
手把手带你爬虫 | 爬取500px图片
目标
爬取500px网站图片并保存到本地。
项目准备
软件:Pycharm
第三方库:requests,fake_useragent
网站地址:https://500px.com/popular
网站分析
首先拿到一个网站,先看一下目标网站是静态加载还是动态加载的。

右边有个下拉滚动条,下拉之后会发现,它是没有页码并且会自动加载的,一般这样就可以初步判断该网站为动态加载方式,或者还可以打开开发者模式,复制其中一个图片链接,Ctrl+U查看源代码,Ctrl+f打开搜索框,把链接地址粘贴进去,会发现根本找不到这个链接地址,这样就可以确定为动态加载。
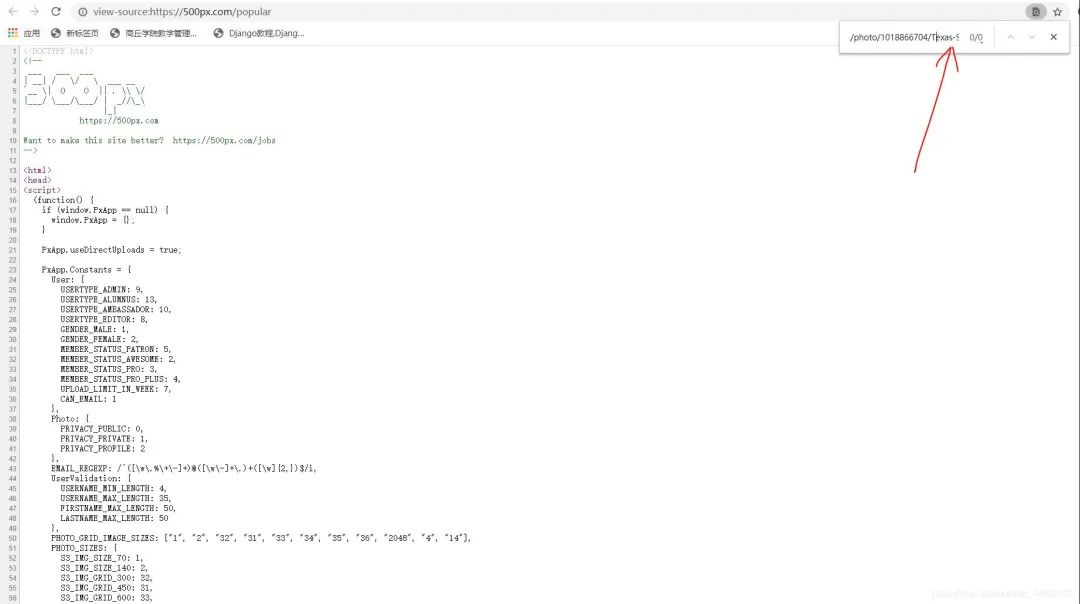
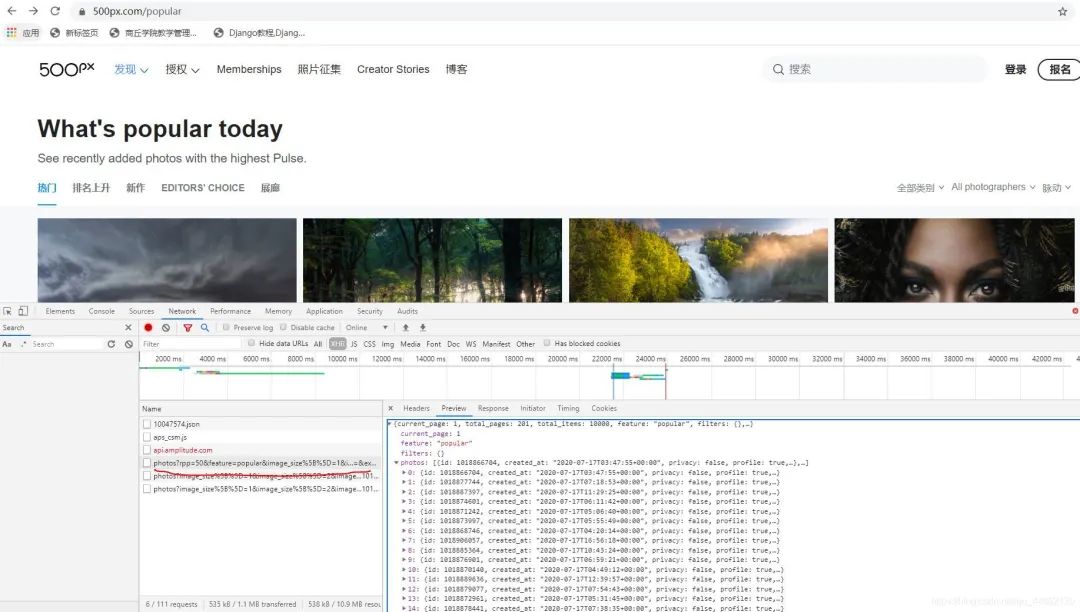
在这里找到了图片链接,向下拉动滚动条,这里会再次加载下一页的内容。
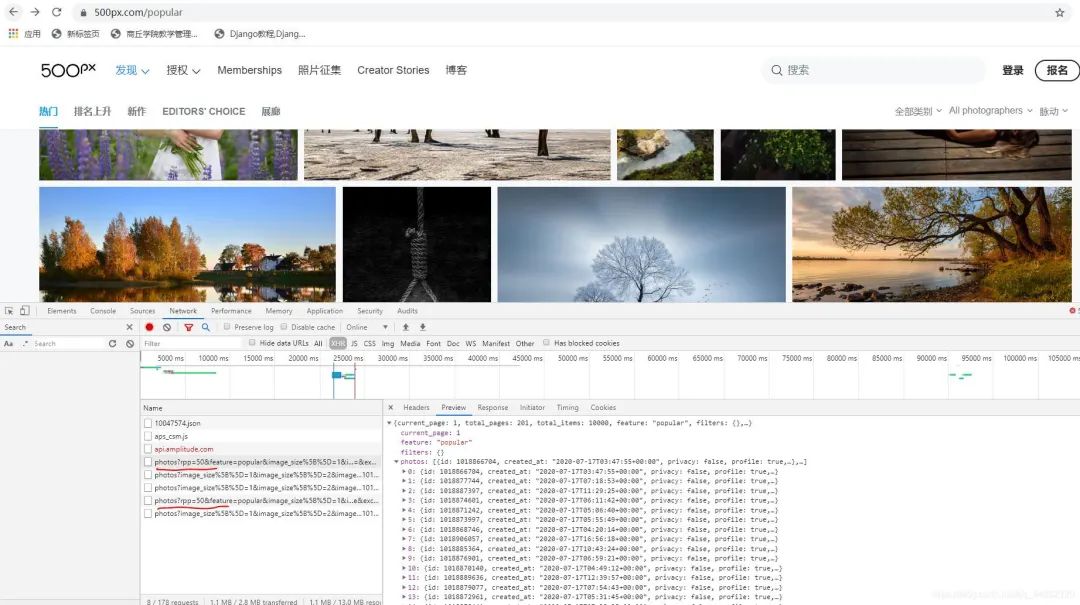
在这里找到了图片链接,向下拉动滚动条,这里会再次加载下一页的内容。
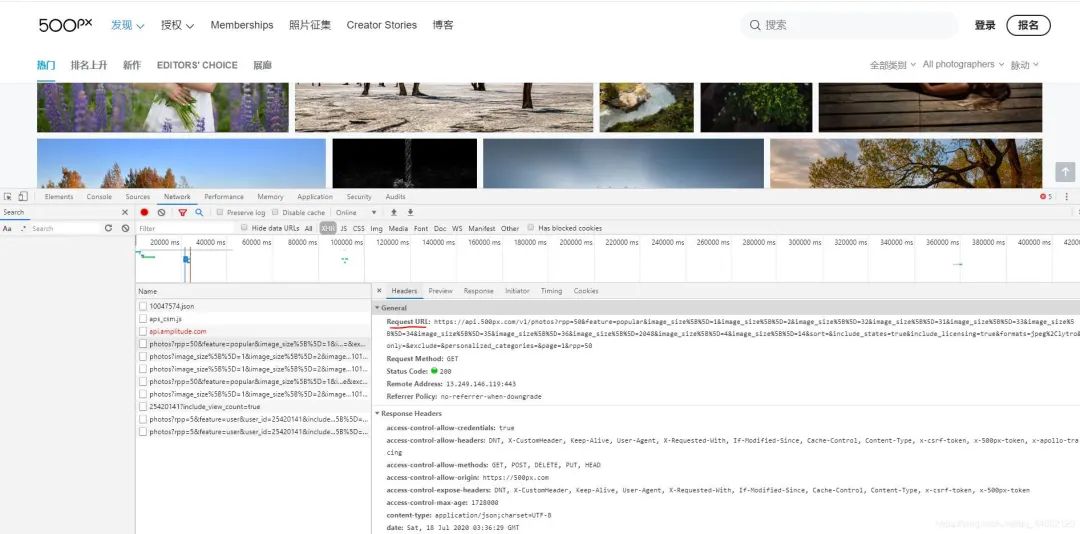
这个就是网页的真实URL链接。
复制下来这前几个地址进行分析:
第一个:https://api.500px.com/v1/photos?rpp=50&feature=popular&image_size%5B%5D=1&image_size%5B%5D=2&image_size%5B%5D=32&image_size%5B%5D=31&image_size%5B%5D=33&image_size%5B%5D=34&image_size%5B%5D=35&image_size%5B%5D=36&image_size%5B%5D=2048&image_size%5B%5D=4&image_size%5B%5D=14&sort=&include_states=true&include_licensing=true&formats=jpeg%2Clytro&only=&exclude=&personalized_categories=&page=1&rpp=50
