
Python爬虫,爬取博客园文章列表
前言
本次的案例源自于蚂蚁老师的爬虫课程。但由于博客园网站作了升级,所以蚂蚁老师的示例代码失效了,我根据蚂蚁老师教授的知识结合网上搜索来的资料,重新编写了一份代码,复现了蚂蚁老师在课程中的演示效果。
需求
下面我们来明确一下需求 爬取博客园前20页的文章标题、对应的文章链接以及对应的点赞数 如图所示 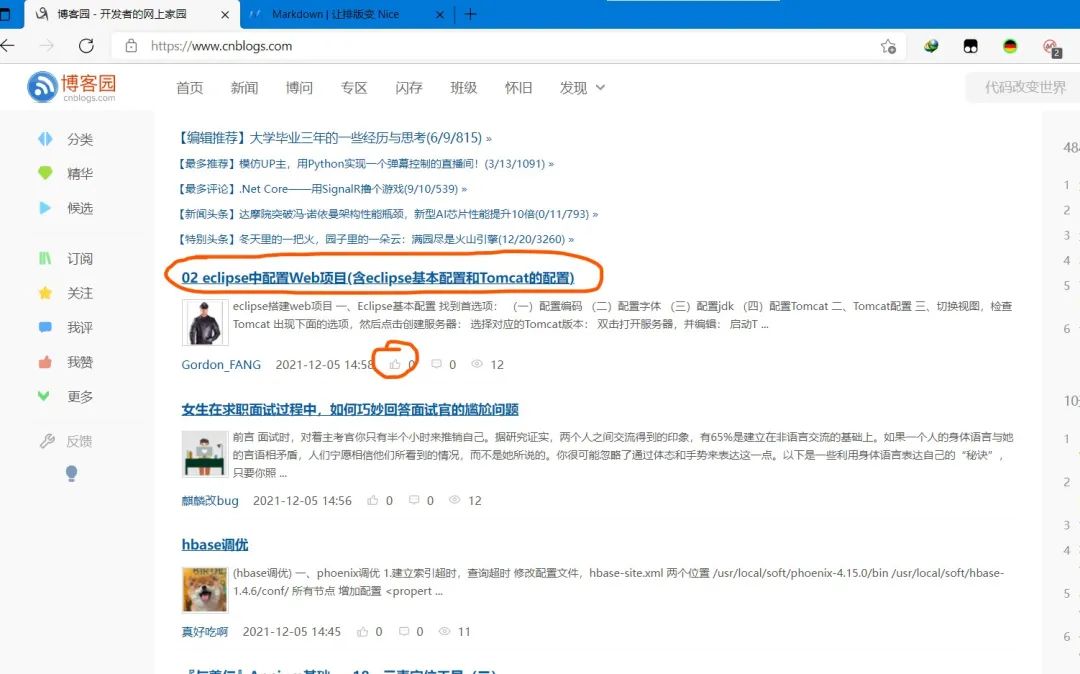 网站分页设置
网站分页设置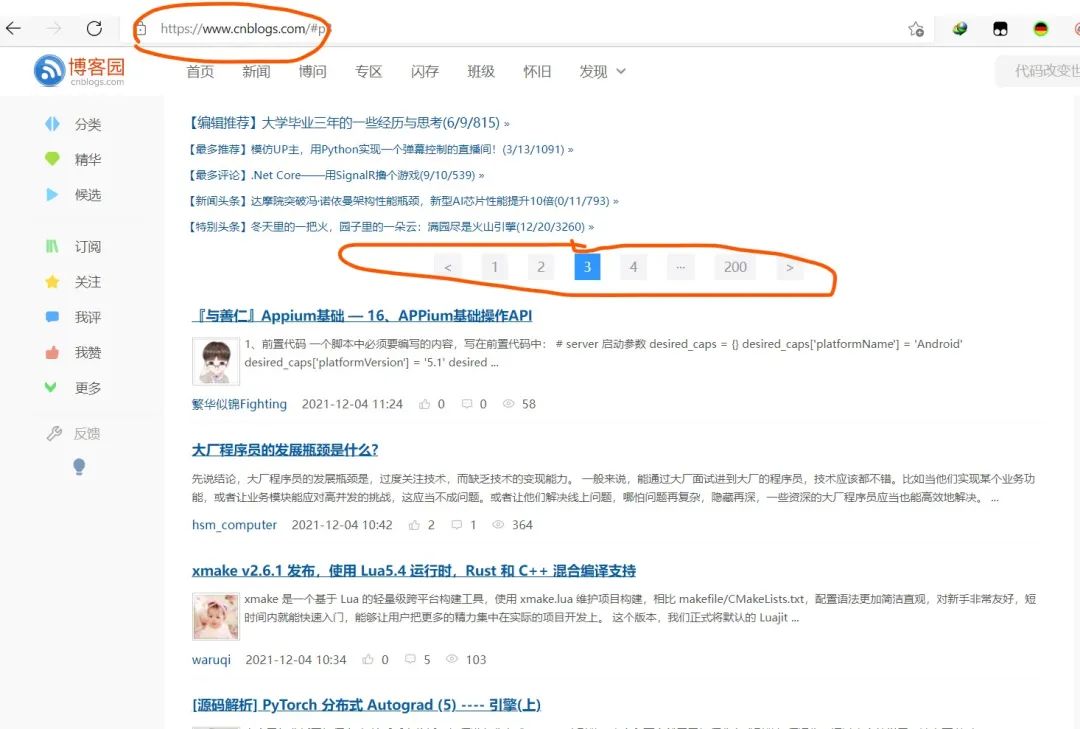
查看网站的html代码
整体分析
通过浏览器内置的查看网络部分,我们发现了点击分页时,实际请求的url并不是浏览器输入框中的信息,而是:https://www.cnblogs.com/AggSite/AggSitePostList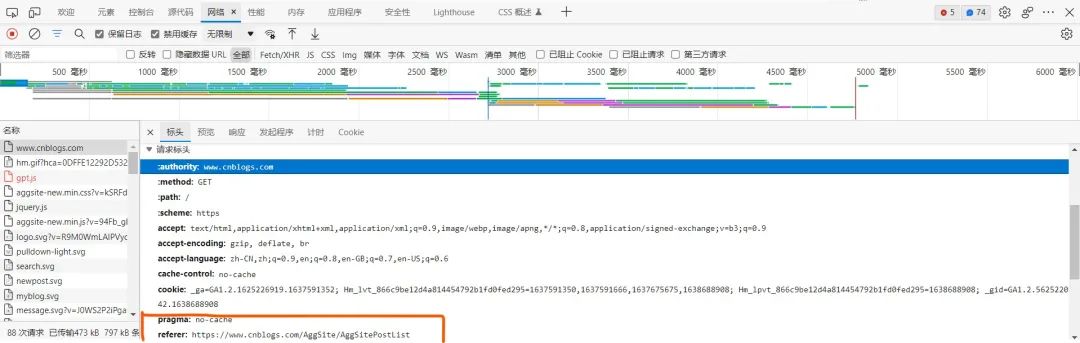
找到对应的请求部分 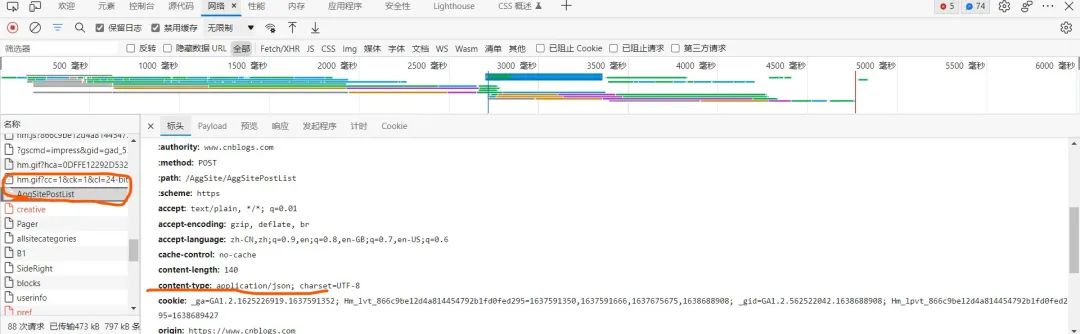 可以发现,对应的content-type信息,以及user-agent信息 我们将这俩信息对应放到代码的header部分,作为一个请求头附入request里面,模拟浏览器,防止网站的反爬虫措施干扰。