用 Python 爬取网页
点击上方“python入门与进阶”,关注并“星标
每日接收Python干货!
作为数据科学家的第一个任务,就是做网页爬取。那时候,我对使用代码从网站上获取数据这项技术完全一无所知,它偏偏又是最有逻辑性并且最容易获得的数据来源。在几次尝试之后,网页爬取对我来说就几乎是种本能行为了。如今,它更成为了我几乎每天都要用到的少数几个技术之一。
在今天的文章中,我将会用几个简单的例子,向大家展示如何爬取一个网站——比如从 Fast Track 上获取 2018 年 100 强企业的信息。用脚本将获取信息的过程自动化,不但能节省手动整理的时间,还能将所有企业数据整理在一个结构化的文件里,方便进一步分析查询。
太长不看版:如果你只是想要一个最基本的 Python 爬虫程序的示例代码,本文中所用到的全部代码都放在 GitHub (https://github.com/kaparker/tutorials/blob/master/pythonscraper/websitescrapefasttrack.py),欢迎自取。
准备工作
每一次打算用 Python 搞点什么的时候,你问的第一个问题应该是:“我需要用到什么库”。
网页爬取方面,有好几个不同的库可以用,包括:
Beautiful Soup
Requests
Scrapy
Selenium
今天我们打算用 Beautiful Soup 库。你只需要用 pip(Python包管理工具)就能很方便地将它装到电脑上:

安装完毕之后,我们就可以开始啦!
检查网页
为了明确要抓取网页中的什么元素,你需要先检查一下网页的结构。
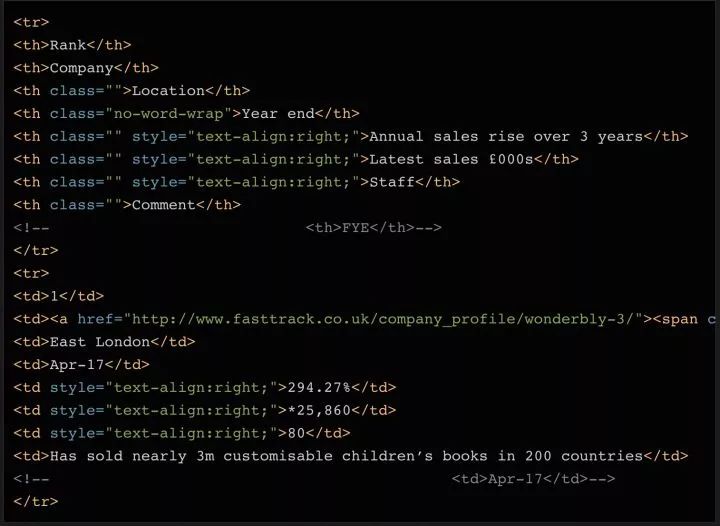
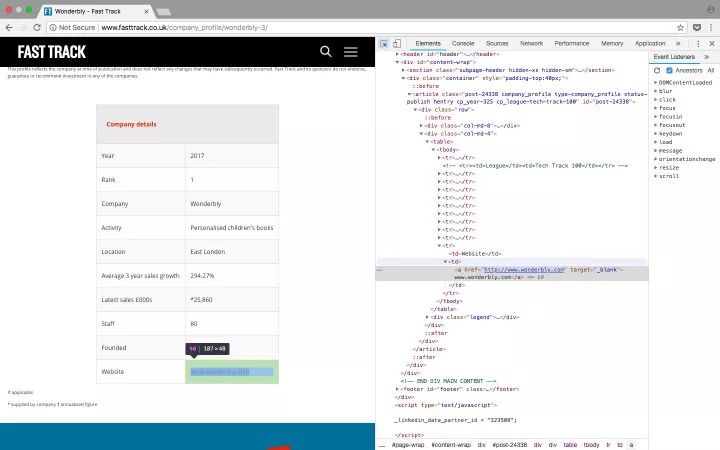
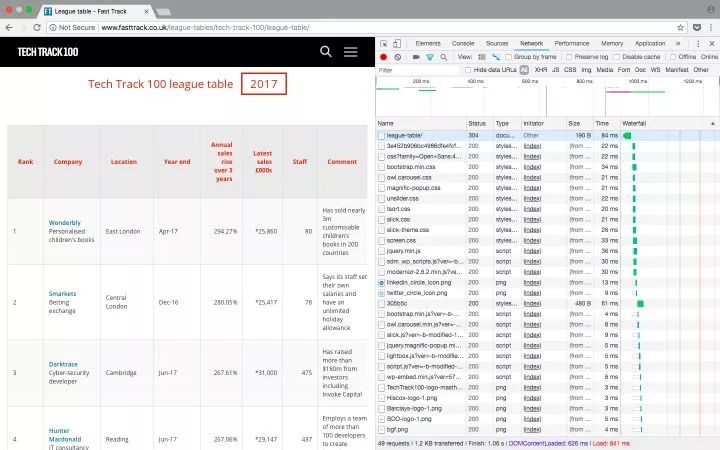
以 Tech Track 100强企业(https://link.zhihu.com/?target=http%3A//www.fasttrack.co.uk/league-tables/tech-track-100/league-table/) 这个页面为例,你在表格上点右键,选择“检查”。在弹出的“开发者工具”中,我们就能看到页面中的每个元素,以及其中包含的内容。
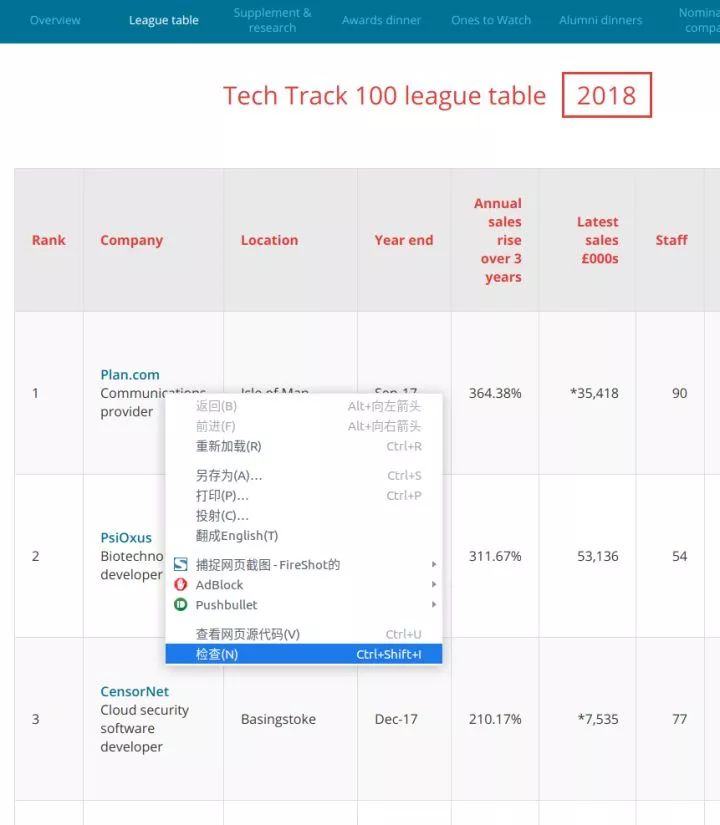
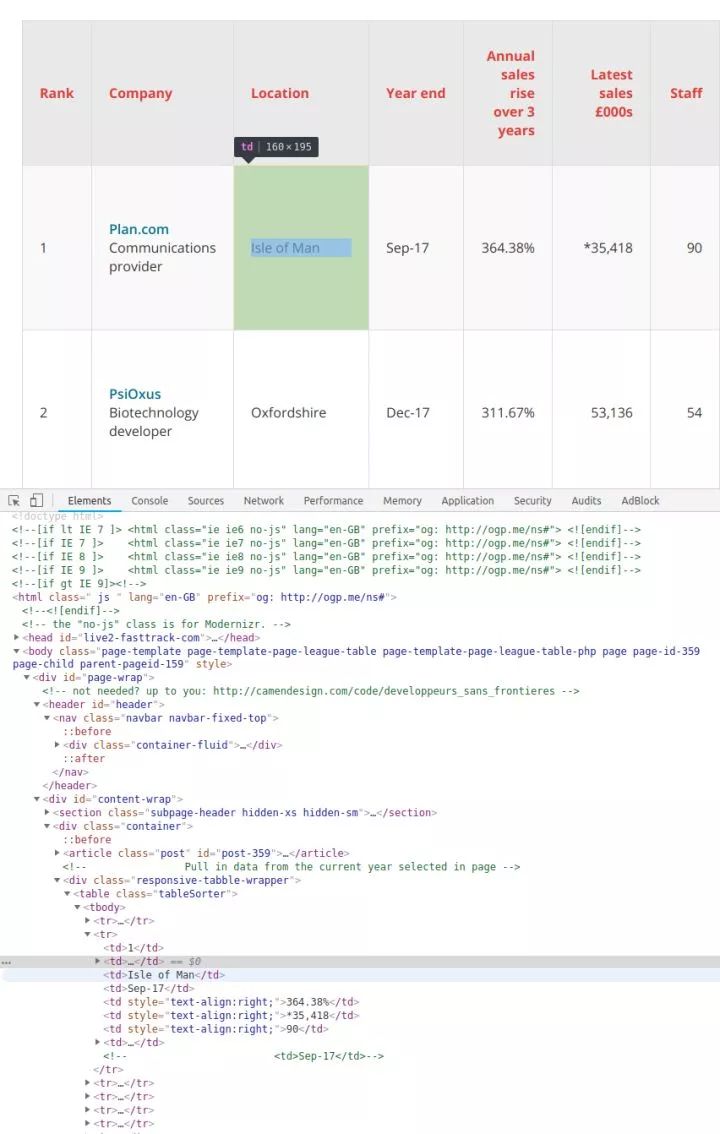
右键点击你想要查看的网页元素,选择“检查”,就能看到具体的 HTML 元素内容
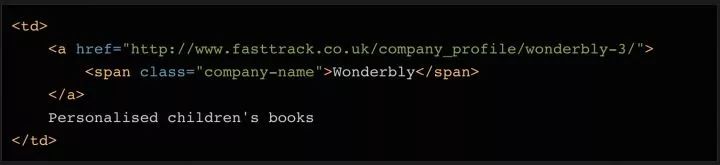
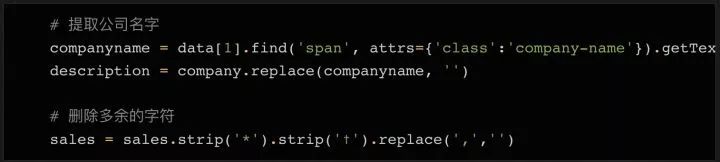
既然数据都保存在表格里,那么只需要简单的几行代码就能直接获取到完整信息。如果你希望自己练习爬网页内容,这就是一个挺不错的范例。但请记住,实际情况往往不会这么简单。