第二个:https://api.500px.com/v1/photos?rpp=50&feature=popular&image_size%5B%5D=1&image_size%5B%5D=2&image_size%5B%5D=32&image_size%5B%5D=31&image_size%5B%5D=33&image_size%5B%5D=34&image_size%5B%5D=35&image_size%5B%5D=36&image_size%5B%5D=2048&image_size%5B%5D=4&image_size%5B%5D=14&sort=&include_states=true&include_licensing=true&formats=jpeg%2Clytro&only=All+photographers%2CPulse&exclude=&personalized_categories=&page=2&rpp=50
会发现第一页是:page=1,第二页是:page=2…但是还有其他地方些许不一样,但是经过验证是没出问题的,这就发现了每一页的规律。
反爬分析
同一个ip地址去多次访问会面临被封掉的风险,这里采用fake_useragent,产生随机的User-Agent请求头进行访问。
代码实现
1.导入相对应的第三方库,定义一个class类继承object,定义init方法继承self,主函数main继承self。
import requests
from fake_useragent import UserAgent
filename=0
class photo_spider(object):
def __init__(self):
self.url = 'https://api.500px.com/v1/photos?rpp=50&feature=popular&image_size%5B%5D=1&image_size%5B%5D=2&image_size%5B%5D=32&image_size%5B%5D=31&image_size%5B%5D=33&image_size%5B%5D=34&image_size%5B%5D=35&image_size%5B%5D=36&image_size%5B%5D=2048&image_size%5B%5D=4&image_size%5B%5D=14&sort=&include_states=true&include_licensing=true&formats=jpeg%2Clytro&only=&exclude=&personalized_categories=&page={}&rpp=50'
ua = UserAgent(verify_ssl=False)
#随机产生user-agent
for i in range(1, 100):
self.headers = {
'User-Agent': ua.random
}
def mian(self):
