
使用OpenCV对运动员的姿势进行检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
如今,体育运动的热潮日益流行。同样,以不正确的方式进行运动的风险也在增加。有时可能会导致严重的伤害。考虑到这些原因,提出一种以分析运动员的关节运动,来帮助运动员纠正姿势的解决方案。
人体姿势估计是计算机视觉领域的重要问题。它的算法有助于定位手腕,脚踝,膝盖等部位。这样做是为了使用深度学习和卷积神经网络的概念提供个性化的运动训练体验。特别是对于体育活动而言,训练质量在很大程度上取决于图像或视频序列中人体姿势的正确性。
从图像或视频序列中检测运动员的姿势
数据集
正确选择数据集以对结果产生适当影响也是非常必要的。在此姿势检测中,模型在两个不同的数据集即COCO关键点数据集和MPII人类姿势数据集上进行了预训练。
1. COCO:COCO关键点数据集是一个多人2D姿势估计数据集,其中包含从Flickr收集的图像。迄今为止,COCO是最大的2D姿势估计数据集,并被视为测试2D姿势估计算法的基准。COCO模型有18种分类。COCO输出格式:鼻子— 0,脖子—1,右肩—2,右肘—3,右手腕—4,左肩—5,左手肘—6,左手腕—7,右臀部—8,右膝盖—9,右脚踝—10,左臀部—11,左膝—12,左脚踝—13,右眼—14,左眼—15,右耳—16,左耳—17,背景—18
2. MPII:MPII人体姿势数据集是一个多人2D姿势估计数据集,包含从Youtube视频中收集的近500种不同的人类活动。MPII是第一个包含各种姿势范围的数据集,也是第一个在2014年发起2D姿势估计挑战的数据集。MPII模型输出15分。MPII输出格式:头—0,脖子—1,右肩—2,右肘—3,右腕—4,左肩—5,左肘—6,左腕—7,右臀部—8,右膝盖—9,右脚踝—10,左臀部—11,左膝盖—12,左脚踝—13,胸部—14,背景—15

这些点是在对数据集进行处理并通过卷积神经网络(CNN)进行全面训练时生成的。
具体步骤
步骤1:需求收集(模型权重)和负载网络
训练有素的模型需要加载到OpenCV中。这些模型在Caffe深度学习框架上进行了训练。Caffe模型包含两个文件,即.prototxt文件和.caffemodel文件。
.prototxt文件指定了神经网络的体系结构。
.caffemodel文件存储训练后的模型的权重。
然后我们将这两个文件加载到网络中。
# Specify the paths for the 2 filesprotoFile = "pose/mpi/pose_deploy_linevec_faster_4_stages.prototxt"weightsFile = "pose/mpi/pose_iter_160000.caffemodel"# Read the network into Memorynet = cv2.dnn.readNetFromCaffe(protoFile, weightsFile)
步骤2:读取图像并准备输入网络
首先,我们需要使用blobFromImage函数将图像从OpenCV格式转换为Caffe blob格式,以便可以将其作为输入输入到网络。这些参数将在blobFromImage函数中提供。由于OpenCV和Caffe都使用BGR格式,因此无需交换R和B通道。
# Read imageframe = cv2.imread("image.jpg")# Specify the input image dimensionsinWidth = 368inHeight = 368# Prepare the frame to be fed to the networkinpBlob = cv2.dnn.blobFromImage(frame, 1.0 / 255, (inWidth, inHeight), (0, 0, 0), swapRB=False, crop=False)# Set the prepared object as the input blob of the networknet.setInput(inpBlob)
步骤3:做出预测并解析关键点
一旦将图像传递到模型,就可以使用OpenCV中DNN类的正向方法进行预测,该方法通过网络进行正向传递,这只是说它正在进行预测的另一种方式。
output = net.forward()输出为4D矩阵:
第一个维度是图片ID(如果您将多个图片传递到网络)。
第二个维度指示关键点的索引。该模型会生成置信度图(在图像上的概率分布,表示每个像素处关节位置的置信度)和所有已连接的零件亲和度图。对于COCO模型,它由57个部分组成-18个关键点置信度图+ 1个背景+ 19 * 2个部分亲和度图。同样,对于MPI,它会产生44点。我们将仅使用与关键点相对应的前几个点。
第三维是输出图的高度。
第四个维度是输出图的宽度。
然后,我们检查图像中是否存在每个关键点。我们通过找到关键点的置信度图的最大值来获得关键点的位置。我们还使用阈值来减少错误检测。

置信度图
一旦检测到关键点,我们便将其绘制在图像上。
H = out.shape[2]W = out.shape[3]# Empty list to store the detected keypointspoints = []for i in range(len()):# confidence map of corresponding body's part.probMap = output[0, i, :, :]# Find global maxima of the probMap.minVal, prob, minLoc, point = cv2.minMaxLoc(probMap)# Scale the point to fit on the original imagex = (frameWidth * point[0]) / Wy = (frameHeight * point[1]) / Hif prob > threshold :cv2.circle(frame, (int(x), int(y)), 15, (0, 255, 255), thickness=-1, lineType=cv.FILLED)cv2.putText(frame, "{}".format(i), (int(x), int(y)), cv2.FONT_HERSHEY_SIMPLEX, 1.4, (0, 0, 255), 3, lineType=cv2.LINE_AA)# Add the point to the list if the probability is greater than the thresholdpoints.append((int(x), int(y)))else :points.append(None)cv2.imshow("Output-Keypoints",frame)cv2.waitKey(0)cv2.destroyAllWindows()
步骤4:绘制骨架
由于我们已经绘制了关键点,因此我们现在只需将两对连接即可绘制骨架。
for pair in POSE_PAIRS:partA = pair[0]partB = pair[1]if points[partA] and points[partB]:points[partA], points[partB], (0, 255, 0), 3)
结果
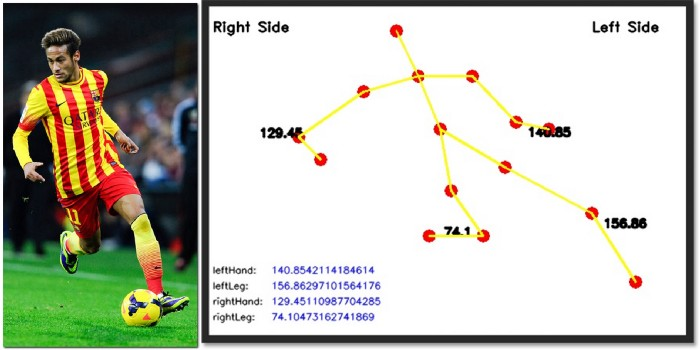
上面显示的输出向我们显示了运动员在特定时刻的准确姿势。下面是视频的检测结果。
项目源码:https://github.com/ManaliSeth/Athlete-Pose-Detection
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~