点赞、转发吧!