
Python爬虫实战:爬取一周的天气预报信息
作者:沐沐
来源:GOGO数据「ID: mu_science」


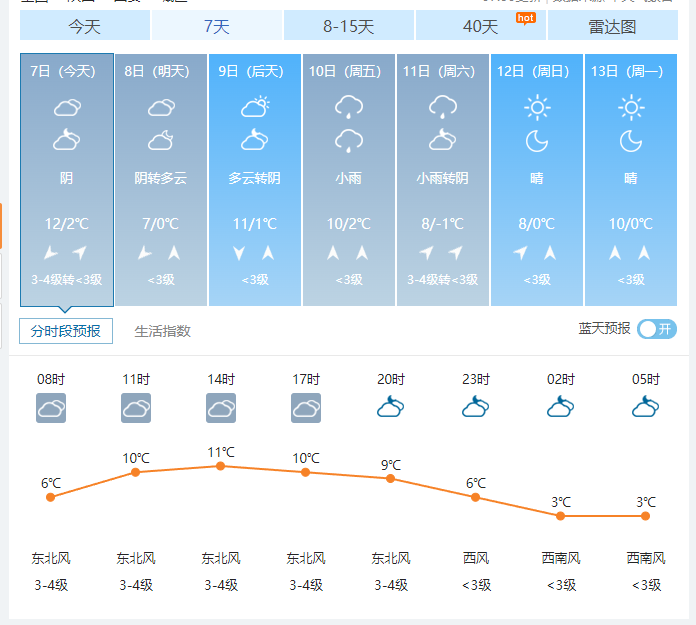
网页分析
今天我们要爬取的内容都在静态网页中,这种网站内容获取都很简单,我们分析出各个元素所在的位置,直接使用xpath获取即可

如何在浏览器中查找页面元素,可以参考之前的文章: 爬虫必备工具,掌握它就解决了一半的问题
代码实现
既然知道了我们要获取的信息所在标签,那么就开始爬取吧!
我们使用的是xpath提取数据。所以我们先来导入必要的库:
import requests
from icecream import ic
from lxml import etree注意:因为网页中含有中文字符,所以我们在下载网页源码之前先看下它的编码格式,输入当前网页的编码格式
print(res.encoding)
'''
ISO-8859-1
'''打印出来的汉字就是这种'7\xe6\x97\xa5\xef\xbc\x88\xe4\xbb'的乱码
所以就需要在此做编码解码处理,很烦~~
我们可以采取一种更简单的方法,直接让获取到的编码格式等于当前的编码格式,一行代码即可解决
# 乱码处理
resp.encoding = resp.apparent_encoding这样就可以获取到中文字符串了
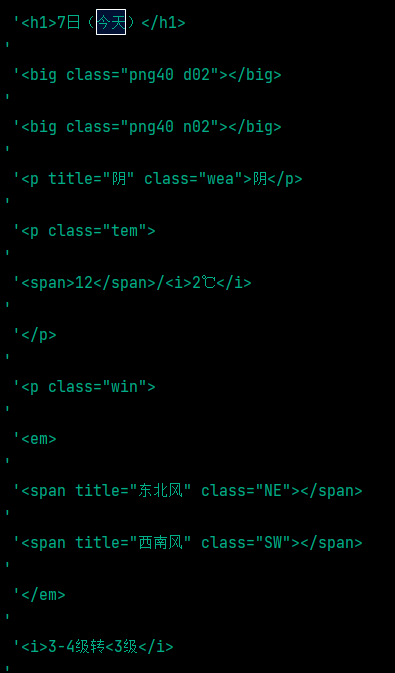
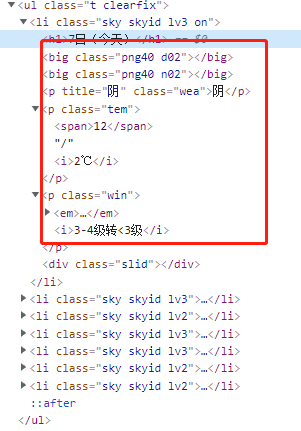
数据提取
因为每天的的天气信息都位于各自独立的li标签中,所以我们使用xpath先来提取到所有的li信息
html = etree.HTML(content)
uls = html.xpath("//div[@class='left-div'][1]/div[@id='7d']/ul/li")
print(len(uls))
'''
7
'''获取到所有的li信息,接下来我们提取内部天气、温度、日期、风力等具体信息
for ul in uls:
date = ul.xpath("//div[@class='left-div'][1]/div[@id='7d']/ul[@class='t clearfix']/li/h1/text()")
weather = ul.xpath("//li/p[@class='wea']/text()")
low_temp = ul.xpath("//li/p[@class='tem']/i/text()")
high_temp = ul.xpath("//li/p[@class='tem']/span/text()")
wind = ul.xpath("//li/p[@class='win']/i/text()")
'''
ic| date: ['7日(今天)', '8日(明天)', '9日(后天)', '10日(周五)', '11日(周六)', '12日(周日)', '13日(周一)']
weather: ['阴', '阴转多云', '多云转阴', '小雨', '小雨转阴', '晴', '晴']
high_temp: ['12', '7', '11', '10', '8', '8', '10']
low_temp: ['2℃', '0℃', '1℃', '2℃', '-1℃', '0℃', '0℃']
wind: ['3-4级转<3级', '<3级', '<3级', '<3级', '3-4级转<3级', '<3级', '<3级']
'''数据保存
数据成功打印,接下来我们尝试将数据保存在本地csv文件中
with open('西安天气.csv', 'a+', encoding='utf-8') as file:
for i in range(0, 7): # 一共有七组数据
file.write(date[i] + ':\t') # 日期
file.write(weather[i] + '\t') # 天气情况
file.write("最高气温:" + high_temp[i] + '\t') # 气温
file.write("最低气温:" + low_temp[i] + '\t') # 气温
file.write("风力:" + wind[i] + '\t') # 风力
file.write('\n')结果展示
结果展示如下:

以上就是通过Python爬虫获取一周天气预报的全过程。整个过程没有特别难的技术点,也没有很复杂的反爬处理,所以还是比较适合刚刚学习爬虫的同学进行练习。核心代码都已在文中给出,不过爬虫的代码经常会因为被爬取网站的更新而失效,所以时间久了有可能需要根据实际情况做调整。但只要掌握了原理,方法都是类似的。建议大家自己动手试一试。
如果文章对你有帮助,欢迎转发/点赞/收藏~
_往期文章推荐_
我在Python的艳阳里,大雪纷飞
如需了解付费精品课程及教学答疑服务 请在Crossin的编程教室内回复: 666
评论