pass
if __name__ == '__main__':
spider = photo_spider()
spider.main()
2.发送请求,获取网页。
def get_html(self,url):
response=requests.get(url,headers=self.headers)
html=response.json()#动态加载的json数据
return html
3.获取图片的链接地址,保存图片格式到本地文件夹。
def get_imageUrl(self,html):
global filename
content_list=html['photos']
for content in content_list:
image_url=content['image_url']
#print(image_url[8])
imageUrl=image_url[8]
r=requests.get(imageUrl,headers=self.headers)
with open('F:/pycharm文件/photo/'+str(filename)+'.jpg','wb') as f:
f.write(r.content)
filename+=1
这里说明一下,imageUrl=image_url[8]这里由于有多个image-url。
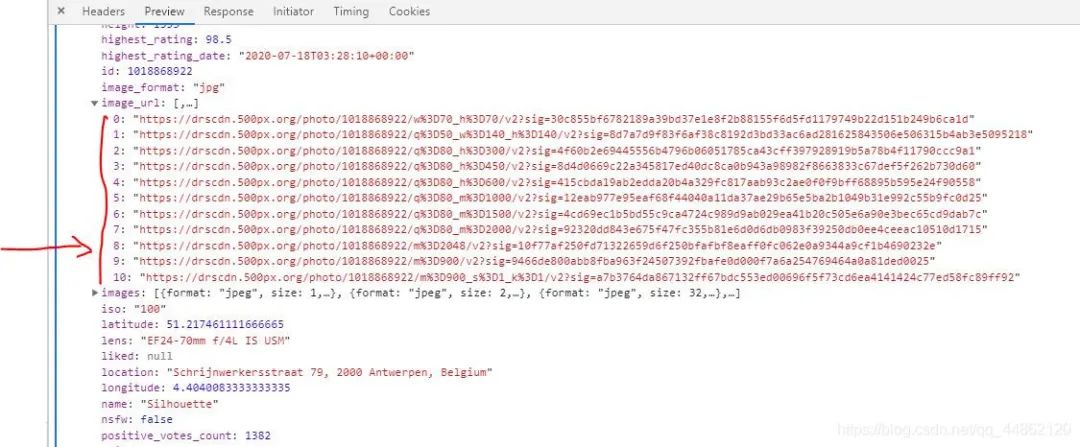
4.获取多页及函数调用。
def main(self):
start = int(input('输入开始页:'))
end = int(input('输入结束页:'))
for page in range(start, end + 1):
print('第%s页内容' % page)
url = self.url.format(page)#{}传入page即页码
html=self.get_html(url)
self.get_imageUrl(html)
print('第%s页爬取完成'%page)
运行结果
打开本地F:/pycharm文件/photo/

完整代码
import requests
from fake_useragent import UserAgent
filename=0
class photo_spider(object):
def __init__(self):
