
超越GAN?OpenAI提出可逆生成模型Glow!图像生成太逼真
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
作者:Aryansh Omray,微软数据科学工程师,Medium技术博主
机器学习领域的一个基本问题就是如何学习复杂数据的表征是机器学习。这项任务的重要性在于,现存的大量非结构化和无标签的数据,只有通过无监督式学习才能理解。密度估计、异常检测、文本总结、数据聚类、生物信息学、DNA建模等各方面的应用均需要完成这项任务。多年来,研究人员发明了许多方法来学习大型数据集的概率分布,包括生成对抗网络(GAN)、变分自编码器(VAE)和Normalizing Flow等。本文即向大家介绍Normalizing Flow这一为了克服GAN和VAE的不足而提出的方法。

Glow模型的输出样例
https://papers.nips.cc/paper/2018/file/d139db6a236200b21cc7f752979132d0-Paper.pdf
GAN和VAE的能力本已十分惊人,它们都能通过简单的推理方法学习十分复杂的数据分布。然而,GAN和VAE都缺乏对概率分布的精确评估和推理,这往往导致VAE中的模糊结果质量不高,GAN训练也面临着如模式崩溃和后置崩溃等挑战。因此,Normalizing Flow应运而生,试图通过使用可逆函数来解决目前GAN和VAE存在的许多问题。
Normalizing Flow
简单地说,Normalizing Flow就是一系列的可逆函数,或者说这些函数的解析逆是可以计算的。例如,f(x)=x+2是一个可逆函数,因为每个输入都有且仅有一个唯一的输出,并且反之亦然,而f(x)=x²则不是一个可逆函数。这样的函数也被称为双射函数。

图源作者
从上图可以看出,Normalizing Flow可以将复杂的数据点(如MNIST中的图像)转化为简单的高斯分布,反之亦然。和GAN非常不一样的地方是,GAN输入的是一个随机向量,而输出的是一个图像,基于流(Flow)的模型则是将数据点转化为简单分布。在上图的MNIST一例中,我们从高斯分布中抽取随机样本,均可重新获得其对应的MNIST图像。
基于流的模型使用负对数可能性损失函数进行训练,其中p(z)是概率函数。下面的损失函数就是使用统计学中的变量变化公式得到的。

