
这篇文章主要介绍了Python 爬虫批量爬取网页图片保存到本地,本文通过实例代码给大家介绍的非常详细,对大家的学习或工作具有一定的参考借鉴价值,需要的朋友可以参考下
其实和爬取普通数据本质一样,不过我们直接爬取数据会直接返回,爬取图片需要处理成二进制数据保存成图片格式(.jpg,.png等)的数据文本。
现在贴一个url=https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg
请复制上面的url直接在某个浏览器打开,你会看到如下内容:
这就是通过网页访问到的该网站的该图片,于是我们可以直接利用requests模块,进行这个图片的请求,于是这个网站便会返回给我们该图片的数据,我们再把数据写入本地文件就行,比较简单。
import requests
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
url='https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg'
re=requests.get(url,headers=headers)
print(re.status_code)#查看请求状态,返回200说明正常
path='test.jpg'#文件储存地址
with open(path, 'wb') as f:#把图片数据写入本地,wb表示二进制储存
for chunk in re.iter_content(chunk_size=128):
f.write(chunk)
然后得到test.jpg图片,如下

点击打开查看如下:
便是下载成功辣,很简单吧。
现在分析下批量下载,我们将上面的代码打包成一个函数,于是针对每张图片,单独一个名字,单独一个图片文件请求,于是有如下代码:
import requests
def get_pictures(url,path):
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
re=requests.get(url,headers=headers)
print(re.status_code)#查看请求状态,返回200说明正常
with open(path, 'wb') as f:#把图片数据写入本地,wb表示二进制储存
for chunk in re.iter_content(chunk_size=128):
f.write(chunk)
url='https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-001.jpg'
path='test.jpg'#文件储存地址
get_pictures(url,path)
现在要实现批量下载图片,也就是批量获得图片的url,那么我们就得分析网页的代码结构,打开原始网站https://www.ivsky.com/tupian/bianxingjingang_v622/,会看到如下的图片:
于是我们需要分别得到该页面中显示的所有图片的url,于是我们再次用requests模块返回当前该页面的内容,如下:
import requests
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
url='https://www.ivsky.com/tupian/bianxingjingang_v622/'
re=requests.get(url,headers=headers)
print(re.text)
运行会返回当前该页面的网页结构内容,于是我们找到和图片相关的也就是.jpg或者.png等图片格式的字条,如下:

上面圈出来的**//img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-017.jpg**便是我们的图片url,不过还需要前面加上https:,于是完成的url就是https://img.ivsky.com/img/tupian/t/201008/05/bianxingjingang-017.jpg。
我们知道了这个结构,现在就是把这个提取出来,写个简单的解析式:
import requests
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
url='https://www.ivsky.com/tupian/bianxingjingang_v622/'
re=requests.get(url,headers=headers)
def get_pictures_urls(text):
st='img src="'
m=len(st)
i=0
n=len(text)
urls=[]#储存url
while i<n:
if text[i:i+m]==st:
url=''
for j in range(i+m,n):
if text[j]=='"':
i=j
urls.append(url)
break
url+=text[j]
i+=1
return urls
urls=get_pictures_urls(re.text)
for url in urls:
print(url)
打印结果如下:
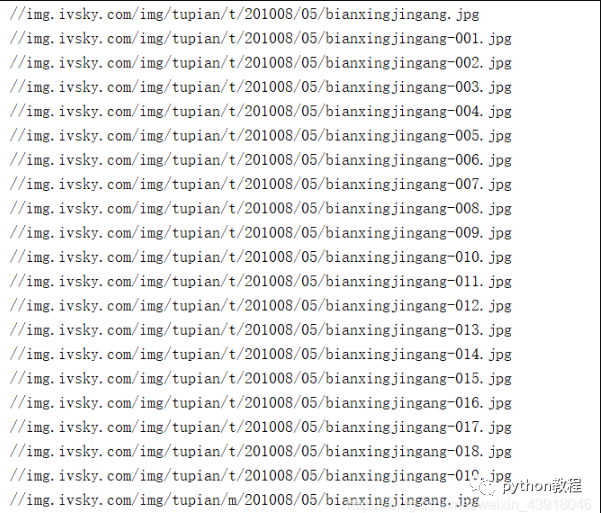
得到了url,现在就直接放入一开始的get_pictures函数中,爬取图片辣。
import requests
def get_pictures(url,path):
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
re=requests.get(url,headers=headers)
print(re.status_code)#查看请求状态,返回200说明正常
with open(path, 'wb') as f:#把图片数据写入本地,wb表示二进制储存
for chunk in re.iter_content(chunk_size=128):
f.write(chunk)
def get_pictures_urls(text):
st='img src="'
m=len(st)
i=0
n=len(text)
urls=[]#储存url
while i<n:
if text[i:i+m]==st:
url=''
for j in range(i+m,n):
if text[j]=='"':
i=j
urls.append(url)
break
url+=text[j]
i+=1
return urls
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3861.400 QQBrowser/10.7.4313.400'}
url='https://www.ivsky.com/tupian/bianxingjingang_v622/'
re=requests.get(url,headers=headers)
urls=get_pictures_urls(re.text)#获取当前页面所有图片的url
for i in range(len(urls)):#批量爬取图片
url='https:'+urls[i]
path='变形金刚'+str(i)+'.jpg'
get_pictures(url,path)
结果如下:
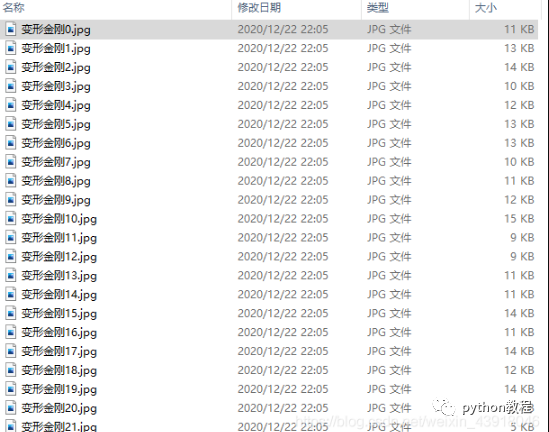
然后就完成辣,这里只是简单介绍下批量爬取图片的过程,具体的网站需要具体分析,所以本文尽可能详细的展示了批量爬取图片的过程分析,希望对你的学习有所帮助,如有问题请及时指出,谢谢~
到此这篇关于Python 爬虫批量爬取网页图片保存到本地的文章就介绍到这了
欢迎大家点赞,留言,转发,转载,感谢大家的相伴与支持
万水千山总是情,点个【在看】行不行
*声明:本文于网络整理,版权归原作者所有,如来源信息有误或侵犯权益,请联系我们删除或授权事宜