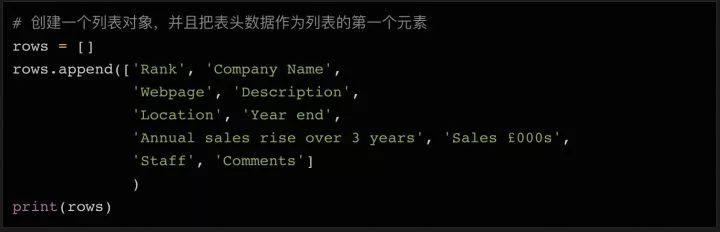
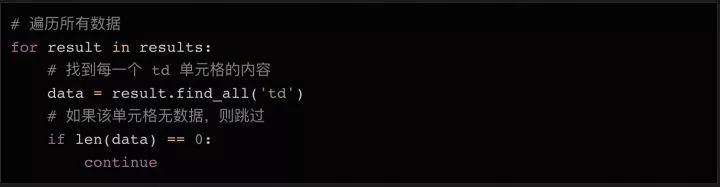
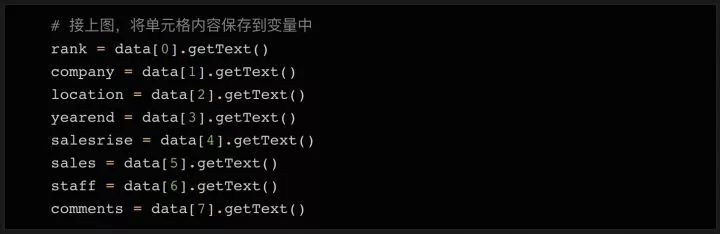
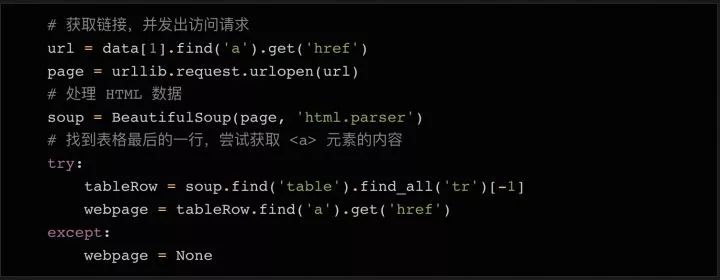
这个例子里,所有的100个结果都包含在同一个页面中,还被 在表格页面上,你可以看到一个包含了所有100条数据的表格,右键点击它,选择“检查”,你就能很容易地看到这个 HTML 表格的结构。包含内容的表格本体是在这样的标签里: 每一行都是在一个 用 Beautiful Soup 库处理网页的 HTML 内容 在熟悉了网页的结构,了解了需要抓取的内容之后,我们终于要拿起代码开工啦~ 首先要做的是导入代码中需要用到的各种模块。上面我们已经提到过 下一步我们需要准备好需要爬取的目标网址。正如上面讨论过的,这个网页上已经包含了所有我们需要的内容,所以我们只需要把完整的网址复制下来,赋值给变量就行了: 接下来,我们就可以用 这时候,你可以试着把 如果变量内容是空的,或者返回了什么错误信息,则说明可能没有正确获取到网页数据。你也许需要用一些错误捕获代码,配合 urllib.error (https://docs.python.org/3/library/urllib.error.html)模块,来发现可能存在的问题。 既然所有的内容都在表格里( 标签分隔成行。但实际抓取过程中,许多数据往往分布在多个不同的页面上,你需要调整每页显示的结果总数,或者遍历所有的页面,才能抓取到完整的数据。 