另外,为了将爬虫伪装得更加像是一个浏览器,可以将请求负载也加到request中
可以发现,对应的content-type信息,以及user-agent信息 我们将这俩信息对应放到代码的header部分,作为一个请求头附入request里面,模拟浏览器,防止网站的反爬虫措施干扰。另外,为了将爬虫伪装得更加像是一个浏览器,可以将请求负载也加到request中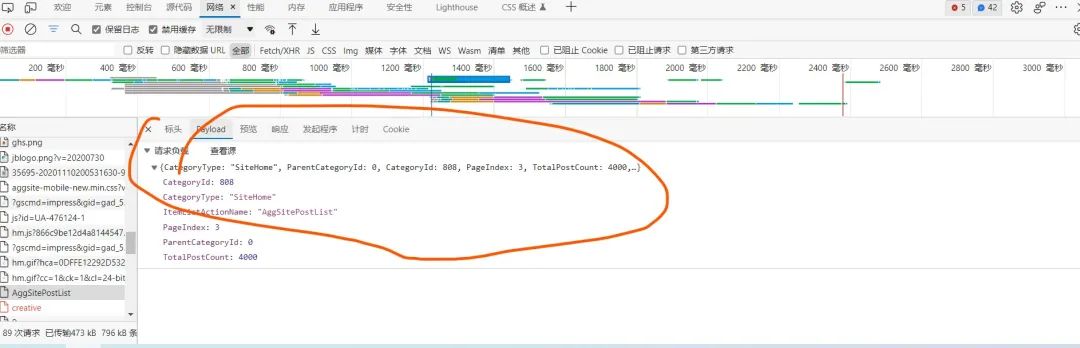
局部分析
下面我们来找具体的信息藏在哪里 鼠标右键对应的内容,查看html代码,就可以发现如下内容
文章标题和url链接 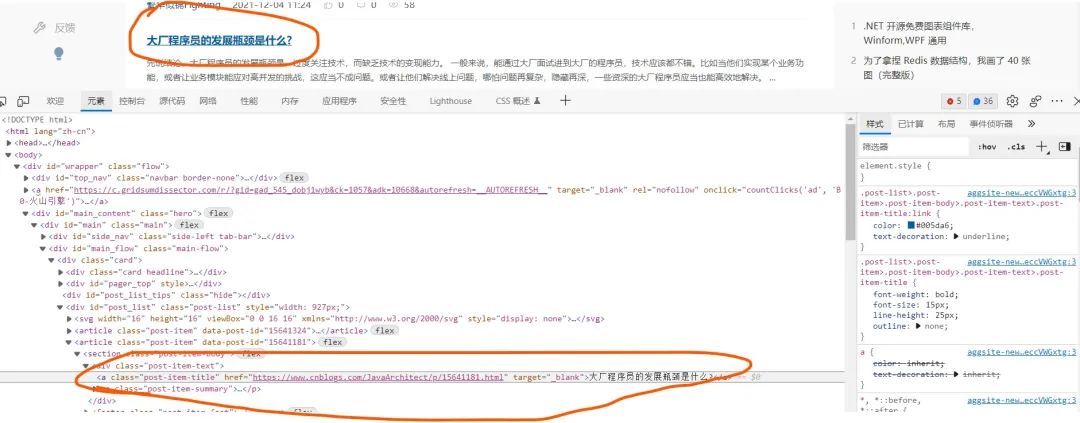 点赞数
点赞数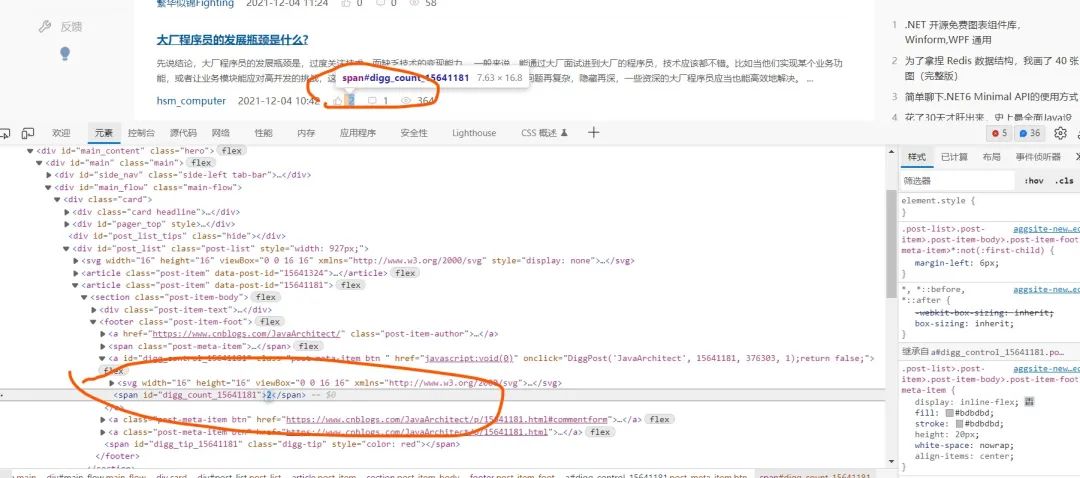
现在我们就可以根据前面的分析写代码了
代码编写
为了演示,我的代码只爬取了前3页的内容,如果你想要爬200页,可自行修改代码
"""
爬取前20页的文章标题、链接、点赞数
"""
import requests
