
基于TensorFlow卷积神经网络与MNIST数据集设计手写数字识别算法
TensorFlow随着数字化的普及和信息技术的发展,在编号处理、数量读取、价格统计等场合,手写数字识别系统的应用需求越来越强烈,如何将数字方便、快速地输入到计算机中已成为关系到计算机技术普及的关键问题。数字识别技术的研究不仅可以解决当下面临的数字识别问题,同时在图像识别、机器学习等方面也有铺垫作用。由于手写数字识别难于建立精确的数学模型,本文基于TensorFlow卷积神经网络设计手写数字识别算法,导入MNIST数据集进行训练,并测试网络模型的识别准确率。
TensorFlow是一个基于Python和基于数据流编程的机器学习框架,由谷歌基于DistBelief进行研发,并在图形分类、音频处理、推荐系统和自然语言处理等场景下有着丰富的应用。2015年11月9日,TensorFlow依据Apache 2.0 开源协议开放源代码。
TensorFlow具有灵活的架构,可部署于各类服务器、PC终端、移动设备和网页并支持GPU和TPU高性能数值计算,提供了各类主流编程语言的API。
数据流图中用“结点”(nodes)和“线”(edges)的有向图来描述数学计算。这些数据“线”可以输运“size可动态调整”的多维数据数组,即“张量”(tensor)。张量从图中流过的直观图像是这个工具取名为“TensorFlow”的原因。一旦输入端的所有张量准备好,节点将被分配到各种计算设备完成异步并行地执行运算。
Tensor和Flow是TensorFlow最为基础的要素。Tensor意味着data;Flow意味着流动,意味着计算,意味着映射,即数据的流动,数据的计算,数据的映射,同时也体现数据是有向的流动、计算和映射。
MNISTMNIST是一个经典的计算机视觉数据集,来自美国国家标准与技术研究所(NIST),由纽约大学的Yann LeCun教授主导建立。
MNIST数据集由250个不同的人手写而成,包含各种手写数字图片,以及每一张图片对应的数值标签。它包含60000个训练样本和10000个测试样本,每个样本都是一张28 * 28像素的灰度手写数字图片,存储在28 * 28的二维数组中。
MNIST数据集在深度学习中的地位,就像Hello,World!在编程中的地位。
自建立以来,它便被广泛应用于检验各种机器学习算法、测试各种模型,为机器学习的发展做出了不可磨灭的贡献,其当之无愧为历史上最伟大的数据集之一。
MNIST数据集已经被集成在Keras中,可以直接使用keras.datasets来访问。
环境安装与数据集(1)环境信息
- Python 3.81. Visual C++库1. Conda包管理工具
(2)查看NVIDIA驱动版本
nvidia-smi
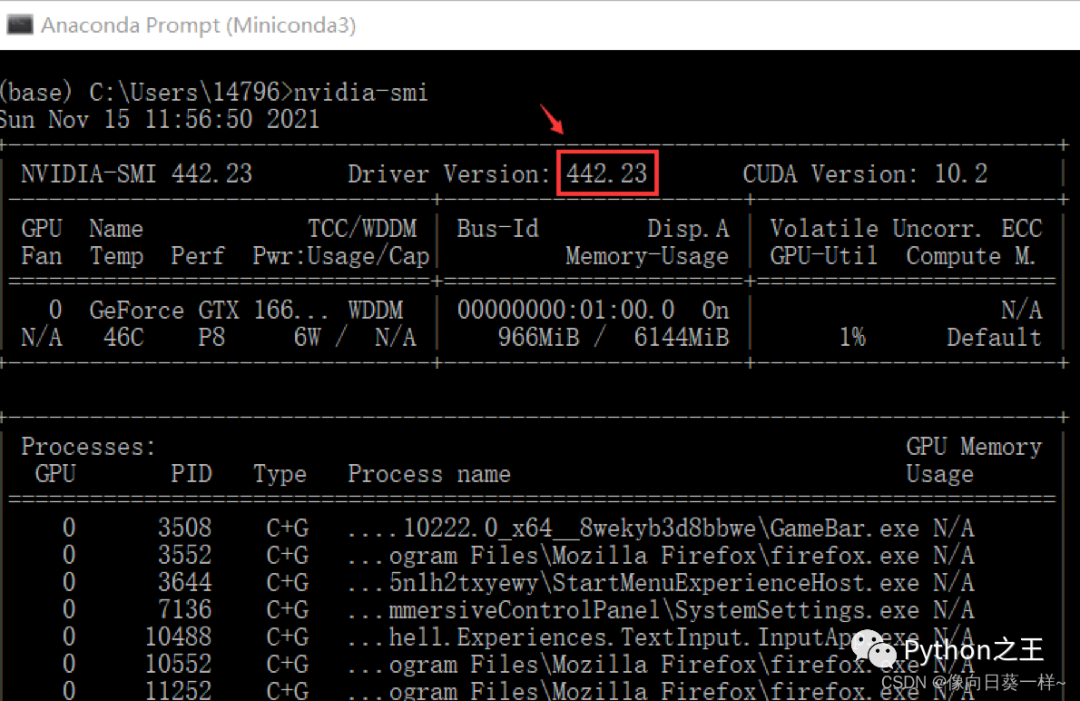
电脑的NVIDIA驱动版本高于418.x,故可以安装GPU版本。
(3)GPU版本的依赖库安装
- 安装CUDA Toolkit
conda install cudatoolkit=10.1
(之前已经安装好了)
2.安装cuDNN库
conda install cudnn=7.6.5
(4)Conda配置文件
(5)下载安装tensorflow-gpu