标签里,也就是我们不需要太复杂的代码,只需要一个循环,就能读取到所有的表格数据,并保存到文件里。 附注:你还可以通过检查当前页面是否发送了 HTTP GET 请求,并获取这个请求的返回值,来获取显示在页面上的信息。因为 HTTP GET 请求经常能返回已经结构化的数据,比如 JSON 或者 XML 格式的数据,方便后续处理。你可以在开发者工具里点击 Network 分类(有必要的话可以仅查看其中的 XHR 标签的内容)。这时你可以刷新一下页面,于是所有在页面上载入的请求和返回的内容都会在 Network 中列出。此外,你还可以用某种 REST 客户端(比如 Insomnia)来发起请求,并输出返回值。
BeautifulSoup,这个模块可以帮我们处理 HTML 结构。接下来要导入的模块还有 urllib,它负责连接到目标地址,并获取网页内容。最后,我们需要能把数据写入 CSV 文件,保存在本地硬盘上的功能,所以我们要导入 csv库。当然这不是唯一的选择,如果你想要把数据保存成 json 文件,那相应的就需要导入 json 库。

urllib 连上这个URL,把内容保存在 page 变量里,然后用 BeautifulSoup 来处理页面,把处理结果存在 soup 变量里:
soup 变量打印出来,看看里面已经处理过的 html 数据长什么样:
查找 HTML 元素