https://papers.nips.cc/paper/2018/file/d139db6a236200b21cc7f752979132d0-Paper.pdf
Normalizing Flow的优势
与GAN和VAE相比,Normalizing Flow具有各种优势,包括:
Normalizing Flow模型不需要在输出中放入噪声,因此可以有更强大的局部方差模型(local variance model);
与GAN相比,基于流的模型训练过程非常稳定,GAN则需要仔细调整生成器和判别器的超参数;
与GAN和VAE相比,Normalizing Flow更容易收敛。
Normalizing Flow的不足
虽然基于流的模型有其优势,但它们也有一些缺点:
基于流的模型在密度估计等任务上的表现不尽如人意;
基于流的模型要求保留变换的体积(volume preservation over transformations),这往往会产生非常高维的潜在空间,通常会导致解释性变差;
基于流的模型产生的样本通常没有GAN和VAE的好。
为了更好地理解Normalizing Flow,我们以Glow架构为例进行解释。Glow是OpenAI在2018年提出的一个基于流的模型。下图展示了Glow的架构。
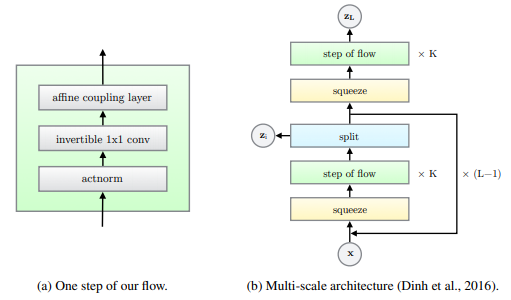
Glow的架构
https://papers.nips.cc/paper/2018/file/d139db6a236200b21cc7f752979132d0-Paper.pdf
Glow架构由多个表层(superficial layers)组合而成。首先我们来看看Glow模型的多尺度框架。Glow模型由一系列的重复层(命名为尺度)组成。每个尺度包括一个挤压函数和一个流步骤,每个流步骤包含ActNorm、1x1 Convolution和Coupling Layer,流步骤后是分割函数。分割函数在通道维度上将输入分成两个相等的部分。其中一半进入之后的层,另一半则进入损失函数。分割是为了减少梯度消失的影响,梯度消失会在模型以端到端方式(end-to-end)训练时出现。
如下图所示,挤压函数(squeeze function)通过横向重塑张量,将大小为[c, h, w]的输入张量转换为大小为[4c, h/2, w/2]的张量。此外,在测试阶段可以采用重塑函数,将输入的[4c, h/2, w/2]重塑为大小为[c, h, w]的张量。
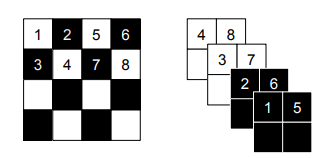
https://arxiv.org/pdf/1605.08803.pdf
其他层,如ActNorm、1x1 Convolution和Affine Coupling层,可以从下表理解。该表展示了每层的功能(包括正向和反向)。
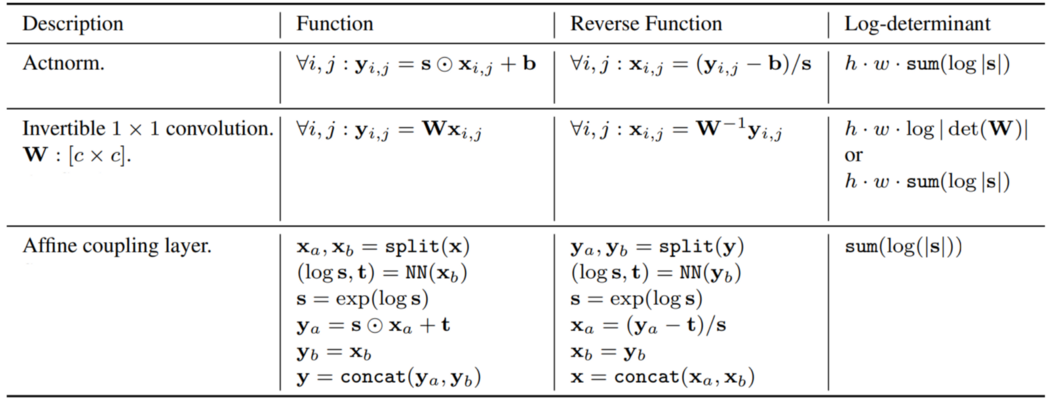
https://arxiv.org/pdf/1605.08803.pdf
实现
在了解了Normalizing Flow和Glow模型的基础知识后,我们将介绍如何使用PyTorch实现该模型,并在MNIST数据集上进行训练。
Glow模型
首先,我们将使用PyTorch和nflows实现Glow架构。为了节省时间,我们使用nflows包含所有层的实现。
import torchimport torch.nn as nnimport torch.nn.functional as Ffrom nflows import transformsimport numpy as npfrom torchvision.transforms.functional import resizefrom nflows.transforms.base import Transformclass Net(nn.Module):def __init__(self, in_channel, out_channels):super().__init__()self.net = nn.Sequential(nn.Conv2d(in_channel, 64, 3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, 1),nn.ReLU(inplace=True),ZeroConv2d(64, out_channels),)def forward(self, inp, context=None):return self.net(inp)def getGlowStep(num_channels, crop_size, i):mask = [1] * num_channelsif i % 2 == 0:mask[::2] = [-1] * (len(mask[::2]))else:mask[1::2] = [-1] * (len(mask[1::2]))def getNet(in_channel, out_channels):return Net(in_channel, out_channels)return transforms.CompositeTransform([transforms.ActNorm(num_channels),transforms.OneByOneConvolution(num_channels),transforms.coupling.AffineCouplingTransform(mask, getNet)])def getGlowScale(num_channels, num_flow, crop_size):z = [getGlowStep(num_channels, crop_size, i) for i in range(num_flow)]return transforms.CompositeTransform([transforms.SqueezeTransform(),*z])def getGLOW():num_channels = 1 * 4num_flow = 32num_scale = 3crop_size = 28 // 2transform = transforms.MultiscaleCompositeTransform(num_scale)for i in range(num_scale):next_input = transform.add_transform(getGlowScale(num_channels, num_flow, crop_size),[num_channels, crop_size, crop_size])num_channels *= 2crop_size //= 2return transformGlow_model = getGLOW()