self.url = 'https://api.500px.com/v1/photos?rpp=50&feature=popular&image_size%5B%5D=1&image_size%5B%5D=2&image_size%5B%5D=32&image_size%5B%5D=31&image_size%5B%5D=33&image_size%5B%5D=34&image_size%5B%5D=35&image_size%5B%5D=36&image_size%5B%5D=2048&image_size%5B%5D=4&image_size%5B%5D=14&sort=&include_states=true&include_licensing=true&formats=jpeg%2Clytro&only=&exclude=&personalized_categories=&page={}&rpp=50'
ua = UserAgent(verify_ssl=False)
for i in range(1, 100):
self.headers = {
'User-Agent': ua.random
}
def get_html(self,url):
response=requests.get(url,headers=self.headers)
html=response.json()
return html
def get_imageUrl(self,html):
global filename
content_list=html['photos']
for content in content_list:
image_url=content['image_url']
#print(image_url[8])
imageUrl=image_url[8]
r=requests.get(imageUrl,headers=self.headers)
with open('F:/pycharm文件/photo/'+str(filename)+'.jpg','wb') as f:
f.write(r.content)
filename+=1
def main(self):
start = int(input('输入开始:'))
end = int(input('输入结束页:'))
for page in range(start, end + 1):
print('第%s页' % page)
url = self.url.format(page)
html=self.get_html(url)
self.get_imageUrl(html)
if __name__ == '__main__':
spider = photo_spider()
spider.main()评论