pip install tensorflow-gpu -i https://pypi.douban.com/simple
(6)安装matplotlib和jupyter notebook
pip install matplotlib notebook -i https://pypi.douban.com/simple
(7)使用可视化终端
jupyter notebook
- 查看Tensorflow版本
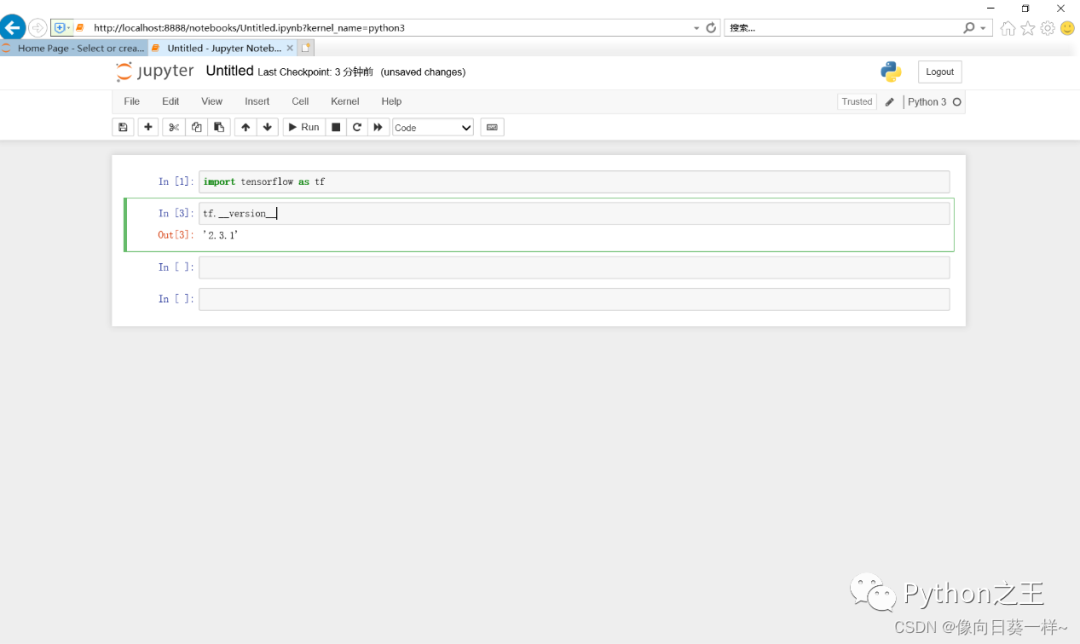
安装版本是2.3.1。
2.测试GPU版本是否正确安装
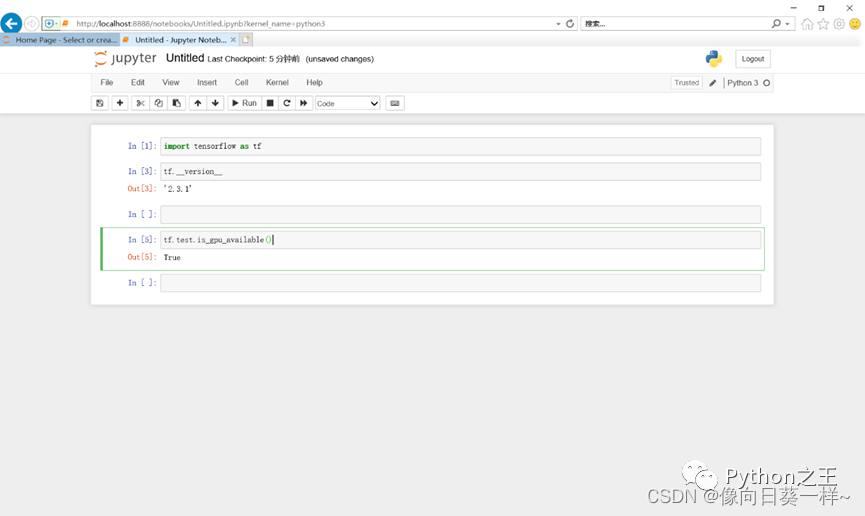
结果为True,安装正确。
算法原理与设计(1)加载MNIST数据
(2)定义变量
- 定义占位符placeholder
通过shape参数,TensorFlow能够自动捕捉因数据维度不一致导致的错误。
2.定义权重和偏置Variable
(3)构建多层卷积网络
整个网络由两个卷积层(包含激活层和池化层),一个全连接层,一个Dropout层和一个Softmax层组成。
** 1.权重初始化**
** 2.卷积和池化 **
卷积是提取特征的过程。将输入图片,处理就很困难。
池化来把卷积结果进行压缩,进一步减少全连接时的连接数。这里采用最大池化,在选中区域中找最大的值作为抽样后的值。
3.密集连接层
Reshape为向量,建立第一个全连接层。
** 4.Dropout层**
** 5.Softmax层**
** 6.训练和评估模型**
计算交叉熵、梯度下降法、精确度计算。再使用Saver,将训练的权重和偏置保存下来,在评价程序中可以再次使用。最后训练100次,进行验证。
使用过程(1)测试Tensorflow是否安装成功、MNIST数据集是否可以成功调用
** 1.下载MNIST数据集**
#导入tensorflow库
import tensorflow as
#mnist数据集的完整前缀和名称
mnist=tf.keras.datasets.mnist
#使用minist数据集的load_data( )加载数据集
(train_ x,train y), (test_ x,test_ y) = mnist.load_data( )
#在第一次执行时本地磁盘中没有这个数据集会自动的通过网络下载,并显示地址和进度。

** 2.训练集和测试集的长度**
print("Training set:",len(train_ x))
print(" Testing set:",len(test X))

** 3.输出图像数据和标记数据的形状**
print("train_ x:",train_ x. shape, train_x.dtype)
print("train_ y:",train_y. shape, train_ y.dtype)

图像数据是一个三维数组,有60000个样本,每一个样本是一个28 * 28的二维数组,是8位无符号整数。
标签是一个一维数组,对应60000个数据值,是8位无符号整数。
4.输出数据集中的第一个样本
train_x[0]
大量的0,其中不为0的表示笔画。
5.显示图片
导入matplotlib内的pyplot方法
import matplotlib.pyplot as plt