from bs4 import BeautifulSoup
import re
import json
for idx in range(1, 3):
print("#" * 30, idx)
url = "https://www.cnblogs.com/AggSite/AggSitePostList"
headers = {"content-type": "application/json", "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.54 Safari/537.36 Edg/95.0.1020.30"}
request_payload = {"CategoryType": "SiteHome", "ParentCategoryId": 0, "CategoryId": 808, "PageIndex": idx, "TotalPostCount": 4000, "ItemListActionName": "AggSitePostList"}
r = requests.post(url, data=json.dumps(request_payload), headers=headers)
if r.status_code != 200:
print(r.status_code)
raise Exception()
soup = BeautifulSoup(r.text, "html.parser")
section_list = soup.find_all("section", class_="post-item-body")
for section in section_list:
a_tag = section.find("a", class_="post-item-title")
passage_link = a_tag.get("href")
passage_name = a_tag.get_text()
span_tag = section.find("span", id=re.compile(r"^digg"))
numbers = span_tag.get_text()
print(passage_link, passage_name, numbers)
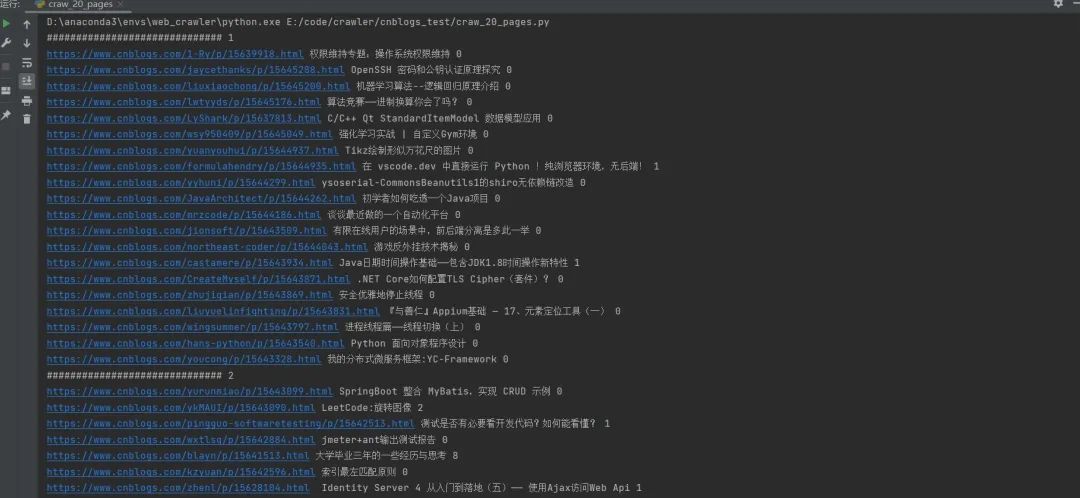
运行结果
评论