
深度学习的实时面部姿势估计研究
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

面部识别是深度学习的蓬勃发展的应用。从电话到机场摄像头,无论是在商业上还是在研究领域,该行业都得到了迅速的普及。当我们将其与姿势估计相结合时,我们将获得非常强大的功能。
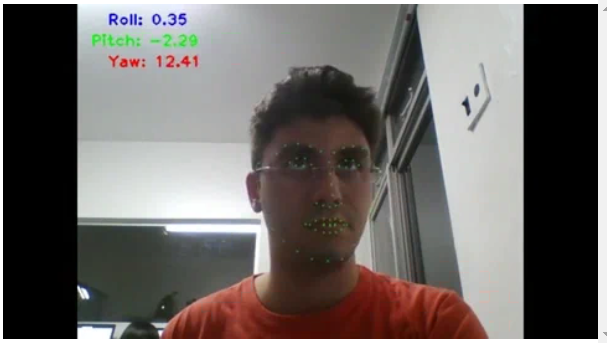
由于人的脸部是立体对象,因此它可以在所有三个轴上旋转-当然有一些限制。在人脸姿势估计问题中,我们将这些运动称为侧倾,俯仰和偏航,如下图所示:

估计这些姿势对于活动检测系统非常有用。例如,它可能会要求用户执行一些预定义的随机运动(例如,“将您的脸向右旋转”)以检查其活动状况。
对于这个问题,我们创建了一个数据库,其中包含来自不同面部数据集的6,288张图像。对于每个图像,我们使用Dlib检测面部标志,并计算所有点之间的成对欧几里德距离。因此,给定68点,我们最终得到(68 * 67)/ 2 = 2,278个特征。每个面孔的侧倾,俯仰和偏航都由Amazon的Face Detection API标记。

现在,可以训练我们的模型了。我们将Keras用于此步骤。在C ++应用程序中使用它。经过几次尝试,我最终得到以下配置:

强调一些有关我们的模型架构的细节:
1. 强大的正则化:由于我们具有许多功能,因此我的网络中很少提供正则化类型,以防止过度拟合和处理维数的限制。首先,所有层都具有L2正则化,因为我们不希望模型对某些功能过分注重视,尤其是在第一层中。另外,模型的架构本身是一种正则化。它遵循自动编码器的模式,其中每个层的神经元数量少于以前的数量,以“迫使”网络学习相关信息并忽略不相关的信息。
2. 我们本可以在第一层中使用L1正则化来迫使网络忽略不必要的功能(因为这种正则化往往会将与此类信息相关的权重设置为零)。但是,由于已经对网络进行了严格的规范化,因此在我们的测试中,L2正则化也略胜一筹。
这是训练了100个时间段后的损失图表:
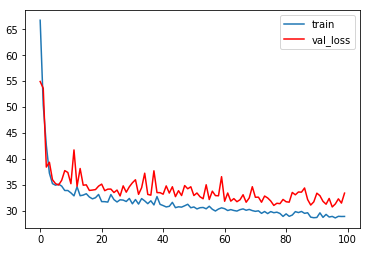
如图所示,在数据集上,我们的模型取得了不错的结果。该图还遵循训练深度学习模型时预期的模式。由于我们使用MSE作为损失函数,因此我们可以估计模型的误差为±6º。
在下图中,我们可以看到测试集中每个点的实际角度和预测角度之间的差异。我们可以看到,偏航是最容易预测的,其次分别是侧倾和俯仰。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~