plt.axis("off")
用imshow方法来显示图片,参数为数据集的第一个样本
plt.imshow(train_x[0],cmap='gray')
plt.show

train_y[0]

输出这个图片的标签,结果是5,表明这个图像是数字。
6.测试
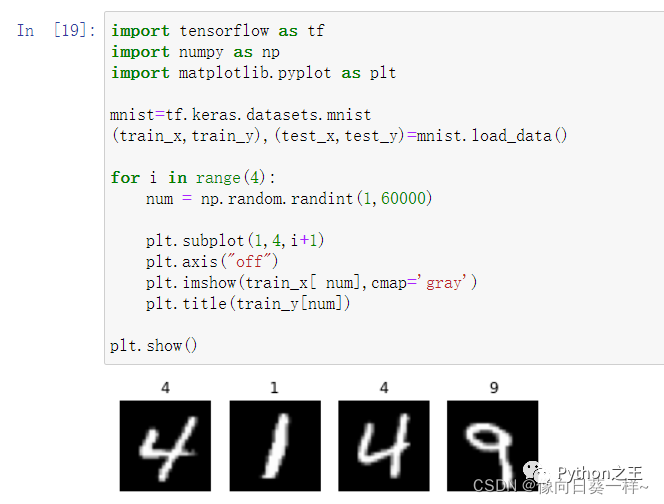
随机显示4幅手写数字图片:
#循环四次
for i in range(4):
#随机产生一个1到60000之间的整数,作为样本的索引值
num=np.random.randint(1,60000)
#将画布划分为一行四列的四个子图局域,依次绘制子图
plt.subplot(1,4,i+1)
plt.axis("off")
#imshow函数显示图像,参数为训练集中随机生成的样本
plt.imshow(train_x[num],cmap=gray’)
#将图像的标签显示在子图标题位置
plt.title(train_y[num])
#显示整个绘图
plt.show()
测试结果:
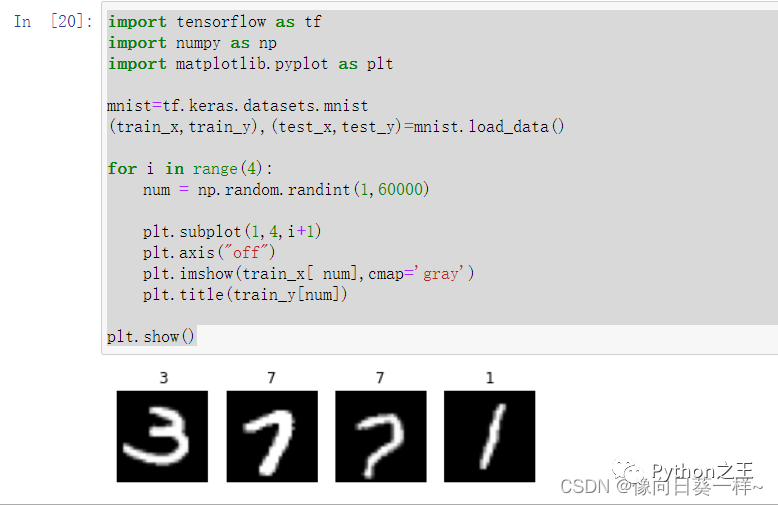
第二次测试结果:
(2)创建MNIST数据集模型
用于导入MNIST数据集-创建模型-保存模型到指定路径。
(1)源代码:
** 1.创建MNIST数据集模型**
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
mnist = input_data.read_data_sets(r'D:\All_Downloads\TIM_Downloads\AI\MNIST_data', one_hot=True) #MNIST数据集所在路径
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev = 0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1,shape = shape)
return tf.Variable(initial)
def conv2d(x,W):
return tf.nn.conv2d(x, W, strides = [1,1,1,1], padding = 'SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x,[-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
saver = tf.train.Saver() #定义saver
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(20000):
batch = mnist.train.next_batch(50)
if i % 100 == 0:
train_accuracy = accuracy.eval(feed_dict={
x: batch[0], y_: batch[1], keep_prob: 1.0})
print('step %d, training accuracy %g' % (i, train_accuracy))