我们可以用各种数据集来训练Glow模型,如MNIST、CIFAR-10、ImageNet等。本文为了演示方便,使用的是MNIST数据集。
像MNIST(https://gas.graviti.cn/dataset/data-decorators/MNIST)这样的数据集可以很容易地从格物钛开放数据集平台(https://gas.graviti.cn/open-datasets)获取,该平台包含了机器学习中所有常用的开放数据集,如分类、密度估计、物体检测和基于文本的分类数据集等。
要访问数据集,我们只需要在格物钛的平台上创建账户,就可以直接fork想要的数据集,可以直接下载或者使用格物钛提供的pipeline导入数据集。基本的代码和相关文档可在TensorBay的支持网页上获得(graviti.cn/tensorBay)。
结合格物钛TensorBay的Python SDK,我们可以很方便地导入MNIST数据集到PyTorch中:
from PIL import Imagefrom torch.utils.data import DataLoader, Datasetfrom torchvision import transformsfrom tensorbay import GASfrom tensorbay.dataset import Dataset as TensorBayDatasetclass MNISTSegment(Dataset):def __init__(self, gas, segment_name, transform):super().__init__()self.dataset = TensorBayDataset("MNIST", gas)self.segment = self.dataset[segment_name]self.category_to_index = self.dataset.catalog.classification.get_category_to_index()self.transform = transformdef __len__(self):return len(self.segment)def __getitem__(self, idx):data = self.segment[idx]with data.open() as fp:image_tensor = self.transform(Image.open(fp))return image_tensor, self.category_to_index[data.label.classification.category]
模型训练
模型训练可以通过下面的代码简单开始。该代码使用格物钛TensorBay提供的Pipeline创建数据加载器,其中的ACCESS_KEY可以在TensorBay的账户设置中获得。
from nflows.distributions import normalACCESS_KEY = "Accesskey-*****"EPOCH = 100to_tensor = transforms.ToTensor()normalization = transforms.Normalize(mean=[0.485], std=[0.229])my_transforms = transforms.Compose([to_tensor, normalization])train_segment = MNISTSegment(GAS(ACCESS_KEY), segment_name="train", transform=my_transforms)train_dataloader = DataLoader(train_segment, batch_size=4, shuffle=True, num_workers=4)optimizer = torch.optim.Adam(Glow_model.parameters(), 1e-3)for epoch in range(EPOCH):for index, (image, label) in enumerate(train_dataloader):if index == 0:image_size = image.shaape[2]channels = image.shape[1]image = image.cuda()output, logabsdet = Glow_model._transform(image)shape = output.shape[1:]log_z = normal.StandardNormal(shape=shape).log_prob(output)loss = log_z + logabsdetloss = -loss.mean()/(image_size * image_size * channels)optimizer.zero_grad()loss.backward()optimizer.step()print(f"Epoch:{epoch+1}/{EPOCH} Loss:{loss}")
上面代码用的是MNIST数据集,要想使用其他数据集我们可以直接替换该数据集的数据加载器。
样例生成
模型训练完成之后,我们可以通过下面的代码来生成样例:
samples = Glow_model.sample(25)display(samples)
使用nflows库之后,我们只需要用一行代码就可以生成样例,而display函数则能在一个网格中显示生成的样本。

用MNIST训练模型之后生成的样例
结语
本文向大家介绍了Normalizing Flow的基本知识,并与GAN和VAE进行了比较,同时向大家展示了Glow模型的基本工作方式。我们还讲解了如何简单实现Glow模型,并使用MNIST数据集进行训练。在格物钛公开数据集平台的帮助下,数据集访问变得十分便捷。

关于「格物钛」
格物钛定位为面向机器学习的数据平台,帮助AI开发者解决日益增长的非结构化数据难题。借助非结构化数据管理平台TensorBay和开源数据集社区Open Datasets,机器学习团队和个人可进行数据管理、查询、协同、可视化和版本控制等高效操作,降低高质量数据获取、存储和处理成本,加速AI开发和产品创新。
Open Datasets 👉
格物钛|公开数据集
graviti.cn/open-datasets
订阅号:格物钛 👉
微信号|Graviti_2019
微博|格物钛
https://www.graviti.cn/
点击阅读原文 / 访问格物钛官网