train_step.run(feed_dict={x: batch[0], y_: batch[1], keep_prob: 0.5})
saver.save(sess, 'D:/All_Downloads/TIM_Downloads/AI/MNISTDataModel/model.ckpt') #模型储存位置
print('test accuracy %g' % accuracy.eval(feed_dict={
x: mnist.test.images, y_: mnist.test.labels, keep_prob: 1.0}))
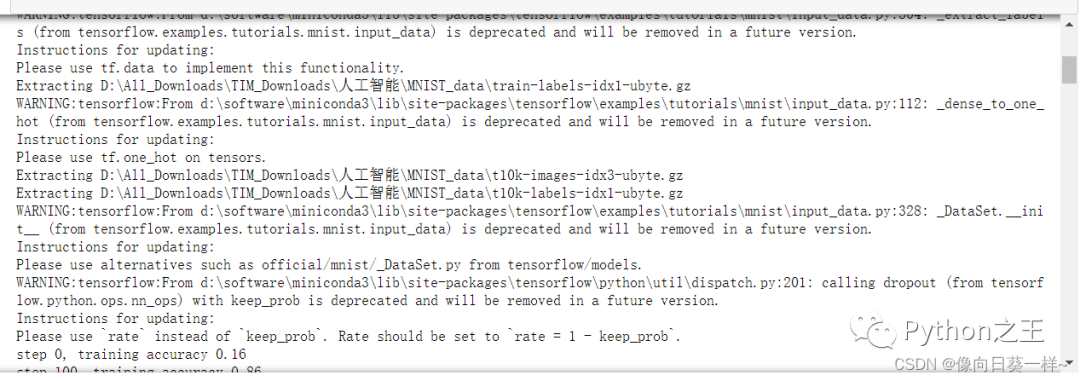
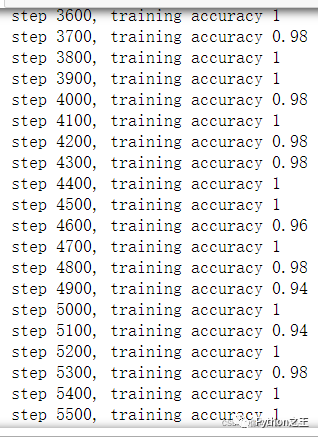
** 2.运行结果**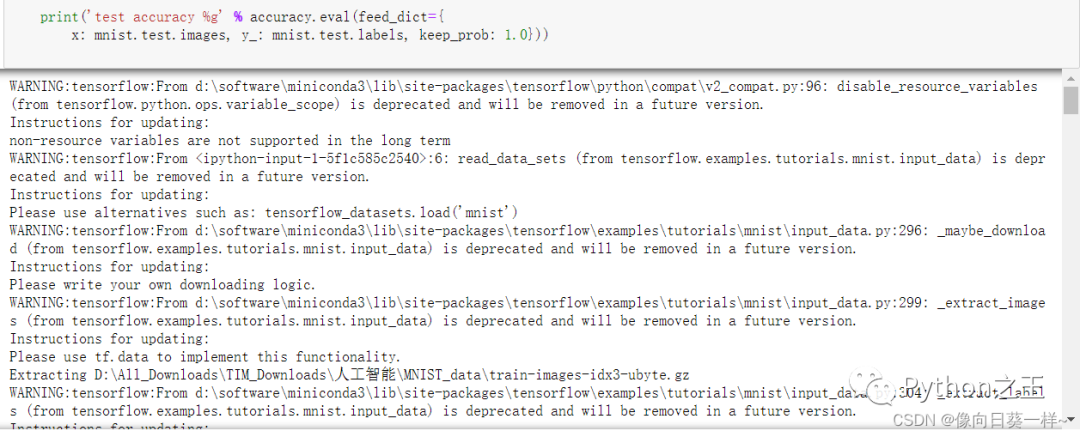


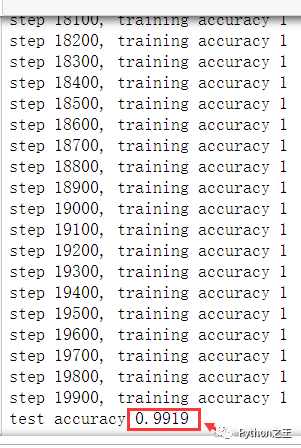
生成的模型准确率高达99.19%。
(3)测试刚创建的模型
1.源代码
from PIL import Image, ImageFilter
import tensorflow.compat.v1 as tf
tf.disable_v2_behavior()
import matplotlib.pyplot as plt
import time
def imageprepare():
"""
This function returns the pixel values.
The imput is a png file location.
"""
file_name='C:/Users/14796/Tensorflow_DataSet/MNIST/4.png'#导入自己的图片地址
#in terminal 'mogrify -format png *.jpg' convert jpg to png
im = Image.open(file_name)
plt.imshow(im)
plt.show()
im = im.convert('L')
im.save("C:/Users/14796/Tensorflow_DataSet/MNIST/sample.png")
tv = list(im.getdata()) #get pixel values
#normalize pixels to 0 and 1. 0 is pure white, 1 is pure black.
tva = [ (255-x)*1.0/255.0 for x in tv]
print(tva)
return tva
"""
This function returns the predicted integer.
The imput is the pixel values from the imageprepare() function.
"""
# Define the model (same as when creating the model file)
result=imageprepare()
x = tf.placeholder(tf.float32, [None, 784])
y_ = tf.placeholder(tf.float32, [None, 10])
def weight_variable(shape):
initial = tf.truncated_normal(shape,stddev = 0.1)
return tf.Variable(initial)
def bias_variable(shape):
initial = tf.constant(0.1,shape = shape)
return tf.Variable(initial)
def conv2d(x,W):
return tf.nn.conv2d(x, W, strides = [1,1,1,1], padding = 'SAME')
def max_pool_2x2(x):
return tf.nn.max_pool(x, ksize=[1,2,2,1], strides=[1,2,2,1], padding='SAME')
W_conv1 = weight_variable([5, 5, 1, 32])
b_conv1 = bias_variable([32])
x_image = tf.reshape(x,[-1,28,28,1])
h_conv1 = tf.nn.relu(conv2d(x_image,W_conv1) + b_conv1)
h_pool1 = max_pool_2x2(h_conv1)
W_conv2 = weight_variable([5, 5, 32, 64])
b_conv2 = bias_variable([64])
h_conv2 = tf.nn.relu(conv2d(h_pool1, W_conv2) + b_conv2)
h_pool2 = max_pool_2x2(h_conv2)
W_fc1 = weight_variable([7 * 7 * 64, 1024])
b_fc1 = bias_variable([1024])
h_pool2_flat = tf.reshape(h_pool2, [-1, 7*7*64])
h_fc1 = tf.nn.relu(tf.matmul(h_pool2_flat, W_fc1) + b_fc1)
keep_prob = tf.placeholder("float")
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
W_fc2 = weight_variable([1024, 10])
b_fc2 = bias_variable([10])
y_conv=tf.nn.softmax(tf.matmul(h_fc1_drop, W_fc2) + b_fc2)
cross_entropy = -tf.reduce_sum(y_*tf.log(y_conv))
train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
correct_prediction = tf.equal(tf.argmax(y_conv,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
saver.restore(sess, "SAVE/model.ckpt") #使用模型
#print ("Model restored.")
prediction=tf.argmax(y_conv,1)
predint=prediction.eval(feed_dict={x: [result],keep_prob: 1.0}, session=sess)
print(h_conv2)
print('识别结果:')
print(predint[0])
** 2.测试图片**
3.运行结果
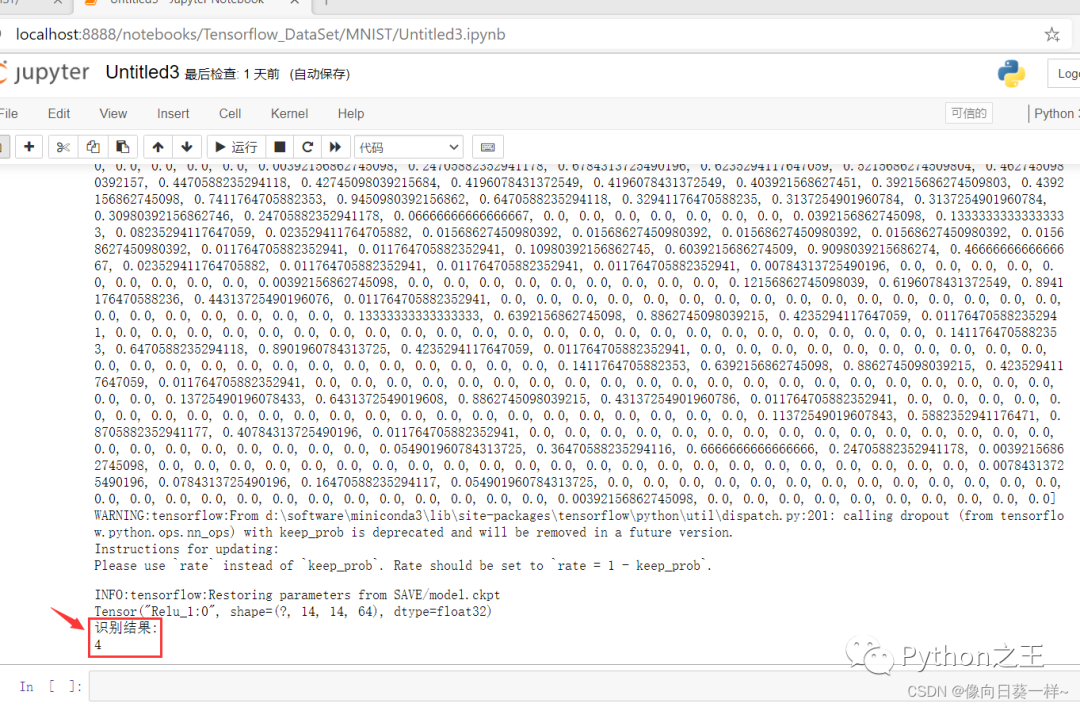
识别结果为4,与测试图片内容一致,识别正确。
总结手写数字识别是模式识别中一个非常重要和活跃的研究领域,数字识别也不是一项孤立的技术,他涉及的问题是模式识别的其他领域都无法回避的;应用上,作为一种信息处理手段,字符识别有广阔的应用背景和巨大的市场需求。因此,对数字识别的研究具有理论和应用的双重意义。
手写数字识别在邮政编码、统计报表、财务报表、快递分拣、银行票据等处理大量字符信息录入的场合中具有广泛应用。另外,图像识别技术的研究为人工智能开启了里程碑,在机器学习、机器人研究等方面起到了关键的作用。这方面的研究很有实用价值,重要性也是不言而喻的。